Recognition: unknown
Spectro-Temporal Modulation Representation Framework for Human-Imitated Speech Detection
Pith reviewed 2026-05-08 06:53 UTC · model grok-4.3
The pith
Spectro-temporal modulation representations detect human-imitated speech at or above human accuracy levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
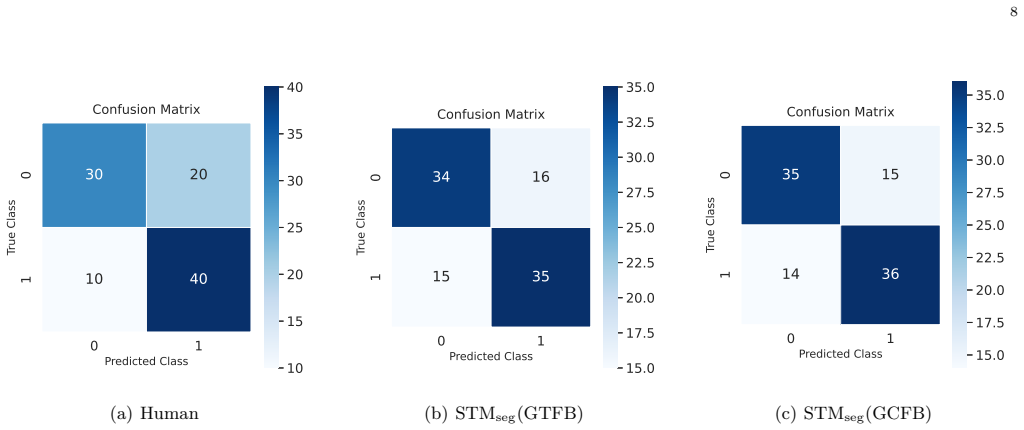
Spectro-Temporal Modulation (STM) representations from Gammatone Filterbank (GTFB) and Gammachirp Filterbank (GCFB) capture temporal and spectral fluctuations corresponding to human auditory perception, enabling effective detection of human-imitated speech. The Segmental-STM variant, using overlapping time windows, proves more effective and surpasses human perceptual performance.
What carries the argument
The Spectro-Temporal Modulation (STM) representation, computed from cochlear filterbank models to jointly capture changes in the spectrogram over time and variations along the frequency axis.
If this is right
- Voice authentication systems gain a tool to counter natural human forgeries that lack artificial artifacts.
- Segmental analysis of modulations offers higher temporal resolution for detecting subtle variations in speech.
- Perceptually motivated features can match or exceed human capabilities in specific detection tasks.
- The framework shows promise for improving robustness against imitation-based speech attacks.
Where Pith is reading between the lines
- Explicit computation of modulation patterns may reveal what specific cues humans use to spot imitations.
- These representations could be tested for generalization to other types of speech manipulation or languages.
- Optimizing the filterbank parameters on independent data might further improve performance without evaluation set bias.
Load-bearing premise
The parameters of the Gammatone and Gammachirp filterbanks together with the chosen segmental windowing scheme accurately model the exact perceptual cues that humans rely on to detect imitated speech.
What would settle it
A new collection of genuine and human-imitated speech samples, evaluated by both the STM detector and a group of human listeners, where the automatic system's accuracy is lower than the humans' average accuracy.
Figures


read the original abstract
Human-imitated speech poses a greater challenge than AI-generated speech for both human listeners and automatic detection systems. Unlike AI-generated speech, which often contains artifacts, over-smoothed spectra, or robotic cues, imitated speech is produced naturally by humans, thereby preserving a higher degree of naturalness that makes imitation-based speech forgery significantly more challenging to detect using conventional acoustic or cepstral features. To overcome this challenge, this study proposes an auditory perception-based Spectro-Temporal Modulation (STM) representation framework for human-imitated speech detection. The STM representations are derived from two cochlear filterbank models: the Gammatone Filterbank (GTFB), which simulates frequency selectivity and can be regarded as a first approximation of cochlear filtering, and the Gammachirp Filterbank (GCFB), which further models both frequency selectivity and level-dependent asymmetry. These STM representations jointly capture temporal and spectral fluctuations in speech signals, corresponding to changes over time in the spectrogram and variations along the frequency axis related to human auditory perception. We also introduce a Segmental-STM representation to analyze short-term modulation patterns across overlapping time windows, enabling high-resolution modeling of temporal speech variations. Experimental results show that STM representations are effective for human-imitated speech detection, achieving accuracy levels close to those of human listeners. In addition, Segmental-STM representations are more effective, surpassing human perceptual performance. The findings demonstrate that perceptually inspired spectro-temporal modeling is promising for detecting imitation-based speech attacks and improving voice authentication robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an auditory-inspired Spectro-Temporal Modulation (STM) framework for detecting human-imitated speech, deriving representations from Gammatone Filterbank (GTFB) and Gammachirp Filterbank (GCFB) models to capture spectro-temporal fluctuations. It further introduces Segmental-STM using overlapping windows for short-term modulation analysis. The central claim is that STM achieves detection accuracy close to human listeners while Segmental-STM surpasses human perceptual performance, offering a promising approach for voice authentication against imitation attacks.
