Recognition: unknown
Breaking Lock-In: Preserving Steerability under Low-Data VLA Post-Training
Pith reviewed 2026-05-08 08:04 UTC · model grok-4.3
The pith
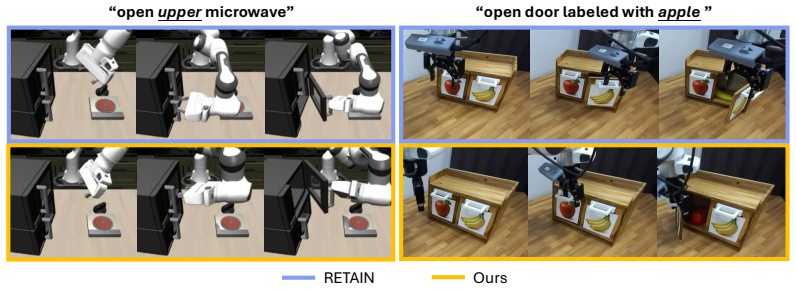
DeLock breaks lock-in in low-data VLA post-training by preserving visual grounding and applying contrastive test-time prompt guidance to steer toward novel instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The pre-trained knowledge inside a VLA policy is already sufficient for novel instructions; lock-in after low-data post-training can be avoided by preserving visual grounding during supervised fine-tuning and steering the policy's denoising dynamics at test time with contrastive prompts that contrast the novel instruction against the locked-in behavior.
What carries the argument
DeLock, a two-part method that preserves visual grounding during low-data SFT and applies test-time contrastive prompt guidance to redirect the policy's denoising toward novel instructions.
If this is right
- VLA policies can be adapted to new tasks using only small demonstration sets while retaining responsiveness to unseen instructions.
- Performance on novel instructions can match or exceed that of policies post-trained with substantially larger curated datasets.
- Lock-in appears in two forms: concept lock-in on training objects and attributes, and spatial lock-in on training targets.
- Test-time guidance can steer denoising dynamics without requiring retraining or additional task-specific data collection.
Where Pith is reading between the lines
- The approach may reduce the data and curation costs of deploying generalist VLAs in new environments.
- Similar preservation of grounding combined with test-time steering could be tested on other generative control models that overfit during fine-tuning.
- Future checks could measure whether the method still works when the novel instructions diverge further from pre-training distributions.
Load-bearing premise
The pre-trained VLA model already holds enough knowledge for novel instructions, and preserving grounding plus contrastive guidance will surface that knowledge without new failure modes.
What would settle it
A benchmark where DeLock is applied to instructions that clearly require knowledge absent from the original pre-training and it shows no gain over standard low-data fine-tuning.
Figures








read the original abstract
Have you ever post-trained a generalist vision-language-action (VLA) policy on a small demonstration dataset, only to find that it stops responding to new instructions and is limited to behaviors observed during post-training? We identify this phenomenon as lock-in: after low-data, supervised fine-tuning (SFT), the policy becomes overly specialized to the post-training data and fails to generalize to novel instructions, manifesting as concept lock-in (fixation on training objects/attributes) and spatial lock-in (fixation on training spatial targets). Many existing remedies introduce additional supervision signals, such as those derived from foundation models or auxiliary objectives, or rely on augmented datasets to recover generalization. In this paper, we show that the policy's internal pre-trained knowledge is sufficient: DeLock mitigates lock-in by preserving visual grounding during post-training and applying test-time contrastive prompt guidance to steer the policy's denoising dynamics according to novel instructions. Across eight simulation and real-world evaluations, DeLock consistently outperforms strong baselines and matches or exceeds the performance of a state-of-the-art generalist policy post-trained with substantially more curated demonstrations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies 'lock-in' in vision-language-action (VLA) policies after low-data supervised fine-tuning (SFT), manifesting as concept lock-in (fixation on training objects/attributes) and spatial lock-in (fixation on training spatial targets). It proposes DeLock, which preserves visual grounding during post-training and applies test-time contrastive prompt guidance to steer the policy's denoising dynamics for novel instructions. Across eight simulation and real-world evaluations, DeLock outperforms strong baselines and matches or exceeds a state-of-the-art generalist policy post-trained with substantially more curated demonstrations, supporting the claim that the policy's internal pre-trained knowledge is sufficient.
Significance. If the results hold, this is significant for scalable robot learning: it shows that pre-trained VLA knowledge can be preserved and surfaced for novel tasks using minimal data and no auxiliary supervision or augmented datasets. The consistent gains across diverse evaluations, combined with the method's reliance on internal knowledge rather than external signals, offer an efficient path to maintaining steerability in generalist policies.
major comments (2)
- [§4 (Experiments)] §4 (Experiments) and Table 1: The evaluations compare DeLock against post-trained baselines but do not report results for the unmodified pre-trained VLA equipped solely with the test-time contrastive prompt guidance on the novel-instruction tasks. This ablation is load-bearing for the central claim that 'the policy's internal pre-trained knowledge is sufficient' and that DeLock merely preserves access to it; without it, the results remain compatible with the low-data SFT stage introducing or recovering capabilities.
