Recognition: unknown
CheXmix: Unified Generative Pretraining for Vision Language Models in Medical Imaging
Pith reviewed 2026-05-08 12:18 UTC · model grok-4.3
The pith
A two-stage early-fusion generative pretraining strategy unifies vision and language for medical imaging tasks without distorting features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CheXmix is a unified early-fusion generative model that applies a two-stage pretraining combining masked autoencoders with autoregressive modeling on chest X-ray report pairs. The resulting models support both discriminative and generative tasks at coarse and fine-grained scales. They outperform well-established generative models across all masking ratios by 6.0 percent and achieve 8.6 percent higher AUROC at high image masking ratios on classification tasks. They also inpaint images over 51.0 percent better than text-only generative models and improve radiology report generation by 45 percent on the GREEN metric.
What carries the argument
The two-stage multimodal generative pretraining in an early-fusion autoregressive architecture, which processes image and text tokens jointly to leverage language model priors.
If this is right
- The model supports both discriminative and generative tasks at coarse and fine scales.
- It maintains performance even at high image masking ratios.
- Image inpainting quality exceeds text-only models significantly.
- Radiology report generation improves substantially on quality metrics.
- The approach captures fine-grained information across a broad spectrum of chest X-ray tasks.
Where Pith is reading between the lines
- Similar two-stage fusion methods could be tested on other imaging modalities like CT or MRI.
- Future work might compare this to scale-matched baselines to isolate the fusion benefit.
- Adopting early fusion might simplify training pipelines by removing the need for separate vision encoders.
Load-bearing premise
The performance improvements are mainly due to the early-fusion architecture and two-stage pretraining rather than larger datasets or different training setups.
What would settle it
Training a comparable model using the standard decoupled projection method with the same data and compute resources and finding no performance gap would challenge the claim.
Figures




read the original abstract
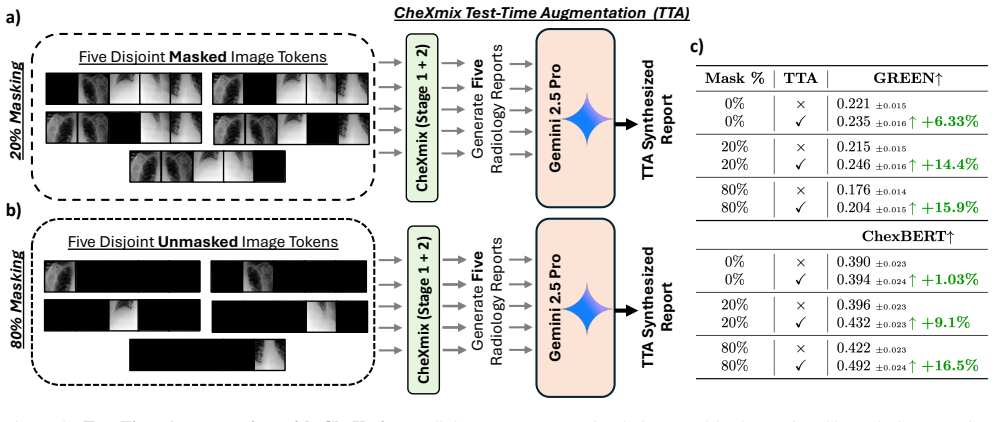
Recent medical multimodal foundation models are built as multimodal LLMs (MLLMs) by connecting a CLIP-pretrained vision encoder to an LLM using LLaVA-style finetuning. This two-stage, decoupled approach introduces a projection layer that can distort visual features. This is especially concerning in medical imaging where subtle cues are essential for accurate diagnoses. In contrast, early-fusion generative approaches such as Chameleon eliminate the projection bottleneck by processing image and text tokens within a single unified sequence, enabling joint representation learning that leverages the inductive priors of language models. We present CheXmix, a unified early-fusion generative model trained on a large corpus of chest X-rays paired with radiology reports. We expand on Chameleon's autoregressive framework by introducing a two-stage multimodal generative pretraining strategy that combines the representational strengths of masked autoencoders with MLLMs. The resulting models are highly flexible, supporting both discriminative and generative tasks at both coarse and fine-grained scales. Our approach outperforms well-established generative models across all masking ratios by 6.0% and surpasses CheXagent by 8.6% on AUROC at high image masking ratios on the CheXpert classification task. We further inpaint images over 51.0% better than text-only generative models and outperform CheXagent by 45% on the GREEN metric for radiology report generation. These results demonstrate that CheXmix captures fine-grained information across a broad spectrum of chest X-ray tasks. Our code is at: https://github.com/StanfordMIMI/CheXmix.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CheXmix, a unified early-fusion generative vision-language model for chest X-rays and radiology reports. It extends the Chameleon autoregressive framework with a two-stage pretraining strategy that first applies masked autoencoding then generative modeling on a large paired corpus. The model supports both discriminative (e.g., CheXpert classification) and generative tasks (inpainting, report generation). The central empirical claims are 6.0% better performance than established generative models across masking ratios, 8.6% AUROC improvement over CheXagent at high masking ratios, 51% better inpainting than text-only models, and 45% higher GREEN score for report generation.
