Recognition: unknown
Quantifying opinion homophily in online social networks: A bounded confidence perspective
Pith reviewed 2026-05-08 07:00 UTC · model grok-4.3
The pith
Online users form opinion neighborhoods more concentrated than random chance predicts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
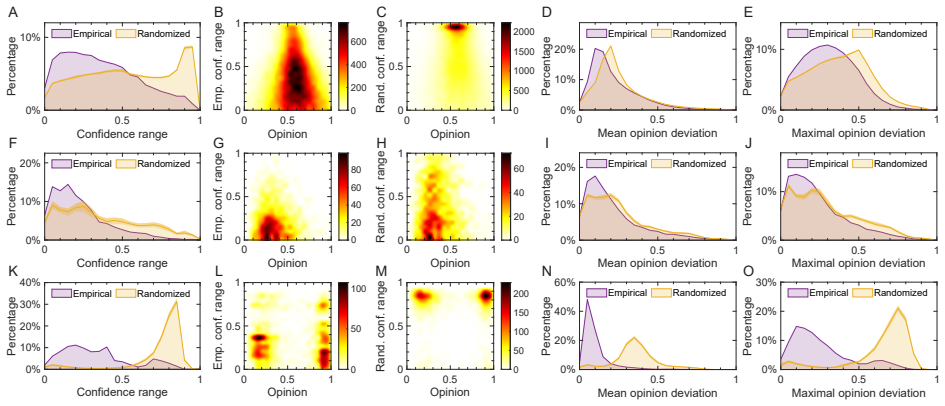
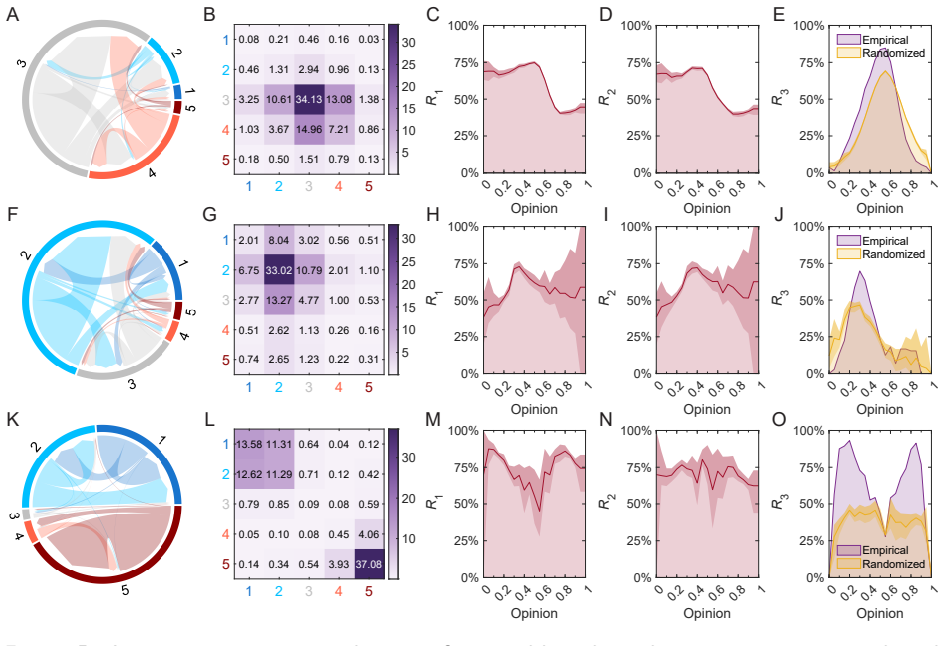
Users' interaction neighborhoods are significantly more concentrated in opinion space than expected by chance, with tie strength and issue polarization further amplifying this effect. Moreover, users often exhibit asymmetric tolerance ranges, with asymmetry typically directed toward locally mainstream positions rather than more radical or opposing ones. These findings support a bounded confidence interpretation of online value homophily.
What carries the argument
Bounded confidence applied to interval-based opinion homophily, measured as the concentration of users' interaction neighborhoods relative to random expectation in sentiment-derived opinion space.
If this is right
- Stronger social ties produce greater opinion concentration within interaction neighborhoods.
- More polarized issues produce greater opinion homophily than less polarized ones.
- Tolerance ranges are asymmetric and directed toward locally mainstream positions.
- The observed patterns are consistent with a bounded confidence mechanism rather than uniform random mixing.
Where Pith is reading between the lines
- Platform recommendation systems that prioritize similar users could further tighten these opinion neighborhoods over time.
- The mainstream-directed asymmetry may cause moderate opinions to spread farther than extreme ones within the same network.
