Recognition: unknown
The Power of Power Law: Asymmetry Enables Compositional Reasoning
Pith reviewed 2026-05-08 11:46 UTC · model grok-4.3
The pith
Power-law distributions let models learn rare compositional skills with far less data than uniform sampling does.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Training under power-law distributions consistently outperforms training under uniform distributions across a wide range of compositional reasoning tasks such as state tracking and multi-step arithmetic. The paper proves this advantage in a minimalist skill-composition task, showing that power-law sampling requires significantly less training data. The mechanism is that the induced asymmetry improves the pathological loss landscape, enabling models to first acquire high-frequency skill compositions with low data complexity; these compositions then serve as stepping stones to efficiently learn rare long-tailed skills.
What carries the argument
The asymmetry induced by power-law sampling in the loss landscape of skill-composition tasks.
If this is right
- High-frequency skill compositions are learned early with low data complexity.
- These compositions act as stepping stones that reduce the data needed for rare combinations.
- Overall training data requirements drop for achieving compositional reasoning.
- Data curation that flattens natural frequencies can slow progress on long-tail skills.
Where Pith is reading between the lines
- Data pipelines for language models might benefit from keeping rather than correcting power-law imbalances.
- The stepping-stone effect could appear in other hierarchical domains such as planning or visual composition.
- Scaling experiments on larger models could quantify the data savings in practice.
- The loss-landscape asymmetry offers a new angle on why certain pretraining distributions work well.
Load-bearing premise
