Recognition: unknown
Mechanistic Steering of LLMs Reveals Layer-wise Feature Vulnerabilities in Adversarial Settings
Pith reviewed 2026-05-08 08:23 UTC · model grok-4.3
The pith
Steering mid-to-late layer feature subgroups in Gemma-2-2B raises harmfulness scores across three grouping methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
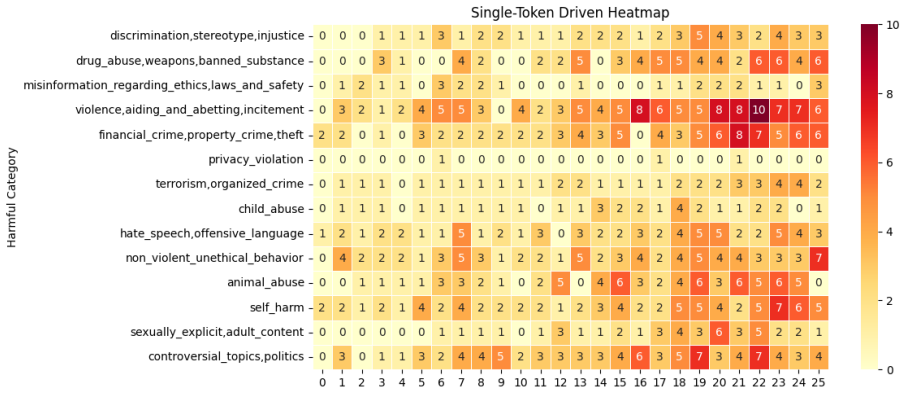
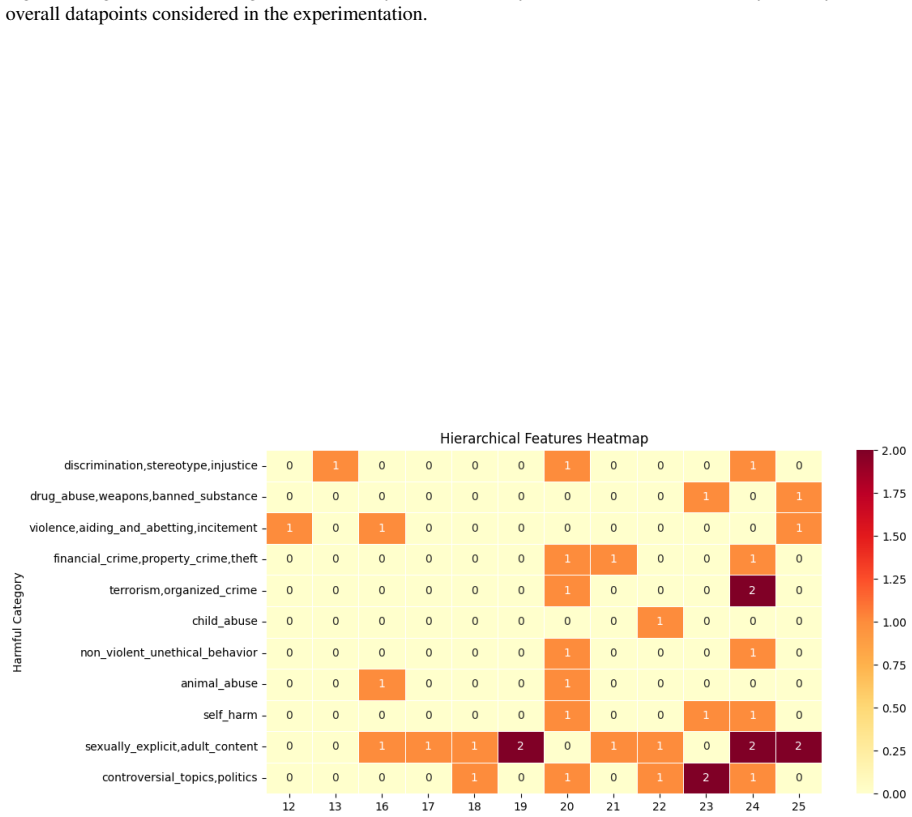
Jailbreak success in Gemma-2-2B is localized to feature subgroups in mid-to-later layers, as amplifying the top SAE features from three different grouping strategies (cluster, hierarchical-linkage, single-token-driven) produces higher harmfulness scores precisely when those subgroups are taken from layers 16-25.
What carries the argument
SAE feature subgroups identified per layer via subspace similarity on concept-aligned tokens, then used as targets for amplification-based steering to measure causal impact on harm scores.
If this is right
- Safety training could shift from prompt-level filtering to suppressing or regularizing the vulnerable mid-layer subgroups.
- Adversarial robustness testing should include layer-specific feature amplification checks rather than prompt-only attacks.
- Model editing or unlearning techniques could be applied selectively to those subgroups without affecting early-layer representations.
Where Pith is reading between the lines
- The same layer-localization pattern may appear in larger models if the mid-layer transition from syntax to semantics is similar.
- Early layers might remain useful for capability preservation while later layers receive targeted safety patches.