- Repeating the neighborhood-concentration test on new platforms or issues would show whether bounded confidence is a general feature of online interaction.
- Models of opinion dynamics that incorporate asymmetric tolerance could be calibrated directly against the reported concentration statistics.
Load-bearing premise
Sentiment analysis combined with fact-checking accurately quantifies users' true opinions on polarizing issues, and reply-based and follow-based networks faithfully represent the relevant social ties without major selection biases.
What would settle it
Recomputing neighborhood concentration after randomly reassigning opinions while preserving network structure; if the concentration level matches the original data, the claim of non-random opinion clustering would be falsified.
Figures




read the original abstract
The concept of homophily is pervasive in online social media. While many empirical studies have relied on external sociodemographic traits to investigate it, significantly less is known about homophily at the cognitive level, that is, at the level of shared opinions or values. For such "value homophily", in this paper we study interval-based patterns of opinion homophily from a bounded confidence perspective. We consider three heterogeneous datasets from Reddit and Twitter covering polarizing issues, with user opinions quantified via sentiment analysis and fact-checking, and analyze the interaction networks formed by weaker (reply-based) and stronger (follow-based) social ties. Our findings show that users' interaction neighborhoods are significantly more concentrated in opinion space than expected by chance, with tie strength and issue polarization further amplifying this effect. Moreover, users often exhibit asymmetric tolerance ranges, with asymmetry typically directed toward locally mainstream positions rather than more radical or opposing ones. These findings support a bounded confidence interpretation of online value homophily.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates value homophily in online social networks from a bounded confidence perspective. It analyzes three heterogeneous datasets from Reddit and Twitter on polarizing issues, with user opinions quantified via sentiment analysis and fact-checking. The authors examine interaction networks based on weaker (reply) and stronger (follow) ties, claiming that users' neighborhoods are significantly more concentrated in opinion space than expected by chance, with this effect amplified by tie strength and issue polarization. They additionally report asymmetric tolerance ranges, typically directed toward locally mainstream positions, and interpret the results as supporting bounded confidence models of online value homophily.
Significance. If the empirical claims hold after addressing validation and statistical gaps, the work would provide a quantitative bridge between bounded confidence theory and large-scale social media data, offering evidence that opinion similarity shapes interaction patterns beyond demographic homophily. The distinction between tie strengths and the focus on asymmetry are potentially valuable contributions to polarization research. However, the current lack of validation for the core opinion-measurement pipeline and missing statistical details substantially limit the immediate significance and interpretability of the findings.
major comments (3)
- [§3] §3 (opinion quantification pipeline): The mapping of posts to scalar opinion values relies on sentiment analysis combined with fact-checking, yet no validation is reported against manual labels, surveys, inter-annotator agreement, or external ground truth on the same Reddit/Twitter threads. Systematic biases (sarcasm, hedging, or fact-checker framing) could artifactually inflate both the reported concentration excess and the direction of asymmetry, directly undermining the central empirical claims.
- [Results] Results section (concentration and baseline comparison): The claim that neighborhoods are 'significantly more concentrated than expected by chance' lacks any description of the null model construction (e.g., how opinions or edges are randomized), sample sizes per dataset, statistical tests used, effect sizes, or controls for confounders such as degree distributions or activity levels. Without these, the support for the homophily finding cannot be evaluated.
- [Results] Results section (asymmetric tolerance): The finding that asymmetry is 'typically directed toward locally mainstream positions' does not specify how tolerance ranges are operationalized from the data, how directionality is quantified, or how 'mainstream' is defined relative to the local neighborhood. This measurement detail is load-bearing for the bounded-confidence interpretation.
minor comments (2)
- [Abstract] The abstract refers to 'three heterogeneous datasets' without providing basic descriptors such as number of users, posts, or time spans, which would aid assessment of scope and generalizability.
- [Methods] Notation for opinion scores and tolerance intervals should be defined more explicitly early in the methods to avoid ambiguity when comparing across tie types.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments identify important gaps in validation, statistical detail, and measurement clarity that we will address through targeted revisions. Below we respond point-by-point to the three major comments.
read point-by-point responses
-
Referee: [§3] §3 (opinion quantification pipeline): The mapping of posts to scalar opinion values relies on sentiment analysis combined with fact-checking, yet no validation is reported against manual labels, surveys, inter-annotator agreement, or external ground truth on the same Reddit/Twitter threads. Systematic biases (sarcasm, hedging, or fact-checker framing) could artifactually inflate both the reported concentration excess and the direction of asymmetry, directly undermining the central empirical claims.
