Recognition: unknown
An Analysis of Active Learning Algorithms using Real-World Crowd-sourced Text Annotations
Pith reviewed 2026-05-08 08:14 UTC · model grok-4.3
The pith
Real crowd-sourced annotations show how eight active learning methods handle label noise and refusals on text data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By collecting actual annotations from crowd-sourced workers on benchmark text datasets and evaluating eight active learning techniques with deep networks on them, the work reveals the impact of incorrect labels and label refusals on algorithm performance, offering evidence that differs from results obtained with simulated oracles.
What carries the argument
The empirical evaluation that uses real crowd-sourced annotations incorporating human errors and abstentions to test active learning techniques instead of simulated oracles.
If this is right
- Active learning methods may select less useful samples or require more queries when faced with inconsistent human labels.
- Worker refusals to provide labels can slow progress more than label errors alone in some techniques.
- Deep neural networks trained with active learning may need modifications to account for real annotation variability before deployment.
- The released dataset supports further testing of noisy active learning strategies on text tasks.
Where Pith is reading between the lines
- Similar experiments on image or audio data could check whether the observed effects of noise and abstention hold in other modalities.
- Active learning variants that estimate individual worker reliability might reduce the impact of errors and refusals.
- Larger-scale replications with more datasets would test if the performance patterns remain stable across different annotation conditions.
Load-bearing premise
The crowd annotations obtained from the platform represent the full range of real-world labeling problems and the eight chosen techniques cover the main active learning approaches in use.
What would settle it
Repeating the full set of experiments with annotations collected from a different crowd platform or different workers that reverses the relative performance of the eight algorithms would undermine the reported findings.
Figures



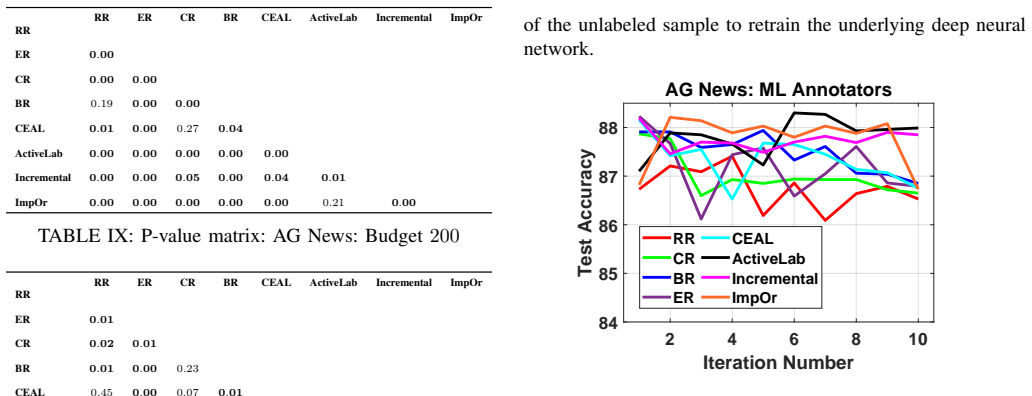
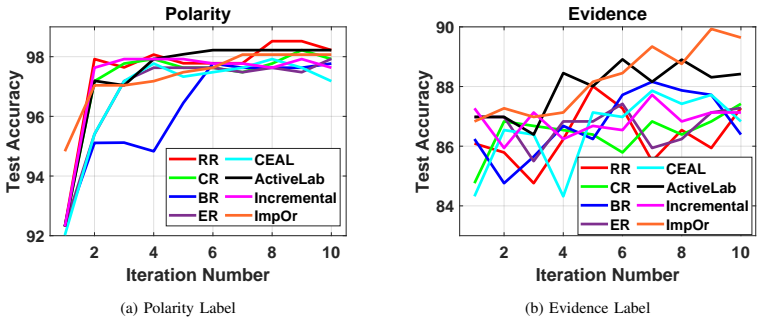
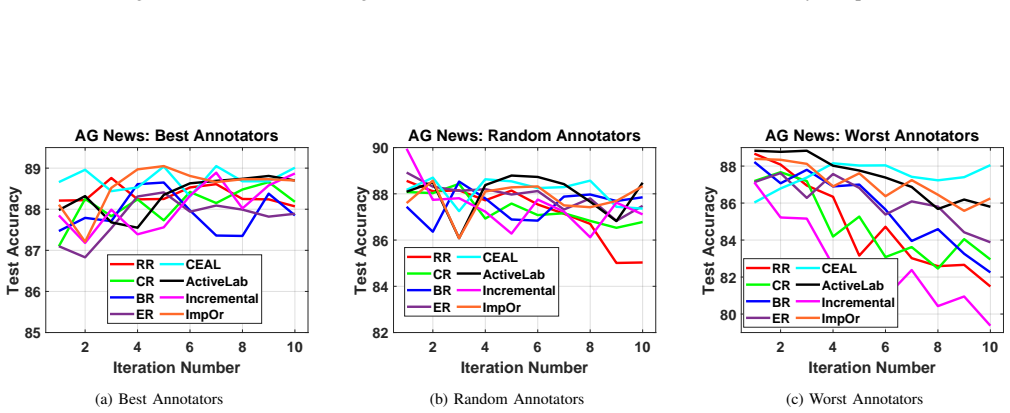




read the original abstract
Active learning algorithms automatically identify the most informative samples from large amounts of unlabeled data and tremendously reduce human annotation effort in inducing a machine learning model. In a conventional active learning setup, the labeling oracles are assumed to be infallible, that is, they always provide correct answers (in terms of class labels) to the queried unlabeled instances, which cannot be guaranteed in real-world applications. To this end, a body of research has focused on the development of active learning algorithms