Recognition: unknown
Reducing Detail Hallucinations in Long-Context Regulatory Understanding via Targeted Preference Optimization
Pith reviewed 2026-05-08 07:10 UTC · model grok-4.3
The pith
Targeted preference optimization on pairs differing in one detail cuts LLM hallucinations in regulatory texts by 42-61%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By constructing preference pairs that differ in exactly one detail dimension, DetailDPO concentrates the DPO gradient signal on detail-bearing tokens; theoretical analysis shows this occurs under mild assumptions, and experiments confirm a 42-61% relative drop in Detail Error Rate across five error types, three context-length tiers, and multiple model families with cross-domain transfer.
What carries the argument
Minimal detail perturbation contrastive pairs inside a targeted DPO loop, which isolate gradient updates to specific factual elements rather than broad response quality.
If this is right
- Detail Error Rate falls 42-61% relative to standard baselines on the same models and data.
- Gains appear uniformly across all five error types in the taxonomy.
- The same training produces measurable improvements on financial and medical documents without domain-specific retraining.
- Benefits hold for models ranging from 7B to 72B parameters and contexts from 8K to 64K tokens.
Where Pith is reading between the lines
- The single-dimension perturbation idea could be adapted to other alignment methods to target specific factual failure modes rather than overall preference.
- DetailBench-style annotation could become a template for building precision benchmarks in any domain where small factual slips carry high cost.
- Controlling the exact difference between preferred and rejected responses may prove more efficient than scaling data volume alone for fixing narrow hallucination types.
Load-bearing premise
Contrastive pairs that differ in exactly one detail dimension will concentrate DPO gradient signal on detail-bearing tokens under the mild assumptions in the theoretical analysis.
What would settle it
Measuring DPO gradients on detail tokens when using minimal-perturbation pairs and finding no concentration relative to standard DPO pairs would falsify the claimed mechanism.
Figures



read the original abstract
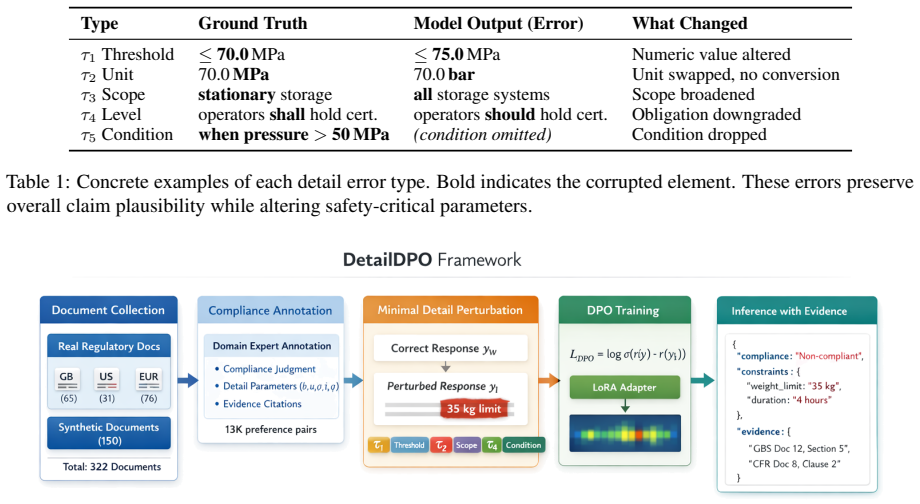
Large language models (LLMs) frequently produce \emph{detail hallucinations} when processing long regulatory documents, including subtle errors in threshold values, units, scopes, obligation levels, and conditions that preserve surface plausibility while corrupting safety-critical parameters. We formalize this phenomenon through a fine-grained \emph{Detail Error Taxonomy} of five error types and introduce \textbf{DetailBench}, a benchmark built from 172 real regulatory documents and 150 synthetic documents spanning three jurisdictions, with human-annotated detail-level ground truth comprising 13,000 preference pairs. We propose \textbf{DetailDPO}, a targeted preference optimization framework that constructs contrastive pairs differing in exactly one detail dimension, concentrating DPO gradient signal on detail-bearing~tokens. We provide theoretical analysis showing why \emph{minimal detail perturbation} pairs yield gradient concentration under mild assumptions. Experiments on the Qwen2.5 family (7B, 14B, 72B) and Llama-3.1-8B across three context-length tiers (8K--64K tokens) show that DetailDPO reduces the Detail Error Rate by 42--61\% relative to baselines, with consistent gains across all five error types and cross-domain transfer to financial and medical documents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that LLMs produce detail hallucinations in long regulatory documents, which it