Recognition: unknown
Explainable AI in Speaker Recognition -- Making Latent Representations Understandable
Pith reviewed 2026-05-08 06:54 UTC · model grok-4.3
The pith
Speaker recognition neural networks organize their latent representations into hierarchical clusters that align with semantic attributes like gender and nationality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
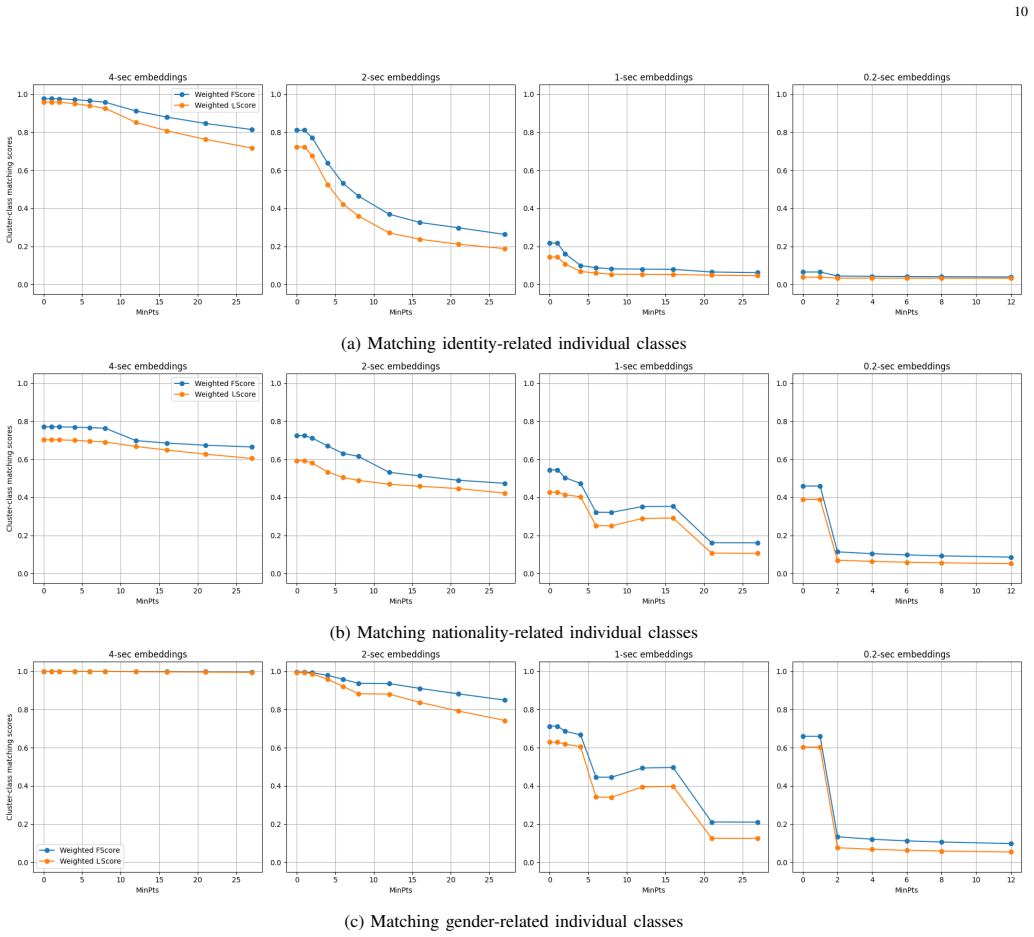
This work shows that applying Single-Linkage Clustering and HDBSCAN to the latent space of a speaker recognition network uncovers hierarchical clustering phenomena, where clusters have relationships rather than being isolated. The new HCCM algorithm matches these clusters to semantic classes, succeeding for single classes such as male or UK and for conjunctions such as male and UK or female and Ireland. Liebig's score measures the quality of these matches to identify the main limitations in the matching process.