in the presence of imperfect / noisy oracles. Existing research on active learning with noisy oracles typically simulate the oracles using machine learning models; however, real-world situations are much more challenging, and using ML models to simulate the annotation patterns may not appropriately capture the nuances of real-world annotation challenges. In this research, we first collect annotations of text samples (from 3 benchmark text classification datasets) from crowd-sourced workers through a crowd-sourcing platform. We then conduct extensive empirical studies of 8 commonly used active learning techniques (in conjunction with deep neural networks) using the obtained annotations. Our analyses sheds light on the performance of these techniques under real-world challenges, where annotators can provide incorrect labels, and can also refuse to provide labels. We hope this research will provide valuable insights that will be useful for the deployment of deep active learning systems in real-world applications. The obtained annotations can be accessed at https://github.com/varuntotakura/al_rcta/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper collects annotations for text samples from three benchmark classification datasets via a crowd-sourcing platform, then uses these static annotations to simulate oracles that can err or refuse labels. It evaluates the performance of eight common active learning algorithms paired with deep neural networks under these real-world conditions and releases the collected annotations publicly at a GitHub repository.
Significance. If the experimental protocol is fully documented and the results are reproducible, the work offers concrete insights into how standard active learning methods behave when oracles exhibit realistic imperfections, moving beyond purely simulated noise models. The public release of the crowd-sourced annotation data is a clear strength that can support follow-on research and benchmarking in noisy active learning.
major comments (2)
- [§5 (Experiments)] The description of the empirical evaluation (abstract and §5) provides no details on the active learning simulation protocol: how refusals are handled during query selection, how multiple or conflicting annotations per instance are resolved into a single oracle response, or how the static dataset is replayed across AL iterations. These choices are load-bearing for the central claim that the study captures real-world annotation challenges.
- [§5 (Experiments)] No information is given on the number of independent runs, random seeds, statistical significance tests, or variance measures used to compare the eight active learning techniques. Without these, the reported performance differences cannot be assessed for reliability.
minor comments (2)
- [Introduction] The eight active learning techniques should be explicitly listed with citations in the introduction or methods section for clarity.
