Recognition: unknown
Scaling Multi-Node Mixture-of-Experts Inference Using Expert Activation Patterns
Pith reviewed 2026-05-08 08:26 UTC · model grok-4.3
The pith
Expert activation patterns in MoE models enable placement and grouping that cuts inter-node all-to-all communication by up to 20 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
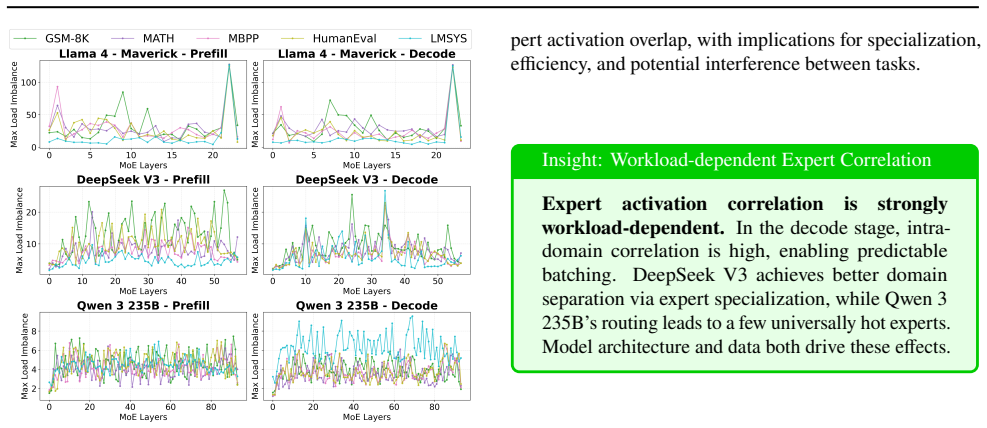
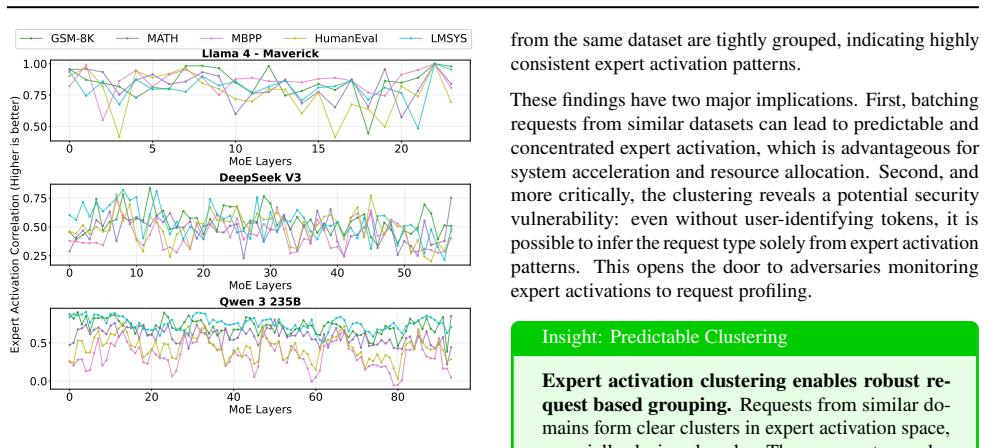
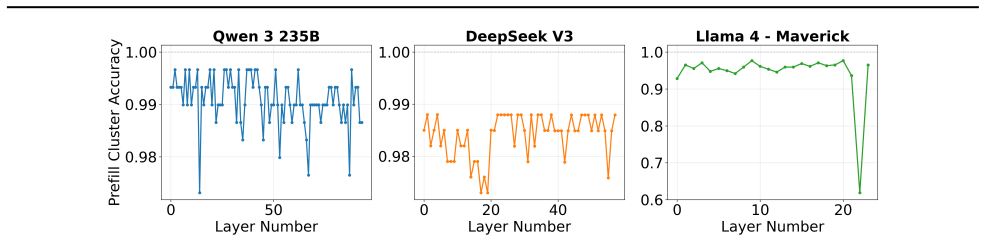
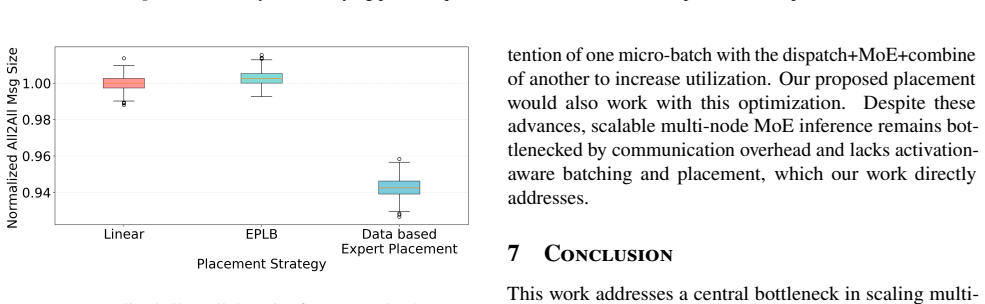
Profiling reveals variable expert load imbalance, domain-specific activation shifts, and strong prefill-decode correlation in models such as Llama 4 Maverick, DeepSeek V3-671B, and Qwen3-230B-A22B. These patterns motivate workload-aware micro-batch grouping and expert placement that maximizes token locality, cutting all-to-all communication volume by up to 20 times and thereby reducing MoE decode latency while raising accelerator utilization.
What carries the argument
workload-aware micro-batch grouping together with expert placement derived from profiled activation patterns, which increases the share of tokens routed to local experts
If this is right
- All-to-all communication data volume falls by as much as 20 times
- MoE decode latency decreases because tokens spend less time moving between nodes
- Accelerator utilization rises as devices spend fewer cycles waiting on communication
- The same placement works across multiple large MoE models and varied datasets
- Static placement becomes practical once patterns are shown to be stable
Where Pith is reading between the lines
- The same profiling could guide how many experts to co-locate on each node when building larger clusters
- Training losses might be extended with a term that encourages experts to activate in more localized patterns
- If patterns drift slowly, a low-cost periodic re-profile could keep the placement current without full retraining
Load-bearing premise
The activation patterns observed during profiling stay similar enough on new tasks and after model changes that the derived placement decisions stay effective without repeated re-profiling.
What would settle it
Measure all-to-all volume after applying the placement to a new task domain where expert popularity differs sharply from the profiled set; savings near zero would falsify the claim.