What carries the argument
The Hierarchical Cluster-Class Matching (HCCM) algorithm, which establishes one-to-one correspondences between hierarchical clusters from SLINK or HDBSCAN and predefined semantic classes or their conjunctions, evaluated using Liebig's score.
If this is right
- Clusters can correspond to individual semantic classes or to their logical combinations, indicating that the network encodes interacting attributes.
- The matching process helps diagnose whether poor performance comes from the clustering step or from the choice of semantic labels.
- Successful matches demonstrate that certain speaker attributes are explicitly grouped in the representation space.
- Liebig's score provides a quantitative way to compare how different networks or clustering methods capture semantic structure.
Where Pith is reading between the lines
- If the hierarchical structure reflects real speaker attribute hierarchies, it could guide the creation of networks that learn more disentangled representations.
- This method might be applied to other tasks in audio processing to reveal hidden organizations in learned features.
- Manual verification of the content in matched clusters could further validate whether the alignments capture intended meanings.
Load-bearing premise
The hierarchical clusters identified by SLINK and HDBSCAN reflect meaningful semantic groupings of speakers that can be systematically matched by HCCM in a non-random fashion.
What would settle it
Running HCCM on the clusters and finding that the majority of matches have low Liebig's scores or that the clusters contain utterances not sharing the expected semantic properties.
Figures






read the original abstract
Neural networks can be trained to learn task-relevant representations from data. Understanding how these networks make decisions falls within the Explainable AI (XAI) domain. This paper proposes to study an XAI topic: uncovering unknown organisational patterns in network representations, particularly those representations learned by the speaker recognition network that recognises the speaker identity of utterances. Past studies employed algorithms (e.g. t-distributed Stochastic Neighbour Embedding and K-means) to analyse and visualise how network representations form independent clusters, indicating the presence of flat clustering phenomena within the space defined by these representations. In contrast, this work applies two algorithms -- Single-Linkage Clustering (SLINK) and Hierarchical Density-Based Spatial Clustering of Applications with Noise (HDBSCAN) -- to analyse how representations form clusters with hierarchical relationships rather than being independent, thereby demonstrating the existence of hierarchical clustering phenomena within the network representation space. To semantically understand the above hierarchical clustering phenomena, a new algorithm, termed Hierarchical Cluster-Class Matching (HCCM), is designed to perform one-to-one matching between predefined semantic classes and hierarchical representation clusters (i.e. those produced by SLINK or HDBSCAN). Some hierarchical clusters are successfully matched to individual semantic classes (e.g. male, UK), while others to conjunctions of semantic classes (e.g. male and UK, female and Ireland). A new metric, Liebig's score, is proposed to quantify the performance of each matching behaviour, allowing us to diagnose the factor that most strongly limits matching performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that speaker recognition networks exhibit hierarchical (rather than flat) clustering phenomena in their latent representations. It demonstrates this by applying SLINK and HDBSCAN to speaker embeddings, then introduces Hierarchical Cluster-Class Matching (HCCM) to align the resulting dendrograms or density hierarchies one-to-one with semantic metadata classes (gender, accent, etc.) and their conjunctions; a new metric called Liebig's score is proposed to quantify matching performance and diagnose limiting factors.
Significance. If the observed hierarchies prove intrinsic rather than algorithm-imposed and the HCCM matches are shown to be non-arbitrary, the work would supply a concrete, reproducible method for moving XAI in speaker recognition beyond t-SNE/K-means visualizations toward interpretable hierarchical structure, with potential utility for diagnosing embedding biases or improving downstream tasks.
major comments (3)
- [Methods/Results] Methods and Results sections: No null-model controls (shuffled embeddings, random vectors with matched covariance, or label-permuted baselines) are reported to test whether the dendrograms or density hierarchies recovered by SLINK/HDBSCAN are stronger or more semantically aligned than those expected from unstructured point clouds; without such controls the central claim that the algorithms reveal 'hierarchical clustering phenomena within the network representation space' cannot be distinguished from the fact that any finite set of points induces some hierarchy under these algorithms.