The minimalist skill-composition task faithfully captures the structure of real compositional reasoning problems so that the data-efficiency advantage transfers.
What would settle it
A controlled experiment on a real compositional task where uniform sampling reaches target performance with equal or fewer examples than power-law sampling.
Figures




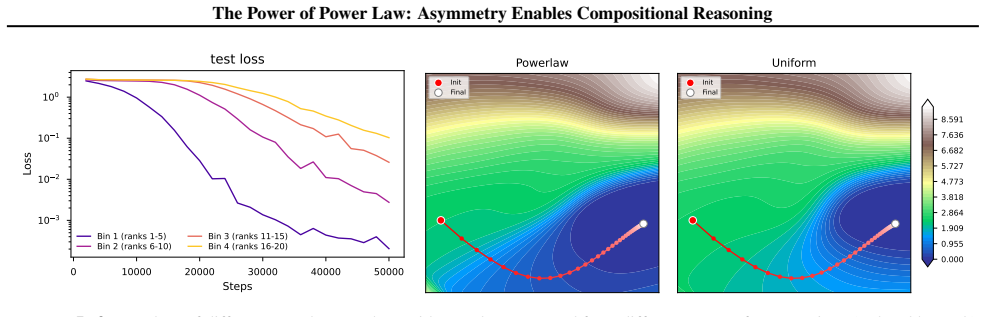


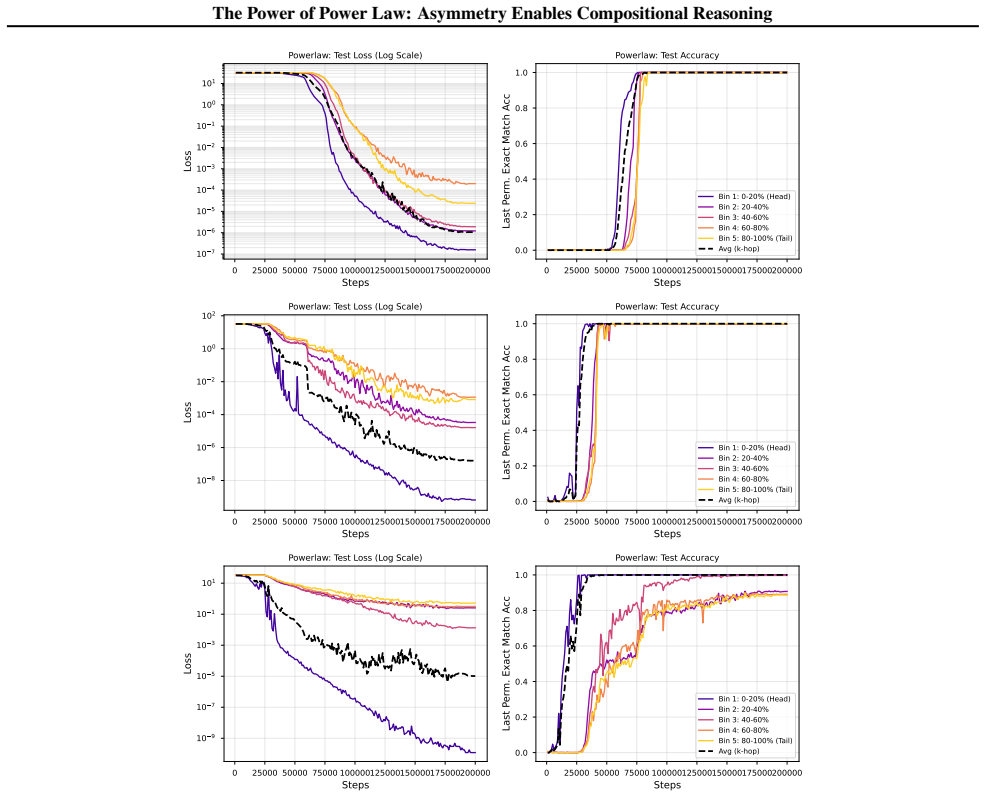
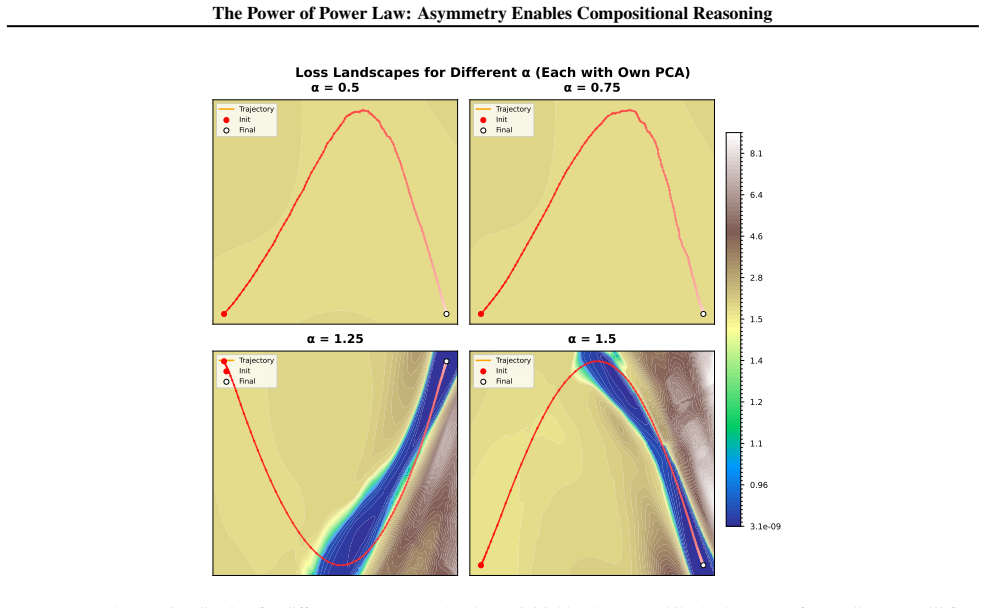


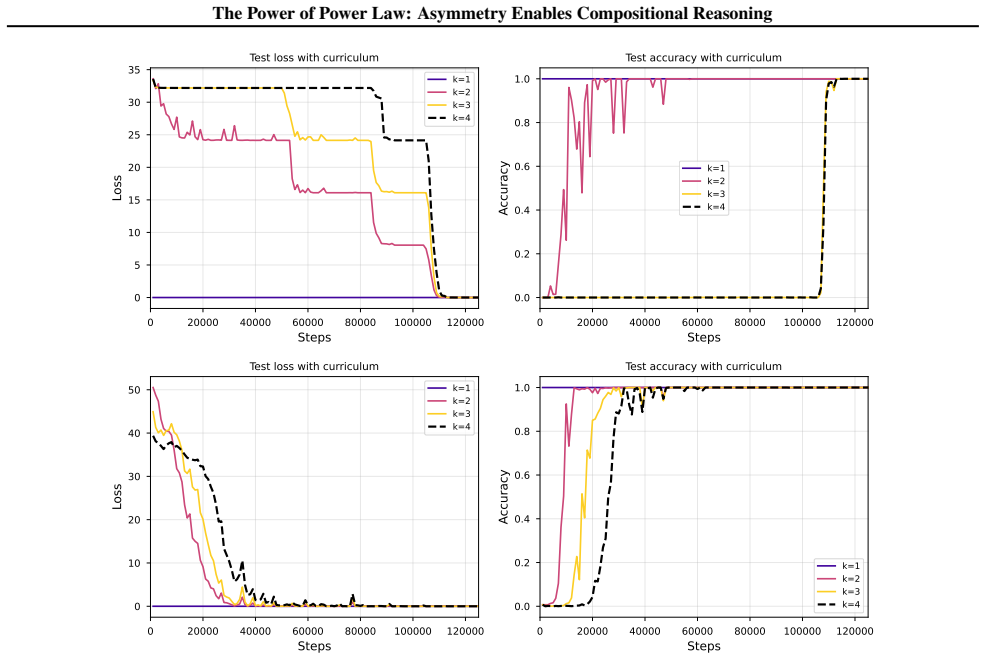


read the original abstract
Natural language data follows a power-law distribution, with most knowledge and skills appearing at very low frequency. While a common intuition suggests that reweighting or curating data towards a uniform distribution may help models better learn these long-tail skills, we find a counterintuitive result: across a wide range of compositional reasoning tasks, such as state tracking and multi-step arithmetic, training under power-law distributions consistently outperforms training under uniform distributions. To understand this advantage, we introduce a minimalist skill-composition task and show that learning under a power-law distribution provably requires significantly less training data. Our theoretical analysis reveals that power law sampling induces a beneficial asymmetry that improves the pathological loss landscape, which enables models to first acquire high-frequency skill compositions with low data complexity, which in turn serves as a stepping stone to efficiently learn rare long-tailed skills. Our results offer an alternative perspective on what constitutes an effective data distribution for training models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that training under power-law distributions outperforms uniform distributions on compositional reasoning tasks such as state tracking and multi-step arithmetic. It supports this empirically across multiple tasks and theoretically via a minimalist skill-composition task, where power-law sampling induces asymmetry in the loss landscape that lets high-frequency skill compositions serve as stepping stones, provably reducing the data needed to learn rare long-tail skills.
