Recognition: unknown
Preserving Long-Tailed Expert Information in Mixture-of-Experts Tuning
Pith reviewed 2026-05-08 11:58 UTC · model grok-4.3
The pith
A new method for fine-tuning mixture-of-experts models preserves information from rarely activated experts using always-active condenser experts and bias-driven sparsification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
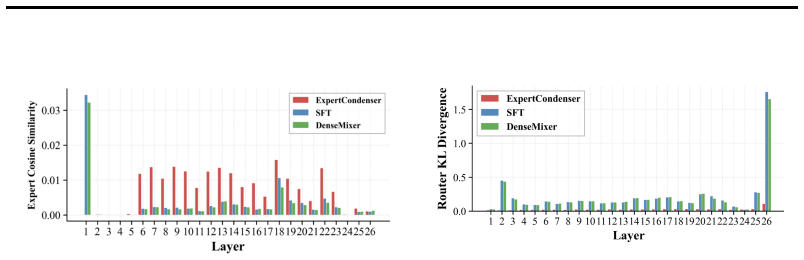
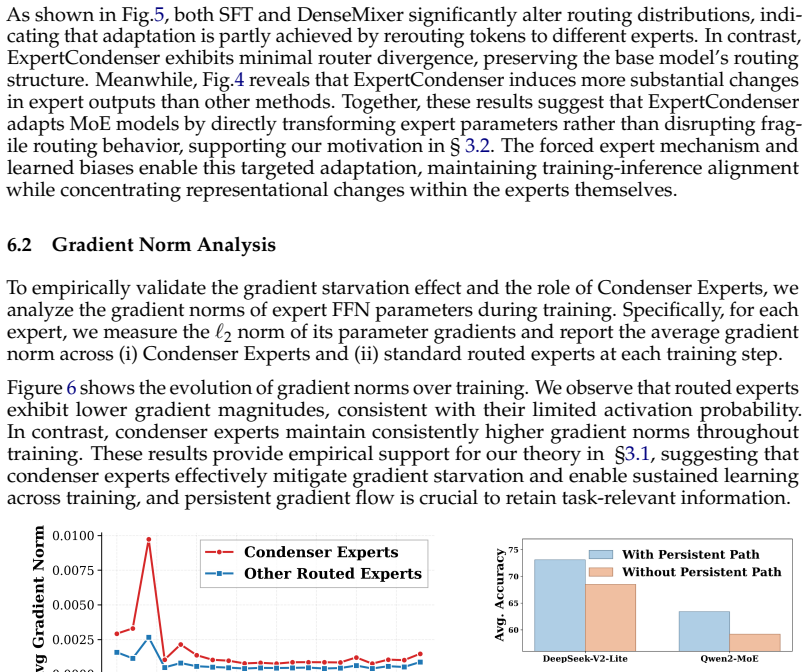
The framework encourages task-relevant experts to remain active while pushing long-tailed experts toward inactivity, with condenser experts providing a persistent pathway that alleviates gradient starvation and consolidates information that would otherwise stay fragmented across sparsely activated experts, leading to better preservation of long-tailed expert information under sparse routing.
What carries the argument
Always-active gated condenser experts combined with bias-driven sparsification, which together allow consolidation of long-tailed expert knowledge without enforcing balanced activation across all experts.
Load-bearing premise
Rarely activated experts hold useful non-trivial knowledge for the tasks, and the condenser experts can consolidate this without causing new performance or gradient issues.
What would settle it
Pruning the long-tailed experts from the fine-tuned model and observing no performance degradation on the benchmarks would show their information was not necessary.
Figures




read the original abstract
Despite MoE models leading many benchmarks, supervised fine-tuning (SFT) for the MoE architectures remains difficult because its router layers are fragile. Methods such as DenseMixer and ESFT mitigate router collapse with dense mixing or auxiliary load-balancing losses, but these introduce noisy gradients that often degrade performance. In preliminary experiments, we systematically pruned experts and observed that while certain super experts are activated far more frequently, discarding less used experts still leads to notable performance degradation. This suggests that even rarely activated experts encode non-trivial knowledge useful for downstream tasks. Motivated by this, we propose an auxiliary-loss-free MoE SFT framework that combines bias-driven sparsification with always-active gated condenser experts. Rather than enforcing balanced activation across all experts, our method encourages task-relevant experts to remain active while pushing long-tailed experts toward inactivity. The condenser experts provide a persistent, learnable pathway that alleviates gradient starvation and facilitates consolidation of information that would otherwise remain fragmented across sparsely activated experts. Analysis further suggest that this design better preserves long-tailed expert information under sparse routing. Experiments on large-scale MoE models demonstrate that our approach outperforms state-of-the-art SFT baselines such as DenseMixer and ESFT, achieving average gain of 2.5%+ on both mathematical reasoning and commonsenseQA benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an auxiliary-loss-free supervised fine-tuning framework for Mixture-of-Experts (MoE) models. It combines bias-driven sparsification, which encourages task-relevant experts to stay active while deactivating long-tailed ones, with always-active gated condenser experts that provide a persistent pathway to consolidate information from sparsely activated experts and mitigate gradient starvation. Motivated by preliminary pruning experiments showing performance drops when discarding rarely used experts, the method is evaluated on large-scale MoE models and claims to outperform baselines such as DenseMixer and ESFT by an average of more than 2.5% on mathematical reasoning and commonsense QA benchmarks.
