Recognition: unknown
From Coarse to Fine: Self-Adaptive Hierarchical Planning for LLM Agents
Pith reviewed 2026-05-08 08:05 UTC · model grok-4.3
The pith
LLM agents improve multi-step task success by starting with coarse plans and refining detail only as task complexity requires.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
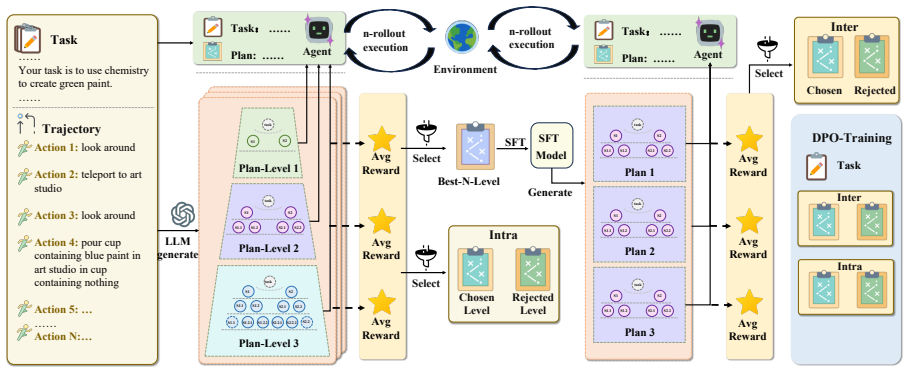
AdaPlan-H initiates with a coarse-grained macro plan and progressively refines it based on task complexity, generating self-adaptive hierarchical plans tailored to varying difficulty levels that are optimized by imitation learning and capability enhancement, leading to higher task execution success rates and reduced overplanning.
What carries the argument
Self-adaptive hierarchical planning mechanism that starts with a coarse macro plan and refines progressively to match task complexity.
If this is right
- Task execution success rates rise for multi-step decision problems.
- Overplanning is reduced at the planning stage across varying task difficulties.
- The method supplies a flexible solution adaptable to both simple and complex tasks.
- Plans can be further improved through imitation learning and capability enhancement.
Where Pith is reading between the lines
- The same coarse-to-fine adaptation could be tested in non-LLM agent systems to check broader applicability.
- Resource consumption during planning might drop when simple subtasks avoid unnecessary detail.
- Integration with automatic complexity estimation could remove the need for external signals to trigger refinement.
- Future agent designs might embed similar progressive mechanisms to scale better with environment size.
Load-bearing premise
That a progressive refinement strategy from cognitive science can be translated into an effective, learnable planning procedure for large language model agents.
What would settle it
A controlled comparison on standard benchmarks where AdaPlan-H produces no measurable gain in task completion rates or no reduction in overplanning compared to fixed-granularity baselines.
Figures



read the original abstract
Large language model-based agents have recently emerged as powerful approaches for solving dynamic and multi-step tasks. Most existing agents employ planning mechanisms to guide long-term actions in dynamic environments. However, current planning approaches face a fundamental limitation that they operate at a fixed granularity level. Specifically, they either provide excessive detail for simple tasks or insufficient detail for complex ones, failing to achieve an optimal balance between simplicity and complexity. Drawing inspiration from the principle of \textit{progressive refinement} in cognitive science, we propose \textbf{AdaPlan-H}, a self-adaptive hierarchical planning mechanism that mimics human planning strategies. Our method initiates with a coarse-grained macro plan and progressively refines it based on task complexity. It generates self-adaptive hierarchical plans tailored to the varying difficulty levels of different tasks, which can be optimized by imitation learning and capability enhancement. Experimental results demonstrate that our method significantly improves task execution success rates while mitigating overplanning at the planning level, providing a flexible and efficient solution for multi-step complex decision-making tasks. To contribute to the community, our code and data will be made publicly available at https://github.com/import-myself/AHP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AdaPlan-H, a self-adaptive hierarchical planning mechanism for LLM agents. Drawing from progressive refinement in cognitive science, the method starts with a coarse-grained macro plan and progressively refines it according to detected task complexity, generating plans tailored to varying difficulty levels. The framework is optimized via imitation learning and capability enhancement. The authors report that experiments on standard agent benchmarks for multi-step complex decision-making tasks demonstrate significant gains in task execution success rates together with reduced overplanning.