Significance. If the central claim holds, the result challenges the common practice of reweighting data toward uniformity for long-tail coverage and instead highlights the value of preserving natural power-law statistics for compositional generalization. The work earns credit for running experiments across several tasks that support the performance claim and for providing a minimalist-task analysis that yields a concrete data-complexity advantage; these elements make the contribution more than purely empirical.
major comments (2)
- [theoretical analysis / minimalist skill-composition task] The theoretical analysis (minimalist skill-composition task): the provable data-efficiency result is derived from the authors' own definition of the task rather than an external benchmark, and the manuscript does not supply a quantitative argument or ablation showing that the clean separability and tree-like composition assumed there survive the overlapping sub-components and context coupling present in the state-tracking tasks of the empirical section.
- [discussion of loss-landscape asymmetry] Mapping from toy model to full-scale loss landscapes: the paper asserts that the asymmetry benefit transfers to real compositional reasoning, yet no diagnostic (e.g., loss-surface visualization or gradient-flow analysis on the actual state-tracking or arithmetic models) is provided to verify that high-frequency stepping stones remain useful once shared sub-skills and contextual dependencies are introduced.
minor comments (1)
- [abstract] The abstract and introduction could more explicitly delimit the range of tasks and model scales on which the power-law advantage was measured, to help readers assess the scope of the empirical claim.