Significance. If the reported gains can be shown to arise from the early-fusion unified token sequence and two-stage pretraining rather than unmatched scale or compute, the work would provide a useful alternative to projection-based MLLM pipelines in medical imaging by preserving fine-grained visual features. The public code release at the cited GitHub repository is a clear strength that supports reproducibility and community follow-up.
major comments (2)
- [Abstract and Experimental Results] Abstract and Experimental Results section: The claimed 6.0% and 8.6% AUROC lifts, 51% inpainting improvement, and 45% GREEN gain are presented without error bars, statistical significance tests, or ablation tables that hold model capacity, training data volume, optimizer schedule, and total compute fixed while varying only the two-stage schedule or early-fusion design. This leaves the attribution of gains to the proposed architecture under-determined relative to baselines such as CheXagent.
- [Methods and Experimental Results] Methods and Experimental Results sections: No controlled comparison is reported that isolates the contribution of the masked-autoencoder-then-generative pretraining versus a single-stage generative baseline or versus late-fusion alternatives, while matching parameter count and corpus size. Without these controls the central claim that the two-stage early-fusion strategy is the primary driver of the observed task improvements cannot be verified.
minor comments (2)
- [Abstract] Abstract: The phrase 'well-established generative models' is used without naming the specific baselines; listing them would improve immediate clarity for readers.
- [Experimental Results] The manuscript would benefit from an explicit statement of the exact data splits and preprocessing steps used for the CheXpert AUROC evaluation to allow direct replication.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the current empirical presentation would benefit from greater statistical rigor and controlled ablations to more convincingly attribute gains to the two-stage early-fusion design. We address each major comment below and commit to incorporating the requested elements in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and Experimental Results] Abstract and Experimental Results section: The claimed 6.0% and 8.6% AUROC lifts, 51% inpainting improvement, and 45% GREEN gain are presented without error bars, statistical significance tests, or ablation tables that hold model capacity, training data volume, optimizer schedule, and total compute fixed while varying only the two-stage schedule or early-fusion design. This leaves the attribution of gains to the proposed architecture under-determined relative to baselines such as CheXagent.
Authors: We acknowledge that the manuscript reports point estimates without error bars or formal significance testing and that direct comparisons to published baselines do not hold every training hyperparameter fixed. In the revision we will rerun the primary CheXpert classification and report-generation experiments with at least three random seeds, report mean and standard deviation, and include paired statistical tests (e.g., Wilcoxon signed-rank) against the strongest baseline. We will also add an ablation table that matches model size, corpus, optimizer schedule, and total compute while varying only the pretraining schedule (two-stage MAE-then-generative versus single-stage generative) and will discuss the contribution of early fusion relative to late-fusion alternatives under these controls. revision: yes
-
Referee: [Methods and Experimental Results] Methods and Experimental Results sections: No controlled comparison is reported that isolates the contribution of the masked-autoencoder-then-generative pretraining versus a single-stage generative baseline or versus late-fusion alternatives, while matching parameter count and corpus size. Without these controls the central claim that the two-stage early-fusion strategy is the primary driver of the observed task improvements cannot be verified.
