Can Humans Detect AI? Mining Textual Signals of AI-Assisted Writing Under Varying Scrutiny Conditions
Pith reviewed 2026-05-08 07:20 UTC · model grok-4.3
The pith
Judges select warned AI-assisted writers as human 54 percent of the time, though standard text features show no difference between groups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
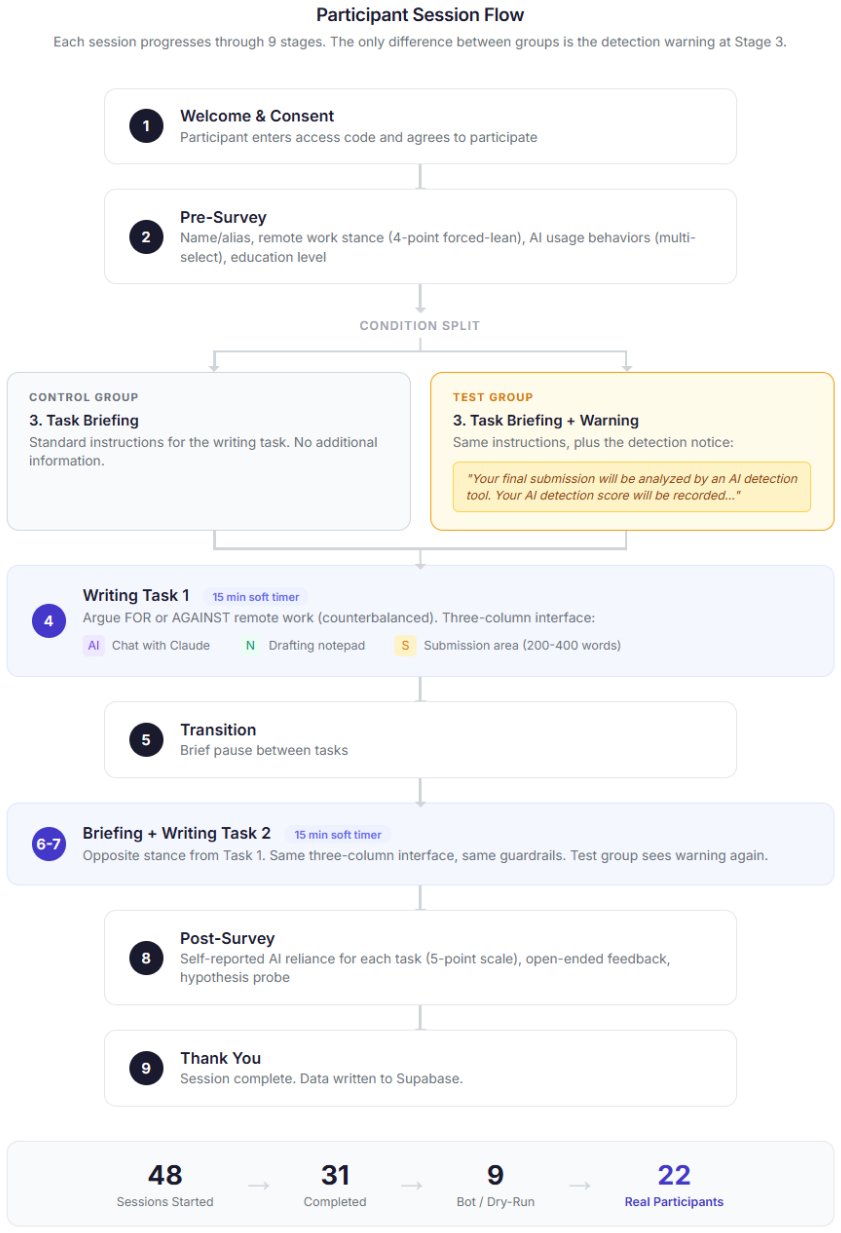
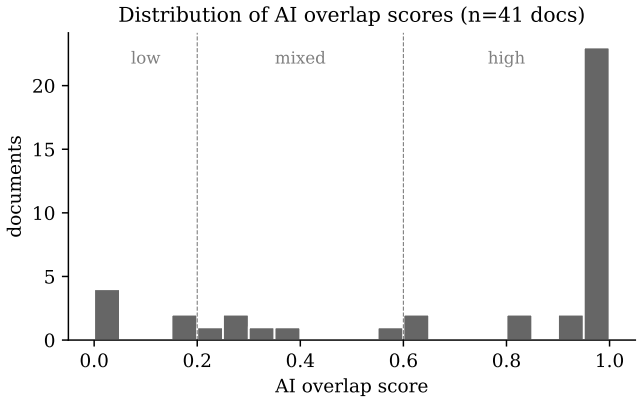
Writers warned that their AI-assisted documents would face detection produced texts that independent judges labeled as human-written at a rate of 54.13 percent compared with 45.87 percent for unwarned writers, a difference significant at p = 0.000243, while all extracted text features including AI overlap scores, lexical diversity, sentence structure, and pronoun usage proved statistically indistinguishable between the groups.