Authors: We agree that explicit validation strengthens the pipeline. The original manuscript employed established tools (VADER for sentiment and verified fact-checking organizations) whose performance has been documented in prior literature, yet we did not report dataset-specific checks. In the revision we will add a dedicated validation subsection to §3 that reports (i) inter-annotator agreement (Cohen’s κ) on a stratified random sample of 500 posts per dataset labeled by two independent coders, (ii) comparison against a small set of manually annotated ground-truth threads, and (iii) sensitivity analyses that quantify the impact of sarcasm and hedging on the resulting opinion distributions. These additions will allow readers to assess potential systematic biases. revision: yes
-
Referee: [Results] Results section (concentration and baseline comparison): The claim that neighborhoods are 'significantly more concentrated than expected by chance' lacks any description of the null model construction (e.g., how opinions or edges are randomized), sample sizes per dataset, statistical tests used, effect sizes, or controls for confounders such as degree distributions or activity levels. Without these, the support for the homophily finding cannot be evaluated.
Authors: We apologize for the missing methodological transparency. The null model is a degree-preserving random rewiring (configuration-model variant) that also preserves the marginal opinion distribution. In the revised Results section we will explicitly state: sample sizes (e.g., 12 450 users and 87 300 edges for the first Reddit dataset), the exact randomization procedure, the statistical test (two-sample Kolmogorov–Smirnov with Bonferroni correction), effect sizes (Cohen’s d and Cliff’s delta), and controls for activity level and degree distribution via propensity-score matching. These details will be accompanied by a short supplementary methods paragraph. revision: yes
-
Referee: [Results] Results section (asymmetric tolerance): The finding that asymmetry is 'typically directed toward locally mainstream positions' does not specify how tolerance ranges are operationalized from the data, how directionality is quantified, or how 'mainstream' is defined relative to the local neighborhood. This measurement detail is load-bearing for the bounded-confidence interpretation.
Authors: We will add a precise operationalization paragraph. Tolerance range for each user is defined as the smallest interval containing 95 % of the opinions of that user’s neighbors. Directionality is quantified by the signed offset between the user’s own opinion and the neighborhood median; asymmetry is the ratio of left- versus right-side tolerance widths. “Locally mainstream” is operationalized as the median opinion within the focal user’s neighborhood. The revised manuscript will include these definitions together with illustrative figures and a robustness check using alternative quantiles (90 % and 99 %). revision: yes
Circularity Check
No circularity: purely empirical comparison against null models on external data
full rationale
The paper performs direct statistical tests on three external Reddit/Twitter datasets: opinions are mapped to scalars via sentiment analysis plus fact-checking, interaction neighborhoods are measured in opinion space, and concentration is compared to randomized baselines. No equations, fitted parameters, or self-citations are invoked to derive the reported homophily or asymmetry results; the findings are generated by applying standard null-model testing to the observed networks. The central claims therefore do not reduce to their inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Opinion dynamics and bounded confidence models, analysis, and simulation.Journal of Artificial Societies and Social Simulation, 5(3):2, 2002
Rainer Hegselmann and Ulrich Krause. Opinion dynamics and bounded confidence models, analysis, and simulation.Journal of Artificial Societies and Social Simulation, 5(3):2, 2002
2002
-
[2]
Bounded confi- dence opinion dynamics: A survey.Automatica, 159:111302, 2024
Carmela Bernardo, Claudio Altafini, Anton Proskurnikov, and Francesco Vasca. Bounded confi- dence opinion dynamics: A survey.Automatica, 159:111302, 2024
2024
-
[3]
Change my mind: Data driven estimate of open-mindedness from political discussions
Valentina Pansanella, Virginia Morini, Tiziano Squartini, and Giulio Rossetti. Change my mind: Data driven estimate of open-mindedness from political discussions. InInternational Conference on Complex Networks and Their Applications, pages 86–97. Springer, 2022
2022
-
[4]
The Pushshift Reddit dataset
Jason Baumgartner, Savvas Zannettou, Brian Keegan, Megan Squire, and Jeremy Blackburn. The Pushshift Reddit dataset. InProceedings of the International AAAI Conference on Web and Social Media, volume 14, pages 830–839, 2020
