Recognition: unknown
Supernodes and Halos: Loss-Critical Hubs in LLM Feed-Forward Layers
Pith reviewed 2026-05-08 06:40 UTC · model grok-4.3
The pith
A small number of channels carry most of the loss sensitivity in each LLM feed-forward layer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM feed-forward layers contain a small learned core of loss-critical channels called supernodes. In Llama-3.1-8B the top 1 percent of channels per layer hold a median 58.7 percent of total loss-proxy mass, with the range across layers from 33.0 to 86.1 percent. These supernodes overlap only weakly with activation outliers and are not explained by activation power or weight norms. They are surrounded by a weaker halo of non-supernode channels that share write support and show greater redundancy with the core. One-shot structured pruning experiments confirm the functional importance of the core: at 50 percent FFN sparsity, methods that remove many supernodes reach perplexity near 989 while SC
What carries the argument
The supernode, a loss-critical channel identified by ranking channels according to a Fisher-style loss proxy computed from activation-gradient second moments, which functions as a hub whose preservation is required to keep loss low.
Load-bearing premise
The second-moment loss proxy accurately ranks channels by their true contribution to overall model loss.
What would settle it
An experiment that ablates the top-ranked LP channels and measures the resulting perplexity increase against an equal number of randomly chosen non-supernode channels; equal or smaller impact from the supernodes would falsify the concentration claim.
Figures



read the original abstract
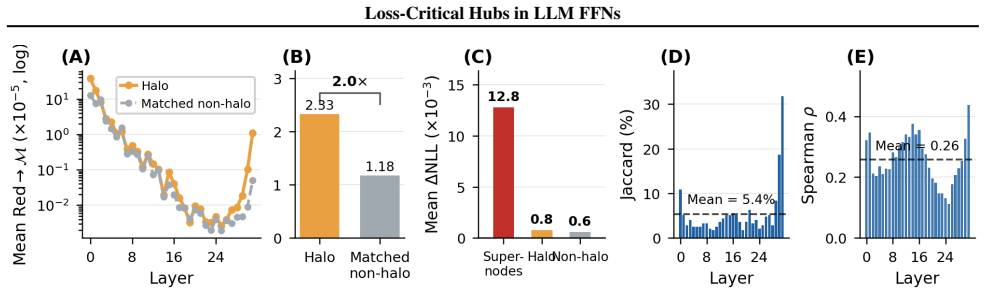
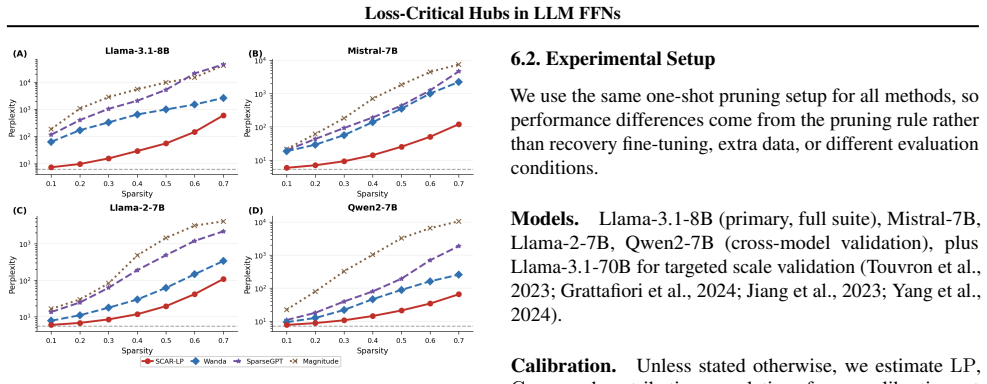
We study the organization of channel-level importance in transformer feed-forward networks (FFNs). Using a Fisher-style loss proxy (LP) based on activation-gradient second moments, we show that loss sensitivity is concentrated in a small set of channels within each layer. In Llama-3.1-8B, the top 1% of channels per layer accounts for a median of 58.7% of LP mass, with a range of 33.0% to 86.1%. We call these loss-critical channels supernodes. Although FFN layers also contain strong activation outliers, LP-defined supernodes overlap only weakly with activation-defined outliers and are not explained by activation power or weight norms alone. Around this core, we find a weaker but consistent halo structure: some non-supernode channels share the supernodes' write support and show stronger redundancy with the protected core. We use one-shot structured FFN pruning as a diagnostic test of this organization. At 50% FFN sparsity, baselines that prune many supernodes degrade sharply, whereas our SCAR variants explicitly protect the supernode core; the strongest variant, SCAR-Prot, reaches perplexity 54.8 compared with 989.2 for Wanda-channel. The LP-concentration pattern appears across Mistral-7B, Llama-2-7B, and Qwen2-7B, remains visible in targeted Llama-3.1-70B experiments, and increases during OLMo-2-7B pretraining. These results suggest that LLM FFNs develop a small learned core of loss-critical channels, and that preserving this core is important for reliable structured pruning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that loss sensitivity in LLM feed-forward layers is highly concentrated in a small set of channels ('supernodes') identified