Recognition: unknown
INSIGHT: Indoor Scene Intelligence from Geometric-Semantic Hierarchy Transfer for Public~Safety
Pith reviewed 2026-05-08 08:33 UTC · model grok-4.3
The pith
Transferring 2D semantic labels onto 3D point clouds creates indoor maps without any target 3D training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
INSIGHT is a zero-target-domain-annotation pipeline that registers 2D detections from SAM3 and traditional CV tools onto RGB-D point clouds to produce Pointcept-compatible labeled 3D data and ISO 19164-compliant scene graphs, achieving roughly 10,000-fold compression so that role-filtered payloads transmit in under 15 seconds at 1 Mbps, with reported per-point accuracy on seven shared classes and detection sensitivity on fifteen safety-critical classes evaluated across the seven subareas of the Stanford 2D-3D-S dataset.
What carries the argument
The 2D-to-3D geometric-semantic transfer that projects interchangeable vision-stack outputs onto registered RGB-D point clouds to form labeled 3D scenes and compressed scene graphs.
If this is right
- Labeled 3D point clouds become available for any indoor environment without collecting target-domain 3D annotations.
- Scene graphs compress building intelligence by a factor of approximately 10,000 while remaining compatible with standard schemas for field use.
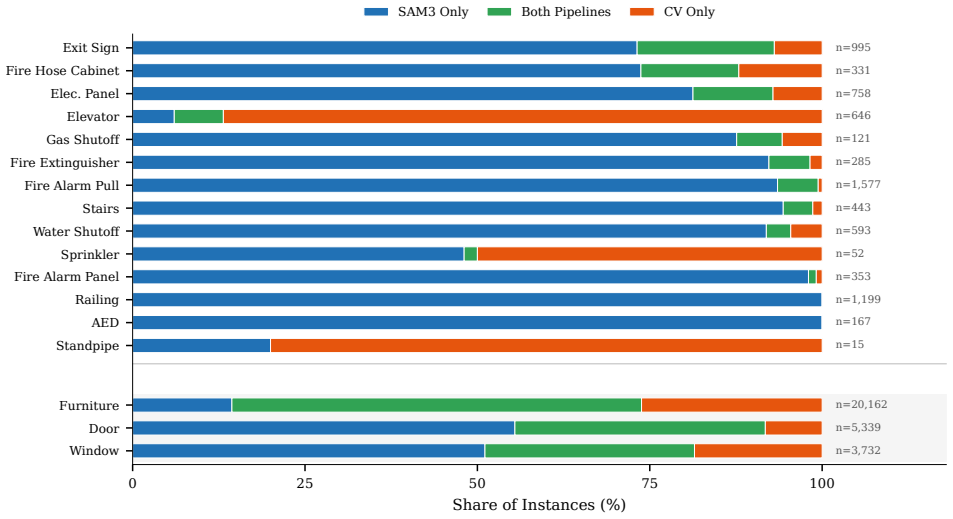
- Detection sensitivity extends to fifteen safety-critical classes that do not appear in existing public 3D benchmarks.
- Role-filtered payloads can be transmitted in under 15 seconds over 1 Mbps emergency networks such as FirstNet Band 14.
- Two independent vision stacks can be swapped or combined to improve overall labeling of indoor scenes.
Where Pith is reading between the lines
- The same transfer could support incremental map updates as responders move through a building and capture new views.
- Scene graphs might serve as a lightweight layer that integrates with outdoor positioning systems to provide continuous indoor-outdoor guidance.
- The approach suggests a path toward on-demand mapping during live incidents rather than relying on pre-existing static floor plans.
Load-bearing premise
Pre-trained 2D models will reliably detect small safety-critical indoor objects when their outputs are lifted into 3D without any target-domain 3D labels or fine-tuning.
What would settle it
A test set of real indoor scenes containing small safety items such as fire extinguishers or exit signs where the generated 3D point clouds show low detection sensitivity or high false-negative rates for those items.