2020
-
[5]
Toward a standard approach for echo chamber detection: Reddit case study.Applied Sciences, 11(12):5390, 2021
Virginia Morini, Laura Pollacci, and Giulio Rossetti. Toward a standard approach for echo chamber detection: Reddit case study.Applied Sciences, 11(12):5390, 2021
2021
-
[6]
Capturing political polarization of Reddit submissions in the Trump Era
Virginia Morini, Laura Pollacci, and Giulio Rossetti. Capturing political polarization of Reddit submissions in the Trump Era. InSEBD, pages 80–87, 2020
2020
-
[7]
Fine-grained sentiment classification using BERT
Manish Munikar, Sushil Shakya, and Aakash Shrestha. Fine-grained sentiment classification using BERT. In2019 Artificial Intelligence for Transforming Business and Society (AITB), volume 1, pages 1–5. IEEE, 2019
2019
-
[8]
Monitoring the public opinion about the vaccination topic from tweets analysis.Expert Systems with Applications, 116:209–226, 2019
Eleonora D’Andrea, Pietro Ducange, Alessio Bechini, Alessandro Renda, and Francesco Marcelloni. Monitoring the public opinion about the vaccination topic from tweets analysis.Expert Systems with Applications, 116:209–226, 2019
2019
-
[9]
Worldwide COVID-19 vaccines sentiment analysis through Twitter content.Electronic Journal of General Medicine, 18(6):em329, 2021
Md Tarique Jamal Ansari and Naseem Ahmad Khan. Worldwide COVID-19 vaccines sentiment analysis through Twitter content.Electronic Journal of General Medicine, 18(6):em329, 2021
2021
-
[10]
AIB- ERTo: Modeling Italian social media language with BERT.IJCoL
Marco Polignano, Valerio Basile, Pierpaolo Basile, Marco de Gemmis, and Giovanni Semeraro. AIB- ERTo: Modeling Italian social media language with BERT.IJCoL. Italian Journal of Computational Linguistics, 5(5-2):11–31, 2019
2019
-
[11]
An effective BERT-based pipeline for Twitter sentiment analysis: a case study in Italian.Sensors, 21(1):133, 2021
Marco Pota, Mirko Ventura, Rosario Catelli, and Massimo Esposito. An effective BERT-based pipeline for Twitter sentiment analysis: a case study in Italian.Sensors, 21(1):133, 2021
2021
-
[12]
Fine-grained sentiment analysis of Arabic COVID-19 tweets using BERT-based transformers and dynamically weighted loss function.Applied Sciences, 11(22):10694, 2021
Nora Alturayeif and Hamzah Luqman. Fine-grained sentiment analysis of Arabic COVID-19 tweets using BERT-based transformers and dynamically weighted loss function.Applied Sciences, 11(22):10694, 2021
2021
-
[13]
SENTIPOLC 2016: Sentiment polarity classification, 2016
SENTIPOLC EVALITA Team. SENTIPOLC 2016: Sentiment polarity classification, 2016. Ac- cessed: March 5, 2025
2016
-
[14]
How to fine-tune BERT for text classification? InChina National Conference on Chinese Computational Linguistics, pages 194–206
Chi Sun, Xipeng Qiu, Yige Xu, and Xuanjing Huang. How to fine-tune BERT for text classification? InChina National Conference on Chinese Computational Linguistics, pages 194–206. Springer, 2019
2019
-
[15]
Quantifying ideological polarization on a network using generalized Euclidean distance.Science Advances, 9(9):eabq2044, 2023
Marilena Hohmann, Karel Devriendt, and Michele Coscia. Quantifying ideological polarization on a network using generalized Euclidean distance.Science Advances, 9(9):eabq2044, 2023. 23
2023
-
[16]
The echo chamber effect on social media.Proceedings of the National Academy of Sciences, 118(9):e2023301118, 2021
Matteo Cinelli, Gianmarco De Francisci Morales, Alessandro Galeazzi, Walter Quattrociocchi, and Michele Starnini. The echo chamber effect on social media.Proceedings of the National Academy of Sciences, 118(9):e2023301118, 2021
2021
-
[17]
2020 United States presidential election, 2021
Laura Wrubel and Daniel Kerchner. 2020 United States presidential election, 2021
2020
-
[18]
Factoring and weighting approaches to status scores and clique identification
Phillip Bonacich. Factoring and weighting approaches to status scores and clique identification. Journal of Mathematical Sociology, 2(1):113–120, 1972
1972
-
[19]
Modularity and community structure in networks.Proceedings of the National Academy of Sciences, 103(23):8577–8582, 2006
Mark EJ Newman. Modularity and community structure in networks.Proceedings of the National Academy of Sciences, 103(23):8577–8582, 2006
2006
-
[20]
A new status index derived from sociometric analysis.Psychometrika, 18(1):39–43, 1953
Leo Katz. A new status index derived from sociometric analysis.Psychometrika, 18(1):39–43, 1953
1953
-
[21]
Power and centrality: A family of measures.American Journal of Sociology, 92(5):1170–1182, 1987
Phillip Bonacich. Power and centrality: A family of measures.American Journal of Sociology, 92(5):1170–1182, 1987. 24
1987
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.