by a Fisher-style loss proxy (LP) based on activation-gradient second moments. In Llama-3.1-8B, the top 1% of channels per layer accounts for a median of 58.7% of LP mass (range 33.0%-86.1%). These supernodes overlap only weakly with activation outliers and are not explained by activation magnitude or weight norms. A surrounding 'halo' of redundant channels is identified. One-shot structured pruning experiments show that explicitly protecting the LP-defined core (SCAR-Prot) yields perplexity 54.8 at 50% FFN sparsity versus 989.2 for Wanda-channel. The concentration pattern holds across Mistral-7B, Llama-2-7B, Qwen2-7B, targeted Llama-3.1-70B runs, and increases during OLMo-2-7B pretraining.
Significance. If the core organization claim holds, the work provides useful insight into FFN structure with implications for pruning, sparsity, and interpretability of LLMs. The multi-model replication of the LP concentration pattern and the use of one-shot pruning as a functional diagnostic are explicit strengths that support the central thesis. The findings could inform structured pruning methods that prioritize loss-critical components.
major comments (2)
- [Abstract and pruning experiments (Section 4)] The central claim that supernodes are loss-critical hubs rests on the LP proxy faithfully measuring per-channel contribution to model loss. However, no section reports a controlled ablation that zeros channels ranked by LP and directly measures the resulting held-out loss delta, independent of the SCAR pruning construction or halo structure. The reported pruning gap (SCAR-Prot at 54.8 PPL vs. Wanda at 989.2) is consistent but indirect, as SCAR is explicitly built to shield the LP core.
- [Methods (LP definition and computation)] Details on the exact LP computation—including how activation-gradient second moments are estimated, any layer-wise or token sampling, and the precise definition of the second-moment matrix—are insufficient for reproducibility. This is load-bearing because the reported concentration statistics (e.g., median 58.7% LP mass in top 1%) and the distinction from activation outliers depend on the proxy's implementation.
minor comments (2)
- [Results on halo structure] The halo structure is described qualitatively; quantitative metrics for redundancy (e.g., cosine similarity of write vectors or activation correlation with supernodes) would clarify its strength and consistency.
- [Figures] Figure captions and axis labels should explicitly state the models, layers, and sparsity levels used in each panel to improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for highlighting the potential significance of the supernode organization for pruning and interpretability. We address each major comment point by point below. Revisions will be incorporated to strengthen the evidence and reproducibility of the LP proxy.
read point-by-point responses
-
Referee: [Abstract and pruning experiments (Section 4)] The central claim that supernodes are loss-critical hubs rests on the LP proxy faithfully measuring per-channel contribution to model loss. However, no section reports a controlled ablation that zeros channels ranked by LP and directly measures the resulting held-out loss delta, independent of the SCAR pruning construction or halo structure. The reported pruning gap (SCAR-Prot at 54.8 PPL vs. Wanda at 989.2) is consistent but indirect, as SCAR is explicitly built to shield the LP core.