- [Data Collection] The paper would benefit from a brief discussion of how the chosen crowd-sourcing platform and worker pool relate to other real-world annotation settings.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight areas where additional detail will strengthen the reproducibility and clarity of our experimental protocol. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§5 (Experiments)] The description of the empirical evaluation (abstract and §5) provides no details on the active learning simulation protocol: how refusals are handled during query selection, how multiple or conflicting annotations per instance are resolved into a single oracle response, or how the static dataset is replayed across AL iterations. These choices are load-bearing for the central claim that the study captures real-world annotation challenges.
Authors: We agree that these protocol details are essential. The current manuscript describes the collection of annotations but does not fully specify the replay mechanics in the AL loop. In revision we will add a dedicated paragraph (and pseudocode) in §5 clarifying: (i) refusals are treated as 'no label' and the instance remains in the unlabeled pool for potential future queries; (ii) when multiple annotations exist for an instance, we use majority vote among non-refusal labels (ties broken randomly); (iii) the static annotation set is replayed deterministically—each queried instance receives the pre-collected label (or refusal) without re-sampling or model-based simulation. This will make explicit how real-world noise and abstention are injected. revision: yes
-
Referee: [§5 (Experiments)] No information is given on the number of independent runs, random seeds, statistical significance tests, or variance measures used to compare the eight active learning techniques. Without these, the reported performance differences cannot be assessed for reliability.
Authors: We acknowledge the omission. The experiments were executed with multiple independent runs using fixed random seeds for model initialization, data shuffling, and query selection. In the revision we will report the exact number of runs, the seed values, the variance (standard deviation) across runs for all curves, and any statistical comparisons performed. If the referee prefers, we can also include pairwise significance tests in the updated tables/figures. revision: yes
Circularity Check
No significant circularity: purely empirical evaluation
full rationale
The paper performs an empirical study: it collects real crowd-sourced annotations on three text datasets via MTurk-style platform, then evaluates eight standard active learning algorithms (paired with DNNs) by replaying those fixed annotations as oracle responses. No mathematical derivations, parameter fitting, uniqueness theorems, or ansatzes are claimed. The central claim is simply that the observed performance patterns under noisy/refusing oracles provide practical insights; this does not reduce to any self-definition, fitted-input prediction, or self-citation chain. Self-citations, if present, are incidental and not load-bearing for any result. The setup is self-contained against external benchmarks (the released annotation data) and contains no internal reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Active learning literature survey,
B. Settles, “Active learning literature survey,” inTechnical Report 1648, University of Wisconsin-Madison, 2010
2010
-
[2]
Support vector machine active learning with ap- plications to text classification,
S. Tong and D. Koller, “Support vector machine active learning with ap- plications to text classification,”Journal of Machine Learning Research (JMLR), vol. 2, pp. 45–66, 2001
2001
-
[3]
Learning loss for active learning,
D. Yoo and I. Kweon, “Learning loss for active learning,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[4]
Active machine learning for transmembrane helix prediction,
H. Osmanbeyoglu, J. Wehner, J. Carbonell, and M. Ganapathiraju, “Active machine learning for transmembrane helix prediction,”BMC Bioinformatics, vol. 11, no. 1, 2010
