Recognition: unknown
Fine-tuning vs. In-context Learning in Large Language Models: A Formal Language Learning Perspective
Pith reviewed 2026-05-08 08:02 UTC · model grok-4.3
The pith
Fine-tuning achieves greater language proficiency than in-context learning on in-distribution generalization in formal languages, with equal out-of-distribution performance and diverging inductive biases at high proficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
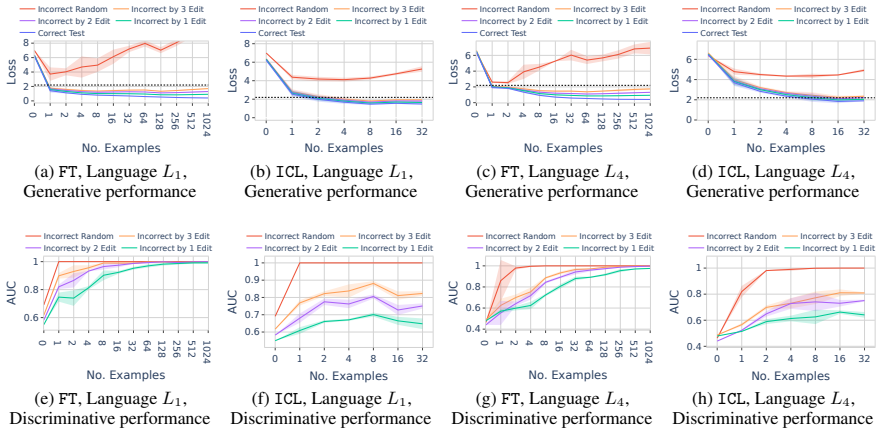
In a formal language learning task, fine-tuning yields greater language proficiency than in-context learning for in-distribution generalization, as measured by higher generation probabilities for in-language strings. Both approaches perform equally on out-of-distribution generalization. Their inductive biases are similar at partial learning levels but diverge at higher proficiency, and in-context learning varies more with model size and token vocabulary.
What carries the argument
The discriminative test for language proficiency, in which an LLM succeeds when it assigns higher generation probability to in-language strings than to out-of-language strings, applied inside a formal language framework that supplies precise boundaries, controlled sampling, and no data contamination.
If this is right
- Fine-tuning should be chosen over in-context learning whenever high in-distribution accuracy on a well-defined language is required.