Significance. If the experimental claims hold after proper validation, the work would be significant for speech forensics and biometric security, as it targets the harder problem of natural human imitation (distinct from artifact-prone AI synthesis) with perceptually motivated features that could enhance robustness in voice authentication systems where conventional cepstral methods fall short.
major comments (3)
- [Abstract] Abstract: The headline claim that 'Segmental-STM representations are more effective, surpassing human perceptual performance' is presented without any description of the human listener experiments (listener pool size, test conditions, stimuli), dataset details (number of speakers, imitation generation protocol, train/test splits), or quantitative margins, making the central performance assertion impossible to evaluate.
- [Abstract] Abstract and method description: The GTFB and GCFB parameters (center frequencies, bandwidths, chirp rates, number of channels) and segmental window length/overlap are introduced without stating whether they were fixed a priori from auditory literature or selected/adjusted by maximizing accuracy on the held-out imitation-speech test set; if the latter, the reported superiority over humans is not evidence of perceptual fidelity but potential overfitting, directly undermining the weakest assumption in the claims.
- [Abstract] Abstract: No baseline comparisons, statistical tests (e.g., significance of accuracy differences), or error analysis are mentioned despite the strong performance assertions, leaving the effectiveness of STM vs. conventional acoustic/cepstral features unverified and the soundness of the experimental outcomes at 3.0.
minor comments (2)
- [Abstract] The abstract uses 'derived from' for the STM representations but does not clarify the exact mathematical formulation (e.g., modulation extraction steps) until later sections; adding a brief equation reference in the abstract would improve clarity.
- [Abstract] Notation for STM and Segmental-STM is introduced without an early table or diagram summarizing the pipeline differences, which would aid readers in distinguishing the two representations.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below. Where the comments identify gaps in the abstract's self-contained presentation of experimental details, we agree that revisions are warranted to improve evaluability while preserving the manuscript's focus.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that 'Segmental-STM representations are more effective, surpassing human perceptual performance' is presented without any description of the human listener experiments (listener pool size, test conditions, stimuli), dataset details (number of speakers, imitation generation protocol, train/test splits), or quantitative margins, making the central performance assertion impossible to evaluate.
Authors: We agree that the abstract's length constraint omitted key contextual details needed for immediate evaluation. The full manuscript describes the human listener experiments (including listener pool size, test conditions, and stimuli), the dataset (speakers, imitation generation protocol, and train/test splits), and quantitative margins in the Experimental Setup and Results sections. To make the abstract self-contained, we will revise it to include concise references to these elements and the performance margins. revision: yes
-
Referee: [Abstract] Abstract and method description: The GTFB and GCFB parameters (center frequencies, bandwidths, chirp rates, number of channels) and segmental window length/overlap are introduced without stating whether they were fixed a priori from auditory literature or selected/adjusted by maximizing accuracy on the held-out imitation-speech test set; if the latter, the reported superiority over humans is not evidence of perceptual fidelity but potential overfitting, directly undermining the weakest assumption in the claims.
Authors: The GTFB and GCFB parameters were fixed a priori using standard values from the auditory literature on cochlear filtering (center frequencies, bandwidths, chirp rates, and channel counts), and the segmental window length/overlap were selected based on typical speech modulation timescales without any optimization or selection on the held-out test set. We will add explicit statements in both the abstract and method sections clarifying this a-priori choice to eliminate any ambiguity regarding overfitting. revision: yes
-
Referee: [Abstract] Abstract: No baseline comparisons, statistical tests (e.g., significance of accuracy differences), or error analysis are mentioned despite the strong performance assertions, leaving the effectiveness of STM vs. conventional acoustic/cepstral features unverified and the soundness of the experimental outcomes at 3.0.