Significance. If the empirical gains hold under rigorous controls, the work could meaningfully advance SFT practices for large MoE architectures by avoiding the noisy gradients of auxiliary balancing losses while explicitly addressing preservation of long-tailed expert knowledge. The condenser-expert design is a concrete, implementable contribution that directly targets router fragility. The paper earns credit for conducting experiments on large-scale models and for releasing (implicitly via the arXiv submission) a reproducible motivation via pruning studies, though the strength of those studies remains open to verification.
major comments (3)
- [Abstract / §4] Abstract and §4 (Experiments): The central motivation rests on pruning experiments where discarding less-activated experts degrades downstream performance, interpreted as evidence that these experts encode non-trivial task-relevant knowledge. However, because pruning simultaneously reduces total parameter count and model capacity, the observed degradation does not isolate expert-specific information from a simple reduction in expressivity. A control that prunes randomly selected experts while preserving total capacity (or matches parameter count via other means) is required to substantiate the claim that long-tailed experts carry irreplaceable information.
- [§3] §3 (Proposed Method): The integration of bias-driven sparsification with the always-active gated condenser experts is described at a high level, but the precise formulation of the bias term, the gating function for the condensers, and how gradients flow through the always-active pathway during back-propagation are not fully specified. Without these equations or pseudocode, it is difficult to verify that the design indeed avoids gradient starvation while preserving the claimed consolidation effect.
- [§4] §4 (Results): The reported average gain of 2.5%+ over DenseMixer and ESFT on mathematical reasoning and commonsense QA benchmarks lacks accompanying details on model sizes, number of independent runs, statistical significance testing, variance across seeds, and exact hyper-parameter settings for the baselines. These omissions make it impossible to assess whether the gains are robust or could be explained by differences in training compute or implementation details.
minor comments (2)
- [§3] Notation for the bias term and condenser gating should be introduced with explicit equations rather than prose descriptions to improve reproducibility.
- [§4] Figure captions and axis labels in the experimental plots would benefit from explicit mention of the number of experts, activation thresholds, and whether results are averaged over multiple seeds.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, with clear indications of planned revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract / §4] The central motivation rests on pruning experiments where discarding less-activated experts degrades downstream performance, interpreted as evidence that these experts encode non-trivial task-relevant knowledge. However, because pruning simultaneously reduces total parameter count and model capacity, the observed degradation does not isolate expert-specific information from a simple reduction in expressivity. A control that prunes randomly selected experts while preserving total capacity (or matches parameter count via other means) is required to substantiate the claim that long-tailed experts carry irreplaceable information.
Authors: We agree that the pruning experiments as currently presented do not fully isolate the contribution of long-tailed expert knowledge from the reduction in overall model capacity. In the revised manuscript, we will add a control experiment that randomly prunes an equivalent number of experts (matching the parameter reduction) and directly compares the resulting performance degradation against the long-tailed pruning case. This will strengthen the motivation by better substantiating that the observed drops stem from loss of task-relevant information rather than capacity alone. revision: yes
-
Referee: [§3] The integration of bias-driven sparsification with the always-active gated condenser experts is described at a high level, but the precise formulation of the bias term, the gating function for the condensers, and how gradients flow through the always-active pathway during back-propagation are not fully specified. Without these equations or pseudocode, it is difficult to verify that the design indeed avoids gradient starvation while preserving the claimed consolidation effect.
Authors: We acknowledge that the current description of the method in §3 is at a high level and lacks the necessary mathematical details. In the revised version, we will add the exact formulation of the bias term applied to router logits, the precise gating function and activation rule for the condenser experts, and a clear explanation of gradient flow through the always-active condenser pathway. We will also include pseudocode for the forward and backward passes to demonstrate how gradient starvation is mitigated. revision: yes
-
Referee: [§4] The reported average gain of 2.5%+ over DenseMixer and ESFT on mathematical reasoning and commonsense QA benchmarks lacks accompanying details on model sizes, number of independent runs, statistical significance testing, variance across seeds, and exact hyper-parameter settings for the baselines. These omissions make it impossible to assess whether the gains are robust or could be explained by differences in training compute or implementation details.
