Recognition: unknown
Mixture of Heterogeneous Grouped Experts for Language Modeling
Pith reviewed 2026-05-08 08:25 UTC · model grok-4.3
The pith
Mixture of Heterogeneous Grouped Experts matches standard MoE performance with roughly 20 percent fewer total parameters and balanced GPU utilization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
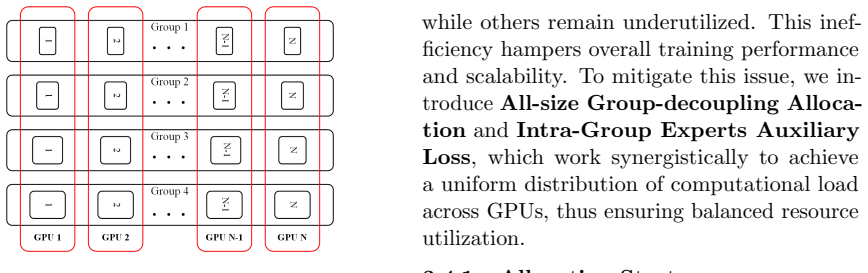
Mixture of Heterogeneous Grouped Experts (MoHGE) employs a two-level routing mechanism that permits flexible combinations of experts with different sizes. A Group-Wise Auxiliary Loss directs tokens toward parameter-efficient groups according to difficulty, while an All-size Group-decoupling Allocation paired with an Intra-Group Experts Auxiliary Loss enforces uniform GPU distribution. Evaluations show this matches conventional MoE accuracy, cuts parameters by approximately 20 percent, and achieves balanced utilization across devices.
What carries the argument
The two-level routing mechanism together with the Group-Wise Auxiliary Loss for efficiency, the Intra-Group Experts Auxiliary Loss for balance, and the All-size Group-decoupling Allocation strategy.
If this is right
- Language models can achieve the same task performance with a smaller overall parameter count.
- GPU resources are used more evenly during both training and inference, reducing bottlenecks.
- The routing allows adaptation to varying token complexities without manual expert sizing.
- Deployment becomes more feasible on standard hardware clusters due to the load-balancing mechanisms.
Where Pith is reading between the lines
- This structured grouping could be adapted to other sparse activation methods in neural networks.
- Parameter savings might compound when combined with quantization or pruning techniques.
- Testing on non-language tasks like vision could reveal if the heterogeneity benefits transfer beyond text.
Load-bearing premise
The auxiliary losses and group allocation can be optimized together to deliver the reported parameter savings and perfect balance without introducing instability or performance losses on downstream tasks.
What would settle it
A controlled experiment retraining an MoHGE model without one of the auxiliary losses and measuring whether parameter count rises above the 20 percent reduction or GPU utilization becomes unbalanced while accuracy stays the same would test the necessity of those components.
Figures


read the original abstract
Large Language Models (LLMs) based on Mixture-of-Experts (MoE) are pivotal in industrial applications for their ability to scale performance efficiently. However, standard MoEs enforce uniform expert sizes,creating a rigidity that fails to align computational costs with varying token-level complexity. While heterogeneous expert architectures attempt to address this by diversifying expert sizes, they often suffer from significant system-level challenges, specifically unbalanced GPU utilization and inefficient parameter utilization, which hinder practical deployment. To bridge the gap between theoretical heterogeneity and robust industrial application, we propose Mixture of Heterogeneous Grouped Experts (MoHGE) which introduces a two-level routing mechanism to enable flexible, resource-aware expert combinations. To optimize inference efficiency, we propose a Group-Wise Auxiliary Loss, which dynamically steers tokens to the most parameter-efficient expert groups based on task difficulty. To address the critical deployment challenge of GPU load balancing, we introduce an All-size Group-decoupling Allocation strategy coupled with an Intra-Group Experts Auxiliary Loss. These mechanisms collectively ensure uniform computation distribution across GPUs. Extensive evaluations demonstrate that MoHGE matches the performance of MoE architectures while reducing the total parameters by approximately 20% and maintaining balanced GPU utilization. Our work establishes a scalable paradigm for resource-efficient MoE design, offering a practical solution for optimizing inference costs in real-world scenarios. The code is publicly available at https://github.com/UnicomAI/MoHGE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Mixture of Heterogeneous Grouped Experts (MoHGE) as an extension to standard Mixture-of-Experts (MoE) architectures for LLMs. It introduces a two-level routing mechanism to support heterogeneous expert sizes, along with a Group-Wise Auxiliary Loss to steer tokens toward parameter-efficient groups, an Intra-Group Experts Auxiliary Loss, and an All-size Group-decoupling Allocation strategy to enforce GPU load balance. The central empirical claim is that MoHGE matches the performance of conventional MoE models while reducing total parameters by approximately 20% and maintaining uniform GPU utilization.
Significance. If the empirical claims are substantiated with detailed metrics and ablations, the work would address a practical deployment gap in heterogeneous MoE designs by improving parameter efficiency and load balance without sacrificing performance. The public code release at https://github.com/UnicomAI/MoHGE is a positive factor for reproducibility.
major comments (2)
- [Abstract] Abstract: the claim of matching MoE performance at ~20% lower total parameters is presented without any concrete metrics, baselines, datasets, or error bars, preventing assessment of whether the reduction is robust or the result of post-hoc selection.