- [Abstract/Results] Abstract and Results: The assertion that 'some hierarchical clusters are successfully matched' to classes or conjunctions is presented without any quantitative metrics (matching accuracy, Liebig's score values, confusion matrices, or statistical significance tests), error analysis, or validation that the HCCM alignments are not post-hoc; this absence makes the performance claims unverifiable and prevents assessment of whether Liebig's score actually diagnoses limiting factors.
- [Proposed Method] Definition of HCCM and Liebig's score: The one-to-one matching procedure and the scoring formula are introduced as novel contributions, yet the manuscript provides no formal algorithmic description, complexity analysis, or proof that the matching is unique or stable under small perturbations of the dendrogram; these omissions render the new entities difficult to reproduce or compare against existing hierarchical clustering evaluation methods.
minor comments (2)
- [Introduction] Notation for semantic classes and their conjunctions is introduced informally; a small table or explicit enumeration of the metadata attributes used would improve clarity.
- [Figures] Figure captions for the dendrograms and cluster visualizations should include the exact hyper-parameters (minimum cluster size for HDBSCAN, linkage threshold for SLINK) and the number of embeddings plotted.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable suggestions. We address each of the major comments below, indicating the revisions we plan to make to enhance the manuscript's rigor and clarity.
read point-by-point responses
-
Referee: [Methods/Results] Methods and Results sections: No null-model controls (shuffled embeddings, random vectors with matched covariance, or label-permuted baselines) are reported to test whether the dendrograms or density hierarchies recovered by SLINK/HDBSCAN are stronger or more semantically aligned than those expected from unstructured point clouds; without such controls the central claim that the algorithms reveal 'hierarchical clustering phenomena within the network representation space' cannot be distinguished from the fact that any finite set of points induces some hierarchy under these algorithms.
Authors: We agree that null-model controls are crucial to substantiate our claims about intrinsic hierarchical clustering in the learned representations rather than artifacts of the clustering algorithms. In the revised version, we will add experiments using shuffled embeddings, random vectors with matched covariance structure, and label-permuted baselines. We will apply SLINK and HDBSCAN to these controls and compare the resulting hierarchies and their semantic alignments using Liebig's score and other metrics, including statistical tests to demonstrate significance. revision: yes
-
Referee: [Abstract/Results] Abstract and Results: The assertion that 'some hierarchical clusters are successfully matched' to classes or conjunctions is presented without any quantitative metrics (matching accuracy, Liebig's score values, confusion matrices, or statistical significance tests), error analysis, or validation that the HCCM alignments are not post-hoc; this absence makes the performance claims unverifiable and prevents assessment of whether Liebig's score actually diagnoses limiting factors.
Authors: We acknowledge the need for quantitative support. Although the manuscript introduces Liebig's score for this purpose, we will revise the Results section to prominently feature specific numerical values of Liebig's score for the reported matches, include confusion matrices for the HCCM procedure, provide error analysis, and conduct statistical significance tests. We will also detail the deterministic steps in HCCM to show that alignments are not arbitrary post-hoc choices but follow predefined matching criteria. revision: yes
-
Referee: [Proposed Method] Definition of HCCM and Liebig's score: The one-to-one matching procedure and the scoring formula are introduced as novel contributions, yet the manuscript provides no formal algorithmic description, complexity analysis, or proof that the matching is unique or stable under small perturbations of the dendrogram; these omissions render the new entities difficult to reproduce or compare against existing hierarchical clustering evaluation methods.