- [§3.2 (Method)] §3.2 (Method): The description of how visual grounding preservation during SFT interacts with the contrastive guidance at test time lacks a formal derivation or pseudocode showing that the combined procedure does not alter the pre-trained denoising distribution in ways that could introduce new failure modes on out-of-distribution instructions.
minor comments (2)
- [Figure 3] Figure 3: Error bars or standard deviations across runs are not reported for the success rates; this makes it difficult to assess the statistical reliability of the claimed consistent outperformance.
- [§3.2] The notation for the contrastive prompt guidance (e.g., the weighting parameter between positive and negative prompts) is introduced without an explicit equation; adding Eq. (X) would improve clarity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained VLA policies contain sufficient internal knowledge to generalize to novel instructions once lock-in is avoided.
Reference graph
Works this paper leans on
-
[1]
Intelligence, K
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al. pi 05: a vision-language-action model with open-world generalization. pi05: a vision-language-action model with open-world generalization, 2025
2025
-
[2]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[4]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review arXiv 2024
-
[5]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review arXiv 2025
-
[6]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review arXiv 2025
-
[7]
G. R. Team, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, T. Armstrong, A. Balakr- ishna, R. Baruch, M. Bauza, M. Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review arXiv 2025
-
[8]
Robocat: A self-improving generalist agent for robotic manipulation
K. Bousmalis, G. Vezzani, D. Rao, C. Devin, A. X. Lee, M. Bauz ´a, T. Davchev, Y . Zhou, A. Gupta, A. Raju, et al. Robocat: A self-improving generalist agent for robotic manipulation. arXiv preprint arXiv:2306.11706, 2023
-
[9]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. pi 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review arXiv 2024
- [10]
- [11]
- [12]
- [13]
-
[14]
B. Cheng, T. Liang, S. Huang, M. Shao, F. Zhang, B. Xu, Z. Xue, and H. Xu. Moe-dp: An moe-enhanced diffusion policy for robust long-horizon robotic manipulation with skill decom- position and failure recovery.arXiv preprint arXiv:2511.05007, 2025
-
[15]
Y . Guo, J. Zhang, X. Chen, X. Ji, Y .-J. Wang, Y . Hu, and J. Chen. Improving vision-language- action model with online reinforcement learning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 15665–15672. IEEE, 2025. 9
2025
-
[16]
X. Li, K. Hsu, J. Gu, K. Pertsch, O. Mees, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kir- mani, et al. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024
work page internal anchor Pith review arXiv 2024
-
[17]
Rl’s razor: Why online reinforcement learning forgets less, 2025
I. Shenfeld, J. Pari, and P. Agrawal. Rl’s razor: Why online reinforcement learning forgets less.arXiv preprint arXiv:2509.04259, 2025
-
[18]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, et al. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review arXiv 2025
- [19]
-
[20]
Wortsman, G
M. Wortsman, G. Ilharco, J. W. Kim, M. Li, S. Kornblith, R. Roelofs, R. G. Lopes, H. Ha- jishirzi, A. Farhadi, H. Namkoong, et al. Robust fine-tuning of zero-shot models. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7959– 7971, 2022
2022
- [21]
-
[22]
Y . Yadav, Z. Zhou, A. Wagenmaker, K. Pertsch, and S. Levine. Robust finetuning of vision- language-action robot policies via parameter merging.arXiv preprint arXiv:2512.08333, 2025
- [23]
-
[24]
W. Chen, J. S. Bhatia, C. Glossop, N. Mathihalli, R. Doshi, A. Tang, D. Driess, K. Pertsch, and S. Levine. Steerable vision-language-action policies for embodied reasoning and hierarchical control.arXiv preprint arXiv:2602.13193, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [25]
-
[26]
N. Kachaev, M. Kolosov, D. Zelezetsky, A. K. Kovalev, and A. I. Panov. Don’t blind your vla: Aligning visual representations for ood generalization, 2025.URL https://arxiv. org/abs/2510.25616, 2(4)
- [27]
-
[28]
arXiv preprint arXiv:2508.09976 (2025)
M. Lepert, J. Fang, and J. Bohg. Masquerade: Learning from in-the-wild human videos using data-editing.arXiv preprint arXiv:2508.09976, 2025
-
[29]
Punamiya, D
R. Punamiya, D. Patel, P. Aphiwetsa, P. Kuppili, L. Y . Zhu, S. Kareer, J. Hoffman, and D. Xu. Egobridge: Domain adaptation for generalizable imitation from egocentric human data. In Human to Robot: Workshop on Sensorizing, Modeling, and Learning from Humans, 2025
2025
-
[30]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review arXiv 2021