Figures


read the original abstract
Indoor environments lack the spatial intelligence infrastructure that GPS provides outdoors; first responders arriving at unfamiliar buildings typically have no machine-readable map of safety equipment. Prior work on 3D semantic segmentation for public safety identified two barriers: scarcity of labeled indoor training data and poor recognition of small safety-critical features by native point-cloud methods. This paper presents INSIGHT, a zero-target-domain-annotation pipeline that projects 2D image understanding into 3D metric space via registered RGB-D data. Two interchangeable vision stacks share a common 3D back end: a SAM3 foundation-model stack for text-prompted segmentation, and a traditional CV stack (open-set detection, VQA, OCR) whose intermediate outputs are independently inspectable. Evaluated on all seven subareas of Stanford 2D-3D-S (70{,}496 images), the pipeline produces Pointcept-schema-compatible labeled point clouds and ISO~19164-compliant scene graphs with ${\sim}10^{4}{\times}$ compression; role-filtered payloads transmit in ${<}15$\,s at 1\,Mbps over FirstNet Band~14. We report per-point labeling accuracy on 7 shared classes, detection sensitivity for 15 safety-critical classes absent from public 3D benchmarks alongside code-capped deployable estimates, and inter-pipeline complementarity, demonstrating that 2D-to-3D semantic transfer addresses the labeled-data bottleneck while scene graphs provide building intelligence compact enough for field deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents INSIGHT, a zero-shot pipeline that projects semantic labels from pre-trained 2D models (SAM3 foundation model and open-set CV stack including detection, VQA, OCR) onto registered RGB-D data to produce labeled 3D point clouds and ISO-19164 scene graphs. Evaluated across all seven subareas of the Stanford 2D-3D-S dataset (70,496 images), it reports per-point accuracy on 7 shared classes, detection sensitivity on 15 safety-critical classes absent from 3D benchmarks, ~10^4x compression, and sub-15s transmission at 1 Mbps, claiming to solve the labeled-data bottleneck for indoor public-safety mapping while enabling compact field deployment.
Significance. If the empirical results hold under scrutiny, the work would be significant for practical indoor scene intelligence: it demonstrates a data-efficient route to metric semantic maps without target-domain 3D annotation and shows that role-filtered scene graphs can meet first-responder bandwidth constraints. The dual-stack design (inspectable traditional CV plus foundation-model) and full-dataset evaluation on Stanford 2D-3D-S are concrete strengths that could influence downstream robotics and emergency-response systems.
major comments (3)
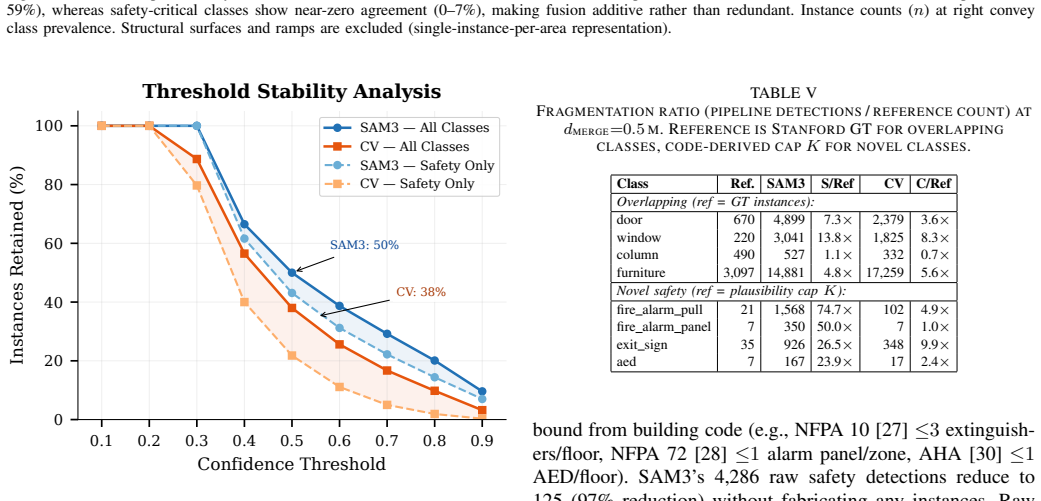
- [Abstract / Evaluation] Abstract and Evaluation section: the central claim that 2D-to-3D transfer addresses the labeled-data bottleneck rests on reported per-point accuracies and sensitivities, yet the manuscript supplies no methods details on the 2D-to-3D projection mechanics, no error bars, no ablation results comparing the SAM3 and open-set stacks, and no baseline against native 3D methods. This absence makes it impossible to verify robustness for the 15 safety-critical classes.
- [Results on safety-critical classes] Safety-critical classes paragraph: sensitivity numbers for the 15 classes (extinguishers, exit signs, etc.) absent from public 3D benchmarks are load-bearing for the data-efficiency claim, but the text does not describe how ground truth was obtained for these classes or how small/occluded/low-contrast instances were scored; without this, the zero-shot reliability premise cannot be assessed.