Authors: We agree that the absence of matched internal baselines leaves the source of the observed gains under-determined. The current manuscript compares against external models whose training details differ. In the revised version we will train and report a single-stage autoregressive baseline on the identical paired corpus using the same architecture, parameter count, and compute budget as CheXmix. We will also add a brief analysis of late-fusion design choices in the Methods section and, where compute permits, a controlled late-fusion ablation. These additions will be placed in the Experimental Results section to directly support the central claim. revision: yes
Circularity Check
No circularity in derivation chain; results are empirical
full rationale
The paper reports AUROC, inpainting, and GREEN metric improvements on held-out CheXpert and report-generation tasks. No equations, first-principles derivations, or predictions are claimed; performance numbers are measured outcomes, not quantities obtained by fitting parameters to the same data and relabeling them as predictions. The two-stage pretraining and early-fusion architecture are presented as design choices whose value is assessed by ablation-style comparisons, not by self-referential definitions. Self-citations, if present, are not load-bearing for any central claim. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Transformer-based autoregressive modeling can jointly process image patches and text tokens in a single sequence without a separate projection layer.
- domain assumption Masked autoencoder pretraining followed by generative continuation improves representation quality for downstream medical imaging tasks.
Reference graph
Works this paper leans on
-
[1]
Shah, Greg Zaharchuk, Marc Willis, Adam Yala, Andrew Johnston, Robert D
Louis Blankemeier, Ashwin Kumar, Joseph Paul Cohen, Jiaming Liu, Longchao Liu, Dave Van Veen, Syed Ja- mal Safdar Gardezi, Hongkun Yu, Magdalini Paschali, Zhi- hong Chen, Jean-Benoit Delbrouck, Eduardo Reis, Rob- bie Holland, Cesar Truyts, Christian Bluethgen, Yufu Wu, Long Lian, Malte Engmann Kjeldskov Jensen, Sophie Ost- meier, Maya Varma, Jeya Maria Jo...
2026
-
[2]
Padchest: A large chest x-ray image dataset with multi-label annotated reports.Medical image analysis, 66:101797, 2020
Aurelia Bustos, Antonio Pertusa, Jose-Maria Salinas, and Maria De La Iglesia-Vaya. Padchest: A large chest x-ray image dataset with multi-label annotated reports.Medical image analysis, 66:101797, 2020. 4
2020
-
[3]
Pierre Chambon, Christian Bluethgen, Curtis P Langlotz, and Akshay Chaudhari. Adapting pretrained vision-language foundational models to medical imaging domains.arXiv preprint arXiv:2210.04133, 2022. 4
-
[4]
Chexpert plus: Hundreds of thousands of aligned radiology texts, images and patients
Pierre Chambon, Jean-Benoit Delbrouck, Thomas Sounack, Shih-Cheng Huang, Zhihong Chen, Maya Varma, Steven QH Truong, Curtis P Langlotz, et al. Chexpert plus: Hundreds of thousands of aligned radiology texts, images and patients. arXiv e-prints, pages arXiv–2405, 2024. 4
2024
-
[5]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Team Chameleon. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024. 2, 3, 4, 5, 14, 15, 16, 18, 19
work page internal anchor Pith review arXiv 2024
-
[6]
Multi-modal masked autoencoders for medical vision-and-language pre- training
Zhihong Chen, Yuhao Du, Jinpeng Hu, Yang Liu, Guan- bin Li, Xiang Wan, and Tsung-Hui Chang. Multi-modal masked autoencoders for medical vision-and-language pre- training. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 679–
-
[7]
3, 5, 18
Springer, 2022. 3, 5, 18
2022
-
[8]
Zhihong Chen, Maya Varma, Jean-Benoit Delbrouck, Mag- dalini Paschali, Louis Blankemeier, Dave Van Veen, Jeya Maria Jose Valanarasu, Alaa Youssef, Joseph Paul Cohen, Eduardo Pontes Reis, Emily B. Tsai, Andrew Johnston, Cameron Olsen, Tanishq Mathew Abraham, Sergios Ga- tidis, Akshay S Chaudhari, and Curtis Langlotz. Chexagent: Towards a foundation model f...