2010
-
[5]
Deep active learning for anomaly detection,
T. Pimentel, M. Monteiro, A. Veloso, and N. Ziviani, “Deep active learning for anomaly detection,” inIEEE International Joint Conference on Neural Networks (IJCNN), 2020
2020
-
[6]
Cost-effective active learning from diverse labelers,
S. Huang, J. Chen, X. Mu, and Z. Zhou, “Cost-effective active learning from diverse labelers,” inInternational Joint Conference on Artificial Intelligence (IJCAI), 2017
2017
-
[7]
Active learning from weak and strong labelers,
C. Zhang and K. Chaudhuri, “Active learning from weak and strong labelers,” inNeural Information Processing Systems (NIPS), 2015
2015
-
[8]
Active learning from imperfect labelers,
S. Yan, K. Chaudhuri, and T. Javidi, “Active learning from imperfect labelers,” inNeural Information Processing Systems (NIPS), 2016
2016
-
[9]
Asking the right questions to the right users: Active learning with imperfect oracles,
S. Chakraborty, “Asking the right questions to the right users: Active learning with imperfect oracles,” inAAAI Conference on Artificial Intelligence, 2020
2020
-
[10]
Active learning from crowds,
Y . Yan, G. Fung, R. Rosales, and J. Dy, “Active learning from crowds,” inInternational Conference on Machine Learning (ICML), 2011
2011
-
[11]
A survey of deep active learning,
P. Ren, Y . Xiao, X. Chang, P. Huang, Z. Li, B. Gupta, X. Chen, and X. Wang, “A survey of deep active learning,”ACM Computing Surveys, vol. 54, no. 9, 2021
2021
-
[12]
Neural active learning on heteroskedastic distributions,
S. Khosla, C. Whye, J. Ash, C. Zhang, K. Kawaguchi, and A. Lamb, “Neural active learning on heteroskedastic distributions,” in arXiv:2211.00928v2, 2023
-
[13]
Direct: Deep active learning under imbalance and label noise,
S. Nuggehalli, J. Zhang, L. Jain, and R. Nowak, “Direct: Deep active learning under imbalance and label noise,” inarXiv:2312.09196v3, 2024
-
[14]
Active learning with a noisy annotator,
N. Shafir, G. Hacohen, and D. Weinshall, “Active learning with a noisy annotator,” inarXiv:2504.04506v1, 2025
-
[15]
Active learning for convolutional neural net- works: A core-set approach,
O. Sener and S. Savarese, “Active learning for convolutional neural net- works: A core-set approach,” inInternational Conference on Learning Representations (ICLR), 2018
2018
-
[16]
Deep batch active learning by diverse, uncertain gradient lower bounds,
J. Ash, C. Zhang, A. Krishnamurthy, J. Langford, and A. Agar- wal, “Deep batch active learning by diverse, uncertain gradient lower bounds,” inInternational Conference on Learning Representations (ICLR), 2020
2020
-
[17]
Semi-supervised active learning with temporal output discrepancy,
S. Huang, T. Wang, H. Xiong, J. Huan, and D. Dou, “Semi-supervised active learning with temporal output discrepancy,” inIEEE International Conference on Computer Vision (ICCV), 2021
2021
-
[18]
Influence selection for active learning,
Z. Liu, H. Ding, H. Zhong, W. Li, J. Dai, and C. He, “Influence selection for active learning,” inIEEE International Conference on Computer Vision (ICCV), 2021
2021
-
[19]
Variational adversarial ac- tive learning,
S. Sinha, S. Ebrahimi, and T. Darrell, “Variational adversarial ac- tive learning,” inIEEE International Conference on Computer Vision (ICCV), 2019
2019
-
[20]
Generative Adversarial Active Learning
J. Zhu and J. Bento, “Generative adversarial active learning,” in arXiv:1702.07956, 2017
work page Pith review arXiv 2017
-
[21]
Adversarial active learning for deep networks: a margin based approach,
M. Ducoffe and F. Precioso, “Adversarial active learning for deep networks: a margin based approach,” inInternational Conference on Machine Learning (ICML), 2018
2018
-
[22]
Improved adap- tive algorithm for scalable active learning with weak labeler,
Y . Chen, K. Sankararaman, A. Lazaric, M. Pirotta, D. Karamshuk, Q. Wang, K. Mandyam, S. Wang, and H. Fang, “Improved adap- tive algorithm for scalable active learning with weak labeler,” in arXiv:2211.02233v1, 2022
-