formalizes via a five-type Detail Error Taxonomy. It introduces DetailBench, a benchmark derived from 172 real and 150 synthetic regulatory documents across jurisdictions with 13,000 human-annotated preference pairs. The proposed DetailDPO method constructs contrastive pairs that differ in exactly one detail dimension to target DPO gradients on detail-bearing tokens, supported by theoretical analysis under mild assumptions. Experiments across Qwen2.5 (7B,14B,72B) and Llama-3.1-8B models at 8K-64K context lengths demonstrate 42-61% relative reductions in Detail Error Rate, with gains across error types and transfer to financial and medical domains.
Significance. If the results hold and the targeted mechanism is confirmed, this would represent a meaningful advance in mitigating a specific and safety-critical failure mode in LLMs for regulatory text processing. The fine-grained taxonomy and large-scale benchmark from real documents provide reusable resources for the community. The consistent performance across model scales and context lengths, plus cross-domain generalization, strengthens the practical value. The theoretical analysis, while not yet empirically validated, offers a principled starting point for targeted alignment techniques.
major comments (3)
- The theoretical analysis claims that contrastive pairs differing in exactly one detail dimension concentrate the DPO gradient on detail-bearing tokens under mild assumptions. However, no empirical verification (e.g., gradient attribution, token-level update analysis, or ablation on attention patterns) is provided to confirm this holds in long-context transformers (8K-64K), where attention diffusion or subword tokenization of numbers/units could spread updates. This is load-bearing for the central claim that gains stem from the targeted mechanism rather than generic preference optimization.
- The Experiments section reports 42--61% relative reductions in Detail Error Rate across models and context tiers but provides no error bars, statistical significance tests, full training hyperparameters, data splits, or ablations on contrastive pair construction (e.g., ensuring exactly one detail dimension differs). These omissions undermine assessment of robustness and the cross-domain transfer claims.
- The DetailBench construction (mentioned with 13,000 pairs) lacks reported inter-annotator agreement for human annotations of the five error types or validation details for the 150 synthetic documents against real regulatory structures. This affects the reliability of the ground truth used to support the taxonomy and evaluation.
minor comments (2)
- The abstract contains a formatting artifact ('detail-bearing~tokens'); ensure consistent notation throughout.
- Consider reporting absolute Detail Error Rates alongside relative reductions to improve interpretability of the 42--61% figures.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. We appreciate the positive assessment of the work's significance and the identification of areas for improvement. Below, we address each major comment in detail and outline the revisions we will make.
read point-by-point responses
-
Referee: The theoretical analysis claims that contrastive pairs differing in exactly one detail dimension concentrate the DPO gradient on detail-bearing tokens under mild assumptions. However, no empirical verification (e.g., gradient attribution, token-level update analysis, or ablation on attention patterns) is provided to confirm this holds in long-context transformers (8K-64K), where attention diffusion or subword tokenization of numbers/units could spread updates. This is load-bearing for the central claim that gains stem from the targeted mechanism rather than generic preference optimization.