- If the subgroups prove stable across datasets, they could serve as a diagnostic for whether a new model has inherited the same vulnerability profile.
Load-bearing premise
That amplifying the identified SAE features directly causes the rise in harmfulness rather than the steering process or judge introducing unrelated effects.
What would settle it
A controlled run where amplifying the same top features from layers 16-25 produces no increase in harm scores while other layers or random features do.
Figures


read the original abstract
Large language models (LLMs) can still be jailbroken into producing harmful outputs despite safety alignment. Existing attacks show this vulnerability, but not the internal mechanisms that cause it. This study asks whether jailbreak success is driven by identifiable internal features rather than prompts alone. We propose a three-stage pipeline for Gemma-2-2B using the BeaverTails dataset. First, we extract concept-aligned tokens from adversarial responses via subspace similarity. Second, we apply three feature-grouping strategies (cluster, hierarchical-linkage, and single-token-driven) to identify SAE feature subgroups for the aligned tokens across all 26 model layers. Third, we steer the model by amplifying the top features from each identified subgroup and measure the change in harmfulness score using a standardized LLM-judge scoring protocol. In all three approaches, the features in the layers [16-25] were relatively more vulnerable to steering. All three methods confirmed that mid to later layer feature subgroups are more responsible for unsafe outputs. These results provide evidence that the jailbreak vulnerability in Gemma-2-2B is localized to feature subgroups of mid to later layers, suggesting that targeted feature-level interventions may offer a more principled path to adversarial robustness than current prompt-level defenses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a three-stage pipeline on Gemma-2-2B with BeaverTails data—(1) extracting concept-aligned tokens from adversarial responses via subspace similarity, (2) grouping SAE features across 26 layers with three strategies (cluster, hierarchical-linkage, single-token-driven), and (3) steering by amplifying the top features from each subgroup while scoring harmfulness via an LLM judge—shows that layers 16-25 are relatively more vulnerable. All three grouping methods converge on the conclusion that mid-to-later-layer feature subgroups are more responsible for unsafe outputs, suggesting targeted feature-level interventions for robustness.
Significance. If the causal attribution holds, the work supplies mechanistic evidence that jailbreak vulnerabilities in aligned LLMs can be localized to specific SAE feature subgroups in mid-to-late layers rather than being uniformly distributed or prompt-only. The convergence of three independent grouping methods on the same layer range is a positive indicator of robustness in the localization result. This could inform more principled, feature-targeted defenses, though the current evidence leaves the specificity of the effect untested.
major comments (2)
- [Steering Experiments] Steering and evaluation protocol (third stage): No control condition is described in which an equal number of randomly selected SAE features (or features drawn from early layers 1-10) are amplified to the identical magnitude and then scored with the same LLM judge. Without this matched non-specific control, the observed rise in harmfulness cannot be attributed specifically to the subgroups identified in layers 16-25 rather than to generic effects of feature amplification or judge sensitivity.
- [Evaluation] Evaluation protocol: The manuscript provides no details on LLM-judge reliability (e.g., agreement with human raters, calibration on held-out examples, or variance across multiple judge prompts) nor on statistical testing (e.g., significance of harmfulness deltas or correction for multiple comparisons across layers and groupings). These omissions leave the quantitative support for the layer-wise vulnerability claim under-specified.
minor comments (1)
- [Abstract] The abstract states that 'all three methods confirmed' the layer range but does not report the exact overlap statistics or any disagreement cases between the three grouping methods; adding a small table or quantitative summary would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which identifies key areas for strengthening the causal claims and evaluation rigor in our work. We address each major comment point-by-point below, indicating where revisions will be incorporated to improve the manuscript.
read point-by-point responses
-
Referee: [Steering Experiments] Steering and evaluation protocol (third stage): No control condition is described in which an equal number of randomly selected SAE features (or features drawn from early layers 1-10) are amplified to the identical magnitude and then scored with the same LLM judge. Without this matched non-specific control, the observed rise in harmfulness cannot be attributed specifically to the subgroups identified in layers 16-25 rather than to generic effects of feature amplification or judge sensitivity.
Authors: We agree that the absence of a matched control condition limits the specificity of our attribution to the identified subgroups. In the revised manuscript, we will add control experiments in which an equal number of randomly selected SAE features (from the same layers 16-25) and features drawn from early layers (1-10) are amplified to the identical magnitude. These controls will be evaluated using the same LLM judge and compared directly to the subgroup steering results, including statistical tests for differences. This will allow us to demonstrate that the observed harmfulness increases are not due to generic amplification effects. We have added a new subsection to the Methods and updated the Results to report these controls. revision: yes
-
Referee: [Evaluation] Evaluation protocol: The manuscript provides no details on LLM-judge reliability (e.g., agreement with human raters, calibration on held-out examples, or variance across multiple judge prompts) nor on statistical testing (e.g., significance of harmfulness deltas or correction for multiple comparisons across layers and groupings). These omissions leave the quantitative support for the layer-wise vulnerability claim under-specified.