Authors: We will include a formal description of the HCCM algorithm with pseudocode in the Methods section. A complexity analysis will be added, showing that the procedure scales as O(N log N) where N is the number of clusters. For stability, we will perform empirical tests by introducing small perturbations to the dendrograms and measuring the consistency of the matches. While a general mathematical proof of uniqueness may require additional assumptions on the data distribution and is beyond the current scope, the empirical evidence and comparison to standard hierarchical evaluation metrics will be provided to facilitate reproducibility and comparison. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper applies the standard algorithms SLINK and HDBSCAN to existing speaker embeddings to identify clusters, then introduces the new HCCM procedure for one-to-one semantic matching and Liebig's score for quantification. No step reduces by construction to its inputs: there are no self-definitional loops where a claimed result is presupposed in the definition of the method, no fitted parameters relabeled as predictions, and no load-bearing self-citations or imported uniqueness theorems. The central claims rest on external clustering routines and a novel matching algorithm whose performance is evaluated against predefined metadata classes, keeping the chain self-contained and independent of the target observations.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Hierarchical Cluster-Class Matching (HCCM)
no independent evidence
-
Liebig's score
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[2]
Deep learning,
Y . LeCun, Y . Bengio, and G. Hinton, “Deep learning,”nature, vol. 521, no. 7553, pp. 436–444, 2015
2015
-
[3]
DARPA’s explainable artificial intelligence (XAI) program,
D. Gunning and D. Aha, “DARPA’s explainable artificial intelligence (XAI) program,”AI magazine, vol. 40, no. 2, pp. 44–58, 2019
2019
-
[4]
Explain- able AI: A brief survey on history, research areas, approaches and challenges,
F. Xu, H. Uszkoreit, Y . Du, W. Fan, D. Zhao, and J. Zhu, “Explain- able AI: A brief survey on history, research areas, approaches and challenges,” inNatural Language Processing and Chinese Computing: 8th CCF International Conference, NLPCC 2019, Dunhuang, China, October 9–14, 2019, Proceedings, Part II 8. Springer, 2019, pp. 563– 574
2019
-
[5]
Explainable AI: A review of machine learning interpretability methods,
P. Linardatos, V . Papastefanopoulos, and S. Kotsiantis, “Explainable AI: A review of machine learning interpretability methods,”Entropy, vol. 23, no. 1, p. 18, 2020
2020
-
[6]
An overview of the supervised machine learning methods,
V . Nasteski, “An overview of the supervised machine learning methods,” Horizons. b, vol. 4, no. 51-62, p. 56, 2017
2017
-
[7]
How humans learn and represent networks,
C. W. Lynn and D. S. Bassett, “How humans learn and represent networks,”Proceedings of the National Academy of Sciences, vol. 117, no. 47, pp. 29 407–29 415, 2020
2020
-
[8]
Selective attention
W. A. Johnston and V . J. Dark, “Selective attention.”Annual Review of Psychology, 1986
1986
-
[9]
W. Cai, J. Chen, and M. Li, “Exploring the encoding layer and loss function in end-to-end speaker and language recognition system,”arXiv preprint arXiv:1804.05160, 2018
-
[10]
V oxCeleb: A large-scale speaker identifica- tion dataset
A. Nagrani, J. S. Chung, and A. Zisserman, “V oxceleb: A large-scale speaker identification dataset,”arXiv preprint arXiv:1706.08612, 2017
-
[11]
In defence of metric learning for speaker recognition,
J. S. Chung, J. Huh, S. Mun, M. Lee, H. S. Heo, S. Choe, C. Ham, S. Jung, B.-J. Lee, and I. Han, “In defence of metric learning for speaker recognition,”arXiv preprint arXiv:2003.11982, 2020
-
[12]
Efficient integrated features based on pre-trained models for speaker verification,
Y . Li, W. Guan, H. Huang, S. Miao, Q. Su, L. Li, and Q. Hong, “Efficient integrated features based on pre-trained models for speaker verification,” inProc. Interspeech 2024, 2024, pp. 2140–2144
2024
-
[13]
Flat clustering,
C. D. Manning, P. Raghavan, and H. Sch ¨utze, “Flat clustering,”Intro- duction to Information Retrieval, vol. 356, p. 360, 2008
2008
-
[14]
Some methods for classification and analysis of multivariate observations,
J. MacQueenet al., “Some methods for classification and analysis of multivariate observations,” inProceedings of the fifth Berkeley Sym- posium on Mathematical Statistics and Probability, vol. 1, no. 14. Oakland, CA, USA, 1967, pp. 281–297