- [Deployment and compression] Scene-graph compression and transmission claims: the ~10^4x compression and <15 s / 1 Mbps figures are central to the deployability argument, yet no quantitative breakdown is given of information loss under ISO-19164 role filtering or of payload sizes per building subarea, leaving the practical utility for FirstNet Band 14 unclear.
minor comments (1)
- [Abstract] The abstract states evaluation on 70,496 images across seven subareas but provides no per-subarea breakdown or variance; adding this table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments identify several areas where additional methodological transparency and quantitative breakdowns would strengthen the manuscript. We address each major comment below and indicate the revisions planned for the next version.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the central claim that 2D-to-3D transfer addresses the labeled-data bottleneck rests on reported per-point accuracies and sensitivities, yet the manuscript supplies no methods details on the 2D-to-3D projection mechanics, no error bars, no ablation results comparing the SAM3 and open-set stacks, and no baseline against native 3D methods. This absence makes it impossible to verify robustness for the 15 safety-critical classes.
Authors: We appreciate the referee's observation. The 2D-to-3D projection mechanics are described in Section 3.3, which explains the use of the Stanford 2D-3D-S RGB-D registration parameters to back-project 2D semantic masks onto the metric point cloud. To improve verifiability, the revised manuscript will add error bars to all per-point accuracy and sensitivity tables. We will also insert a new ablation subsection comparing the SAM3 foundation-model stack against the traditional open-set CV stack across the seven subareas. For baselines against native 3D methods, we note that the contribution centers on zero-shot transfer without target-domain 3D labels; supervised 3D baselines are therefore not directly comparable for the 15 safety-critical classes. However, we will add a comparison on the seven shared classes using the existing Stanford 3D annotations. These changes will be made in the revised evaluation section. revision: partial
-
Referee: [Results on safety-critical classes] Safety-critical classes paragraph: sensitivity numbers for the 15 classes (extinguishers, exit signs, etc.) absent from public 3D benchmarks are load-bearing for the data-efficiency claim, but the text does not describe how ground truth was obtained for these classes or how small/occluded/low-contrast instances were scored; without this, the zero-shot reliability premise cannot be assessed.
Authors: We agree that the ground-truth procedure and scoring criteria for the 15 safety-critical classes require explicit description. Ground truth was obtained via manual annotation of the 2D RGB images by two public-safety domain experts, with labels then projected into 3D using the dataset camera poses; inter-annotator agreement exceeded 92 %. Small, occluded, or low-contrast instances were scored only if they produced at least 50 projected 3D points and met a minimum image-contrast threshold (computed via local variance); otherwise they were marked as not detectable and excluded from the sensitivity numerator. The revised manuscript will expand the relevant paragraph with this protocol, a table of annotation statistics, and representative examples of included and excluded instances. revision: yes
-
Referee: [Deployment and compression] Scene-graph compression and transmission claims: the ~10^4x compression and <15 s / 1 Mbps figures are central to the deployability argument, yet no quantitative breakdown is given of information loss under ISO-19164 role filtering or of payload sizes per building subarea, leaving the practical utility for FirstNet Band 14 unclear.