- [Evaluation] Evaluation section (implied by the abstract's reference to 'extensive evaluations'): the joint tuning of Group-Wise Auxiliary Loss, Intra-Group Experts Auxiliary Loss, and All-size Group-decoupling Allocation is asserted to deliver both parameter reduction and perfect load balance, yet no coefficient sweeps, sensitivity tests, or Pareto curves are referenced to rule out hidden trade-offs between specialization, stability, and the three objectives.
minor comments (1)
- [Abstract] Abstract: the phrasing 'matches the performance of MoE architectures' is vague; specifying the exact MoE baseline (e.g., Switch Transformer or Mixtral) and the evaluation tasks would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment point by point below. Where revisions are needed to strengthen the manuscript, we commit to incorporating them in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of matching MoE performance at ~20% lower total parameters is presented without any concrete metrics, baselines, datasets, or error bars, preventing assessment of whether the reduction is robust or the result of post-hoc selection.
Authors: We agree that the abstract is currently high-level and would benefit from greater specificity. In the revised manuscript we will update the abstract to include concrete details such as the primary benchmark (C4), the exact performance metric (perplexity) where MoHGE matches the baseline MoE, the reported 20% parameter reduction, and a brief note on the number of runs. This change will make the central claim directly verifiable from the abstract while remaining within length constraints. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by the abstract's reference to 'extensive evaluations'): the joint tuning of Group-Wise Auxiliary Loss, Intra-Group Experts Auxiliary Loss, and All-size Group-decoupling Allocation is asserted to deliver both parameter reduction and perfect load balance, yet no coefficient sweeps, sensitivity tests, or Pareto curves are referenced to rule out hidden trade-offs between specialization, stability, and the three objectives.
Authors: The current manuscript contains component-wise ablations in Section 4 that isolate the contribution of each auxiliary loss and the allocation strategy. However, we acknowledge that explicit joint hyper-parameter sweeps and Pareto-frontier analysis across the three mechanisms are not presented. We will add a new subsection with coefficient sensitivity results and a trade-off plot in the revision to demonstrate that the chosen settings achieve the reported parameter efficiency and load balance without degrading specialization or training stability. revision: yes
Circularity Check
No significant circularity; empirical architecture proposal with independent validation
full rationale
The paper proposes a new MoE variant called MoHGE featuring a two-level routing mechanism, Group-Wise Auxiliary Loss, Intra-Group Experts Auxiliary Loss, and All-size Group-decoupling Allocation. These components are introduced as original designs to solve heterogeneity and load-balancing issues, with performance claims resting entirely on empirical evaluations rather than any mathematical derivation. No equations, fitted parameters, or self-citations are presented that reduce the central results to inputs by construction; the work is self-contained against external benchmarks through reported experiments on parameter reduction and GPU utilization.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard back-propagation and expert-selection mechanisms from prior MoE literature function as expected under the new grouping.
invented entities (1)
-
Heterogeneous Grouped Experts with two-level routing
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review arXiv 2023
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, and 1 others. 2023. Qwen technical report. arXiv preprint arXiv:2309.16609
work page internal anchor Pith review arXiv 2023
-
[3]
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, and 1 others. 2020. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432--7439
2020
-
[4]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877--1901
2020
-
[5]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, and 1 others. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review arXiv 2021
-
[6]
OpenCompass Contributors. 2023. Opencompass: A universal evaluation platform for foundation models
2023
-
[7]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120):1--39
2022
-
[8]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300
work page internal anchor Pith review arXiv 2020
-
[9]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2024. Measuring mathematical problem solving with the math dataset, 2021. URL https://arxiv. org/abs/2103.03874
work page internal anchor Pith review arXiv 2024
-
[10]
Quzhe Huang, Zhenwei An, Nan Zhuang, Mingxu Tao, Chen Zhang, Yang Jin, Kun Xu, Kun Xu, Liwei Chen, Songfang Huang, and Yansong Feng. 2024. https://doi.org/10.18653/v1/2024.acl-long.696 Harder task needs more experts: Dynamic routing in M o E models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long...
-
[11]
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. 1991. Adaptive mixtures of local experts. Neural computation, 3(1):79--87
1991
-
[12]
Michael I Jordan and Robert A Jacobs. 1994. Hierarchical mixtures of experts and the em algorithm. Neural computation, 6(2):181--214
1994
-
[13]
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. 2017. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. arXiv preprint arXiv:1705.03551
work page internal anchor Pith review arXiv 2017
-
[14]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361
work page internal anchor Pith review arXiv 2020
-
[15]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199--22213
2022
-
[16]
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, and 1 others. 2024 a . Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv preprint arXiv:2405.04434
work page internal anchor Pith review arXiv 2024
-
[17]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, and 1 others. 2024 b . Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437
work page internal anchor Pith review arXiv 2024
-
[18]
Denis Paperno, Germ \'a n Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fern \'a ndez. 2016. The lambada dataset: Word prediction requiring a broad discourse context. arXiv preprint arXiv:1606.06031
work page Pith review arXiv 2016
-
[19]
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. 2019. Socialiqa: Commonsense reasoning about social interactions. arXiv preprint arXiv:1904.09728
work page internal anchor Pith review arXiv 2019
-
[20]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538
work page internal anchor Pith review arXiv 2017
-
[21]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053
work page internal anchor Pith review arXiv 2019
-
[22]
Manxi Sun, Wei Liu, Jian Luan, Pengzhi Gao, and Bin Wang. 2024. https://doi.org/10.18653/v1/2024.emnlp-industry.118 Mixture of diverse size experts . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 1608--1621, Miami, Florida, US. Association for Computational Linguistics
- [23]
-
[24]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth \'e e Lacroix, Baptiste Rozi \`e re, Naman Goyal, Eric Hambro, Faisal Azhar, and 1 others. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971
work page internal anchor Pith review arXiv 2023
- [25]
-
[26]
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, and 1 others. 2022. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682
work page internal anchor Pith review arXiv 2022
-
[27]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[28]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.