- In-context learning performance will continue to depend more strongly on the choice of base model and its tokenizer than fine-tuning performance does.
- Inductive biases of the two learning modes remain comparable only while both are still acquiring partial command of the language.
- Formal languages supply a contamination-free testbed that can isolate LLM behaviors otherwise entangled in natural-language datasets.
Where Pith is reading between the lines
- Practitioners could use small formal-language proxies to decide whether fine-tuning or prompting is likely to be more effective for a target task before investing in large-scale training.
- The observed divergence in biases at higher proficiency levels suggests that further scaling or continued training would widen the difference between the two modes rather than close it.
- The same formal-language protocol could be applied to other structured domains, such as programming languages or logical formulas, to obtain clean comparisons free of natural-language leakage.
Load-bearing premise
Assigning higher probability to in-language strings on the formal-language discriminative test accurately measures differences in language proficiency between fine-tuning and in-context learning that would matter for natural language.
What would settle it
Running the identical models on a natural-language task that supplies known in-language and out-of-language strings without contamination and finding that the probability gap between fine-tuning and in-context learning disappears or reverses on in-distribution items.
Figures



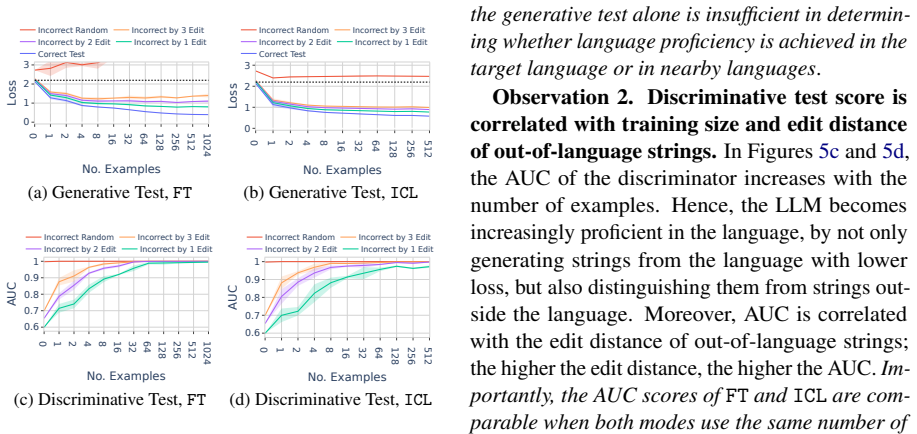
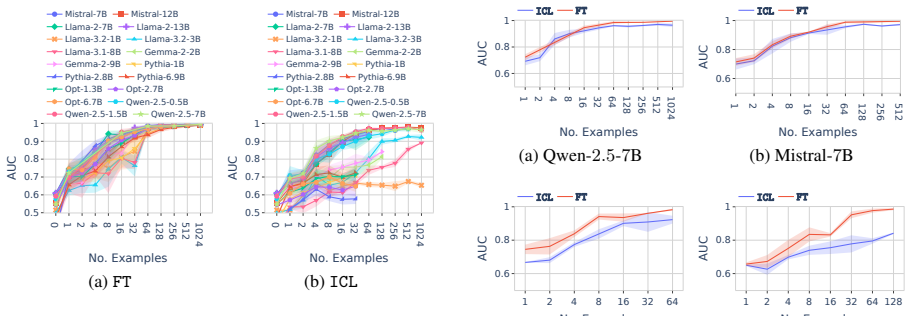










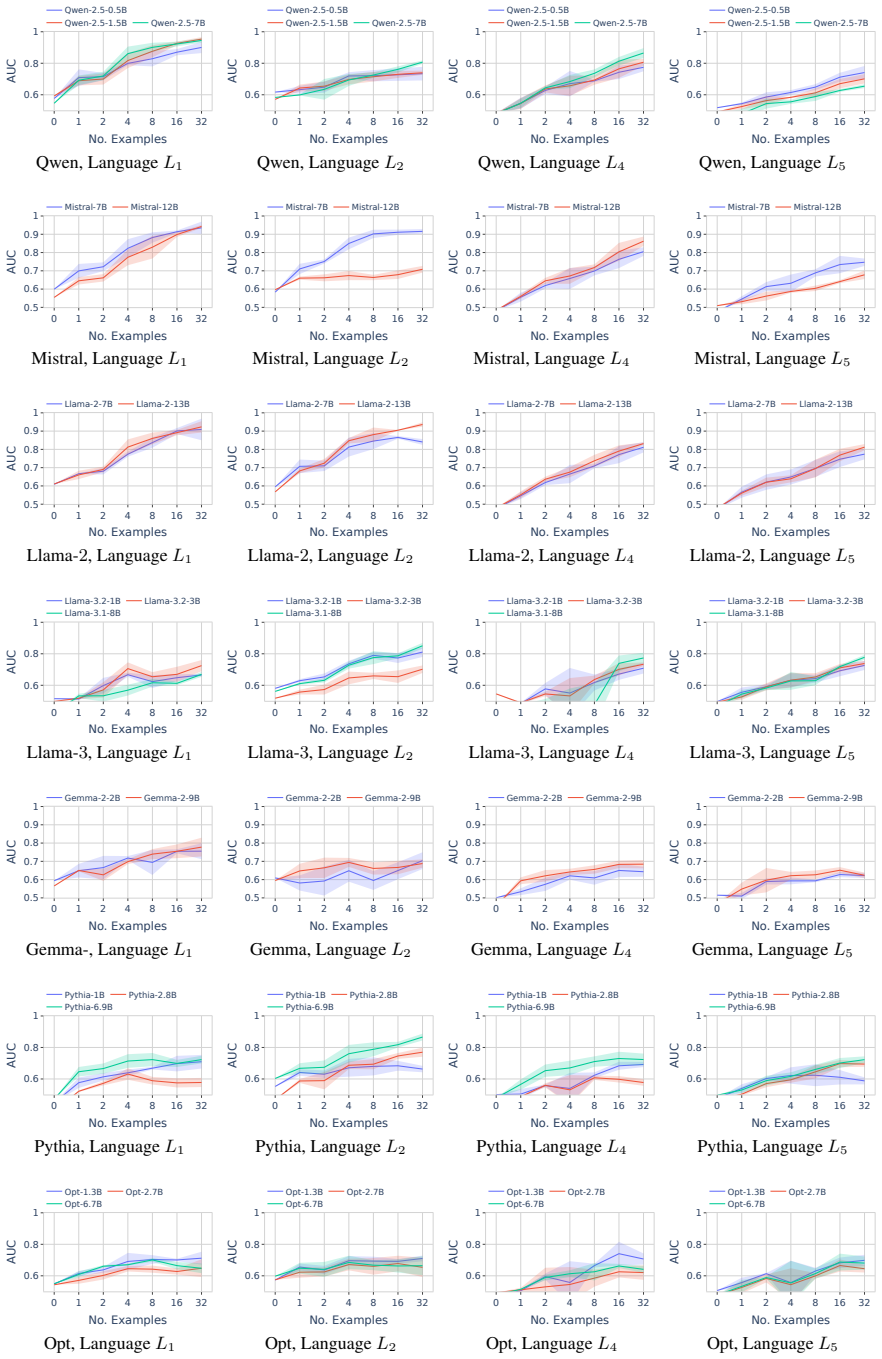







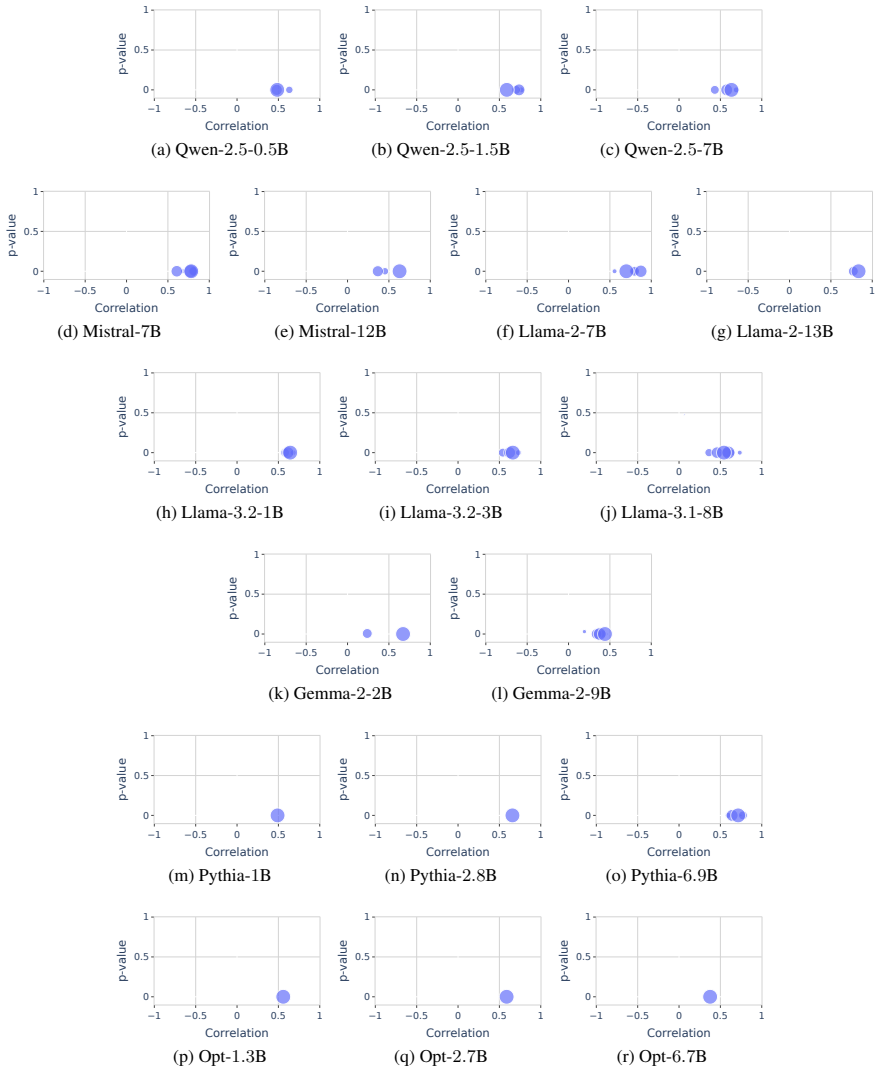
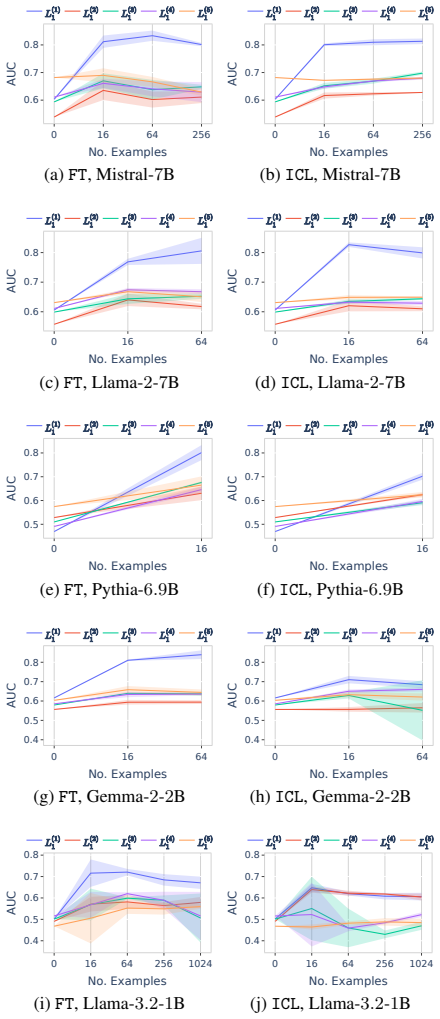




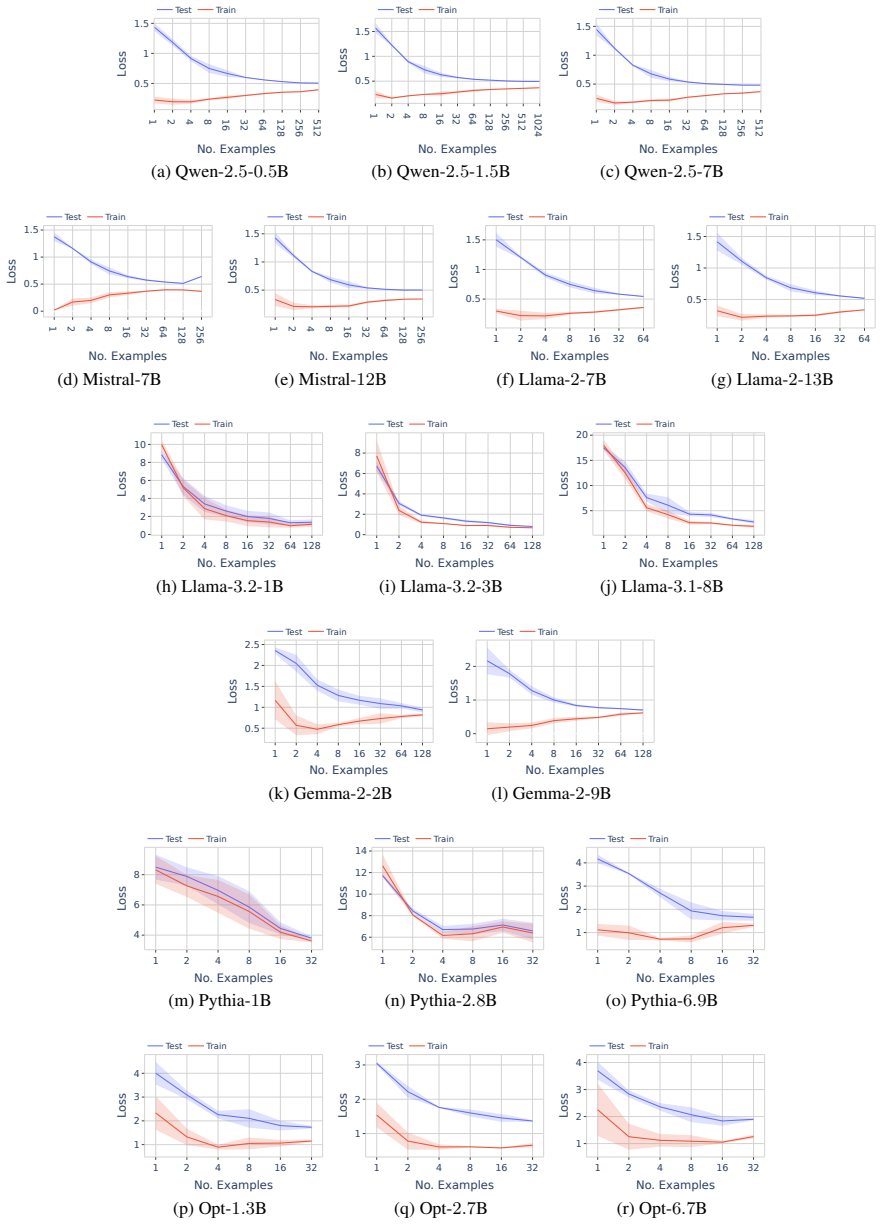

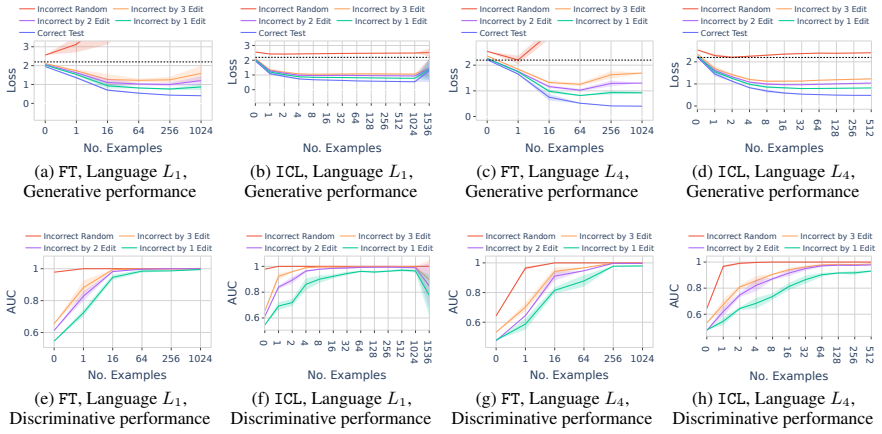



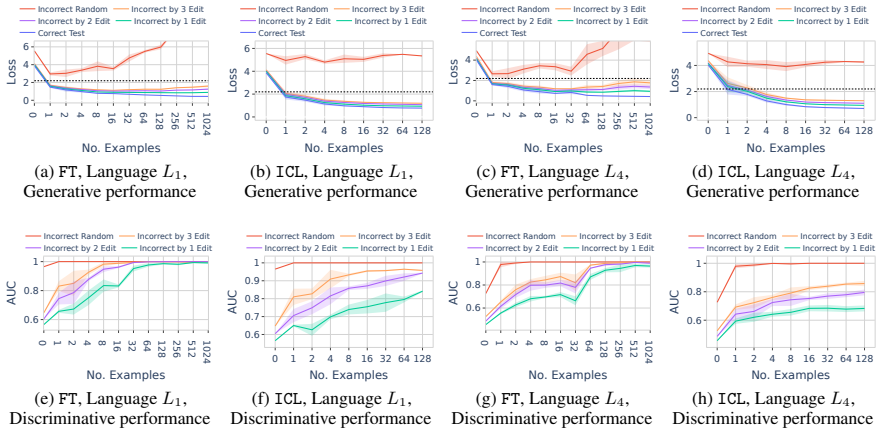

read the original abstract
Large language models (LLMs) operate in two fundamental learning modes - fine-tuning (FT) and in-context learning (ICL) - raising key questions about which mode yields greater language proficiency and whether they differ in their inductive biases. Prior studies comparing FT and ICL have yielded mixed and inconclusive results due to inconsistent experimental setups. To enable a rigorous comparison, we propose a formal language learning task - offering precise language boundaries, controlled string sampling, and no data contamination - and introduce a discriminative test for language proficiency, where an LLM succeeds if it assigns higher generation probability to in-language strings than to out-of-language strings. Empirically, we find that: (a) FT has greater language proficiency than ICL on in-distribution generalization, but both perform equally well on out-of-distribution generalization. (b) Their inductive biases, measured by the correlation in string generation probabilities, are similar when both modes partially learn the language but diverge at higher proficiency levels. (c) Unlike FT, ICL performance differs substantially across models of varying sizes and families and is sensitive to the token vocabulary of the language. Thus, our work demonstrates the promise of formal languages as a controlled testbed for evaluating LLMs, behaviors that are difficult to isolate in natural language datasets. Our source code is available at https://github.com/bishwamittra/formallm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a formal language learning task as a controlled testbed to compare fine-tuning (FT) and in-context learning (ICL) in LLMs. It defines a discriminative test for language proficiency (higher generation probability assigned to in-language strings than out-of-language strings) and reports three main empirical findings: (a) FT shows greater proficiency than ICL on in-distribution generalization but both modes perform equally on out-of-distribution generalization; (b) inductive biases (measured by correlation in string generation probabilities) are similar at partial learning levels but diverge at higher proficiency; (c) ICL performance varies more across model sizes/families and is sensitive to token vocabulary, unlike FT. Source code is released.