What carries the argument
The warning condition as the sole experimental variable in a two-phase setup, with blinded human pairwise judgments serving as the primary detection measure rather than automated classifiers.
If this is right
- Automated AI detectors relying on measurable text features will miss signals that become visible once writers know they are under scrutiny.
- Writers change their output style when warned about detection in ways that make the result appear more human to other readers.
- The human preference for warned texts holds across different writing stances, suggesting the effect is not limited to one topic or tone.
- Current feature sets fail to capture the full set of cues humans use when judging whether text involved AI assistance.
Where Pith is reading between the lines
- Detectors could improve by modeling how writers adapt behavior under the threat of monitoring rather than relying only on static linguistic statistics.
- The result suggests that training or priming writers about detection risks may produce AI-assisted text that is harder for both humans and machines to flag reliably.
- Similar warning effects might appear in other AI-assisted domains such as code or image creation, where human judgment could again outpace feature-based checks.
Load-bearing premise
Any differences judges notice stem directly from the warning and reflect genuine detection of AI assistance rather than other biases, random choices, or unmeasured influences on writing style.
What would settle it
A larger replication in which judges show no statistically significant preference for warned documents over unwarned ones in the same paired-comparison task.
Figures









read the original abstract
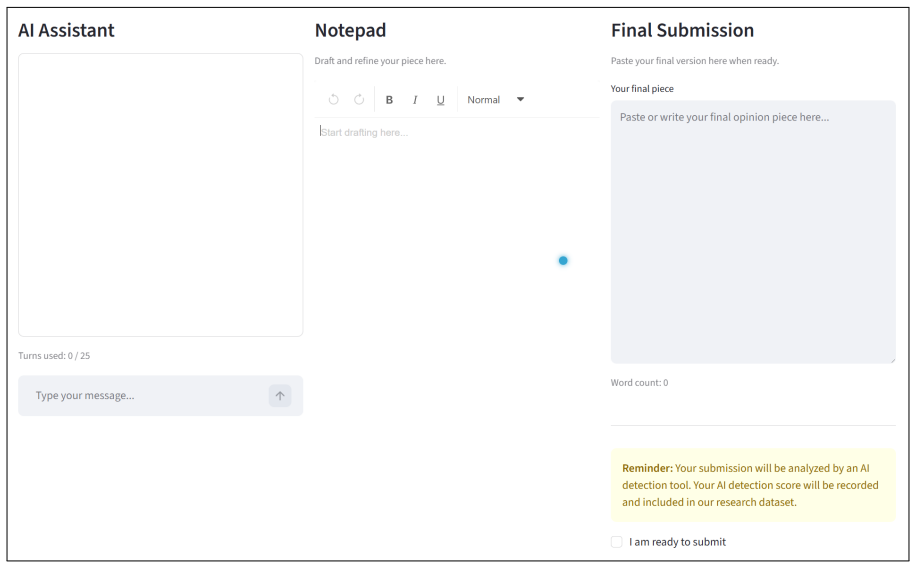
This study asks whether the threat of AI detection changes how people write with AI, and whether other people can tell the difference. In a two-phase controlled experiment, 21 participants wrote opinion pieces on remote work using an AI chatbot. Half were randomly warned that their submission would be scanned by an AI detection tool. The other half received no warning. Both groups had access to the same chatbot. In Phase 2, 251 independent judges evaluated 1,999 paired comparisons, each time choosing which document in the pair was written by a human. Judges were not told that both writers had access to AI. Across all evaluations, judges selected the warned writer's document as human 54.13% of the time versus 45.87% for the unwarned writer. A two-sided binomial test rejects chance guessing at p = 0.000243, and the result holds across both writing stances. Yet on every measurable text feature extracted, including AI overlap scores, lexical diversity, sentence structure, and pronoun usage, the two groups were indistinguishable. The judges are picking up on something that feature-based methods do not capture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a two-phase experiment with 21 writers producing AI-assisted opinion pieces on remote work (half randomly warned about AI detection scanning, half not). In Phase 2, 251 judges performed 1,999 paired comparisons and selected the warned document as human-written 54.13% of the time versus 45.87% for the unwarned document. A two-sided binomial test yields p=0.000243, with the result holding across writing stances. No differences were detected between groups on extracted textual features including AI overlap scores, lexical diversity, sentence structure, and pronoun usage.