Authors: We will expand the experimental details in the revised §4 to include all requested information: the specific MoE model sizes and configurations, results averaged over multiple independent runs (with reported standard deviations), statistical significance testing (e.g., paired t-tests), variance across random seeds, and the complete hyper-parameter settings used for our method as well as the DenseMixer and ESFT baselines. These additions will enable proper assessment of robustness and reproducibility. revision: yes
Circularity Check
No circularity: empirical method proposal with external benchmark validation
full rationale
The paper introduces a new auxiliary-loss-free MoE SFT framework (bias-driven sparsification plus always-active condenser experts) motivated by the authors' own preliminary pruning experiments. These experiments are presented as empirical observations rather than a fitted model or self-referential definition. The central claims are performance gains (average +2.5% on math and commonsense benchmarks) measured against external baselines (DenseMixer, ESFT) on standard datasets. No equations, uniqueness theorems, or self-citations are invoked that reduce the method or results to the inputs by construction. The pruning observation is used only for motivation; the design itself is a novel architectural choice whose value is assessed by downstream evaluation, not by algebraic equivalence to the pruning data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MoE router layers are fragile during supervised fine-tuning
invented entities (1)
-
gated condenser experts
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Esft patch for qwen2 mixture-of-experts models
AWS Samples . Esft patch for qwen2 mixture-of-experts models. https://github.com/aws-samples/sample-ESFT/blob/main/model_patch/patch_qwen2_moe.py, 2024. GitHub repository, accessed March 2026
2024
-
[2]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation, 2013. URL https://arxiv.org/abs/1308.3432
work page internal anchor Pith review arXiv 2013
-
[3]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review arXiv 2021
-
[4]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23 0 (120): 0 1--39, 2022
2022
-
[5]
Accelerate: Training and inference at scale made simple, efficient and adaptable
Sylvain Gugger, Lysandre Debut, Thomas Wolf, Philipp Schmid, Zachary Mueller, Sourab Mangrulkar, Marc Sun, and Benjamin Bossan. Accelerate: Training and inference at scale made simple, efficient and adaptable. https://github.com/huggingface/accelerate, 2022
2022
-
[6]
Lighteval: A lightweight framework for llm evaluation, 2023
Nathan Habib, Clémentine Fourrier, Hynek Kydlíček, Thomas Wolf, and Lewis Tunstall. Lighteval: A lightweight framework for llm evaluation, 2023. URL https://github.com/huggingface/lighteval
2023
-
[7]
Sparse matrix in large language model fine-tuning
Haoze He, Juncheng Billy Li, Xuan Jiang, and Heather Miller. Sparse matrix in large language model fine-tuning. arXiv preprint arXiv:2405.15525, 2024
-
[8]
Learning to solve arithmetic word problems with verb categorization
Mohammad Javad Hosseini, Hannaneh Hajishirzi, Oren Etzioni, and Nate Kushman. Learning to solve arithmetic word problems with verb categorization. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.\ 523--533, 2014
2014
-
[9]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021. URL https://arxiv.org/abs/2106.09685
work page internal anchor Pith review arXiv 2021
-
[10]
Llm-adapters: An adapter family for parameter-efficient fine- tuning of large language models,
Zhiqiang Hu, Lei Wang, Yihuai Lan, Wanyu Xu, Ee-Peng Lim, Lidong Bing, Xing Xu, Soujanya Poria, and Roy Ka-Wei Lee. Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language models. arXiv preprint arXiv:2304.01933, 2023
-
[11]
Sft trainer implementation in trl
Hugging Face . Sft trainer implementation in trl. https://github.com/huggingface/trl/blob/main/trl/trainer/sft_trainer.py, 2024. GitHub repository, accessed March 2026
2024
-
[12]
Parsing algebraic word problems into equations
Rik Koncel-Kedziorski, Hannaneh Hajishirzi, Ashish Sabharwal, Oren Etzioni, and Siena Dumas Ang. Parsing algebraic word problems into equations. Transactions of the Association for Computational Linguistics, 3: 0 585--597, 2015
2015
-
[13]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[14]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668, 2020
work page internal anchor Pith review arXiv 2006
-
[15]
Program induction by rationale generation: Learning to solve and explain algebraic word problems
Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. Program induction by rationale generation: Learning to solve and explain algebraic word problems. arXiv preprint arXiv:1705.04146, 2017
-
[16]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024 a
work page internal anchor Pith review arXiv 2024
-
[17]
Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model
An Liu, Bing Feng, Bo Wang, and Bo Wang. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv preprint arXiv:2406.01952, 2024 b
-
[18]
F., Cheng, K.-T., and Chen, M.-H
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation, 2024 c . URL https://arxiv.org/abs/2402.09353
-
[19]
Xudong Lu, Qi Liu, Yuhui Xu, Aojun Zhou, Siyuan Huang, Bo Zhang, Junchi Yan, and Hongsheng Li. Not all experts are equal: Efficient expert pruning and skipping for mixture-of-experts large language models. arXiv preprint arXiv:2402.14800, 2024
-
[20]
Smith, Pang Wei Koh, Amanpreet Singh, and Hannaneh Hajishirzi
Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, and Hannaneh Hajishirzi. O...