-
[9]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 15
work page internal anchor Pith review arXiv 2025
-
[10]
Ibrahim Ethem Hamamci, Sezgin Er, Chenyu Wang, Furkan Almas, Ayse Gulnihan Simsek, Sevval Nil Esirgun, Irem Doga, Omer Faruk Durugol, Weicheng Dai, Murong Xu, et al. Developing generalist foundation models from a mul- timodal dataset for 3d computed tomography.arXiv preprint arXiv:2403.17834, 2024. 1
-
[11]
Continual instruction tuning for large multimodal models
Jinghan He, Haiyun Guo, Ming Tang, and Jinqiao Wang. Continual instruction tuning for large multimodal models. arXiv preprint arXiv:2311.16206, 2023. 2, 3
-
[12]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000– 16009, 2022. 2, 3, 5, 16, 18, 22
2022
-
[13]
Gloria: A multimodal global-local represen- tation learning framework for label-efficient medical image recognition
Shih-Cheng Huang, Liyue Shen, Matthew P Lungren, and Serena Yeung. Gloria: A multimodal global-local represen- tation learning framework for label-efficient medical image recognition. InProceedings of the IEEE/CVF international conference on computer vision, pages 3942–3951, 2021. 3
2021
-
[14]
Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison
Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Sil- viana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. InProceedings of the AAAI conference on artificial intelligence, pages 590–597, 2019. 4
2019
-
[15]
arXiv preprint arXiv:2106.14463 (2021)
Saahil Jain, Ashwin Agrawal, Adriel Saporta, Steven QH Truong, Du Nguyen Duong, Tan Bui, Pierre Chambon, Yuhao Zhang, Matthew P Lungren, Andrew Y Ng, et al. Rad- graph: Extracting clinical entities and relations from radiol- ogy reports.arXiv preprint arXiv:2106.14463, 2021. 15, 18
-
[16]
Mimic-cxr-jpg, a large publicly available database of labeled chest radiographs,
Alistair EW Johnson, Tom J Pollard, Nathaniel R Green- baum, Matthew P Lungren, Chih-ying Deng, Yifan Peng, Zhiyong Lu, Roger G Mark, Seth J Berkowitz, and Steven Horng. Mimic-cxr-jpg, a large publicly available database of 9 labeled chest radiographs.arXiv preprint arXiv:1901.07042,
-
[17]
Raphi Kang, Yue Song, Georgia Gkioxari, and Pietro Per- ona. Is clip ideal? no. can we fix it? yes!arXiv preprint arXiv:2503.08723, 2025. 2
-
[18]
Llava-med: Training a large language- and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564,
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language- and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564,
-
[19]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 3
2023
-
[20]
On erro- neous agreements of clip image embeddings
Siting Li, Pang Wei Koh, and Simon Shaolei Du. On erro- neous agreements of clip image embeddings. 2024. 2
2024
-
[21]
Textbooks Are All You Need II: phi-1.5 technical report
Yuanzhi Li, S ´ebastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar, and Yin Tat Lee. Textbooks are all you need ii: phi-1.5 technical report.arXiv preprint arXiv:2309.05463, 2023. 4
work page internal anchor Pith review arXiv 2023
-
[22]
Video-llava: Learning united visual repre- sentation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual repre- sentation by alignment before projection. InProceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing, pages 5971–5984, 2024. 1
2024
-
[23]
HealthGPT: A medical large vision- language model for unifying comprehension and generation via heterogeneous knowledge adaptation, 2025
Tianwei Lin, Wenqiao Zhang, Sijing Li, Yuqian Yuan, Binhe Yu, Haoyuan Li, Wanggui He, Hao Jiang, Mengze Li, Xiao- hui Song, Siliang Tang, Jun Xiao, Hui Lin, Yueting Zhuang, and Beng Chin Ooi. HealthGPT: A medical large vision- language model for unifying comprehension and generation via heterogeneous knowledge adaptation, 2025. 5, 18
2025
-
[24]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 1, 3
2023
-
[25]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 1