Authors: The abstract prioritizes the novel STM framework and headline results; however, the full manuscript presents baseline comparisons against conventional cepstral and acoustic features, statistical significance tests on accuracy differences, and error analysis in the Results section. We concur that a brief mention would strengthen the abstract. We will revise the abstract to note the baseline comparisons and statistical validation of the reported improvements. revision: yes
Circularity Check
No circularity: claims rest on experimental outcomes using standard auditory filterbanks
full rationale
The paper derives STM representations from established Gammatone and Gammachirp filterbank models (standard in auditory literature) and introduces segmental windows as an analysis extension. Performance claims are supported solely by experimental detection accuracies on imitation-speech data, with no equations, fitted parameters, or self-citations that reduce the reported results to definitional equivalence or post-hoc optimization by construction. The derivation chain is independent of the target detection task and does not invoke uniqueness theorems or ansatzes from the authors' prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gammatone and Gammachirp filterbanks provide a sufficiently accurate model of human cochlear frequency selectivity and level-dependent asymmetry for speech detection purposes
invented entities (2)
-
Spectro-Temporal Modulation (STM) representation
no independent evidence
-
Segmental-STM representation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Dictionary attacks on speaker verification,
M. Marras, P. Korus, A. Jain, and N. Memon, “Dictionary attacks on speaker verification,” IEEE Transactions on Infor- mation Forensics and Security, vol. 18, pp. 773–788, 2023
2023
-
[2]
Speaker anonymization for voice biometrics protection using voice conversion and multi- target speaker voice fusion,
Y. A. Wubet and K.-Y. Lian, “Speaker anonymization for voice biometrics protection using voice conversion and multi- target speaker voice fusion,” IEEE Transactions on Information Forensics and Security, 2025
2025
-
[3]
Securing voice biometrics: One-shot learning approach for audio deepfake detection,
A. Khan and K. M. Malik, “Securing voice biometrics: One-shot learning approach for audio deepfake detection,” in 2023 IEEE international workshop on information forensics and security (WIFS). IEEE, 2023, pp. 1–6
2023
-
[4]
Deep4snet: deep learning for fake speech classification,
D. M. Ballesteros, Y. Rodriguez-Ortega, D. Renza, and G. Arce, “Deep4snet: deep learning for fake speech classification,” Expert Systems with Applications, vol. 184, p. 115465, 2021
2021
-
[5]
Deepfake speech detection: approaches from acoustic features related to auditory perception to deep neural net- works,
M. Unoki, K. Li, A. Chaiwongyen, Q.-H. Nguyen, and K. Zaman, “Deepfake speech detection: approaches from acoustic features related to auditory perception to deep neural net- works,” IEICE Transactions on Information and Systems, 2024
2024
-
[6]
Hybrid transformer architectures with diverse audio features for deepfake speech classification,
K. Zaman, I. J. Samiul, M. Sah, C. Direkoglu, S. Okada, and M. Unoki, “Hybrid transformer architectures with diverse audio features for deepfake speech classification,” IEEE Access, vol. 12, pp. 149 221–149 237, 2024
2024
-
[7]
Fake speech detection using vggish with attention block,
T. Kanwal, R. Mahum, A. M. AlSalman, M. Sharaf, and H. Has- san, “Fake speech detection using vggish with attention block,” EURASIP Journal on Audio, Speech, and Music Processing, vol. 2024, no. 1, p. 35, 2024
2024
-
[8]
Tacotron: Towards end-to-end speech synthesis,
Y. Wang, R. Skerry-Ryan, D. Stanton, Y. Wu, R. J. Weiss, N. Jaitly, Z. Yang, Y. Xiao, Z. Chen, S. Bengio et al., “Tacotron: Towards end-to-end speech synthesis,” in Proc. Interspeech 2017, 2017, pp. 4006–4010
2017
-
[9]
Natural tts synthesis by conditioning wavenet on mel spectrogram pre- dictions,
J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang, Z. Chen, Y. Zhang, Y. Wang, R. Skerrv-Ryan et al., “Natural tts synthesis by conditioning wavenet on mel spectrogram pre- dictions,” in 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018, pp. 4779– 4783
2018
-
[10]
Wavenet: A generative model for raw audio,
A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, “Wavenet: A generative model for raw audio,” in Proc. SSW 2016, 2016, pp. 125–125