-
[21]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling, 2025. URL https://arxiv.org/abs/2501.19393
work page internal anchor Pith review arXiv 2025
-
[22]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI. gpt-oss-120b & gpt-oss-20b model card, 2025. URL https://arxiv.org/abs/2508.10925
work page internal anchor Pith review arXiv 2025
-
[23]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are NLP models really able to solve simple math word problems? In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou (eds.), Proceedings of the 2021 Conference of the North American Chapter of the Associa...
-
[24]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA : A graduate-level google-proof q&a benchmark. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=Ti67584b98
2024
-
[25]
arXiv:2101.06840 [cs.DC]https://arxiv.org/abs/2101.06840
Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyang Yang, Minjia Zhang, Dong Li, and Yuxiong He. Zero-offload: Democratizing billion-scale model training. ArXiv, abs/2101.06840, 2021. URL https://arxiv.org/abs/2101.06840
-
[26]
Solving general arithmetic word problems
Subhro Roy and Dan Roth. Solving general arithmetic word problems. arXiv preprint arXiv:1608.01413, 2016
-
[27]
Unveiling super experts in mixture-of-experts large language models,
Zunhai Su, Qingyuan Li, Hao Zhang, YuLei Qian, Yuchen Xie, and Kehong Yuan. Unveiling super experts in mixture-of-experts large language models. arXiv preprint arXiv:2507.23279, 2025
-
[28]
Trl: Transformer reinforcement learning
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. Trl: Transformer reinforcement learning. https://github.com/huggingface/trl, 2020
2020
-
[29]
Auxiliary-loss-free load balancing strategy for mixture-of-experts.arXiv preprint arXiv:2408.15664,
Lean Wang, Huazuo Gao, Chenggang Zhao, Xu Sun, and Damai Dai. Auxiliary-loss-free load balancing strategy for mixture-of-experts. arXiv preprint arXiv:2408.15664, 2024 a
-
[30]
Zihan Wang, Deli Chen, Damai Dai, Runxin Xu, Zhuoshu Li, and Yu Wu. Let the expert stick to his last: Expert-specialized fine-tuning for sparse architectural large language models. arXiv preprint arXiv:2407.01906, 2024 b
-
[31]
arXiv preprint arXiv:2512.24880 , year=
Zhenda Xie, Yixuan Wei, Huanqi Cao, Chenggang Zhao, Chengqi Deng, Jiashi Li, Damai Dai, Huazuo Gao, Jiang Chang, Kuai Yu, et al. mhc: Manifold-constrained hyper-connections. arXiv preprint arXiv:2512.24880, 2025
-
[32]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfeng ...
work page internal anchor Pith review arXiv 2024
-
[33]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review arXiv 2025
-
[34]
Densemixer: Improving moe post-training with precise router gradient, June 2025
Feng Yao, Junxia Cui, Ruohan Zhang, Liyuan Liu, Shibo Hao, Li Zhang, Chengyu Dong, Shuohang Wang, Yelong Shen, Jianfeng Gao, and Jingbo Shang. Densemixer: Improving moe post-training with precise router gradient, June 2025. URL https://fengyao.notion.site/moe-posttraining
2025
-
[35]
Super weights: The hidden powerhouses of large language models.arXiv preprint arXiv:2411.07191,
Mengxia Yu, De Wang, Qi Shan, Colorado Reed, and Alvin Wan. The super weight in large language models, 2025. URL https://arxiv.org/abs/2411.07191
-
[36]
arXiv preprint arXiv:2409.19606 , year=
Defa Zhu, Hongzhi Huang, Zihao Huang, Yutao Zeng, Yunyao Mao, Banggu Wu, Qiyang Min, and Xun Zhou. Hyper-connections. arXiv preprint arXiv:2409.19606, 2024
-
[37]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[38]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[39]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[40]
)R?m? l ?2ɰ߭ - . ,[ S&Ցrt 6`y_gpfu
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.