2024
-
[26]
Towards interpretable counterfactual generation via multi- modal autoregression
Chenglong Ma, Yuanfeng Ji, Jin Ye, Lu Zhang, Ying Chen, Tianbin Li, Mingjie Li, Junjun He, and Hongming Shan. Towards interpretable counterfactual generation via multi- modal autoregression. InInternational Conference on Med- ical Image Computing and Computer-Assisted Intervention, pages 611–620. Springer, 2025. 3
2025
-
[27]
Chest radiographs of cardiac devices (part 1): Lines, tubes, non-cardiac medical devices and materials.SA Jour- nal of Radiology, 23(1):1–9, 2019
Rishi P Mathew, Timothy Alexander, Vimal Patel, and Gavin Low. Chest radiographs of cardiac devices (part 1): Lines, tubes, non-cardiac medical devices and materials.SA Jour- nal of Radiology, 23(1):1–9, 2019. 14
2019
-
[28]
Green: Generative radiology re- port evaluation and error notation
Sophie Ostmeier, Justin Xu, Zhihong Chen, Maya Varma, Louis Blankemeier, Christian Bluethgen, Arne Ed- ward Michalson Md, Michael Moseley, Curtis Langlotz, Ak- shay S Chaudhari, et al. Green: Generative radiology re- port evaluation and error notation. InFindings of the asso- ciation for computational linguistics: EMNLP 2024, pages 374–390, 2024. 6, 15, 17
2024
-
[29]
Context encoders: Feature learning by inpainting
Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A Efros. Context encoders: Feature learning by inpainting. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 2536–2544, 2016. 5
2016
-
[30]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 1, 3
2021
-
[31]
The challenges, opportunities, and impera- tive of structured reporting in medical imaging.Journal of digital imaging, 22(6):562–568, 2009
Bruce I Reiner. The challenges, opportunities, and impera- tive of structured reporting in medical imaging.Journal of digital imaging, 22(6):562–568, 2009. 6
2009
-
[32]
Subtle lung nodules: influence of local anatomic variations on detection.Radiology, 228(1):76–84,
Ehsan Samei, Michael J Flynn, Edward Peterson, and William R Eyler. Subtle lung nodules: influence of local anatomic variations on detection.Radiology, 228(1):76–84,
-
[33]
Com- puted radiography image artifacts revisited.American Jour- nal of Roentgenology, 196(1):W37–W47, 2011
Chandrakant Manmath Shetty, Ashita Barthur, Avinash Kambadakone, Nilna Narayanan, and Rajagopal Kv. Com- puted radiography image artifacts revisited.American Jour- nal of Roentgenology, 196(1):W37–W47, 2011. 14
2011
-
[34]
Augmenting the national institutes of health chest radiograph dataset with expert annotations of possi- ble pneumonia.Radiology: Artificial Intelligence, 1(1): e180041, 2019
George Shih, Carol C Wu, Safwan S Halabi, Marc D Kohli, Luciano M Prevedello, Tessa S Cook, Arjun Sharma, Judith K Amorosa, Veronica Arteaga, Maya Galperin- Aizenberg, et al. Augmenting the national institutes of health chest radiograph dataset with expert annotations of possi- ble pneumonia.Radiology: Artificial Intelligence, 1(1): e180041, 2019. 4
2019
-
[35]
Akshay Smit, Saahil Jain, Pranav Rajpurkar, Anuj Pareek, Andrew Y Ng, and Matthew P Lungren. Chexbert: com- bining automatic labelers and expert annotations for accu- rate radiology report labeling using bert.arXiv preprint arXiv:2004.09167, 2020. 6, 15, 18
-
[36]
Shikhar Srivastava, Md Yousuf Harun, Robik Shrestha, and Christopher Kanan. Improving multimodal large lan- guage models using continual learning.arXiv preprint arXiv:2410.19925, 2024. 2, 3
-
[37]
Generative pretraining in mul- timodality
Quan Sun, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, Yueze Wang, Hongcheng Gao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Emu: Generative pretraining in multimodality.arXiv preprint arXiv:2307.05222, 2023. 3
-
[38]
Towards gen- eralist biomedical ai.Nejm Ai, 1(3):AIoa2300138, 2024
Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaeker- mann, Mohamed Amin, Pi-Chuan Chang, Andrew Carroll, Charles Lau, Ryutaro Tanno, Ira Ktena, et al. Towards gen- eralist biomedical ai.Nejm Ai, 1(3):AIoa2300138, 2024. 3
2024
-
[39]
Maya Varma, Ashwin Kumar, Rogier Van der Sluijs, Sophie Ostmeier, Louis Blankemeier, Pierre Chambon, Christian Bluethgen, Jip Prince, Curtis Langlotz, and Akshay Chaud- hari. Medvae: Efficient automated interpretation of medical images with large-scale generalizable autoencoders.arXiv preprint arXiv:2502.14753, 2025. 4
-
[40]
Maria De La Iglesia Vay´a, Jose Manuel Saborit, Joaquim An- gel Montell, Antonio Pertusa, Aurelia Bustos, Miguel Ca- zorla, Joaquin Galant, Xavier Barber, Domingo Orozco- Beltr´an, Francisco Garc ´ıa-Garc´ıa, et al. Bimcv covid-19+: A large annotated dataset of rx and ct images from covid-19 patients.arXiv preprint arXiv:2006.01174, 2020. 4 10
-
[41]
Gaurav Verma, Minje Choi, Kartik Sharma, Jamelle Watson- Daniels, Sejoon Oh, and Srijan Kumar. Cross-modal pro- jection in multimodal llms doesn’t really project visual at- tributes to textual space.arXiv preprint arXiv:2402.16832,
-
[42]
Xinyi Wang, Grazziela Figueredo, Ruizhe Li, Wei Emma Zhang, Weitong Chen, and Xin Chen. A survey of deep learning-based radiology report generation using multimodal data.arXiv preprint arXiv:2405.12833, 2024. 6
-
[43]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528, 2024. 2, 3, 7, 16
work page internal anchor Pith review arXiv 2024
-
[44]
Self-supervised learning application on covid- 19 chest x-ray image classification using masked autoen- coder.Bioengineering, 10(8):901, 2023
Xin Xing, Gongbo Liang, Chris Wang, Nathan Jacobs, and Ai-Ling Lin. Self-supervised learning application on covid- 19 chest x-ray image classification using masked autoen- coder.Bioengineering, 10(8):901, 2023. 16, 22
2023
-
[45]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023. 3
2023
-
[46]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, et al. Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs.arXiv preprint arXiv:2303.00915,
work page internal anchor Pith review arXiv
-
[47]
BERTScore: Evaluating Text Generation with BERT
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Wein- berger, and Yoav Artzi. Bertscore: Evaluating text genera- tion with bert.arXiv preprint arXiv:1904.09675, 2019. 15, 18
work page internal anchor Pith review arXiv 1904
-
[48]
Why are visually-grounded language models bad at image classi- fication?Advances in Neural Information Processing Sys- tems, 37:51727–51753, 2024
Yuhui Zhang, Alyssa Unell, Xiaohan Wang, Dhruba Ghosh, Yuchang Su, Ludwig Schmidt, and Serena Yeung-Levy. Why are visually-grounded language models bad at image classi- fication?Advances in Neural Information Processing Sys- tems, 37:51727–51753, 2024. 2, 3, 14
2024
-
[49]
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Chunting Zhou, Lili Yu, Arun Babu, Kushal Tirumala, Michihiro Yasunaga, Leonid Shamis, Jacob Kahn, Xuezhe Ma, Luke Zettlemoyer, and Omer Levy. Transfusion: Pre- dict the next token and diffuse images with one multi-modal model.arXiv preprint arXiv:2408.11039, 2024. 2, 3, 7, 16 11 CheXmix: Unified Generative Pretraining for Vision Language Models in Medica...
work page internal anchor Pith review arXiv 2024
-
[50]
A single ‘‘Findings’’ section
-
[51]
A single ‘‘Impressions’’ section. Rules:
-
[52]
Combine and de-duplicate all repetitive information
-
[53]
Make sure the synthesized report is the SAME LENGTH as the original reports
-
[54]
If there are slight variations in wording for the same finding, use the most precise and complete description
-
[55]
Ensure the final ‘‘Findings’’ and ‘‘Impressions’’ are comprehensive and written as a single, coherent section each with no newlines or bullet points
-
[56]
If no findings or impressions are present in the generated reports, then leave blank. 25
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.