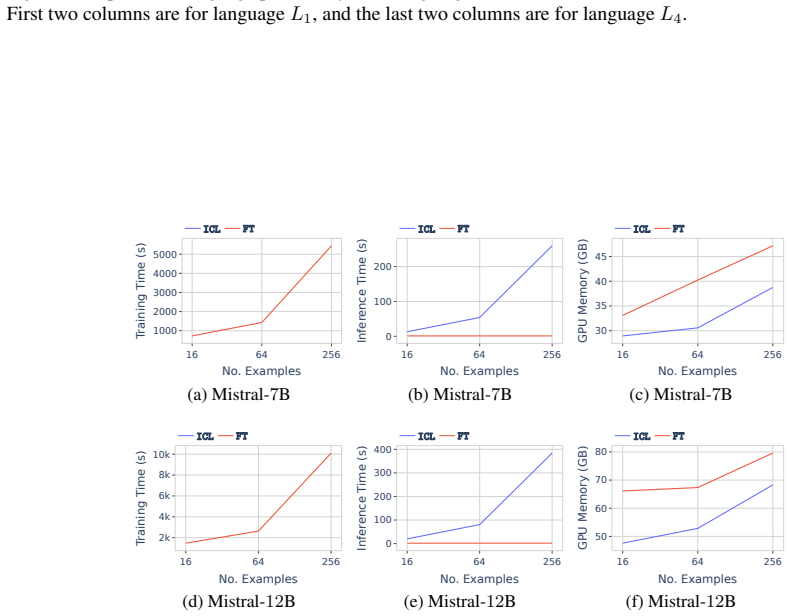
Significance. If the results hold under rigorous controls, the work supplies a contamination-free, precisely bounded testbed that can help resolve mixed prior comparisons of FT vs. ICL. The public code release is a clear strength for reproducibility. The approach of using formal languages to isolate inductive biases and generalization modes is a useful methodological contribution to the field.
major comments (3)
- [§4 and §3.2] §4 (Experimental Setup) and §3.2 (Discriminative Test): The sampling of out-of-language strings is not described with sufficient controls (length matching, n-gram overlap, or structural violation types). This is load-bearing for claims (a) and (b), because the reported equal OOD performance and the FT/ICL bias divergence at high proficiency could be artifacts if OOD strings share local surface statistics with training data rather than testing full grammar acquisition.
- [§5] §5 (Results): No statistical tests, number of independent runs, sample sizes, or error bars are reported for the performance differences, correlations, or sensitivity analyses. This undermines verification of the empirical claims, especially given the abstract's lack of these details and the low reader confidence in soundness.
- [§3.1] §3.1 (Formal Language Task): The specific formal languages (e.g., regular, context-free) and their generative grammars are not enumerated with examples. Without this, it is difficult to assess whether the discriminative test requires learning the underlying grammar or can be satisfied by rejecting local invalid patterns, directly affecting the interpretation of proficiency differences.
minor comments (2)
- [Abstract] Abstract: The phrase 'precise language boundaries, controlled string sampling' is used but not previewed with even one concrete language or sampling rule; adding a brief example would improve immediate readability.
- [§3.3] Notation: The correlation metric for inductive biases is introduced without an explicit equation; adding a short definition (e.g., Pearson correlation over log-probabilities) would aid clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped us strengthen the clarity and empirical rigor of the manuscript. We address each major comment below and have incorporated revisions to improve the presentation of our controlled testbed and results.
read point-by-point responses
-
Referee: [§4 and §3.2] §4 (Experimental Setup) and §3.2 (Discriminative Test): The sampling of out-of-language strings is not described with sufficient controls (length matching, n-gram overlap, or structural violation types). This is load-bearing for claims (a) and (b), because the reported equal OOD performance and the FT/ICL bias divergence at high proficiency could be artifacts if OOD strings share local surface statistics with training data rather than testing full grammar acquisition.
Authors: We agree that explicit controls on OOD sampling are essential to substantiate claims about full grammar acquisition versus surface-level patterns. Although §4 described the overall sampling approach and noted the use of structural violations, we acknowledge that additional specifics were needed. We have revised §4 and §3.2 to detail: length matching between in- and out-of-language strings, explicit minimization of 3-gram overlap with the training distribution, and enumeration of violation categories (e.g., nesting depth violations for context-free languages and symbol-order violations for regular languages). These additions confirm that OOD evaluation targets global structural properties, supporting the interpretation of equal OOD performance and bias divergence. revision: yes
-
Referee: [§5] §5 (Results): No statistical tests, number of independent runs, sample sizes, or error bars are reported for the performance differences, correlations, or sensitivity analyses. This undermines verification of the empirical claims, especially given the abstract's lack of these details and the low reader confidence in soundness.
Authors: We accept that the lack of statistical reporting limits verifiability. We have updated §5 to specify five independent runs per condition, test sample sizes (500 strings for proficiency discrimination and 1,000 for probability correlations), paired t-tests with reported p-values for all FT-ICL comparisons, and standard-error bars on all figures. We have also added a brief mention of these controls to the abstract. These changes provide the necessary quantitative support for the reported differences and sensitivity results. revision: yes
-
Referee: [§3.1] §3.1 (Formal Language Task): The specific formal languages (e.g., regular, context-free) and their generative grammars are not enumerated with examples. Without this, it is difficult to assess whether the discriminative test requires learning the underlying grammar or can be satisfied by rejecting local invalid patterns, directly affecting the interpretation of proficiency differences.