Figures







read the original abstract
Most recent state-of-the-art (SOTA) large language models (LLMs) use Mixture-of-Experts (MoE) architectures to scale model capacity without proportional per-token compute, enabling higher-quality outputs at manageable serving costs. However, MoE inference at scale is fundamentally bottlenecked by expert load imbalance and inefficient token routing, especially in multi-node deployments where tokens are not guaranteed to be routed to local experts, resulting in significant inter-node all-to-all communication overhead. To systematically characterize these challenges, we profile SOTA open-source MoE models, including Llama 4 Maverick, DeepSeek V3-671B, and Qwen3-230B-A22B, on various datasets and collected over 100k real expert activation traces. Upon studying the expert activation patterns, we uncover various persistent properties across all the frontier MoE models: variable expert load imbalance, domain-specific expert activation where expert popularity shifts across task families (code, math, chat, general), and a strong correlation between prefill and decode expert activations. Motivated by these findings, we propose workload-aware micro-batch grouping and an expert placement strategy to maximize token locality to the destination expert, thereby reducing inter-node communication. Across models and datasets, these optimizations help reduce all2all communication data up to 20, resulting in lower MoE decode latency and better accelerator utilization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper profiles over 100k expert activation traces from frontier MoE models (Llama 4 Maverick, DeepSeek V3-671B, Qwen3-230B-A22B) across datasets, identifying persistent properties including variable load imbalance, domain-specific popularity shifts (code/math/chat/general), and strong prefill-decode activation correlation. It then proposes workload-aware micro-batch grouping and expert placement strategies to maximize token-expert locality in multi-node settings, claiming up to 20x reduction in all-to-all communication volume, lower decode latency, and improved accelerator utilization across models and datasets.
