Recognition: unknown
Come Together: Analyzing Popular Songs Through Statistical Embeddings
Pith reviewed 2026-05-08 09:08 UTC · model grok-4.3
The pith
Logistic principal component analysis turns song features into embeddings that support statistical study of stylistic changes in early Beatles music.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
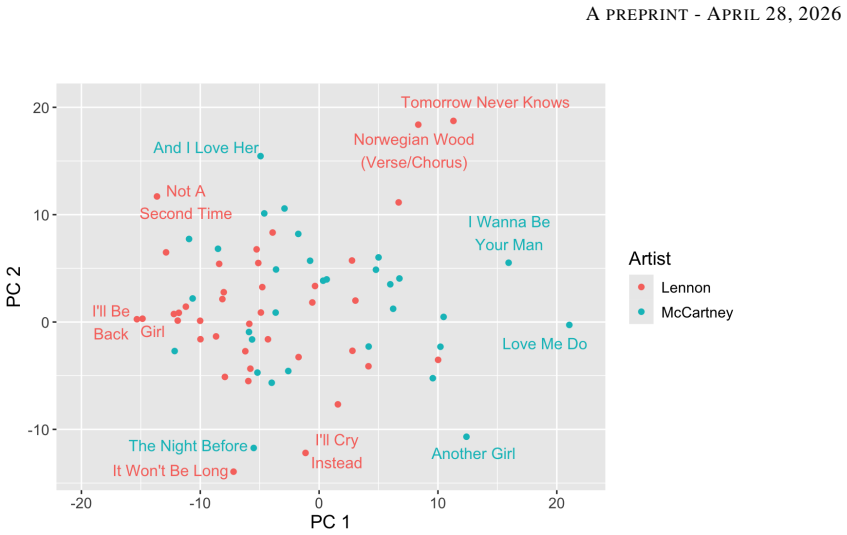
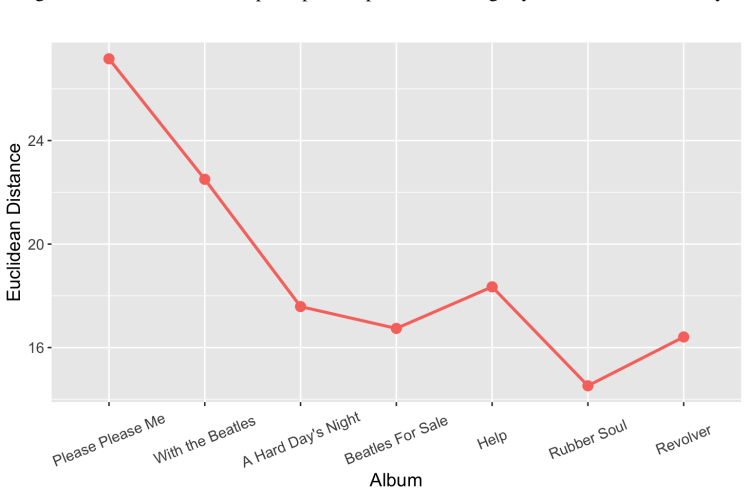
The central claim is that embeddings obtained through logistic principal component analysis on global song features including chords, melodic notes, chord and pitch transitions, and melodic contours enable standard multivariate analysis of a corpus of Lennon and McCartney songs from 1962-1966. This framework is applied to explore how the embeddings cluster by Beatles album, how songwriting styles changed over time, and whether the two songwriters' compositions converged or diverged.
What carries the argument
logistic principal component analysis applied to global song features to produce vector embeddings suitable for multivariate statistical analysis
Load-bearing premise
The selected musical features and the logistic PCA embeddings derived from them meaningfully encode the stylistic and structural differences the authors wish to study.
What would settle it
Recomputing the embeddings and finding no album-aligned clusters or no consistent temporal trends across the 1962-1966 songs would show that the features and embeddings do not capture the intended differences.
Figures








read the original abstract
Statistical modeling of popular music presents a unique challenge due to the complexity of song structures, which cannot be easily analyzed using conventional statistical tools. However, recent advances in data science have shown that converting non-standard data objects into real vector-valued embeddings enables meaningful statistical analysis. In this work, we demonstrate an approach based on logistic principal component analysis to construct embeddings from global song features, allowing for standard multivariate analysis. We apply this method to a corpus of Lennon and McCartney songs from 1962-1966, using embeddings derived from chords, melodic notes, chord and pitch transitions, and melodic contours. Our analysis explores how these song embeddings cluster by Beatles album, how songwriting styles evolved over time, and whether Lennon and McCartney's compositions exhibited convergence or divergence. This embedding-based approach offers a powerful framework for statistically examining musical structure and stylistic development in popular music.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes logistic principal component analysis to construct low-dimensional embeddings from global song features (chords, melodic notes, chord/pitch transitions, and melodic contours) extracted from a corpus of Lennon-McCartney Beatles songs (1962-1966). These embeddings are then used for standard multivariate statistical analyses to examine album-based clustering, temporal evolution of songwriting styles, and convergence or divergence between Lennon and McCartney.