Significance. If the central statistical claim survives reanalysis, the work demonstrates that human judges can detect subtle, scrutiny-induced shifts in AI-assisted writing that evade standard feature-based detection methods. This highlights limitations in current automated AI detectors and underscores the value of human evaluation under realistic conditions. The large number of judgments (1,999) and controlled design are strengths.
major comments (2)
- [Results] Results section (binomial test on 54.13% vs 45.87% selections, p=0.000243): The test assumes independent Bernoulli trials, but the design reuses the same 21 documents across 251 judges and 1,999 comparisons. This induces clustering at the document/writer level, violating independence, underestimating variance, and producing an anti-conservative p-value. A mixed-effects logistic regression with random intercepts for documents (or document-level clustering) is required to reassess significance.
- [Methods/Results] Feature analysis (indistinguishability claim): With only n=21 writers, the absence of differences on AI overlap, lexical diversity, sentence structure, and pronoun usage does not establish equivalence. No details are provided on exact feature definitions, extraction methods, statistical tests for differences, or power/equivalence analyses (e.g., TOST). This weakens the claim that judges detect signals 'not captured by features.'
minor comments (3)
- [Methods] Clarify the exact procedure for constructing the 1,999 pairs (e.g., matching criteria, randomization) to rule out selection biases.
- [Methods] Provide the full list of textual features, their computation formulas or tools used, and any preprocessing steps.
- [Results] Report effect sizes or confidence intervals alongside the binomial p-value for interpretability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments on our manuscript. We address each major comment point by point below, agreeing with the concerns raised and outlining the specific revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Results] Results section (binomial test on 54.13% vs 45.87% selections, p=0.000243): The test assumes independent Bernoulli trials, but the design reuses the same 21 documents across 251 judges and 1,999 comparisons. This induces clustering at the document/writer level, violating independence, underestimating variance, and producing an anti-conservative p-value. A mixed-effects logistic regression with random intercepts for documents (or document-level clustering) is required to reassess significance.
Authors: We agree that the binomial test is inappropriate here because the same 21 documents are evaluated repeatedly across judges, violating the independence assumption and likely underestimating variance. To correct this, we will reanalyze the 1,999 judgments using a mixed-effects logistic regression with random intercepts for each document (and potentially writer). We will report the model specification, estimated effects, confidence intervals, and p-values in the revised Results section and update the abstract and discussion accordingly if the substantive conclusion changes. revision: yes
-
Referee: [Methods/Results] Feature analysis (indistinguishability claim): With only n=21 writers, the absence of differences on AI overlap, lexical diversity, sentence structure, and pronoun usage does not establish equivalence. No details are provided on exact feature definitions, extraction methods, statistical tests for differences, or power/equivalence analyses (e.g., TOST). This weakens the claim that judges detect signals 'not captured by features.'
Authors: We acknowledge that n=21 is small and that failing to detect differences does not demonstrate equivalence; we also omitted detailed feature definitions, extraction code or formulas, the exact statistical tests applied, and any power or equivalence analysis. In revision we will expand the Methods section with precise definitions and computation steps for every feature (AI overlap via embedding cosine similarity, lexical diversity via type-token ratio and MTLD, sentence structure via parse-tree depth and length statistics, pronoun usage via POS tagging counts), specify the tests used (two-sample t-tests or Wilcoxon rank-sum with exact p-values), add a post-hoc power calculation, and perform two one-sided tests (TOST) for equivalence on each feature. We will also revise the interpretation in Results and Discussion to state that no significant differences were observed on these features rather than claiming full indistinguishability, while noting that human judges may still be responding to unmeasured cues. revision: partial
Circularity Check
No circularity: empirical experiment with direct statistical test on human judgments
full rationale
The paper reports an experimental result from a controlled two-phase study with 21 writers and 251 judges producing 1,999 paired judgments. The central claim (54.13% selection rate for warned documents, p=0.000243 via two-sided binomial test) follows directly from observed choice counts without any equations, fitted parameters, ansatzes, or derivations that reduce to the inputs by construction. Text-feature comparisons are likewise direct empirical measurements. No self-citation chains, uniqueness theorems, or renamings of known results underpin the load-bearing evidence. The analysis is self-contained as a standard empirical comparison against external human judgments.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Random assignment to warned and unwarned conditions controls for individual differences in writing ability and AI usage style