1967
-
[15]
Investigating deep neural network internal clustering and generalization properties,
G. Peiffer, “Investigating deep neural network internal clustering and generalization properties,” Master’s thesis, Universit ´e catholique de Louvain, Louvain, Belgium, 2021
2021
-
[16]
Intraclass clustering: An implicit learning ability that regularizes DNNs,
S. Carbonnelle and C. De Vleeschouwer, “Intraclass clustering: An implicit learning ability that regularizes DNNs,” inInternational Con- ference on Learning Representations, 2020
2020
-
[17]
Deep clustering for unsupervised learning of visual features,
M. Caron, P. Bojanowski, A. Joulin, and M. Douze, “Deep clustering for unsupervised learning of visual features,” inProceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 132–149
2018
-
[18]
The tree of diffusion life: Evolutionary embeddings to understand the generation process of diffusion models,
V . Prasad, H. van Gorp, C. Humer, A. Vilanova, and N. Pezzotti, “The tree of diffusion life: Evolutionary embeddings to understand the generation process of diffusion models,”arXiv e-prints, pp. arXiv–2406, 2024
2024
-
[19]
Frame- level phoneme-invariant speaker embedding for text-independent speaker recognition on extremely short utterances,
N. Tawara, A. Ogawa, T. Iwata, M. Delcroix, and T. Ogawa, “Frame- level phoneme-invariant speaker embedding for text-independent speaker recognition on extremely short utterances,” inICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6799–6803
2020
-
[20]
Visualizing data using t-SNE
L. Van der Maaten and G. Hinton, “Visualizing data using t-SNE.” Journal of Machine Learning Research, vol. 9, no. 11, 2008
2008
-
[21]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
L. McInnes, J. Healy, and J. Melville, “Umap: Uniform manifold approximation and projection for dimension reduction,”arXiv preprint arXiv:1802.03426, 2018
work page internal anchor Pith review arXiv 2018
-
[22]
Comprehensive survey on hierarchical clustering algorithms and the recent developments,
X. Ran, Y . Xi, Y . Lu, X. Wang, and Z. Lu, “Comprehensive survey on hierarchical clustering algorithms and the recent developments,” Artificial Intelligence Review, vol. 56, no. 8, pp. 8219–8264, 2023
2023
-
[23]
Minimum spanning trees and single linkage cluster analysis,
J. C. Gower and G. J. Ross, “Minimum spanning trees and single linkage cluster analysis,”Journal of the Royal Statistical Society: Series C (Applied Statistics), vol. 18, no. 1, pp. 54–64, 1969
1969
-
[24]
SLINK: an optimally efficient algorithm for the single-link cluster method,
R. Sibson, “SLINK: an optimally efficient algorithm for the single-link cluster method,”The Computer Journal, vol. 16, no. 1, pp. 30–34, 1973
1973
-
[25]
Density-based clustering based on hierarchical density estimates,
R. J. G. B. Campello, D. Moulavi, and J. Sander, “Density-based clustering based on hierarchical density estimates,” inAdvances in Knowledge Discovery and Data Mining, J. Pei, V . S. Tseng, L. Cao, H. Motoda, and G. Xu, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2013, pp. 160–172
2013
-
[26]
V-measure: A conditional entropy- based external cluster evaluation measure,
A. Rosenberg and J. Hirschberg, “V-measure: A conditional entropy- based external cluster evaluation measure,” inProceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Process- ing and Computational Natural Language Learning (EMNLP-CoNLL), 2007, pp. 410–420
2007
-
[27]
A statistical method for evaluating systematic relationships,
R. R. Sokal, C. D. Micheneret al., “A statistical method for evaluating systematic relationships,” 1958
1958
-
[28]
Morzycki,Modification
M. Morzycki,Modification. Cambridge University Press, 2016
2016
-
[29]
V on Liebig’s law of the minimum and plankton ecology (1899–1991),
H. De Baar, “V on Liebig’s law of the minimum and plankton ecology (1899–1991),”Progress in Oceanography, vol. 33, no. 4, pp. 347–386, 1994
1991
-
[30]
A unified approach to interpreting model predictions,
S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,”Advances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[31]
‘Why should i trust you?’ explaining the predictions of any classifier,
M. T. Ribeiro, S. Singh, and C. Guestrin, “‘Why should i trust you?’ explaining the predictions of any classifier,” inProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016, pp. 1135–1144
2016
-
[32]
Grad-CAM: Why did you say that?
