Recognition: unknown
CASP: Support-Aware Offline Policy Selection for Two-Stage Recommender Systems
Pith reviewed 2026-05-08 10:03 UTC · model grok-4.3
The pith
CASP selects two-stage recommender policies by penalizing those that rely on weakly supported generator-item pairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CASP combines doubly robust value estimation with a support-burden penalty for selecting from a finite library of two-stage policies. It shows that stagewise rules ignoring downstream continuation value can be arbitrarily suboptimal and derives population, finite-class, and reconstructed-propensity guarantees for conservative selection.
What carries the argument
The support-burden penalty in CASP, which quantifies the reliance on generator-item pairs with low reconstructed propensity and adds it to the value estimate to enforce conservatism.
If this is right
- Selected policies will tend to have lower support burden when estimated value and data credibility are in tension.
- Two-stage systems require joint consideration of generator and ranker rather than optimizing stages independently.
- The approach provides finite-sample guarantees even when using reconstructed propensities instead of true ones.
- Simulations and MovieLens experiments demonstrate selection of lower-burden policies.
Where Pith is reading between the lines
- Applying similar support penalties could improve policy selection in other sequential decision systems with partial observability.
- If support estimation is noisy, the method might need additional regularization to remain effective.
- Extending CASP to infinite policy classes would require new approximation techniques for the burden term.
Load-bearing premise
Support can be reliably measured using reconstructed propensities from a finite, pre-specified library of policies.
What would settle it
An experiment showing that a policy with high estimated value but high support burden outperforms the CASP-selected policy in a live deployment would indicate the penalty is overly conservative or miscalibrated.
Figures





read the original abstract
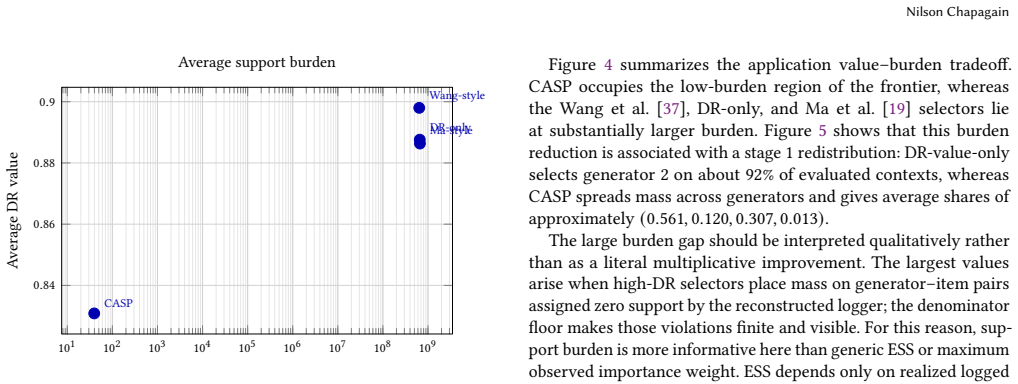
Two-stage recommender systems first choose a candidate generator and then rank items within the generated set. Because the generator decides which items are available to the ranker, changing the generator changes both the policy value and the data support used to estimate that value. This creates an offline selection problem that standard single-stage objectives do not capture: a policy may look good under a retrieval score or a raw off-policy value estimate, but still be unreliable if it depends on weakly supported generator-item pairs. We propose CASP (Coupled Action-Set Pessimism), a support-aware offline selector for finite libraries of two-stage recommender policies. CASP combines doubly robust value estimation with a support-burden penalty. We show that stagewise rules that ignore downstream continuation value can be arbitrarily suboptimal, and we derive population, finite-class, and reconstructed-propensity guarantees for conservative selection. In simulations and a reconstructed MovieLens 1M application, CASP selects lower-burden policies when estimated value and support credibility are in tension.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CASP (Coupled Action-Set Pessimism), a method for offline selection among a finite library of two-stage recommender policies. It combines doubly robust value estimation with a support-burden penalty that accounts for the generator's effect on item support available to the ranker. The central claims are that stagewise selection rules ignoring continuation value can be arbitrarily suboptimal, and that CASP provides population, finite-class, and reconstructed-propensity guarantees enabling conservative selection when value estimates conflict with support credibility. Empirical results on simulations and a reconstructed MovieLens 1M dataset show CASP preferring lower-burden policies.