Authors: We thank the referee for noting this gap in concreteness. While §3.1 outlined the task framework, we agree that explicit grammars and examples are required to demonstrate that the test probes full grammar learning. We have expanded §3.1 to enumerate the languages (Dyck language as the primary context-free example and a^n b^n as a regular example), provide their generative grammars in standard notation, and include sample in-language versus out-of-language strings. This makes clear that local n-gram rejection is insufficient for high proficiency scores, thereby clarifying the interpretation of FT versus ICL differences. revision: yes
Circularity Check
No circularity: empirical comparisons on formal language task
full rationale
The paper's central claims rest on empirical evaluations of FT versus ICL using a proposed formal language learning task and a discriminative probability test. No load-bearing derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described methodology; results are reported directly from model runs on controlled string samples, with no equations or premises that reduce to their own inputs by construction. The work is self-contained as an experimental study introducing a new testbed rather than deriving results from prior fitted quantities or author-specific uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Formal languages offer precise boundaries and controlled string sampling with no data contamination.
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Ekin Aky \"u rek, Bailin Wang, Yoon Kim, and Jacob Andreas. 2024. In-context language learning: Architectures and algorithms. In Proceedings of the 41st International Conference on Machine Learning, ICML'24. JMLR.org
2024
- [4]
-
[5]
Akari Asai, Sneha Kudugunta, Xinyan Yu, Terra Blevins, Hila Gonen, Machel Reid, Yulia Tsvetkov, Sebastian Ruder, and Hannaneh Hajishirzi. 2024. https://doi.org/10.18653/v1/2024.naacl-long.100 BUFFET : Benchmarking large language models for few-shot cross-lingual transfer . In Proceedings of the 2024 Conference of the North American Chapter of the Associat...
-
[6]
Anas Awadalla, Mitchell Wortsman, Gabriel Ilharco, Sewon Min, Ian Magnusson, Hannaneh Hajishirzi, and Ludwig Schmidt. 2022. Exploring the landscape of distributional robustness for question answering models. In Findings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics
2022
-
[7]
Gormley, and Graham Neubig
Amanda Bertsch, Maor Ivgi, Uri Alon, Jonathan Berant, Matthew R. Gormley, and Graham Neubig. 2024. https://openreview.net/forum?id=4KAmc7vUbq In-context learning with long-context models: An in-depth exploration . In First Workshop on Long-Context Foundation Models @ ICML 2024
2024
-
[8]
Kush Bhatia, Avanika Narayan, Christopher M De Sa, and Christopher R \'e . 2023. TART : A plug-and-play transformer module for task-agnostic reasoning. Advances in Neural Information Processing Systems, 36:9751--9788
2023
-
[9]
Satwik Bhattamishra, Kabir Ahuja, and Navin Goyal. 2020. On the ability and limitations of transformers to recognize formal languages. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online. Association for Computational Linguistics
2020
-
[10]
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, and 1 others. 2023. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397--2430. PMLR
2023
-
[11]
Nadav Borenstein, Anej Svete, Robin Chan, Josef Valvoda, Franz Nowak, Isabelle Augenstein, Eleanor Chodroff, and Ryan Cotterell. 2024. What languages are easy to language-model? a perspective from learning probabilistic regular languages. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
2024
-
[12]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877--1901
2020
-
[13]
Nick Chater and Christopher D Manning. 2006. Probabilistic models of language processing and acquisition. Trends in cognitive sciences, 10(7):335--344
2006
-
[14]
Wentong Chen, Yankai Lin, ZhenHao Zhou, HongYun Huang, YanTao Jia, Zhao Cao, and Ji-Rong Wen. 2025. https://aclanthology.org/2025.coling-main.693/ ICLE val: Evaluating in-context learning ability of large language models . In Proceedings of the 31st International Conference on Computational Linguistics, pages 10398--10422, Abu Dhabi, UAE. Association for ...
2025
-
[15]
Ta-Chung Chi, Ting-Han Fan, Alexander I Rudnicky, and Peter J Ramadge. 2023. Transformer working memory enables regular language reasoning and natural language length extrapolation. In Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore. Association for Computational Linguistics
2023
-
[16]
Noam Chomsky. 1956. Three models for the description of language. IRE Transactions on information theory, 2(3):113--124
1956
-
[17]
Michael Collins. 2013. Probabilistic context-free grammars ( PCFGs )
2013
-
[18]
Ryan Cotterell, Sabrina J Mielke, Jason Eisner, and Brian Roark. 2018. Are all languages equally hard to language-model? In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, Louisiana. Association for Computational Linguistics
2018
- [19]
-
[20]
Gr \'e goire Del \'e tang, Anian Ruoss, Jordi Grau-Moya, Tim Genewein, Li Kevin Wenliang, Elliot Catt, Chris Cundy, Marcus Hutter, Shane Legg, Joel Veness, and 1 others. 2023. Neural networks and the chomsky hierarchy. In The Eleventh International Conference on Learning Representations
2023
-
[21]
Ricardo Dominguez-Olmedo, Florian E Dorner, and Moritz Hardt. 2025. Training on the test task confounds evaluation and emergence. In The Thirteenth International Conference on Learning Representations
2025
-
[22]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, and 1 others. 2024. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review arXiv 2024
- [23]
-
[24]
Michael Hahn. 2020. Theoretical limitations of self-attention in neural sequence models. Transactions of the Association for Computational Linguistics, 8:156--171
2020
-
[25]
Michael Hahn and Mark Rofin. 2024. Why are sensitive functions hard for transformers? In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand. Association for Computational Linguistics
2024
-
[26]
Mark Hopkins. 2022. Towards more natural artificial languages. In Proceedings of the 26th Conference on Computational Natural Language Learning (CoNLL), pages 85--94
2022
-
[27]
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 Lo RA : Low-rank adaptation of large language models . In International Conference on Learning Representations
2022
-
[28]
Shengding Hu, Yuge Tu, Xu Han, Ganqu Cui, Chaoqun He, Weilin Zhao, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Xinrong Zhang, Zhen Leng Thai, Chongyi Wang, Yuan Yao, Chenyang Zhao, Jie Zhou, Jie Cai, Zhongwu Zhai, Ning Ding, and 5 others. 2024. https://openreview.net/forum?id=3X2L2TFr0f Mini CPM : Unveiling the potential of small language models wit...