Simulated Author's Rebuttal
We thank the referee for the insightful comments, which help clarify the scope and limitations of our theoretical analysis. We address each major point below, providing additional context on the design of the minimalist task and the nature of the loss-landscape argument while outlining targeted revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [theoretical analysis / minimalist skill-composition task] The theoretical analysis (minimalist skill-composition task): the provable data-efficiency result is derived from the authors' own definition of the task rather than an external benchmark, and the manuscript does not supply a quantitative argument or ablation showing that the clean separability and tree-like composition assumed there survive the overlapping sub-components and context coupling present in the state-tracking tasks of the empirical section.
Authors: The minimalist task is deliberately constructed as an abstracted model that isolates the effect of power-law sampling on compositional acquisition, enabling a clean proof of reduced data complexity via the stepping-stone mechanism. The separability and tree structure are modeling choices that make the asymmetry in the loss landscape mathematically tractable; they are not claimed to be literal replicas of natural language. In the empirical sections, state-tracking and arithmetic tasks do contain overlapping sub-skills and contextual dependencies, yet the consistent performance advantage under power-law sampling provides supporting evidence that the core dynamic persists. We do not provide a new quantitative ablation bridging the two in the current version. We will revise the manuscript to add an explicit discussion paragraph that articulates the modeling assumptions, notes the gap between the toy setting and full tasks, and explains why the empirical results are still consistent with the predicted mechanism. revision: partial
-
Referee: [discussion of loss-landscape asymmetry] Mapping from toy model to full-scale loss landscapes: the paper asserts that the asymmetry benefit transfers to real compositional reasoning, yet no diagnostic (e.g., loss-surface visualization or gradient-flow analysis on the actual state-tracking or arithmetic models) is provided to verify that high-frequency stepping stones remain useful once shared sub-skills and contextual dependencies are introduced.
Authors: The loss-landscape asymmetry is rigorously characterized only within the minimalist task, where the loss function can be analyzed directly. Extending the same visualization or gradient-flow diagnostics to the high-dimensional parameter spaces of the state-tracking and arithmetic models is computationally prohibitive and rarely yields interpretable surfaces even when attempted. The transfer argument therefore rests on the theoretical insight plus the observed generalization gap between power-law and uniform training across multiple tasks. We agree that additional diagnostics would be valuable. We will revise the discussion section to acknowledge this limitation explicitly and to outline feasible future probes, such as measuring the acquisition order of high-frequency versus low-frequency compositions via intermediate checkpoints or representation similarity. revision: partial
Circularity Check
No significant circularity detected; derivation is self-contained.
full rationale
The paper introduces a minimalist skill-composition task as an explicit theoretical construct to isolate the effect of power-law sampling on compositional learning. The claimed provable data-efficiency advantage is derived as a consequence of the sampling distribution within this model (asymmetry improving the loss landscape for high-frequency stepping stones), which does not reduce to a tautology or self-referential definition. Empirical results on state tracking and arithmetic tasks are reported separately and do not depend on the theory for validity. No load-bearing step equates a prediction to its fitted input by construction, nor does any uniqueness theorem or ansatz reduce to prior self-citation. The analysis remains within standard bounds for model-based proofs and does not import external results that collapse back to the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Natural language data follows a power-law distribution over skills and compositions.
- ad hoc to paper The minimalist skill-composition task isolates the essential structure of real compositional reasoning.