Authors: We acknowledge that the current manuscript lacks sufficient details on judge reliability and statistical analysis, which weakens the quantitative support. In the revision, we will expand the Evaluation section to include: (1) inter-annotator agreement between the LLM judge and human raters on a held-out set of 200 examples (reporting percentage agreement and Cohen's kappa), (2) calibration results on examples with known harm levels, and (3) variance across three different judge prompts. We will also report statistical significance of harmfulness deltas using paired t-tests (or non-parametric equivalents) with p-values corrected via Bonferroni for multiple comparisons across layers and groupings. These additions will be incorporated into the revised manuscript along with the updated results. revision: yes
Circularity Check
No circularity in experimental pipeline
full rationale
The paper presents a purely empirical three-stage pipeline: subspace-based token extraction from adversarial responses, application of three distinct feature-grouping strategies to SAE features, and direct measurement of harmfulness-score changes after steering. No equations, fitted parameters, or derivations are described that reduce any result to its inputs by construction. Conclusions rest on observed layer-wise differences in measured steering effects rather than self-definitional steps, load-bearing self-citations, or renamed known results. The work is self-contained against external benchmarks of harmfulness scoring.
Axiom & Free-Parameter Ledger
free parameters (2)
- top-feature selection count or threshold
- clustering hyperparameters
axioms (2)
- domain assumption SAE features correspond to human-interpretable concepts that can be aligned with adversarial tokens via subspace similarity
- domain assumption Amplifying a feature subgroup via steering isolates its causal contribution to harmfulness without major interference from other features
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Nick Cammarata, Gabriel Goh, Shan Carter, Ludwig Schubert, Michael Petrov, and Chris Olah. 2020. Curve detectors. Distill, 5(6):e00024--003
2020
-
[4]
Brian Cheung, Alexander Terekhov, Yubei Chen, Pulkit Agrawal, and Bruno Olshausen. 2019. Superposition of many models into one. Advances in neural information processing systems, 32
2019
-
[5]
Jiaming Ji, Mickel Liu, Josef Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. 2023. Beavertails: Towards improved safety alignment of llm via a human-preference dataset. Advances in Neural Information Processing Systems, 36:24678--24704
2023
- [6]
-
[7]
Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, J \'a nos Kram \'a r, Anca Dragan, Rohin Shah, and Neel Nanda. 2024. Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 278--300
2024
-
[8]
Runqi Lin, Bo Han, Fengwang Li, and Tongliang Liu. 2025. Understanding and enhancing the transferability of jailbreaking attacks. The Thirteenth International Conference on Learning Representations
2025
-
[9]
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. 2024. Tree of attacks: Jailbreaking black-box llms automatically. Advances in Neural Information Processing Systems, 37:61065--61105
2024
-
[10]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. The Eleventh International Conference on Learning Representations
-
[11]
Chris Olah, Arvind Satyanarayan, Ian M Johnson, Shan Carter, Ludwig Schubert, Katherine Ye, and Alexander Mordvintsev. 2018. The building blocks of interpretability. Distill
2018
-
[12]
Joshua Placidi. 2025. Attribution graphs: How to read an artificial neural brain. Medium
2025
-
[13]
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. 2024. https://openreview.net/forum?id=hTEGyKf0dZ Fine-tuning aligned language models compromises safety, even when users do not intend to! In The Twelfth International Conference on Learning Representations
2024
-
[14]
Andrew Rufail, Sanjana Rathore, Daniel Son, Adrian Simon, Soham Dave, Daniel Zhang, Cole Blondin, Sean O'Brien, and Kevin Zhu. 2025. https://openreview.net/forum?id=oOxrKNo1lQ Semantic convergence: Investigating shared representations across scaled LLM s . In ACL 2025 Student Research Workshop
2025
-
[15]
Anthropic Research Team. 2025. https://transformer-circuits.pub/2025/attribution-graphs/ Circuit tracing: Revealing computational graphs in language models . Transformer Circuits Blog
2025
-
[16]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, L \'e onard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ram \'e , and 1 others. 2024. Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118
work page internal anchor Pith review arXiv 2024
-
[17]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2023. Jailbroken: How does llm safety training fail? arXiv preprint arXiv:2307.02483
work page internal anchor Pith review arXiv 2023
-
[18]
Zhengxuan Wu, Aryaman Arora, Atticus Geiger, Zheng Wang, Jing Huang, Dan Jurafsky, Christopher D Manning, and Christopher Potts. 2025. https://openreview.net/forum?id=K2CckZjNy0 Axbench: Steering LLM s? even simple baselines outperform sparse autoencoders . In Forty-second International Conference on Machine Learning
2025
-
[19]
Zifan Zheng, Yezhaohui Wang, Yuxin Huang, Shichao Song, Mingchuan Yang, Bo Tang, Feiyu Xiong, and Zhiyu Li. 2025. Attention heads of large language models. Patterns, 6(2)
2025
-
[20]
Andy Zou, Stéphanie Kolter Wang, Zico Z., and Matt Fredrikson. 2023. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.