Significance. If the locality optimizations and reported speedups hold under broader conditions, the work could meaningfully advance practical scaling of large MoE inference by directly addressing inter-node communication bottlenecks that currently limit multi-node deployments. The large-scale empirical trace collection also provides a reusable resource for studying MoE routing behavior.
major comments (2)
- [Abstract] Abstract: the claim that the optimizations deliver up to 20x communication reduction 'across models and datasets' is load-bearing for the central systems contribution, yet the manuscript does not quantify degradation when placement derived from one task family (e.g., code) is applied to another (e.g., math or chat), despite explicitly noting domain-specific shifts; this leaves open whether the gains are in-distribution only.
- [Evaluation] Evaluation section: the reported latency and utilization improvements lack explicit baselines, statistical significance testing, or ablation on profile stability across unseen workloads/hardware, making it impossible to assess whether the 20x figure is robust or condition-specific.
minor comments (1)
- [Method] The description of the micro-batch grouping heuristic would benefit from a concise pseudocode or algorithmic listing to clarify the exact locality objective being optimized.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, indicating revisions where the manuscript will be updated.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the optimizations deliver up to 20x communication reduction 'across models and datasets' is load-bearing for the central systems contribution, yet the manuscript does not quantify degradation when placement derived from one task family (e.g., code) is applied to another (e.g., math or chat), despite explicitly noting domain-specific shifts; this leaves open whether the gains are in-distribution only.
Authors: We agree that cross-domain degradation should be quantified given the domain-specific shifts we report in the profiling results. In the revised manuscript we add a dedicated cross-domain evaluation subsection that applies placement policies derived from one task family (code) to the others (math, chat, general). These experiments show that peak reductions of 20x occur in-distribution while cross-domain application yields 5–12x reductions depending on domain similarity. We have updated the abstract to state that the 20x figure represents the maximum observed reduction and to reference the cross-domain results. revision: yes
-
Referee: [Evaluation] Evaluation section: the reported latency and utilization improvements lack explicit baselines, statistical significance testing, or ablation on profile stability across unseen workloads/hardware, making it impossible to assess whether the 20x figure is robust or condition-specific.
Authors: We accept that the evaluation section requires clearer baselines and statistical rigor. The revised version now includes explicit baselines (standard all-to-all routing and random expert placement), reports paired t-test results (p < 0.01) over ten runs for latency and utilization metrics, and adds an ablation that derives placements from 80 % of traces and evaluates on the held-out 20 % across workloads, confirming stable gains. For unseen hardware we have added a limitations discussion noting that all experiments use the multi-node accelerator configurations described in the paper; a broader hardware sweep is outside the scope of the current study. revision: partial
Circularity Check
No significant circularity; empirical profiling followed by measured heuristic optimization
full rationale
The paper profiles SOTA MoE models to collect >100k expert activation traces, identifies persistent properties (load imbalance, domain-specific popularity shifts, prefill-decode correlation), and designs workload-aware micro-batch grouping plus expert placement to improve locality. Reported reductions (up to 20x all2all data) are direct experimental measurements on the profiled models and datasets rather than any fitted parameter reused as a prediction, self-definitional equation, or load-bearing self-citation. The chain is self-contained empirical characterization plus heuristic evaluation with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert activation patterns observed on the profiled datasets and models are representative of production workloads.