Significance. If the guarantees are valid, the work fills a gap in offline policy evaluation for two-stage systems by explicitly coupling generator-induced support with ranker value estimation. The pessimism mechanism could prevent selection of policies whose apparent performance relies on sparsely observed generator-item pairs. The finite-library assumption and reconstructed-propensity setting are realistic for many production recommenders, but the result's impact hinges on whether the support penalty reliably bounds true risk under realistic misspecification.
major comments (3)
- [§4] §4 (theoretical guarantees): the manuscript states population, finite-class, and reconstructed-propensity bounds but supplies no derivation steps, concentration inequalities, or proof sketches for how the support-burden penalty is subtracted from the doubly robust estimator to produce a conservative upper bound on true risk. Without these steps it is impossible to verify that the penalty protects against policies inflated by weakly supported generator-item pairs.
- [§3.2] §3.2 (reconstructed-propensity support estimation): the support penalty is defined using propensities reconstructed from the generator; however, no sensitivity analysis or error propagation bound is given showing how generator misspecification, data sparsity, or estimation variance in the reconstruction affects the pessimism term. If reconstruction error is moderate, the penalty may under-penalize high-value but low-support policies, violating the conservative guarantee.
- [§2] §2 (suboptimality of stagewise rules): the claim that stagewise rules ignoring downstream continuation value can be arbitrarily suboptimal is illustrated but lacks a general construction or worst-case example that applies beyond the specific two-stage setup; it is therefore unclear whether the suboptimality result is load-bearing for the need for CASP or merely motivational.
minor comments (2)
- [§3] Notation for the support-burden penalty and the reconstructed propensity should be introduced with explicit definitions and distinguished from standard propensity scores to avoid confusion with single-stage off-policy estimators.
- [§5] The MovieLens experiment description should specify how the generator and ranker policies were constructed from the data and how the finite library was enumerated, including any hyper-parameter choices for the reconstruction step.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We respond to each major comment below, indicating planned revisions to the manuscript where appropriate.
read point-by-point responses
-
Referee: [§4] §4 (theoretical guarantees): the manuscript states population, finite-class, and reconstructed-propensity bounds but supplies no derivation steps, concentration inequalities, or proof sketches for how the support-burden penalty is subtracted from the doubly robust estimator to produce a conservative upper bound on true risk. Without these steps it is impossible to verify that the penalty protects against policies inflated by weakly supported generator-item pairs.
Authors: The complete proofs for the population, finite-class, and reconstructed-propensity guarantees appear in the appendix. To improve accessibility, we will add concise proof sketches to Section 4 of the main text. These sketches will outline the decomposition of the doubly robust estimator, the subtraction of the support-burden penalty, and the concentration inequalities that establish the conservative upper bound on true risk. revision: yes
-
Referee: [§3.2] §3.2 (reconstructed-propensity support estimation): the support penalty is defined using propensities reconstructed from the generator; however, no sensitivity analysis or error propagation bound is given showing how generator misspecification, data sparsity, or estimation variance in the reconstruction affects the pessimism term. If reconstruction error is moderate, the penalty may under-penalize high-value but low-support policies, violating the conservative guarantee.
Authors: This concern is well-taken. The current reconstructed-propensity guarantee assumes accurate reconstruction. In the revision we will add a sensitivity analysis to Section 3.2 that derives bounds on the effect of reconstruction error, data sparsity, and estimation variance on the pessimism term, under standard bounded-misspecification assumptions. This will clarify the conditions under which the conservative guarantee continues to hold. revision: yes
-
Referee: [§2] §2 (suboptimality of stagewise rules): the claim that stagewise rules ignoring downstream continuation value can be arbitrarily suboptimal is illustrated but lacks a general construction or worst-case example that applies beyond the specific two-stage setup; it is therefore unclear whether the suboptimality result is load-bearing for the need for CASP or merely motivational.