Significance. If the experimental results hold, the work addresses a practical limitation of fixed-granularity planning in LLM agents by enabling adaptive detail levels, which could improve both efficiency and reliability on dynamic tasks. The commitment to releasing code and data publicly supports reproducibility and community follow-up.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our work and the recommendation to accept the paper. We appreciate that the significance of the adaptive hierarchical planning approach was recognized, particularly its potential to address fixed-granularity limitations in LLM agents.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes a new method (AdaPlan-H) for self-adaptive hierarchical planning in LLM agents, drawing external inspiration from cognitive science on progressive refinement. It describes the coarse-to-fine mechanism, its implementation via imitation learning and capability enhancement, and validates improvements through experiments on standard benchmarks. No equations, self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text or abstract. The central claims rest on the described architecture and empirical results rather than reducing to inputs by construction, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Progressive refinement from cognitive science applies directly to LLM agent planning and can be mimicked via self-adaptive hierarchies
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review arXiv 2023
- [2]
- [3]
-
[4]
Carlos G Correa, Sophia Sanborn, Mark K Ho, Frederick Callaway, Nathaniel D Daw, and Thomas L Griffiths. 2025. Exploring the hierarchical structure of human plans via program generation. Cognition, 255:105990
2025
-
[5]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, and 1 others. 2024. The llama 3 herd of models. arXiv e-prints, pages arXiv--2407
2024
- [6]
-
[7]
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. 2025. Group-in-group policy optimization for llm agent training. arXiv preprint arXiv:2505.10978
work page internal anchor Pith review arXiv 2025
-
[8]
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Juanzi Li, and 37 others. 2024. https://arxiv.org/abs/2406.12793 Chatglm: A family of large language models from glm-130b to glm-4 all tools . Prep...
work page internal anchor Pith review arXiv 2024
-
[9]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, and 1 others. 2022. Lora: Low-rank adaptation of large language models. ICLR, 1(2):3
2022
- [10]
-
[11]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles, pages 611--626
2023
-
[12]
Bo Liu, Yuqian Jiang, Xiaohan Zhang, Qiang Liu, Shiqi Zhang, Joydeep Biswas, and Peter Stone. 2023. Llm+ p: Empowering large language models with optimal planning proficiency. arXiv preprint arXiv:2304.11477
work page internal anchor Pith review arXiv 2023
- [13]
- [14]
- [15]
-
[16]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300
work page internal anchor Pith review arXiv 2024
-
[17]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36:8634--8652
2023
-
[18]
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre C \^o t \'e , Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. 2020. Alfworld: Aligning text and embodied environments for interactive learning. arXiv preprint arXiv:2010.03768
work page internal anchor Pith review arXiv 2020
- [19]
- [20]
-
[21]
Qwen Team. 2024. https://qwenlm.github.io/blog/qwen2.5/ Qwen2.5: A party of foundation models
2024
-
[22]
Qwen Team. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
work page internal anchor Pith review arXiv 2025
- [23]
-
[24]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, and 1 others. 2024. A survey on large language model based autonomous agents. Frontiers of Computer Science, 18(6):186345
2024
- [25]
- [26]
- [27]
- [28]
-
[29]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023 a . Tree of thoughts: Deliberate problem solving with large language models. Advances in neural information processing systems, 36:11809--11822
2023
-
[30]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023 b . React: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR)
2023
-
[31]
Jeffrey M Zacks, Barbara Tversky, and Gowri Iyer. 2001. Perceiving, remembering, and communicating structure in events. Journal of experimental psychology: General, 130(1):29
2001
- [32]
- [33]
-
[34]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, and 1 others. 2023. A survey of large language models. arXiv preprint arXiv:2303.18223
work page internal anchor Pith review arXiv 2023
-
[35]
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. 2024. Llamafactory: Unified efficient fine-tuning of 100+ language models. arXiv preprint arXiv:2403.13372
work page internal anchor Pith review arXiv 2024
-
[36]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[37]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.