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
S., Bresler, G., and Nagaraj, D
Abbe, E., Boix-Adsera, E., Brennan, M. S., Bresler, G., and Nagaraj, D. The staircase property: How hierarchical structure can guide deep learning. Advances in Neural Information Processing Systems, 34: 0 26989--27002, 2021
2021
-
[3]
B., and Misiakiewicz, T
Abbe, E., Adsera, E. B., and Misiakiewicz, T. The merged-staircase property: a necessary and nearly sufficient condition for sgd learning of sparse functions on two-layer neural networks. In Conference on Learning Theory, pp.\ 4782--4887. PMLR, 2022
2022
-
[4]
Provable advantage of curriculum learning on parity targets with mixed inputs
Abbe, E., Cornacchia, E., and Lotfi, A. Provable advantage of curriculum learning on parity targets with mixed inputs. Advances in Neural Information Processing Systems, 36: 0 24291--24321, 2023
2023
-
[5]
Physics of language models: Part 3.2, knowledge manipula- tion.arXiv:2309.14402, 2023
Allen-Zhu, Z. and Li, Y. Physics of language models: Part 3.2, knowledge manipulation. arXiv preprint arXiv:2309.14402, 2023
-
[6]
Asymptotics of SGD in sequence-single index models and single-layer attention networks
Arnaboldi, L., Loureiro, B., Stephan, L., Krzakala, F., and Zdeborova, L. Asymptotics of sgd in sequence-single index models and single-layer attention networks. arXiv preprint arXiv:2506.02651, 2025
-
[7]
A theory for emergence of complex skills in language models
Arora, S. and Goyal, A. A theory for emergence of complex skills in language models. arXiv preprint arXiv:2307.15936, 2023
-
[8]
Hidden progress in deep learning: Sgd learns parities near the computational limit
Barak, B., Edelman, B., Goel, S., Kakade, S., Malach, E., and Zhang, C. Hidden progress in deep learning: Sgd learns parities near the computational limit. Advances in Neural Information Processing Systems, 35: 0 21750--21764, 2022
2022
-
[9]
arXiv preprint arXiv:2406.12775 , year=
Biran, E., Gottesman, D., Yang, S., Geva, M., and Globerson, A. Hopping too late: Exploring the limitations of large language models on multi-hop queries. arXiv preprint arXiv:2406.12775, 2024
-
[10]
David Chiang, Peter Cholak, and Anand Pillay
Chen, L., Peng, B., and Wu, H. Theoretical limitations of multi-layer transformer. arXiv preprint arXiv:2412.02975, 2024
-
[11]
Skill-it! a data-driven skills framework for understanding and training language models
Chen, M., Roberts, N., Bhatia, K., Wang, J., Zhang, C., Sala, F., and R \'e , C. Skill-it! a data-driven skills framework for understanding and training language models. Advances in Neural Information Processing Systems, 36: 0 36000--36040, 2023
2023
-
[12]
and Mossel, E
Cornacchia, E. and Mossel, E. A mathematical model for curriculum learning for parities. In International Conference on Machine Learning, pp.\ 6402--6423. PMLR, 2023
2023
-
[13]
arXiv preprint arXiv:2502.06443 , year=
Cornacchia, E., Mikulincer, D., and Mossel, E. Low-dimensional functions are efficiently learnable under randomly biased distributions. arXiv preprint arXiv:2502.06443, 2025
-
[14]
Neural networks can learn representations with gradient descent
Damian, A., Lee, J., and Soltanolkotabi, M. Neural networks can learn representations with gradient descent. In Conference on Learning Theory, pp.\ 5413--5452. PMLR, 2022
2022
-
[15]
and Malach, E
Daniely, A. and Malach, E. Learning parities with neural networks. Advances in Neural Information Processing Systems, 33: 0 20356--20365, 2020
2020
-
[16]
From explicit cot to implicit cot: Learning to internalize cot step by step
Deng, Y., Choi, Y., and Shieber, S. From explicit cot to implicit cot: Learning to internalize cot step by step. arXiv preprint arXiv:2405.14838, 2024
-
[17]
R., Guo, S., Valko, M., Lillicrap, T., Jimenez Rezende, D., Bengio, Y., Mozer, M
Didolkar, A., Goyal, A., Ke, N. R., Guo, S., Valko, M., Lillicrap, T., Jimenez Rezende, D., Bengio, Y., Mozer, M. C., and Arora, S. Metacognitive capabilities of llms: An exploration in mathematical problem solving. Advances in Neural Information Processing Systems, 37: 0 19783--19812, 2024
2024
-
[18]
and Hsu, D
Dudeja, R. and Hsu, D. Learning single-index models in gaussian space. In Bubeck, S., Perchet, V., and Rigollet, P. (eds.), Proceedings of the 31st Conference On Learning Theory, volume 75 of Proceedings of Machine Learning Research, pp.\ 1887--1930. PMLR, 06--09 Jul 2018. URL https://proceedings.mlr.press/v75/dudeja18a.html
1930
-
[19]
Gordon, M. A., Duh, K., and Kaplan, J. Data and parameter scaling laws for neural machine translation. In Moens, M.-F., Huang, X., Specia, L., and Yih, S. W.-t. (eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp.\ 5915--5922, Online and Punta Cana, Dominican Republic, November 2021. Association for Computati...