Authors: The example in Section 2 is constructed to exhibit arbitrary suboptimality arising from the generator–ranker interaction that is central to two-stage systems. We view it as load-bearing for motivating CASP. We will revise the section to present the construction more explicitly as a worst-case within the two-stage policy class and add a short discussion clarifying its scope and relevance to the paper’s setting. revision: partial
Circularity Check
No circularity: CASP guarantees derived independently from standard off-policy techniques
full rationale
The paper derives population, finite-class, and reconstructed-propensity guarantees for conservative selection by combining doubly robust value estimation with an externally defined support-burden penalty. No equations reduce these guarantees to fitted inputs by construction, and the support penalty is not defined in terms of the value estimate itself. The finite-library assumption is stated explicitly as a precondition rather than smuggled in via self-citation or ansatz. The central claims rest on first-principles derivations for two-stage systems rather than renaming known results or importing uniqueness theorems from the authors' prior work. This is a standard adaptation of offline RL techniques and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aman Agarwal, Keisuke Takatsu, Ilya Zaitsev, and Thorsten Joachims. 2018. Counterfactual Learning-to-Rank for Additive Metrics and Deep Models. In Proceedings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR)
2018
-
[2]
Charles, D
Léon Bottou, Jonas Peters, Joaquin Quiñonero-Candela, Denis X. Charles, D. Max Chickering, Elon Portugaly, Dipankar Ray, Patrice Simard, and Ed Snelson. 2013. Counterfactual Reasoning and Learning Systems: The Example of Computational Advertising. InJournal of Machine Learning Research: Workshop and Conference Proceedings, Vol. 30. 320–327
2013
-
[3]
Minmin Chen, Alex Beutel, Paul Covington, Sagar Jain, Fran Belletti, and Ed H. Chi. 2019. Top-K Off-Policy Correction for a REINFORCE Recommender System. InProceedings of the Twelfth ACM International Conference on Web Search and Data Mining (WSDM). 456–464. doi:10.1145/3289600.3290999
-
[4]
McAuley, Dietmar Jannach, and Lina Yao
Xiaocong Chen, Siyu Wang, Julian J. McAuley, Dietmar Jannach, and Lina Yao
-
[5]
On the Opportunities and Challenges of Offline Reinforcement Learning for Recommender Systems.ACM Transactions on Information Systems42, 6 (2024), 150:1–150:26. doi:10.1145/3661996
-
[6]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep Neural Networks for YouTube Recommendations. InProceedings of the 10th ACM Conference on Recommender Systems (RecSys). Association for Computing Machinery, New York, NY, USA, 191–198. doi:10.1145/2959100.2959190
-
[7]
Miroslav Dudík, Dumitru Erhan, John Langford, and Lihong Li. 2014. Doubly Robust Policy Evaluation and Optimization.Statist. Sci.29, 4 (2014), 485–511. doi:10.1214/14-STS500
-
[8]
Chongming Gao et al . 2024. Causal Inference in Recommender Systems: A Survey and Future Directions.ACM Transactions on Information Systems(2024). doi:10.1145/3639048
-
[9]
Alexandre Gilotte, Clément Calauzènes, Thomas Nedelec, Alexandre Abraham, and Simon Dollé. 2018. Offline A/B Testing for Recommender Systems. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining (WSDM). Association for Computing Machinery, New York, NY, USA, 198–206. doi:10.1145/3159652.3159687
-
[10]
Yifan Hu, Yehuda Koren, and Chris Volinsky. 2008. Collaborative Filtering for Implicit Feedback Datasets. InProceedings of the 2008 Eighth IEEE International Conference on Data Mining (ICDM). IEEE, 263–272. doi:10.1109/ICDM.2008.22
-
[11]
Eugene Ie, Chih-Wei Hsu, Martin Mladenov, Vihan Jain, Sanmit Narvekar, Jing Wang, Rui Wu, and Craig Boutilier. 2019. Reinforcement Learning for Slate-Based Recommender Systems: A Tractable Decomposition and Practical Methodology. InProceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI). 2592–2599. doi:10.24963/i...