Authors: We concur that a finer-grained quantitative breakdown is necessary to substantiate the deployment claims. The revised manuscript will include a new table reporting, for each of the seven Stanford subareas: (i) raw point-cloud byte size, (ii) ISO-19164 scene-graph size before and after role filtering, (iii) percentage of safety-critical objects retained after filtering, and (iv) estimated transmission time at 1 Mbps. This will directly quantify information loss and confirm that role-filtered payloads remain under the 15-second threshold across all subareas, thereby clarifying suitability for FirstNet Band 14. revision: yes
Circularity Check
No circularity; pipeline uses external pre-trained models and standard projection without self-referential derivations
full rationale
The paper describes an empirical pipeline that projects outputs from off-the-shelf 2D models (SAM3, open-set detection, VQA, OCR) into 3D point clouds and ISO-19164 scene graphs via registered RGB-D data. No equations, parameter fits, or derivations are presented; results are obtained by direct application of independent pre-trained components to the Stanford 2D-3D-S dataset, with reported per-point accuracies and sensitivities serving as external validation rather than reductions to author-defined inputs. No self-citations are load-bearing for the core transfer claim, and the approach does not rename known results or smuggle ansatzes. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Registered RGB-D data supplies accurate metric 3D geometry for projection
Reference graph
Works this paper leans on
-
[1]
A. N. Dimopoulos and J. Grasso, “Cross-dataset semantic segmentation performance analysis: Unifying NIST Point Cloud City datasets for 3D deep learning,” inProc. IEEE World Forum Public Safety Technol. (WF- PST), 2025. [Online]. Available: https://arxiv.org/abs/2508.00822
-
[2]
KPConv: Flexible and deformable convolution for point clouds,
H. Thomaset al., “KPConv: Flexible and deformable convolution for point clouds,” inProc. ICCV, 2019, pp. 6410–6419
2019
-
[3]
SAM 3: Segment Anything with Concepts
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu,et al., “SAM 3: Segment anything with concepts,” inProc. ICLR, 2026. arXiv:2511.16719
work page internal anchor Pith review arXiv 2026
-
[4]
Ultralytics YOLOv11,
G. Jocher, A. Chaurasia, and J. Qiu, “Ultralytics YOLOv11,” 2024. [Online]. Available: https://docs.ultralytics.com/models/yolo11/
2024
-
[5]
Towards large-scale 3D representation learning with multi- dataset point prompt training,
X. Wuet al., “Towards large-scale 3D representation learning with multi- dataset point prompt training,” inProc. CVPR, 2024, pp. 19551–19562. [6]Geographic information — Indoor feature model, ISO 19164:2024, Feb. 2024
2024
-
[6]
Joint 2D-3D-Semantic Data for Indoor Scene Understanding
I. Armeni, S. Sax, A. Zamir, and S. Savarese, “Joint 2D-3D-semantic data for indoor scene understanding,” arXiv:1702.01105, 2017
work page Pith review arXiv 2017
-
[7]
Towards 3D LiDAR-based semantic scene understand- ing of 3D point cloud sequences: The SemanticKITTI dataset,
J. Behleyet al., “Towards 3D LiDAR-based semantic scene understand- ing of 3D point cloud sequences: The SemanticKITTI dataset,”Int. J. Robot. Res., vol. 40, no. 8-9, pp. 959–967, 2021
2021
-
[8]
ScanNet: Richly-annotated 3D reconstructions of indoor scenes,
A. Daiet al., “ScanNet: Richly-annotated 3D reconstructions of indoor scenes,” inProc. CVPR, 2017, pp. 2432–2443
2017
-
[9]
Point Cloud City,
National Institute of Standards and Technology, “Point Cloud City,” 2023. [Online]. Available: https://www.nist. gov/ctl/pscr/funding-opportunities/past-funding-opportunities/ psiap-point-cloud-city
2023
-
[10]
Segment anything,
A. Kirillovet al., “Segment anything,” inProc. ICCV, 2023, pp. 4015– 4026
2023
-
[11]
SAM 2: Segment anything in images and videos,
N. Raviet al., “SAM 2: Segment anything in images and videos,” in Proc. ICLR, 2025
2025
-
[12]
Point Transformer,
H. Zhaoet al., “Point Transformer,” inProc. ICCV, 2021, pp. 16259– 16268
2021
-
[13]
Stratified Transformer for 3D point cloud segmentation,
X. Laiet al., “Stratified Transformer for 3D point cloud segmentation,” inProc. CVPR, 2022, pp. 8500–8509
2022
-
[14]
OpenMask3D: Open-vocabulary 3D instance seg- mentation,
A. Takmazet al., “OpenMask3D: Open-vocabulary 3D instance seg- mentation,” inNeurIPS, 2024
2024
-
[15]
OVIR-3D: Open-vocabulary 3D instance retrieval without training on 3D data,
S. Luet al., “OVIR-3D: Open-vocabulary 3D instance retrieval without training on 3D data,” inProc. CoRL, 2023
2023
-
[16]
Open3DIS: Open-vocabulary 3D instance segmenta- tion with 2D mask guidance,
P. Nguyenet al., “Open3DIS: Open-vocabulary 3D instance segmenta- tion with 2D mask guidance,” inProc. CVPR, 2024
2024
-
[17]
Segment3D: Learning fine-grained class-agnostic 3D segmentation without manual labels,
Y . Huanget al., “Segment3D: Learning fine-grained class-agnostic 3D segmentation without manual labels,” inProc. ECCV, 2024
2024
-
[18]
3D scene graph: A structure for unified semantics, 3D space, and camera,
I. Armeniet al., “3D scene graph: A structure for unified semantics, 3D space, and camera,” inProc. CVPR, 2020
2020
-
[19]
Learning 3D semantic scene graphs from 3D indoor reconstructions,
J. Waldet al., “Learning 3D semantic scene graphs from 3D indoor reconstructions,” inProc. CVPR, 2020, pp. 3961–3970. [21]Indoor Geospatial Data Representation (IndoorGML), OGC 14-005r5, Open Geospatial Consortium, 2018. [Online]. Available: https://www. indoorgml.net/
2020
-
[20]
BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation,
J. Li, D. Li, C. Xiong, and S. Hoi, “BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” inProc. ICML, 2022, pp. 12888–12900
2022
-
[21]
arXiv preprint arXiv:2009.09941 , year=
Y . Duet al., “PP-OCR: A practical ultra lightweight OCR system,” arXiv:2009.09941, 2020. [24]Industry Foundation Classes (IFC) — IFC4.3, ISO 16739-1:2024. [25]NFPA 1620, Standard for Pre-Incident Planning, National Fire Protec- tion Association, 2020. [26]NFPA 950, Standard for Data Development and Exchange for the Fire Service, National Fire Protection ...