Reference graph
Works this paper leans on
-
[1]
Grok-1. URL https://github.com/xai-org/ grok-1. Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review arXiv
-
[2]
Program Synthesis with Large Language Models
Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732,
work page internal anchor Pith review arXiv
-
[3]
R., Kumar, S
Bambhaniya, A. R., Kumar, S. C., and Krishna, T. Moe- ERAS: Expert residency aware selection. InMachine Learning for Computer Architecture and Systems 2024,
2024
-
[4]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review arXiv
-
[5]
URL https://arxiv.org/abs/2412.19437. Eliseev, A. and Mazur, D. Fast inference of mixture-of- experts language models with offloading,
work page internal anchor Pith review arXiv
-
[6]
Fedus, W., Zoph, B., and Shazeer, N
URL https://arxiv.org/abs/2312.17238. Fedus, W., Zoph, B., and Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.arXiv preprint arXiv:2101.03961,
- [7]
-
[8]
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J
URL https://arxiv.org/ abs/2502.06643. Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the math dataset. NeurIPS,
-
[9]
S., Wu, C.-J., and Lee, B
Huang, H., Ardalani, N., Sun, A., Ke, L., Bhosale, S., Lee, H.-H. S., Wu, C.-J., and Lee, B. Toward efficient inference for mixture of experts. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024a. URL https://openreview.net/ forum?id=stXtBqyTWX. Huang, H., Ardalani, N., Sun, A., Ke, L., Lee, H.- H. S., Bhosale, S., Wu, C....
2024
-
[10]
URLhttps://arxiv.org/abs/2505.11432. Lepikhin, D., Lee, H., Xu, Y., Chen, D., Firat, O., Huang, Y., Krikun, M., Shazeer, N., and Chen, Z. {GS}hard: Scaling giant models with conditional com- putation and automatic sharding. InInternational Confer- ence on Learning Representations,
-
[11]
[On- line; accessed 2025-04-10]
URL https://ai.meta.com/blog/ llama-4-multimodal-intelligence/ . [On- line; accessed 2025-04-10]. Lu, X., Liu, Q., Xu, Y., Zhou, A., Huang, S., Zhang, B., Yan, J., and Li, H. Not all experts are equal: Efficient expert pruning and skipping for mixture-of-experts large language models. In Ku, L.-W., Martins, A., and Srikumar, V. (eds.),Proceedings of the 6...
2025
-
[12]
doi: 10.18653/v1/2024.acl-long.334
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.334. URL https:// aclanthology.org/2024.acl-long.334/. Narayan, S., Cohen, S. B., and Lapata, M. Don’t give me the details, just the summary! topic-aware convolu- tional neural networks for extreme summarization.ArXiv, abs/1808.08745,
-
[13]
URL https: //arxiv.org/abs/2201.05596. Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., and Catanzaro, B. Megatron-lm: Training multi-billion pa- rameter language models using model parallelism.arXiv preprint arXiv:1909.08053,
-
[14]
URLhttps://arxiv.org/abs/2507.20534. team, M. A. Mixtral-8x22b,
work page internal anchor Pith review arXiv
-
[15]
URL https: //arxiv.org/abs/2505.09388. Unsloth. Llama 4 maverick - 1.78bit unsloth dynamic gguf : r/localllama
work page internal anchor Pith review arXiv
-
[16]
Yu, D., Shen, L., Hao, H., Gong, W., Wu, H., Bian, J., Dai, L., and Xiong, H
URL https://arxiv.org/abs/2401.08383. Yu, D., Shen, L., Hao, H., Gong, W., Wu, H., Bian, J., Dai, L., and Xiong, H. Moesys: A distributed and efficient mixture-of-experts training and inference system for internet services.IEEE Transactions on Services Computing, 17(5):2626–2639,
-
[17]
doi: 10.1109/TSC. 2024.3399654. Zheng, L., Chiang, W.-L., Sheng, Y., Li, T., Zhuang, S., Wu, Z., Zhuang, Y., Li, Z., Lin, Z., Xing, E. P., Gonzalez, J. E., Stoica, I., and Zhang, H. Lmsys-chat-1m: A large-scale real-world llm conversation dataset,
work page doi:10.1109/tsc 2024
-
[18]
URL https: //arxiv.org/abs/2202.08906
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.