2016
-
[11]
Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram,
R. Yamamoto, E. Song, and J.-M. Kim, “Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram,” in ICASSP 2020- 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6199–6203
2020
-
[12]
Mel- gan: Generative adversarial networks for conditional waveform synthesis,
K. Kumar, R. Kumar, T. De Boissiere, L. Gestin, W. Z. Teoh, J. Sotelo, A. De Brebisson, Y. Bengio, and A. C. Courville, “Mel- gan: Generative adversarial networks for conditional waveform synthesis,” Advances in neural information processing systems, vol. 32, 2019
2019
-
[13]
DiffWave: A Versatile Diffusion Model for Audio Synthesis
Z. Kong, W. Ping, J. Huang, K. Zhao, and B. Catanzaro, “Diffwave: A versatile diffusion model for audio synthesis,” arXiv preprint arXiv:2009.09761, 2020
work page internal anchor Pith review arXiv 2009
-
[14]
Automatic speaker verification spoofing and countermeasures challenge (asvspoof 2015) database,
T. Kinnunen, Z. Wu, E. Nicholas Evans, and J. Yamagishi, “Automatic speaker verification spoofing and countermeasures challenge (asvspoof 2015) database,” 2018
2015
-
[15]
The 2nd automatic speaker verification spoofing and countermeasures challenge (asvspoof 2017) database, version 2,
T. Kinnunen, M. Sahidullah, E. Héctor Delgado, E. Massim- iliano Todisco, E. Nicholas Evans, J. Yamagishi, and K. A. Lee, “The 2nd automatic speaker verification spoofing and countermeasures challenge (asvspoof 2017) database, version 2,” 2018
2017
-
[16]
The asvspoof 2017 challenge: Assessing the limits of replay spoofing attack detection,
T. Kinnunen, M. Sahidullah, H. Delgado, M. Todisco, N. Evans, J. Yamagishi, and K. A. Lee, “The asvspoof 2017 challenge: Assessing the limits of replay spoofing attack detection,” in Interspeech 2017. International Speech Communication As- sociation, 2017, pp. 2–6
2017
-
[17]
Asvspoof 2019: A large-scale public database of synthesized, converted and replayed speech,
X. Wang, J. Yamagishi, M. Todisco, H. Delgado, A. Nautsch, N. Evans, M. Sahidullah, V. Vestman, T. Kinnunen, K. A. Lee et al., “Asvspoof 2019: A large-scale public database of synthesized, converted and replayed speech,” Computer Speech & Language, vol. 64, p. 101114, 2020
2019
-
[18]
Asvspoof 2021: Towards spoofed and deepfake speech detection in the wild,
X. Liu, X. Wang, M. Sahidullah, J. Patino, H. Delgado, T. Kin- nunen, M. Todisco, J. Yamagishi, N. Evans, A. Nautsch et al., “Asvspoof 2021: Towards spoofed and deepfake speech detection in the wild,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2507–2522, 2023
2021
-
[19]
Asvspoof 5: crowdsourced speech data, deepfakes, and adversarial attacks at scale,
X. Wang, H. Delgado, H. Tak, J.-w. Jung, H.-j. Shim, M. Todisco, I. Kukanov, X. Liu, M. Sahidullah, T. H. Kinnunen et al., “Asvspoof 5: crowdsourced speech data, deepfakes, and adversarial attacks at scale,” in Proc. ASVspoof 2024, 2024, pp. 1–8
2024
-
[20]
Add 2022: the first audio deep synthesis detection challenge,
J. Yi, R. Fu, J. Tao, S. Nie, H. Ma, C. Wang, T. Wang, Z. Tian, Y. Bai, C. Fan et al., “Add 2022: the first audio deep synthesis detection challenge,” in In Proc. ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 9216–9220
2022
-
[21]
Add 2023: the second audio deepfake detection challenge,
J. Yi, J. Tao, R. Fu, X. Yan, C. Wang, T. Wang, C. Y. Zhang, X. Zhang, Y. Zhao, Y. Ren et al., “Add 2023: the second audio deepfake detection challenge,” in CEUR Workshop Proceedings, vol. 3597, 2023, pp. 125–130
2023
-
[22]
For: A dataset for synthetic speech detection,
R. Reimao and V. Tzerpos, “For: A dataset for synthetic speech detection,” in 2019 International Conference on Speech Technology and Human-Computer Dialogue (SpeD). IEEE, 2019, pp. 1–10
2019
-
[23]
Cfad: A chinese dataset for fake audio detection,
H. Ma, J. Yi, C. Wang, X. Yan, J. Tao, T. Wang, S. Wang, and R. Fu, “Cfad: A chinese dataset for fake audio detection,” Speech Communication, vol. 164, p. 103122, 2024
2024
-
[24]
Touch-based continuous mobile device authentication: State- of-the-art, challenges and opportunities,
A. Z. Zaidi, C. Y. Chong, Z. Jin, R. Parthiban, and A. S. Sadiq, “Touch-based continuous mobile device authentication: State- of-the-art, challenges and opportunities,” Journal of Network and Computer Applications, vol. 191, p. 103162, 2021
2021
-
[25]
Does audio deepfake detection generalize?