Significance. If the embeddings faithfully represent the input musical features, the work supplies a practical framework for applying conventional multivariate tools to complex, non-vector musical data. The Beatles application serves as a coherent proof-of-concept, with internally consistent feature encoding, logistic PCA implementation, and exploratory visualizations that illustrate album clustering and stylistic trends without requiring additional distributional assumptions.
minor comments (3)
- The abstract describes the method and goals but supplies no equations, validation steps, error analysis, or results; adding a single sentence summarizing the key empirical observations (e.g., observed clustering patterns) would improve reader orientation without altering the manuscript's scope.
- The methods section would benefit from an explicit statement of the number of songs analyzed and the precise encoding scheme used for each feature type (chords, notes, transitions, contours) to allow direct replication.
- Figure captions should more clearly indicate which panels correspond to which downstream analysis (album clustering, temporal trends, Lennon-McCartney comparison) and note any preprocessing steps applied to the embeddings before visualization.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. The review accurately captures the core contribution of using logistic PCA embeddings to enable standard multivariate analyses on musical features.
Circularity Check
No significant circularity detected
full rationale
The paper applies logistic principal component analysis—an established external technique—to song feature vectors (chords, notes, transitions, contours) to produce embeddings, then performs standard multivariate analysis on those embeddings. No derivation step reduces to a self-definition, a fitted parameter renamed as a prediction, or a load-bearing self-citation chain. The workflow is a direct, non-circular dimensionality reduction followed by exploratory interpretation on a new corpus, remaining fully self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Logistic principal component analysis is appropriate for converting categorical musical features into continuous embeddings suitable for multivariate analysis
Reference graph
Works this paper leans on
-
[1]
doi: 10.1201/9780367816377. Leo Breiman. Random forests.Machine Learning, 45(1):5–32, Oct
-
[2]
ISSN 1573-0565. doi: 10.1023/A: 1010933404324. URLhttps://doi.org/10.1023/A:1010933404324. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Zi...
-
[3]
Language Models are Few-Shot Learners
URL https://arxiv.org/abs/2005.14165. John Ashley Burgoyne, Jonathan Wild, and Ichiro Fujinaga. Compositional data analysis of harmonic structures in popular music. InMathematics and Computation in Music, pages 52–63, Berlin, Heidelberg,
work page internal anchor Pith review arXiv 2005
-
[4]
Jan de Leeuw
URL https://proceedings.neurips.cc/paper_files/ paper/2001/file/f410588e48dc83f2822a880a68f78923-Paper.pdf. Jan de Leeuw. Principal component analysis of binary data by iterated singular value decomposition.Computational Statistics & Data Analysis, 50(1):21–39,
2001
-
[5]
doi: https://doi.org/10.1016/j.csda.2004.07.010
ISSN 0167-9473. doi: https://doi.org/10.1016/j.csda.2004.07.010. URL https://www.sciencedirect.com/science/article/pii/S0167947304002300. 2nd Special issue on Matrix Computations and Statistics. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding,
-
[6]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
URLhttps://arxiv.org/abs/1810.04805. Mark Glickman, Jason Brown, and Ryan Song. (A) Data in the Life: Authorship Attribution in Lennon-McCartney Songs.Harvard Data Science Review, 1(1), jul 2
work page internal anchor Pith review arXiv
-
[7]
ISSN 0047-259X. doi: https://doi.org/10.1016/j. jmva.2020.104668. Seokho Lee, Jianhua Z. Huang, and Jianhua Hu. Sparse logistic principal components analysis for binary data. The Annals of Applied Statistics, 4(3), September
work page doi:10.1016/j 2020
-
[8]
ISSN 1932-6157. doi: 10.1214/10-aoas327. URL http://dx.doi.org/10.1214/10-AOAS327. J. Lennon, D. Sheff, and Y . Ono.All We Are Saying: The Last Major Interview with John Lennon and Yoko Ono. Pan Macmillan,
-
[9]
Efficient Estimation of Word Representations in Vector Space
URLhttps://arxiv.org/abs/1301.3781. Barry Miles.Paul McCartney: Many Years From Now. Henry Holt & Co,
work page internal anchor Pith review arXiv
-
[10]
doi: 10.1109/ICME. 2002.1035728. David J. Pannell. Quantitative analysis of the evolution of the beatles’ releases for emi, 1962–1970.Jour- nal of Beatles Studies, 2023(Spring/Autumn):65–90,
-
[11]
doi: 10.3828/jbs.2023.5. URL https://www. liverpooluniversitypress.co.uk/doi/abs/10.3828/jbs.2023.5. 12 APREPRINT- APRIL28, 2026 Andrew I. Schein, Lawrence K. Saul, and Lyle H. Ungar. A generalized linear model for principal component analysis of binary data. In Christopher M. Bishop and Brendan J. Frey, editors,Proceedings of the Ninth International Work...
-
[12]
URL https://arxiv.org/abs/2312. 11805. arXiv:2312.11805. John Thickstun, Zaid Harchaoui, and Sham Kakade. Learning features of music from scratch. InInternational Conference on Learning Representations,
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.