2024
-
[29]
Thomas F Icard. 2020. Calibrating generative models: The probabilistic Chomsky--Sch \"u tzenberger hierarchy. Journal of Mathematical Psychology, 95:102308
2020
-
[30]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. https://arxiv.org/abs/2310.0...
work page internal anchor Pith review arXiv 2023
-
[31]
Jaap Jumelet and Willem Zuidema. 2023. Transparency at the source: Evaluating and interpreting language models with access to the true distribution. In Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore. Association for Computational Linguistics
2023
-
[32]
Julie Kallini, Isabel Papadimitriou, Richard Futrell, Kyle Mahowald, and Christopher Potts. 2024. Mission: Impossible language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand. Association for Computational Linguistics
2024
-
[33]
Masahiro Kaneko, Danushka Bollegala, and Timothy Baldwin. 2025. The gaps between fine tuning and in-context learning in bias evaluation and debiasing. In Proceedings of the 31st International Conference on Computational Linguistics, pages 2758--2764
2025
-
[34]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361
work page internal anchor Pith review arXiv 2020
-
[35]
Toutanova, Llion Jones, Ming-Wei Chang, Andrew Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Matthew Kelcey, Jacob Devlin, Kenton Lee, Kristina N. Toutanova, Llion Jones, Ming-Wei Chang, Andrew Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural questions: a benchmark for question answering research. T...
2019
-
[36]
Sander Land and Max Bartolo. 2024. Fishing for Magikarp : Automatically detecting under-trained tokens in large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, Florida, USA. Association for Computational Linguistics
2024
-
[37]
Teven Le Scao and Alexander M Rush. 2021. How many data points is a prompt worth? In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2627--2636
2021
-
[38]
Eric Lehman, Evan Hernandez, Diwakar Mahajan, Jonas Wulff, Micah J Smith, Zachary Ziegler, Daniel Nadler, Peter Szolovits, Alistair Johnson, and Emily Alsentzer. 2023. Do we still need clinical language models? In Conference on health, inference, and learning, pages 578--597. PMLR
2023
-
[39]
Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics
2021
-
[40]
Ziqian Lin and Kangwook Lee. 2024. https://openreview.net/forum?id=5H4nJIGqmK Dual operating modes of in-context learning . In ICLR 2024 Workshop on Mathematical and Empirical Understanding of Foundation Models
2024
-
[41]
Bingbin Liu, Jordan T Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang. 2023. Transformers learn shortcuts to automata. In The Eleventh International Conference on Learning Representations
2023
-
[42]
Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin A Raffel. 2022. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. Advances in Neural Information Processing Systems, 35:1950--1965
2022
-
[43]
Christopher D Manning. 2003. Probabilistic syntax. Probabilistic linguistics, 289341
2003
-
[44]
William Merrill. 2023. Formal languages and the NLP black box. In International Conference on Developments in Language Theory, pages 1--8. Springer
2023
-
[45]
Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, Pouya Tafti, Léonard Hussenot, Pier Giuseppe Sessa, Aakanksha Chowdhery, Adam Roberts, Aditya Barua, Alex Botev, Alex Castro-Ros, Ambrose Slone, Amélie Héliou, and 88 others. 2024. Gemma: Open models based on ...
work page internal anchor Pith review arXiv 2024
-
[46]
Sabrina J Mielke, Ryan Cotterell, Kyle Gorman, Brian Roark, and Jason Eisner. 2019. What kind of language is hard to language-model? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy. Association for Computational Linguistics
2019
-
[47]
Marius Mosbach, Tiago Pimentel, Shauli Ravfogel, Dietrich Klakow, and Yanai Elazar. 2023. https://doi.org/10.18653/v1/2023.findings-acl.779 Few-shot fine-tuning vs. in-context learning: A fair comparison and evaluation . In Findings of the Association for Computational Linguistics: ACL 2023, pages 12284--12314, Toronto, Canada. Association for Computation...