N. Müller, P. Czempin, F. Dieckmann, A. Froghyar, and K. Böt- tinger, “Does audio deepfake detection generalize?” in Inter- 10 national Speech Communication Association (INTERSPEECH Annual Conference) 2022, 2022
2022
-
[26]
Half-truth: A partially fake audio detection dataset,
J. Yi, Y. Bai, J. Tao, H. Ma, Z. Tian, C. Wang, T. Wang, and R. Fu, “Half-truth: A partially fake audio detection dataset,” in Interspeech, 2021
2021
-
[27]
WaveFake: A Data Set to Facilitate Audio Deepfake Detection,
J. Frank and L. Schönherr, “WaveFake: A Data Set to Facilitate Audio Deepfake Detection,” in Thirty-fifth Conference on Neu- ral Information Processing Systems Datasets and Benchmarks Track, 2021
2021
-
[28]
The cmu arctic speech databases,
J. Kominek and A. W. Black, “The cmu arctic speech databases,” in Fifth ISCA workshop on speech synthesis, 2004
2004
-
[29]
Real-time detection of AI-generated speech for deepfake voice conversion,
J. J. Bird and A. Lotfi, “Real-time detection of ai- generated speech for deepfake voice conversion,” arXiv preprint arXiv:2308.12734, 2023
-
[30]
The partialspoof database and countermeasures for the detec- tion of short fake speech segments embedded in an utterance,
L. Zhang, X. Wang, E. Cooper, N. Evans, and J. Yamagishi, “The partialspoof database and countermeasures for the detec- tion of short fake speech segments embedded in an utterance,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 813–825, 2022
2022
-
[31]
The codecfake dataset and countermeasures for the universally detection of deepfake audio,
Y. Xie, Y. Lu, R. Fu, Z. Wen, Z. Wang, J. Tao, X. Qi, X. Wang, Y. Liu, H. Cheng et al., “The codecfake dataset and countermeasures for the universally detection of deepfake audio,” IEEE Transactions on Audio, Speech and Language Processing, 2025
2025
-
[32]
Fmfcc-a: a challenging mandarin dataset for synthetic speech detection,
Z. Zhang, Y. Gu, X. Yi, and X. Zhao, “Fmfcc-a: a challenging mandarin dataset for synthetic speech detection,” in Interna- tional Workshop on Digital Watermarking. Springer, 2021, pp. 117–131
2021
-
[33]
The voice conversion challenge 2018: Promoting development of parallel and non- parallel methods,
J. Lorenzo-Trueba, J. Yamagishi, T. Toda, D. Saito, F. Villav- icencio, T. Kinnunen, and Z. Ling, “The voice conversion challenge 2018: Promoting development of parallel and non- parallel methods,” in The Speaker and Language Recognition Workshop. ISCA, 2018, pp. 195–202
2018
-
[34]
A review of modern audio deepfake detection methods: challenges and future directions,
Z. Almutairi and H. Elgibreen, “A review of modern audio deepfake detection methods: challenges and future directions,” Algorithms, vol. 15, no. 5, p. 155, 2022
2022
-
[35]
Vocal imitation set: a dataset of vocally imitated sound events using the audioset ontology
B. Kim, M. Ghei, B. Pardo, and Z. Duan, “Vocal imitation set: a dataset of vocally imitated sound events using the audioset ontology. ” in DCASE, 2018, pp. 148–152
2018
-
[36]
A machine learning model to detect fake voice,
Y. Rodríguez-Ortega, D. M. Ballesteros, and D. Renza, “A machine learning model to detect fake voice,” in International Conference on Applied Informatics. Springer, 2020, pp. 3–13
2020
-
[37]
Ara- bic audio clips: Identification and discrimination of authentic cantillations from imitations,
M. Lataifeh, A. Elnagar, I. Shahin, and A. B. Nassif, “Ara- bic audio clips: Identification and discrimination of authentic cantillations from imitations,” Neurocomputing, vol. 418, pp. 162–177, 2020
2020
-
[38]
Vocal imitation of per- cussion sounds: On the perceptual similarity between imitations and imitated sounds,