-
[20]
Scaling Laws for Autoregressive Generative Modeling
Henighan, T., Kaplan, J., Katz, M., Chen, M., Hesse, C., Jackson, J., Jun, H., Brown, T. B., Dhariwal, P., Gray, S., et al. Scaling laws for autoregressive generative modeling. arXiv preprint arXiv:2010.14701, 2020
work page internal anchor Pith review arXiv 2010
-
[21]
Hestness, J., Narang, S., Ardalani, N., Diamos, G., Jun, H., Kianinejad, H., Patwary, M. M. A., Yang, Y., and Zhou, Y. Deep learning scaling is predictable, empirically. arXiv preprint arXiv:1712.00409, 2017
work page internal anchor Pith review arXiv 2017
-
[22]
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. d. L., Hendricks, L. A., Welbl, J., Clark, A., et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022
work page internal anchor Pith review arXiv 2022
- [23]
-
[24]
Transformers provably learn chain-of-thought reasoning with length generalization
Huang, Y., Wen, Z., Singh, A., Chi, Y., and Chen, Y. Transformers provably learn chain-of-thought reasoning with length generalization. arXiv preprint arXiv:2511.07378, 2025 b
-
[25]
A., Brown, M., Yang, M.-H., Wang, L., and Gong, B
Jamal, M. A., Brown, M., Yang, M.-H., Wang, L., and Gong, B. Rethinking class-balanced methods for long-tailed visual recognition from a domain adaptation perspective. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 7610--7619, 2020
2020
-
[26]
Investigating multi-hop factual shortcuts in knowledge editing of large language models
Ju, T., Chen, Y., Yuan, X., Zhang, Z., Du, W., Zheng, Y., and Liu, G. Investigating multi-hop factual shortcuts in knowledge editing of large language models. arXiv preprint arXiv:2402.11900, 2024
-
[27]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review arXiv 2001
-
[28]
Linear convergence of gradient and proximal-gradient methods under the polyak- ojasiewicz condition
Karimi, H., Nutini, J., and Schmidt, M. Linear convergence of gradient and proximal-gradient methods under the polyak- ojasiewicz condition. In Machine Learning and Knowledge Discovery in Databases, pp.\ 795--811. Springer, 2016
2016
-
[29]
Kassner, N., Krojer, B., and Sch \"u tze, H. Are pretrained language models symbolic reasoners over knowledge? arXiv preprint arXiv:2006.10413, 2020
-
[30]
Kim, J. and Suzuki, T. Transformers provably solve parity efficiently with chain of thought. arXiv preprint arXiv:2410.08633, 2024
-
[31]
Understanding and patching compositional reasoning in llms
Li, Z., Jiang, G., Xie, H., Song, L., Lian, D., and Wei, Y. Understanding and patching compositional reasoning in llms. arXiv preprint arXiv:2402.14328, 2024 a
-
[32]
Chain of thought empowers transformers to solve inherently serial problems, 2024
Li, Z., Liu, H., Zhou, D., and Ma, T. Chain of thought empowers transformers to solve inherently serial problems. arXiv preprint arXiv:2402.12875, 2024 b
-
[33]
T., Goel, S., Krishnamurthy, A., and Zhang, C
Liu, B., Ash, J. T., Goel, S., Krishnamurthy, A., and Zhang, C. Transformers learn shortcuts to automata. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=De4FYqjFueZ
2023
-
[34]
Liu, Z., Liu, Y., Michaud, E. J., Gore, J., and Tegmark, M. Physics of skill learning. arXiv preprint arXiv:2501.12391, 2025
-
[35]
Martinez-Taboada, D. and Ramdas, A. Empirical bernstein in smooth banach spaces. arXiv preprint arXiv:2409.06060, 2024
-
[36]
arXiv preprint arXiv:2510.25108 , year=
Medvedev, M., Lyu, K., Li, Z., and Srebro, N. Shift is good: Mismatched data mixing improves test performance. arXiv preprint arXiv:2510.25108, 2025
-
[37]
arXiv preprint arXiv:2602.08907 , year=
Medvedev, M., Attias, I., Cornacchia, E., Misiakiewicz, T., Vardi, G., and Srebro, N. Positive distribution shift as a framework for understanding tractable learning. arXiv preprint arXiv:2602.08907, 2026 a
-
[38]
Shift is good: Mismatched data mixing improves test performance
Medvedev, M., Lyu, K., Li, Z., and Srebro, N. Shift is good: Mismatched data mixing improves test performance. In The 29th International Conference on Artificial Intelligence and Statistics, 2026 b