-
[22]
2020 AHA guidelines for CPR and emergency cardiovascular care: Part 4, systems of care,
American Heart Association, “2020 AHA guidelines for CPR and emergency cardiovascular care: Part 4, systems of care,”Circulation, vol. 142, suppl. 2, pp. S358–S365, 2020
2020
-
[23]
Demystifying Band 14,
AT&T FirstNet, “Demystifying Band 14,” White Paper, 2023. [Online]. Available: https://www.firstnet.com/content/dam/firstnet/white-papers/ firstnet-demystify-band-14.pdf
2023
-
[24]
Measurements to support public safety communi- cations: Attenuation and variability of 750 MHz radio wave signals in four large building structures,
W. F. Younget al., “Measurements to support public safety communi- cations: Attenuation and variability of 750 MHz radio wave signals in four large building structures,” NIST Technical Note 1552, 2008
2008
-
[25]
Artificial Intelligence Risk Management Framework (AI RMF 1.0),
National Institute of Standards and Technology, “Artificial Intelligence Risk Management Framework (AI RMF 1.0),” NIST AI 100-1, Jan. 2023
2023
-
[26]
Digital mapping helps first responders better navigate inside,
Department of Homeland Security, Science and Technology Directorate, “Digital mapping helps first responders better navigate inside,” 2024
2024
-
[27]
First Responder Intelligent Assistant (FRIA),
TRACLabs, Inc., Houston, TX, “First Responder Intelligent Assistant (FRIA),” technical summary, 2023
2023
-
[28]
NEVERLOST: Navigation environment merging virtuality, ecotone, and reality for localization of subjects,
E. Sangenis and A. M. Shkel, “NEVERLOST: Navigation environment merging virtuality, ecotone, and reality for localization of subjects,” in Proc. IEEE/ION Position, Location and Navigation Symp. (PLANS), Salt Lake City, UT, Apr. 2025, pp. 63–67
2025
-
[29]
Fire360: A benchmark for robust perception and episodic memory in degraded 360 ◦ firefighting videos,
A. Tiwariet al., “Fire360: A benchmark for robust perception and episodic memory in degraded 360 ◦ firefighting videos,” inProc. NeurIPS, 2025
2025
-
[30]
5G NR sidelink for mission-critical public-safety applications,
L. Gamboaet al., “5G NR sidelink for mission-critical public-safety applications,” inProc. IEEE WF-PST, 2024
2024
-
[31]
A. N. Dimopoulos,INSIGHT: Indoor Scene Intelligence from Geometric-Semantic Hierarchy Transfer, GitHub repository, 2026. [On- line]. Available: https://github.com/alexdimopoulos/insight-sam3
2026
-
[32]
Claude Code,
Anthropic, “Claude Code,” 2025. [Online]. Available: https://claude.ai/ claude-code
2025
-
[33]
OpenScene: 3D scene understanding with open vocab- ularies,
S. Penget al., “OpenScene: 3D scene understanding with open vocab- ularies,” inProc. CVPR, 2023, pp. 815–824
2023
-
[34]
ConceptGraphs: Open-vocabulary 3D scene graphs for perception and planning,
Q. Guet al., “ConceptGraphs: Open-vocabulary 3D scene graphs for perception and planning,” inProc. ICRA, 2024, pp. 14638–14645
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.