A. Mehrabi, S. Dixon, and M. Sandler, “Vocal imitation of per- cussion sounds: On the perceptual similarity between imitations and imitated sounds,” Plos one, vol. 14, no. 7, p. e0219955, 2019
2019
-
[39]
Detection of speaker characteristics using voice imitation,
E. Zetterholm, “Detection of speaker characteristics using voice imitation,” Speaker classification II: selected projects, pp. 192– 205, 2007
2007
-
[40]
Automatic versus human speaker verification: The case of voice mimicry,
R. G. Hautamäki, T. Kinnunen, V. Hautamäki, and A.-M. Laukkanen, “Automatic versus human speaker verification: The case of voice mimicry,” Speech Communication, vol. 72, pp. 13– 31, 2015
2015
-
[41]
Ability of human auditory perception to distinguish human- imitated speech,
K. Zaman, K. Li, I. J. Samiul, Y. Uezu, S. Kidani, and M. Unoki, “Ability of human auditory perception to distinguish human- imitated speech,” IEEE Access, 2025
2025
-
[42]
Spectrotemporal modulation provides a unifying framework for auditory cortical asymmetries,
A. Flinker, W. K. Doyle, A. D. Mehta, O. Devinsky, and D. Poeppel, “Spectrotemporal modulation provides a unifying framework for auditory cortical asymmetries,” Nature human behaviour, vol. 3, no. 4, pp. 393–405, 2019
2019
-
[43]
Synthetic speech detection using temporal modulation feature,
Z. Wu, X. Xiao, E. S. Chng, and H. Li, “Synthetic speech detection using temporal modulation feature,” in 2013 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing. IEEE, 2013, pp. 7234–7238
2013
-
[44]
Analysis of spectro-temporal modulation representation for deep-fake speech detection,
H. Cheng, C. O. Mawalim, K. Li, L. Wang, and M. Unoki, “Analysis of spectro-temporal modulation representation for deep-fake speech detection,” in 2023 Asia Pacific Signal and Information Processing Association Annual Summit and Con- ference (APSIPA ASC). IEEE, 2023, pp. 1822–1829
2023
-
[45]
Machine anomalous sound detection using spectral-temporal modulation representations derived from machine-specific fil- terbanks,
K. Li, K. Zaman, X. Li, M. Akagi, J. Dang, and M. Unoki, “Machine anomalous sound detection using spectral-temporal modulation representations derived from machine-specific fil- terbanks,” IEEE Transactions on Audio, Speech and Language Processing, 2025
2025
-
[46]
Hearing and aging
M. Bance, “Hearing and aging. ” CMAJ: Canadian Medical Association Journal, vol. 176, no. 7, pp. 925–928, 2007
2007
-
[47]
Robust emotion recogni- tion by spectro-temporal modulation statistic features,
T.-S. Chi, L.-Y. Yeh, and C.-C. Hsu, “Robust emotion recogni- tion by spectro-temporal modulation statistic features,” Journal of Ambient Intelligence and Humanized Computing, vol. 3, no. 1, pp. 47–60, 2012
2012
-
[48]
An efficient auditory filterbank based on the gammatone function,
R. D. Patterson, I. Nimmo-Smith, J. Holdsworth, and P. Rice, “An efficient auditory filterbank based on the gammatone function,” Applied Psychology Unit, Cambridge, UK, APU Report 2341, 1988
1988
-
[49]
A time-domain, level-dependent auditory filter: The gammachirp,
T. Irino and R. Patterson, “A time-domain, level-dependent auditory filter: The gammachirp,” The Journal of the Acoustical Society of America, vol. 101, no. 1, pp. 412–419, 1997
1997
-
[50]
An analysis/synthesis auditory fil- terbank based on an iir implementation of the gammachirp,
T. Irino and M. Unoki, “An analysis/synthesis auditory fil- terbank based on an iir implementation of the gammachirp,” Journal of the Acoustical Society of Japan (E), vol. 20, no. 6, pp. 397–406, 1999
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.