R. R. Selvaraju, A. Das, R. Vedantam, M. Cogswell, D. Parikh, and D. Batra, “Grad-CAM: Why did you say that?”arXiv preprint arXiv:1611.07450, 2016
-
[33]
Learning deep features for discriminative localization,
B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba, “Learning deep features for discriminative localization,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2921– 2929
2016
-
[34]
RISE: Randomized Input Sampling for Explanation of Black-box Models
V . Petsiuk, A. Das, and K. Saenko, “Rise: Randomized input sampling for explanation of black-box models,”arXiv preprint arXiv:1806.07421, 2018
work page Pith review arXiv 2018
-
[35]
Latent space cartography: Visual analysis of vector space embeddings,
Y . Liu, E. Jun, Q. Li, and J. Heer, “Latent space cartography: Visual analysis of vector space embeddings,” inComputer graphics forum, vol. 38, no. 3. Wiley Online Library, 2019, pp. 67–78
2019
-
[36]
Closed-form factorization of latent semantics in GANs,
Y . Shen and B. Zhou, “Closed-form factorization of latent semantics in GANs,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 1532–1540
2021
-
[37]
L2m- gan: Learning to manipulate latent space semantics for facial attribute editing,
G. Yang, N. Fei, M. Ding, G. Liu, Z. Lu, and T. Xiang, “L2m- gan: Learning to manipulate latent space semantics for facial attribute editing,” in2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 2950–2959
2021
-
[38]
Ganalyze: Toward visual definitions of cognitive image properties,
L. Goetschalckx, A. Andonian, A. Oliva, and P. Isola, “Ganalyze: Toward visual definitions of cognitive image properties,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 5744–5753
2019
-
[39]
Toward a quantitative survey of dimension reduction techniques,
M. Espadoto, R. M. Martins, A. Kerren, N. S. Hirata, and A. C. Telea, “Toward a quantitative survey of dimension reduction techniques,”IEEE Transactions on Visualization and Computer Graphics, vol. 27, no. 3, pp. 2153–2173, 2019
2019
-
[40]
Algorithms for hierarchical clustering: an overview, ii,
F. Murtagh and P. Contreras, “Algorithms for hierarchical clustering: an overview, ii,”Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, vol. 7, no. 6, p. e1219, 2017
2017
-
[41]
Objective-based hierarchical clustering of deep embedding vectors,
S. Naumov, G. Yaroslavtsev, and D. Avdiukhin, “Objective-based hierarchical clustering of deep embedding vectors,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 10, pp. 9055–9063, May 2021. [Online]. Available: https://ojs.aaai.org/index. php/AAAI/article/view/17094
2021
-
[42]
Speaker diarization using deep neural network embeddings,
D. Garcia-Romero, D. Snyder, G. Sell, D. Povey, and A. McCree, “Speaker diarization using deep neural network embeddings,” in2017 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP). IEEE, 2017, pp. 4930–4934
2017
-
[43]
Supervised hierarchical clustering using graph neural networks for speaker diarization,
P. Singh, A. Kaul, and S. Ganapathy, “Supervised hierarchical clustering using graph neural networks for speaker diarization,” inICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[44]
Speaker identification and clustering using convolutional neural networks,
Y . Lukic, C. V ogt, O. D ¨urr, and T. Stadelmann, “Speaker identification and clustering using convolutional neural networks,” in2016 IEEE 26th 15 International Workshop on Machine Learning for Signal Processing (MLSP). IEEE, 2016, pp. 1–6
2016
-
[45]
A density-based algorithm for discovering clusters in large spatial databases with noise,