2026
-
[39]
The expressive power of transformers with chain of thought, 2024
Merrill, W. and Sabharwal, A. The expresssive power of transformers with chain of thought. arXiv preprint arXiv:2310.07923, 2023 a
-
[40]
and Sabharwal, A
Merrill, W. and Sabharwal, A. The parallelism tradeoff: Limitations of log-precision transformers. Transactions of the Association for Computational Linguistics, 11: 0 531--545, 2023 b
2023
-
[41]
The quantization model of neural scaling
Michaud, E., Liu, Z., Girit, U., and Tegmark, M. The quantization model of neural scaling. Advances in Neural Information Processing Systems, 36: 0 28699--28722, 2023
2023
-
[42]
Mousavi-Hosseini, A., Wu, D., Suzuki, T., and Erdogdu, M. A. Gradient-based feature learning under structured data. Advances in Neural Information Processing Systems, 36: 0 71449--71485, 2023
2023
-
[43]
Task arithmetic in the tangent space: Improved editing of pre-trained models
Ortiz-Jimenez, G., Favero, A., and Frossard, P. Task arithmetic in the tangent space: Improved editing of pre-trained models. Advances in Neural Information Processing Systems, 36: 0 66727--66754, 2023
2023
-
[44]
On limitations of the transformer architecture
Peng, B., Narayanan, S., and Papadimitriou, C. On limitations of the transformer architecture. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=KidynPuLNW
2024
-
[45]
Prabha, D., Aswini, J., Maheswari, B., Subramanian, R
Press, O., Zhang, M., Min, S., Schmidt, L., Smith, N., and Lewis, M. Measuring and narrowing the compositionality gap in language models. In Bouamor, H., Pino, J., and Bali, K. (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023, pp.\ 5687--5711, Singapore, December 2023. Association for Computational Linguistics. doi:10.18653/v1...
-
[46]
Ren, Y., Wang, Z., and Lee, J. D. Learning and transferring sparse contextual bigrams with linear transformers. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[47]
and Vershynin, R
Rudelson, M. and Vershynin, R. Hanson-wright inequality and sub-gaussian concentration. 2013
2013
-
[48]
Representational strengths and limitations of transformers
Sanford, C., Hsu, D., and Telgarsky, M. Representational strengths and limitations of transformers. In Advances in Neural Information Processing Systems 36, 2023
2023
-
[49]
Beyond neural scaling laws: beating power law scaling via data pruning
Sorscher, B., Geirhos, R., Shekhar, S., Ganguli, S., and Morcos, A. Beyond neural scaling laws: beating power law scaling via data pruning. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Advances in Neural Information Processing Systems, volume 35, pp.\ 19523--19536. Curran Associates, Inc., 2022. URL https://proceeding...
2022
-
[50]
Characterizing statistical query learning: simplified notions and proofs
Sz \"o r \'e nyi, B. Characterizing statistical query learning: simplified notions and proofs. In International Conference on Algorithmic Learning Theory, pp.\ 186--200. Springer, 2009
2009
-
[51]
Grokked transformers are implicit reasoners: A mechanistic journey to the edge of generalization
Wang, B., Yue, X., Su, Y., and Sun, H. Grokked transformers are implicit reasoners: A mechanistic journey to the edge of generalization. arXiv preprint arXiv:2405.15071, 2024
- [52]
-
[53]
Wang, Z., Nichani, E., Bietti, A., Damian, A., Hsu, D., Lee, J. D., and Wu, D. Learning compositional functions with transformers from easy-to-hard data. arXiv preprint arXiv:2505.23683, 2025
-
[54]
International Conference on Learning Representations , year =
Wen, K., Zhang, H., Lin, H., and Zhang, J. From sparse dependence to sparse attention: unveiling how chain-of-thought enhances transformer sample efficiency. arXiv preprint arXiv:2410.05459, 2024
-
[55]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Zhou, J., Lin, J., Dang, K., Bao, K., Yang, K., Yu, L., Deng, L., Li, M., Xue, M., Li, M., Zhang, P., Wang, P., Zhu, Q...