-
[12]
Olivier Jeunen and Bart Goethals. 2021. Pessimistic Reward Models for Off- Policy Learning in Recommendation. InProceedings of the 15th ACM Conference on Recommender Systems (RecSys). Association for Computing Machinery, New York, NY, USA, 63–74. doi:10.1145/3460231.3474247 Nilson Chapagain
-
[13]
Olivier Jeunen and Bart Goethals. 2023. Pessimistic Decision-Making for Recom- mender Systems.ACM Transactions on Recommender Systems1, 1 (2023), 1–27. doi:10.1145/3568029
-
[14]
Olivier Jeunen, Jatin Mandav, Ivan Potapov, Nakul Agarwal, Sourabh Vaid, Wen- zhe Shi, and Aleksei Ustimenko. 2024. Multi-Objective Recommendation via Multivariate Policy Learning. InProceedings of the 18th ACM Conference on Rec- ommender Systems (RecSys). Association for Computing Machinery, New York, NY, USA, 712–721. doi:10.1145/3640457.3688132
-
[15]
Thorsten Joachims, Adith Swaminathan, and Maarten de Rijke. 2018. Deep Learning with Logged Bandit Feedback. InInternational Conference on Learning Representations (ICLR)
2018
-
[16]
Thorsten Joachims, Adith Swaminathan, and Tobias Schnabel. 2017. Unbiased Learning-to-Rank with Biased Feedback. InProceedings of the Tenth ACM Interna- tional Conference on Web Search and Data Mining (WSDM). Association for Com- puting Machinery, New York, NY, USA, 781–789. doi:10.1145/3018661.3018699
-
[17]
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. 2020. Offline Re- inforcement Learning: Tutorial, Review, and Perspectives on Open Problems. arXiv preprint arXiv:2005.01643(2020)
work page internal anchor Pith review arXiv 2020
-
[18]
Lihong Li, Wei Chu, John Langford, and Xuanhui Wang. 2011. Unbiased Offline Evaluation of Contextual-bandit-based News Article Recommendation Algo- rithms. InProceedings of the 4th ACM International Conference on Web Search and Data Mining (WSDM). Association for Computing Machinery, New York, NY, USA, 297–306. doi:10.1145/1935826.1935878
-
[19]
Huishi Luo, Fuzhen Zhuang, Ruobing Xie, Hengshu Zhu, Deqing Wang, Zhulin An, and Yongjun Xu. 2024. A Survey on Causal Inference for Recommendation. The Innovation5, 3 (2024)
2024
-
[20]
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Ji Yang, Minmin Chen, Jiaxi Tang, Lichan Hong, and Ed H. Chi. 2020. Off-Policy Learning in Two-Stage Recommender Systems. InProceedings of The Web Conference 2020 (WWW). Association for Computing Machinery, New York, NY, USA, 463–473. doi:10.1145/3366423.3380130
-
[21]
James McInerney, Brian Brost, Praveen Chandar, Rishabh Mehrotra, and Ben Carterette. 2020. Counterfactual Evaluation of Slate Recommendations with Se- quential Reward Interactions. InProceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). Association for Computing Machinery, New York, NY, USA, 1779–1788
2020
-
[22]
Jiaxi Peng, Hao Zou, Jiacheng Liu, Shilong Li, Yichi Jiang, Jian Pei, and Peng Cui
-
[23]
InProceedings of The Web Conference 2023 (WWW)
Offline Policy Evaluation in Large Action Spaces via Outcome-Oriented Action Grouping. InProceedings of The Web Conference 2023 (WWW). 1220–1230
2023
-
[24]
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt- Thieme. 2009. BPR: Bayesian Personalized Ranking from Implicit Feedback. InProceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelli- gence (UAI). AUAI Press, 452–461
2009
-
[25]
Noveen Sachdeva, Yi Su, and Thorsten Joachims. 2020. Off-Policy Bandits with Deficient Support. InProceedings of the 26th ACM SIGKDD Conference on Knowl- edge Discovery and Data Mining (KDD). Association for Computing Machinery, New York, NY, USA, 965–975
2020
-
[26]
Noveen Sachdeva, Lequn Wang, Dawen Liang, Nathan Kallus, and Julian McAuley. 2024. Off-Policy Evaluation for Large Action Spaces via Policy Convo- lution. InProceedings of The Web Conference 2024 (WWW). Association for Com- puting Machinery, New York, NY, USA, 3576–3585. doi:10.1145/3589334.3645501
-
[27]
Yuta Saito et al. 2021. Open Bandit Pipeline: A Pipeline for Reproducible Off- Policy Evaluation and Learning.Journal of Machine Learning Research22 (2021), 1–37