M. Ester, H.-P. Kriegel, J. Sander, and X. Xu, “A density-based algorithm for discovering clusters in large spatial databases with noise,” ser. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD’96). AAAI Press, 1996, p. 226–231
1996
-
[46]
A comprehensive survey of clustering algorithms,
D. Xu and Y . Tian, “A comprehensive survey of clustering algorithms,” Annals of Data Science, vol. 2, pp. 165–193, 2015
2015
-
[47]
Comprehensive cross-hierarchy cluster agreement evaluation
D. M. Johnson, C. Xiong, J. Gao, and J. J. Corso, “Comprehensive cross-hierarchy cluster agreement evaluation.” inAAAI (Late-Breaking Developments), 2013
2013
-
[48]
Hierarchical clustering algorithms for document datasets,
Y . Zhao, G. Karypis, and U. Fayyad, “Hierarchical clustering algorithms for document datasets,”Data Mining and Knowledge Discovery, vol. 10, pp. 141–168, 2005
2005
-
[49]
A review of the f-measure: Its history, properties, criticism, and alternatives,
P. Christen, D. J. Hand, and N. Kirielle, “A review of the f-measure: Its history, properties, criticism, and alternatives,”ACM Computing Surveys, vol. 56, no. 3, pp. 1–24, 2023
2023
-
[50]
Shortest connection networks and some generalizations,
R. C. Prim, “Shortest connection networks and some generalizations,” The Bell System Technical Journal, vol. 36, no. 6, pp. 1389–1401, 1957
1957
-
[51]
On the shortest spanning subtree of a graph and the traveling salesman problem,
J. B. Kruskal, “On the shortest spanning subtree of a graph and the traveling salesman problem,”Proceedings of the American Mathematical society, vol. 7, no. 1, pp. 48–50, 1956
1956
-
[52]
HDBSCAN: Hierarchical density based clustering,
L. McInnes, J. Healy, and S. Astels, “HDBSCAN: Hierarchical density based clustering,”The Journal of Open Source Software, vol. 2, no. 11, p. 205, 2017
2017
-
[53]
V oxceleb2: Deep speaker recognition,
J. S. Chung, A. Nagrani, and A. Zisserman, “V oxceleb2: Deep speaker recognition,”arXiv preprint arXiv:1806.05622, 2018
-
[54]
Prototypical networks for few-shot learning,
J. Snell, K. Swersky, and R. Zemel, “Prototypical networks for few-shot learning,”Advances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[55]
R. L. Solso, M. K. MacLin, and O. H. MacLin,Cognitive psychology. Pearson Education New Zealand, 2005
2005
-
[56]
Social psychology as history
K. J. Gergen, “Social psychology as history.”Journal of personality and social psychology, vol. 26, no. 2, p. 309, 1973
1973
-
[57]
Paralanguage: A first approximation,
G. L. Trager, “Paralanguage: A first approximation,”Stud. Linguist., vol. 13, pp. 1–12, 1958
1958
-
[58]
Speech pathology; a dynamic neurological treatment of normal speech and speech deviations
L. E. Travis, “Speech pathology; a dynamic neurological treatment of normal speech and speech deviations.” 1931
1931
-
[59]
A system for describing vocal timbre in popular song
K. Heidemann, “A system for describing vocal timbre in popular song.” Music Theory Online, vol. 22, no. 1, 2016
2016
-
[60]
Paralinguistic singing attribute recognition using supervised machine learning for describing the classical tenor solo singing voice in vocal pedagogy,
Y . Xu, W. Wang, H. Cui, M. Xu, and M. Li, “Paralinguistic singing attribute recognition using supervised machine learning for describing the classical tenor solo singing voice in vocal pedagogy,”EURASIP Journal on Audio, Speech, and Music Processing, vol. 2022, no. 1, p. 8, 2022. Yanze Xuwas admitted to the B.Sc. programme at Sun Yat-sen University as a ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.