-
[31]
Y . Ma, Z. Song, Y . Zhuang, J. Hao, and I. King. A survey on vision-language-action models for embodied ai.arXiv preprint arXiv:2405.14093, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Nguyen, M
T. Nguyen, M. N. Vu, B. Huang, A. Vuong, Q. Vuong, N. Le, T. V o, and A. Nguyen. Language- driven 6-dof grasp detection using negative prompt guidance. InEuropean Conference on Computer Vision, pages 363–381. Springer, 2024
2024
-
[33]
Y . Ban, R. Wang, T. Zhou, M. Cheng, B. Gong, and C.-J. Hsieh. Understanding the impact of negative prompts: When and how do they take effect? Ineuropean conference on computer vision, pages 190–206. Springer, 2024
2024
-
[34]
J. Jang, S. Ye, and M. Seo. Can large language models truly understand prompts? a case study with negated prompts. InTransfer learning for natural language processing workshop, pages 52–62. PMLR, 2023
2023
-
[35]
D. Wan, J. Cho, E. Stengel-Eskin, and M. Bansal. Contrastive region guidance: Improving grounding in vision-language models without training. InEuropean Conference on Computer Vision, pages 198–215. Springer, 2024
2024
-
[36]
Jeong, J
J. Jeong, J. Kim, G. Lee, Y . Choi, and Y . Uh. Stylekeeper: Prevent content leakage using negative visual query guidance. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15760–15769, 2025
2025
-
[37]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[38]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[39]
R. Anil, A. M. Dai, O. Firat, M. Johnson, D. Lepikhin, A. Passos, S. Shakeri, E. Taropa, P. Bailey, Z. Chen, et al. Palm 2 technical report.arXiv preprint arXiv:2305.10403, 2023
work page internal anchor Pith review arXiv 2023
-
[40]
Q. Chen, J. Yu, M. Schwager, P. Abbeel, Y . Shentu, and P. Wu. Sarm: Stage-aware reward modeling for long horizon robot manipulation.arXiv preprint arXiv:2509.25358, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Zero-shot robotic manipu- lation with pretrained image-editing diffusion models,
K. Black, M. Nakamoto, P. Atreya, H. Walke, C. Finn, A. Kumar, and S. Levine. Zero- shot robotic manipulation with pretrained image-editing diffusion models.arXiv preprint arXiv:2310.10639, 2023
-
[42]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review arXiv 2024
- [43]
-
[44]
Lossless adaptation of pre- trained vision models for robotic manipulation,
M. Sharma, C. Fantacci, Y . Zhou, S. Koppula, N. Heess, J. Scholz, and Y . Aytar. Lossless adap- tation of pretrained vision models for robotic manipulation.arXiv preprint arXiv:2304.06600, 2023
- [45]
-
[46]
T.-Y . Xiang, A.-Q. Jin, X.-H. Zhou, M.-J. Gui, X.-L. Xie, S.-Q. Liu, S.-Y . Wang, S.-B. Duan, F.-C. Xie, W.-K. Wang, et al. Parallels between vla model post-training and human motor learning: Progress, challenges, and trends.arXiv preprint arXiv:2506.20966, 2025
- [47]
-
[48]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[49]
H. Li, Y . Zuo, J. Yu, Y . Zhang, Z. Yang, K. Zhang, X. Zhu, Y . Zhang, T. Chen, G. Cui, et al. Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674, 2025
work page internal anchor Pith review arXiv 2025
- [50]
- [51]
- [52]
-
[53]
M. Du and S. Song. Dynaguide: Steering diffusion polices with active dynamic guidance. arXiv preprint arXiv:2506.13922, 2025
- [54]
- [55]
-
[56]
F. Koulischer, J. Deleu, G. Raya, T. Demeester, and L. Ambrogioni. Dynamic negative guid- ance of diffusion models.arXiv preprint arXiv:2410.14398, 2024
-
[57]
M. Nakamoto, O. Mees, A. Kumar, and S. Levine. Steering your generalists: Improving robotic foundation models via value guidance.arXiv preprint arXiv:2410.13816, 2024
-
[58]
Steering your diffusion policy with latent space reinforcement learning
A. Wagenmaker, M. Nakamoto, Y . Zhang, S. Park, W. Yagoub, A. Nagabandi, A. Gupta, and S. Levine. Steering your diffusion policy with latent space reinforcement learning.arXiv preprint arXiv:2506.15799, 2025
-
[59]
M. Xu, Z. Xu, C. Chi, M. Veloso, and S. Song. Xskill: Cross embodiment skill discovery. In Conference on robot learning, pages 3536–3555. PMLR, 2023
2023
-
[60]
Z. Li, J. Liu, Z. Dong, T. Teng, Q. Rouxel, D. Caldwell, and F. Chen. Towards deploying vla without fine-tuning: Plug-and-play inference-time vla policy steering via embodied evolution- ary diffusion.arXiv preprint arXiv:2511.14178, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
PaliGemma: A versatile 3B VLM for transfer
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdul- mohsin, M. Tschannen, E. Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024. 12 Appendix A Pseudocode for Training and Inference For completeness, we provide pseudocode for the two core components ofDeLock. Algorith...
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.