-
[48]
Shikhar Murty, Pratyusha Sharma, Jacob Andreas, and Christopher D Manning. 2023. Characterizing intrinsic compositionality in transformers with tree projections. In The Eleventh International Conference on Learning Representations
2023
- [49]
-
[50]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730--27744
2022
-
[51]
Jane Pan, Tianyu Gao, Howard Chen, and Danqi Chen. 2023. https://doi.org/10.18653/v1/2023.findings-acl.527 What in-context learning learns in-context: Disentangling task recognition and task learning . In Findings of the Association for Computational Linguistics: ACL 2023, pages 8298--8319, Toronto, Canada. Association for Computational Linguistics
-
[52]
Isabel Papadimitriou and Dan Jurafsky. 2023. Injecting structural hints: Using language models to study inductive biases in language learning. In Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore. Association for Computational Linguistics
2023
-
[53]
Branislav Pecher, Ivan Srba, and Maria Bielikova. 2025. Comparing specialised small and general large language models on text classification: 100 labelled samples to achieve break-even performance. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 165--184
2025
-
[54]
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners
2019
-
[55]
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. https://doi.org/10.18653/v1/D16-1264 SQ u AD : 100,000+ questions for machine comprehension of text . In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383--2392, Austin, Texas. Association for Computational Linguistics
-
[56]
Shauli Ravfogel, Yoav Goldberg, and Tal Linzen. 2019. Studying the inductive biases of RNNs with synthetic variations of natural languages. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, Minnesota. Association ...
2019
-
[57]
Amirhossein Razavi, Mina Soltangheis, Negar Arabzadeh, Sara Salamat, Morteza Zihayat, and Ebrahim Bagheri. 2025. Benchmarking prompt sensitivity in large language models. In European Conference on Information Retrieval, pages 303--313. Springer
2025
-
[58]
Gautam Reddy. 2024. The mechanistic basis of data dependence and abrupt learning in an in-context classification task. In The Twelfth International Conference on Learning Representations
2024
-
[59]
Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, Johan Ferret, Peter Liu, Pouya Tafti, Abe Friesen, Michelle Casbon, Sabela Ramos, Ravin Kumar, Charline Le Lan, Sammy Jerome, Anton Tsitsulin, and 178 others. 2024. Gemma 2: Improving open language mode...
work page internal anchor Pith review arXiv 2024
- [60]
-
[61]
Hui Shi, Sicun Gao, Yuandong Tian, Xinyun Chen, and Jishen Zhao. 2022. Learning bounded context-free-grammar via LSTM and the transformer: difference and the explanations. In Proceedings of the AAAI conference on artificial intelligence, volume 36, pages 8267--8276
2022
-
[62]
Heydar Soudani, Evangelos Kanoulas, and Faegheh Hasibi. 2024. Fine tuning vs. retrieval augmented generation for less popular knowledge. In Proceedings of the 2024 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region, pages 12--22
2024
- [63]
- [64]
-
[65]
Hongjin Su, Jungo Kasai, Chen Henry Wu, Weijia Shi, Tianlu Wang, Jiayi Xin, Rui Zhang, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, and 1 others. 2023. Selective annotation makes language models better few-shot learners. In The Eleventh International Conference on Learning Representations
2023
-
[66]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth \'e e Lacroix, Baptiste Rozi \`e re, Naman Goyal, Eric Hambro, Faisal Azhar, and 1 others. 2023 a . Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971
work page internal anchor Pith review arXiv 2023
-
[67]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, and 1 others. 2023 b . Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288
work page internal anchor Pith review arXiv 2023
-
[68]
Shunjie Wang. 2021. Evaluating transformer’s ability to learn mildly context-sensitive languages. University of Washington
2021
- [69]
-
[70]
Jennifer C White and Ryan Cotterell. 2021. Examining the inductive bias of neural language models with artificial languages. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online. Association for Computational Linguistics
2021
-
[71]
Adina Williams, Nikita Nangia, and Samuel Bowman. 2018. http://aclweb.org/anthology/N18-1101 A broad-coverage challenge corpus for sentence understanding through inference . In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1112--...
2018
-
[72]
Qinyuan Wu, Mohammad Aflah Khan, Soumi Das, Vedant Nanda, Bishwamittra Ghosh, Camila Kolling, Till Speicher, Laurent Bindschaedler, Krishna Gummadi, and Evimaria Terzi. 2025. Towards reliable latent knowledge estimation in llms: Zero-prompt many-shot based factual knowledge extraction. In Proceedings of the Eighteenth ACM International Conference on Web S...
2025
- [73]
-
[74]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, and 1 others. 2024. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115
work page internal anchor Pith review arXiv 2024
-
[75]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. https://doi.org/10.18653/v1/D18-1259 H otpot QA : A dataset for diverse, explainable multi-hop question answering . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369--2380, Brussels...
-
[76]
Qingyu Yin, Xuzheng He, Chak Tou Leong, Fan Wang, Yanzhao Yan, Xiaoyu Shen, and Qiang Zhang. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.239 Deeper insights without updates: The power of in-context learning over fine-tuning . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 4138--4151, Miami, Florida, USA. Associat...
-
[77]
Biao Zhang, Zhongtao Liu, Colin Cherry, and Orhan Firat. 2024. https://openreview.net/forum?id=5HCnKDeTws When scaling meets LLM finetuning: The effect of data, model and finetuning method . In The Twelfth International Conference on Learning Representations
2024
-
[78]
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, and 1 others. 2022. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068
work page internal anchor Pith review arXiv 2022
-
[79]
Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. 2021. Calibrate before use: Improving few-shot performance of language models. In International conference on machine learning, pages 12697--12706. PMLR
2021
-
[80]
Jingming Zhuo, Songyang Zhang, Xinyu Fang, Haodong Duan, Dahua Lin, and Kai Chen. 2024. ProSA : Assessing and understanding the prompt sensitivity of llms. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 1950--1976
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.