Authors: We agree that empirical verification of the gradient concentration mechanism would strengthen the central claim. The theoretical analysis in the manuscript derives the concentration result under the stated mild assumptions of token independence and single-dimension perturbation. The experimental results show that DetailDPO outperforms standard DPO, which we attribute to the targeted construction, but we acknowledge the lack of direct attribution analysis. In the revised version, we will add an ablation study on contrastive pair construction (single vs. multiple dimension differences) and include a preliminary token-level gradient analysis for a subset of the models to provide supporting evidence for the mechanism. revision: yes
-
Referee: The Experiments section reports 42--61% relative reductions in Detail Error Rate across models and context tiers but provides no error bars, statistical significance tests, full training hyperparameters, data splits, or ablations on contrastive pair construction (e.g., ensuring exactly one detail dimension differs). These omissions undermine assessment of robustness and the cross-domain transfer claims.
Authors: We thank the referee for pointing out these reporting gaps. The full set of training hyperparameters and data splits are detailed in Appendix B of the manuscript, but we will move key information to the main Experiments section for better visibility. We will add error bars (standard deviation over 3 runs) and statistical significance tests (e.g., Wilcoxon signed-rank tests) to all reported results. Additionally, we will include an ablation on the contrastive pair construction to demonstrate the benefit of ensuring exactly one detail dimension differs, which will also bolster the cross-domain transfer claims by showing consistent gains. revision: yes
-
Referee: The DetailBench construction (mentioned with 13,000 pairs) lacks reported inter-annotator agreement for human annotations of the five error types or validation details for the 150 synthetic documents against real regulatory structures. This affects the reliability of the ground truth used to support the taxonomy and evaluation.
Authors: We agree that reporting inter-annotator agreement is essential for establishing the reliability of the annotations. Although the manuscript describes the annotation process, we did not include the specific agreement metrics in the main text. In the revision, we will add the inter-annotator agreement results (computed using standard metrics such as Cohen's kappa) for the five error types. Similarly, we will provide additional details on how the 150 synthetic documents were validated against real regulatory structures, including the expert review process used to ensure they reflect authentic regulatory formats. revision: yes
Circularity Check
No circularity: theoretical analysis and empirical gains are independent of inputs by construction
full rationale
The paper's derivation chain consists of (1) formalizing a Detail Error Taxonomy, (2) building DetailBench with human-annotated pairs, (3) constructing contrastive pairs that differ in one detail dimension, and (4) providing theoretical analysis under mild assumptions that such pairs concentrate DPO gradients on detail-bearing tokens. None of these steps reduce to a self-definition, a fitted parameter renamed as prediction, or a load-bearing self-citation. The reported 42-61% Detail Error Rate reductions are measured on external benchmarks (Qwen2.5 family, Llama-3.1, cross-domain transfer) rather than quantities defined by the method itself. The theoretical claim is an explanatory analysis, not a uniqueness theorem or ansatz smuggled via prior work that would force the outcome. This is the normal case of an empirical method with supporting analysis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rethinking Attention with Performers
Legal-bert: The muppets straight out of law school. InFindings of the association for computa- tional linguistics: EMNLP 2020, pages 2898–2904. Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. 2020. A simple framework for contrastive learning of visual representations. InIn- ternational conference on machine learning, pages 1597–1607. Pm...
work page internal anchor Pith review arXiv 2020
-
[2]
YaRN: Efficient Context Window Extension of Large Language Models
Training language models to follow instruc- tions with human feedback.Advances in neural in- formation processing systems, 35:27730–27744. Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and En- rico Shippole. 2023. Yarn: Efficient context window extension of large language models.arXiv preprint arXiv:2309.00071. Rafael Rafailov, Archit Sharma, Eric Mitchell, ...
work page internal anchor Pith review arXiv 2023
-
[3]
Proximal Policy Optimization Algorithms
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proxi- mal policy optimization algorithms.arXiv preprint arXiv:1707.06347. Thomas Schuster, Marian Lambert, Nico Döring, and J...
work page internal anchor Pith review arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.