- domain assumption The set of extracted text features (AI overlap, lexical diversity, sentence structure, pronoun usage) is sufficient to detect any stylistic differences present
Reference graph
Works this paper leans on
-
[1]
A., Chen, M., & Burrows, L
Bargh, J. A., Chen, M., & Burrows, L. (1996). Automaticity of social behavior: Direct effects of trait construct and stereotype activation on action.Journal of Personality and Social Psychology, 71(2), 230–244
1996
-
[2]
TurningtoTurnitintofightplagiarismamonguniversitystudents.Educational Technology & Society, 13(2), 1–12
Batane, T.(2010). TurningtoTurnitintofightplagiarismamonguniversitystudents.Educational Technology & Society, 13(2), 1–12
2010
-
[3]
Bilic-Zulle, L., Frkovic, V., Turk, T., Azman, J., & Petrovecki, M. (2008). Is there an effective approach to deterring students from plagiarizing?Science and Engineering Ethics, 14, 139–147
2008
-
[4]
Brehm, J. W. (1966).A Theory of Psychological Reactance. Academic Press
1966
-
[5]
Brooks, J. L. (2012). Counterbalancing for serial order carryover effects in experimental condition orders.Psychological Methods, 17(4), 600–614
2012
-
[6]
Language Models are Few-Shot Learners
Brown, T. B., Mann, B., Ryder, N., et al. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems33. arXiv:2005.14165. https://arxiv. org/abs/2005.14165
work page internal anchor Pith review arXiv 2020
-
[7]
Corneille, O., & Lush, P. (2023). Sixty years after Orne’s American Psychologist article: A conceptual framework for subjective experiences elicited by demand characteristics.Personality and Social Psychology Review, 27(1), 83–101.https://doi.org/10.1177/10888683221104368
-
[8]
E., Isom, M., Jarosova, R., & Hua, D
Desaire, H., Chua, A. E., Isom, M., Jarosova, R., & Hua, D. (2023). Distinguishing academic science writing from humans or ChatGPT with over 99% accuracy using off-the-shelf machine 22 learning tools.Cell Reports Physical Science, 4(6), 101426.https://doi.org/10.1016/j.xcrp. 2023.101426
-
[9]
Jiang, F., & Hyland, K. (2025). Does ChatGPT argue like students? Bundles in argumentative essays.Applied Linguistics, 46, 375–391.https://doi.org/10.1093/applin/amae052
-
[10]
M., Halverson, C., Horn, D., & Karat, J
Karat, C. M., Halverson, C., Horn, D., & Karat, J. (1999). Patterns of entry and correction in large vocabulary continuous speech recognition systems.Proceedings of CHI ’99, 568–575
1999
-
[11]
no opinion
Krosnick, J. A., Holbrook, A. L., Berent, M. K., Carson, R. T., Hanemann, W. M., Kopp, R. J., ... Conaway, M. (2002). The impact of “no opinion” response options on data quality.Public Opinion Quarterly, 66(3), 371–403
2002
-
[12]
Lee, K., Ippolito, D., Nystrom, A., Zhang, C., Eck, D., Callison-Burch, C., & Carlini, N. (2022). Deduplicating training data makes language models better.Proceedings of ACL 2022. arXiv:2107.06499.https://arxiv.org/abs/2107.06499
work page Pith review arXiv 2022
-
[13]
McCambridge, J., Witton, J., & Elbourne, D. R. (2014). Systematic review of the Hawthorne effect: New concepts are needed to study research participation effects.Journal of Clinical Epidemiology, 67(3), 267–277
2014
-
[14]
Mummolo, J., & Peterson, E. (2019). Demand effects in survey experiments: An empirical assessment.American Political Science Review, 113(2), 517–529
2019
-
[15]
Noy, S., & Zhang, W. (2023). Experimental evidence on the productivity effects of generative artificial intelligence.Science, 381(6654), 187–192
2023
-
[16]
Orne, M. T. (1962). On the social psychology of the psychological experiment.American Psychologist, 17(11), 776–783
1962
-
[17]
Reviriego, P., Conde, J., Merino-Gomez, E., Martinez, G., & Hernandez, J. A. (2024). Playing with words: Comparing the vocabulary and lexical diversity of ChatGPT and humans.Machine Learning with Applications, 18, 100602.https://doi.org/10.1016/j.mlwa.2024.100602
- [18]
-
[19]
Schleimer, S., Wilkerson, D. S., & Aiken, A. (2003). Winnowing: Local algorithms for document fingerprinting.Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data, 76–85.https://doi.org/10.1145/872757.872770
-
[20]
Schwarz, N. (1999). Self-reports: How the questions shape the answers.American Psychologist, 54(2), 93–105.https://doi.org/10.1037/0003-066X.54.2.93
-
[21]
Weingarten, E., et al. (2016). From primed concepts to action: A meta-analysis of the behavioral effects of incidentally presented words.Psychological Bulletin, 142(5), 472–497
2016
-
[22]
Affected docs
Zenker, F., & Kyle, K. (2021). Investigating minimum text length for lexical diversity indices. Assessing Writing, 47, 100505. 23 Appendix A. Full Assignment Table (PIDs 1 to 12) PID Condition Task 1 Task 2 1 Control For Against 2 Test For Against 3 Control Against For 4 Test Against For 5 Control For Against 6 Test For Against 7 Control Against For 8 Tes...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.