work page internal anchor Pith review arXiv 2025
-
[56]
arXiv preprint arXiv:2402.16837 , year=
Yang, S., Gribovskaya, E., Kassner, N., Geva, M., and Riedel, S. Do large language models latently perform multi-hop reasoning? arXiv preprint arXiv:2402.16837, 2024
-
[57]
Yao, Y., Du, Y., Zhu, D., Hahn, M., and Koller, A. Language models can learn implicit multi-hop reasoning, but only if they have lots of training data. arXiv preprint arXiv:2505.17923, 2025 a
-
[58]
Cake: Circuit-aware editing enables generalizable knowledge learners
Yao, Y., Fang, J., Gu, J.-C., Zhang, N., Deng, S., Chen, H., and Peng, N. Cake: Circuit-aware editing enables generalizable knowledge learners. arXiv preprint arXiv:2503.16356, 2025 b
-
[59]
How does transformer learn implicit reasoning? arXiv preprint arXiv:2505.23653, 2025
Ye, J., Yao, Z., Huang, Z., Pan, L., Liu, J., Bai, Y., Xin, A., Weichuan, L., Che, X., Hou, L., et al. How does transformer learn implicit reasoning? arXiv preprint arXiv:2505.23653, 2025
-
[60]
Ye, T., Xu, Z., Li, Y., and Allen-Zhu, Z. Physics of language models: Part 2.1, grade-school math and the hidden reasoning process. arXiv preprint arXiv:2407.20311, 2024
-
[61]
Skill-mix: a flexible and expandable family of evaluations for ai models
Yu, D., Kaur, S., Gupta, A., Brown-Cohen, J., Goyal, A., and Arora, S. Skill-mix: a flexible and expandable family of evaluations for ai models. In The Twelfth International Conference on Learning Representations, 2023
2023
-
[62]
Frequency balanced datasets lead to better language models
Zevallos, R., Farr \'u s, M., and Bel, N. Frequency balanced datasets lead to better language models. In Findings of the Association for Computational Linguistics: EMNLP 2023, pp.\ 7859--7872, 2023
2023
-
[63]
Zhang, M., Fang, B., Liu, Q., Ren, P., Wu, S., Chen, Z., and Wang, L. Enhancing multi-hop reasoning through knowledge erasure in large language model editing. arXiv preprint arXiv:2408.12456, 2024
-
[64]
Can models learn skill composition from examples? Advances in Neural Information Processing Systems, 37: 0 102393--102427, 2024
Zhao, H., Kaur, S., Yu, D., Goyal, A., and Arora, S. Can models learn skill composition from examples? Advances in Neural Information Processing Systems, 37: 0 102393--102427, 2024
2024
-
[65]
arXiv preprint arXiv:2305.14795
Zhong, Z., Wu, Z., Manning, C. D., Potts, C., and Chen, D. Mquake: Assessing knowledge editing in language models via multi-hop questions. arXiv preprint arXiv:2305.14795, 2023
-
[66]
Zhou, Y., Liu, H., Chen, Z., Tian, Y., and Chen, B. Gsm-infinite: How do your llms behave over infinitely increasing context length and reasoning complexity? arXiv preprint arXiv:2502.05252, 2025
-
[67]
Scaling Latent Reasoning via Looped Language Models
Zhu, R.-J., Wang, Z., Hua, K., Zhang, T., Li, Z., Que, H., Wei, B., Wen, Z., Yin, F., Xing, H., et al. Scaling latent reasoning via looped language models. arXiv preprint arXiv:2510.25741, 2025
work page internal anchor Pith review arXiv 2025
-
[68]
Zipf, G. K. Human behavior and the principle of least effort: An introduction to human ecology. Ravenio books, 2016
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.