[23]
Proactive learning: cost-sensitive active learning with multiple imperfect oracles,
P. Donmez and J. Carbonell, “Proactive learning: cost-sensitive active learning with multiple imperfect oracles,” inACM Conference on Information and Knowledge Management (CIKM), 2008
2008
-
[24]
Efficiently learning the accuracy of labeling sources for selective sampling,
P. Donmez, J. Carbonell, and J. Schneider, “Efficiently learning the accuracy of labeling sources for selective sampling,” inACM Conference on Knowledge Discovery and Data Mining (KDD), 2009
2009
-
[25]
Active learning from multiple noisy labelers with varied costs,
Y . Zheng, S. Scott, and K. Deng, “Active learning from multiple noisy labelers with varied costs,” inIEEE International Conference on Data Mining (ICDM), 2010
2010
-
[26]
Repeated labeling using multiple noisy labelers,
P. Ipeirotis, F. Provost, V . Sheng, and J. Wang, “Repeated labeling using multiple noisy labelers,”Data Mining and Knowledge Discovery, vol. 28, 2014
2014
-
[27]
Incremental relabeling for active learning with noisy crowdsourced annotations,
L. Zhao, G. Sukthankar, and R. Sukthankar, “Incremental relabeling for active learning with noisy crowdsourced annotations,” inInternational Conference on Social Computing, 2011
2011
-
[28]
Activelab: Active learning with re-labeling by multiple annotators,
H. Goh and J. Mueller, “Activelab: Active learning with re-labeling by multiple annotators,” inInternational Conference on Learning Repre- sentations Workshop (ICLR-W), 2023
2023
-
[29]
Active learning from multiple knowledge sources,
Y . Yan, R. Rosales, G. Fung, F. Farooq, B. Rao, and J. Dy, “Active learning from multiple knowledge sources,” inInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2012
2012
-
[30]
Character-level convolutional net- works for text classification,
X. Zhang, J. Zhao, and Y . LeCun, “Character-level convolutional net- works for text classification,” inNeural Information Processing Systems (NeurIPS), 2015
2015
-
[31]
Probability distribution and entropy as a measure of uncertainty,
Q. A. Wang, “Probability distribution and entropy as a measure of uncertainty,”Journal of Physics A: Mathematical and Theoretical, vol. 41, 2008
2008
-
[32]
BERT: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” inNations of the Americas Chapter of the Association for Computational Linguis- tics (NAACL), 2019
2019
-
[33]
Stopping criterion for active learning with model stability,
Y . Zhang, W. Cai, W. Wang, and Y . Zhang, “Stopping criterion for active learning with model stability,”ACM Transactions on Intelligent Systems and Technology (TIST), vol. 9, 2017
2017
-
[34]
Learning a stopping criterion for active learning for word sense disambiguation and text classification,
J. Zhu, H. Wang, and E. Hovy, “Learning a stopping criterion for active learning for word sense disambiguation and text classification,” inInternational Joint Conference on Natural Language Processing (IJNLP), 2008
2008
-
[35]
Stopping criterion for active learning based on deterministic generalization bounds,
H. Ishibashi and H. Hino, “Stopping criterion for active learning based on deterministic generalization bounds,” inInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2020
2020
-
[36]
Active learning of multi-class classification models from ordered class sets,
Y . Xue and M. Hauskrecht, “Active learning of multi-class classification models from ordered class sets,” inAAAI Conference on Artificial Intelligence, 2019
2019
-
[37]
How to get the most out of your curation effort,
A. Rzhetsky, H. Shatkay, and W. Wilbur, “How to get the most out of your curation effort,”PLoS Computational Biology, vol. 5, no. 5, 2009
2009
-
[38]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,” inTechnical Report, OpenAI, 2019. APPENDIX We present the following in this Appendix. •Performance on Scientific Text Data (Section A) •Performance using a Subset of Annotators (Section B) •Error bar plots (Section C) •Further analysis...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.