2021
-
[28]
Yuta Saito, Shunsuke Aihara, Megumi Matsutani, and Yusuke Narita. 2021. Open Bandit Dataset and Pipeline: Towards Realistic and Reproducible Off-Policy Evaluation. InNeurIPS 2021 Datasets and Benchmarks Track. Curran Associates, Inc., Red Hook, NY, USA, 38 pages
2021
-
[29]
Yuta Saito and Thorsten Joachims. 2022. Off-Policy Evaluation for Large Action Spaces via Embeddings. InProceedings of the 39th International Conference on Machine Learning (ICML) (Proceedings of Machine Learning Research, Vol. 162). PMLR, Baltimore, MD, USA, 19089–19122
2022
-
[30]
Yuta Saito, Qingyang Ren, and Thorsten Joachims. 2023. Off-Policy Evaluation for Large Action Spaces via Conjunct Effect Modeling. InProceedings of the 40th International Conference on Machine Learning (ICML) (Proceedings of Machine Learning Research, Vol. 202). PMLR, Honolulu, HI, USA, 29734–29759
2023
-
[31]
Yuta Saito, Takuma Udagawa, Haruka Kiyohara, Kazuki Mogi, Yusuke Narita, and Kei Tateno. 2021. Evaluating the Robustness of Off-Policy Evaluation. In Proceedings of the 15th ACM Conference on Recommender Systems (RecSys). 114–
2021
-
[32]
doi:10.1145/3460231.3474245
-
[33]
Tobias Schnabel, Adith Swaminathan, Ashudeep Singh, Navin Chandak, and Thorsten Joachims. 2016. Recommendations as Treatments: Debiasing Learning and Evaluation. InProceedings of the 33rd International Conference on Machine Learning (ICML) (Proceedings of Machine Learning Research, Vol. 48). PMLR, 1670– 1679
2016
-
[34]
Yi Su, Maria Dimakopoulou, Akshay Krishnamurthy, and Miroslav Dudík. 2020. Doubly Robust Off-Policy Evaluation with Shrinkage. InProceedings of the 37th International Conference on Machine Learning (ICML). PMLR
2020
-
[35]
Adith Swaminathan and Thorsten Joachims. 2015. Batch Learning from Logged Bandit Feedback through Counterfactual Risk Minimization.Journal of Machine Learning Research16, 52 (2015), 1731–1755
2015
-
[36]
Adith Swaminathan and Thorsten Joachims. 2015. Counterfactual Risk Min- imization: Learning from Logged Bandit Feedback. InProceedings of the 32nd International Conference on Machine Learning (ICML) (Proceedings of Machine Learning Research, Vol. 37). PMLR, Lille, France, 814–823
2015
-
[37]
Adith Swaminathan and Thorsten Joachims. 2015. The Self-Normalized Estima- tor for Counterfactual Learning. InAdvances in Neural Information Processing Systems
2015
-
[38]
Adith Swaminathan, Akshay Krishnamurthy, Alekh Agarwal, Miroslav Dudík, John Langford, Damien Jose, and Imed Zitouni. 2017. Off-Policy Evaluation for Slate Recommendation. InAdvances in Neural Information Processing Systems, Vol. 30. Curran Associates, Inc., Red Hook, NY, USA, 3632–3642
2017
-
[39]
Nikos Vlassis, Ashok Chandrashekar, Fernando Amat Gil, and Nathan Kallus
-
[40]
InAdvances in Neural Information Processing Systems, Vol
Control Variates for Slate Off-Policy Evaluation. InAdvances in Neural Information Processing Systems, Vol. 34. Curran Associates, Inc., Red Hook, NY, USA, 3667–3679
-
[41]
Peiyao Wang, Zhan Shi, Amina Shabbeer, and Ben London. 2025. Off-Policy Evaluation of Candidate Generators in Two-Stage Recommender Systems. InProceedings of the 19th ACM Conference on Recommender Systems (Rec- Sys). Association for Computing Machinery, New York, NY, USA, 350–359. doi:10.1145/3705328.3748057
-
[42]
Xiaojie Wang, Rui Zhang, Yu Sun, and Jianzhong Qi. 2019. Doubly Robust Joint Learning for Recommendation on Data Missing Not at Random. InProceedings of the 36th International Conference on Machine Learning (ICML) (Proceedings of Machine Learning Research, Vol. 97). PMLR, Long Beach, CA, USA, 6638–6647
2019
-
[43]
Yu-Xiang Wang, Alekh Agarwal, and Miroslav Dudík. 2017. Optimal and Adap- tive Off-Policy Evaluation in Contextual Bandits. InProceedings of the 34th International Conference on Machine Learning (ICML) (Proceedings of Machine Learning Research, Vol. 70). PMLR, Sydney, NSW, Australia, 3589–3597. CASP: Support-Aware Offline Policy Selection for Two-Stage Re...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.