Authors: We agree that the pruning results, while demonstrating the practical value of protecting LP-defined channels, constitute an indirect test because SCAR is constructed around the supernode core. A direct ablation that isolates LP ranking by zeroing channels and measuring held-out loss change would provide stronger validation of the proxy. In the revised manuscript we will add such an experiment to Section 4: channels will be ranked and zeroed solely by LP (without SCAR or halo considerations), and the resulting perplexity delta will be reported on held-out data. This addition will directly address the concern while preserving the existing pruning diagnostics. revision: yes
-
Referee: [Methods (LP definition and computation)] Details on the exact LP computation—including how activation-gradient second moments are estimated, any layer-wise or token sampling, and the precise definition of the second-moment matrix—are insufficient for reproducibility. This is load-bearing because the reported concentration statistics (e.g., median 58.7% LP mass in top 1%) and the distinction from activation outliers depend on the proxy's implementation.
Authors: We acknowledge that the current Methods description is insufficient for exact replication of the LP values and concentration statistics. We will expand the relevant subsection to provide: the precise mathematical definition of the second-moment matrix (expected outer product of per-channel activation-gradient vectors), the estimation procedure (including token sampling strategy, number of tokens/layer, batch size, and whether gradients are computed on a frozen forward pass), layer-wise independence of the computation, and any normalization steps. Pseudocode will be added for clarity, ensuring the median 58.7% figure and outlier comparisons can be reproduced. revision: yes
Circularity Check
No significant circularity; empirical concentration and pruning test are independent
full rationale
The paper computes the Fisher-style LP metric from activation-gradient second moments, then reports the empirical concentration of LP mass (top 1% holding median 58.7%) and labels the high-LP channels as supernodes. This is a direct distributional measurement on the computed values rather than a self-referential definition or tautology, as uniform LP would yield only 1% mass in the top 1%. The paper further validates by showing weak overlap with activation outliers and weight norms. One-shot pruning experiments (SCAR-Prot vs. Wanda-channel) provide an independent functional test of whether protecting the LP-ranked core preserves performance, without reducing to the LP definition itself. No self-citations, uniqueness theorems, ansatzes, or fitted inputs presented as predictions appear in the derivation. The chain is self-contained against the reported data and ablation-style pruning outcomes.
Axiom & Free-Parameter Ledger
free parameters (1)
- supernode threshold =
1%
axioms (1)
- domain assumption Second-moment approximation to Fisher information is a valid proxy for per-channel loss sensitivity
invented entities (2)
-
supernode
no independent evidence
-
halo
no independent evidence
Reference graph
Works this paper leans on
-
[1]
BoolQ: Exploring the surprising difficulty of natural yes/no questions
Clark, C., Lee, K., Chang, M.-W., Kwiatkowski, T., Collins, M., and Toutanova, K. BoolQ: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, pp. 2924– 2936,
2019
-
[2]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try ARC, the AI2 reasoning chal- lenge.arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review arXiv
-
[3]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review arXiv
-
[4]
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., et al. Mistral 7b.arXiv preprint arXiv:2310.06825,
work page internal anchor Pith review arXiv
-
[5]
Pointer Sentinel Mixture Models
Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843,
work page internal anchor Pith review arXiv
-
[6]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Mihaylov, T., Clark, P., Khot, T., and Sabharwal, A. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 2381–2391,
2018
-
[7]
Sun, M., Chen, X., Kolter, J. Z., and Liu, Z. Massive activations in large language models. InFirst Conference on Language Modeling, 2024a. Sun, M., Liu, Z., Bair, A., and Kolter, J. Z. A simple and effective pruning approach for large language models. In International Conference on Learning Representations, 2024b. Team OLMo, Walsh, P., Soldaini, L., Groe...
work page internal anchor Pith review arXiv
-
[8]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine- tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review arXiv
-
[9]
Yang, A., Yang, B., Hui, B., Zheng, B., Yu, B., Zhou, C., Li, C., Li, C., Liu, D., Huang, F., et al. Qwen2 technical report.arXiv preprint arXiv:2407.10671,
work page internal anchor Pith review arXiv
-
[10]
Super weights: The hidden powerhouses of large language models.arXiv preprint arXiv:2411.07191,
Yu, M., Wang, D., Shan, Q., Reed, C. J., and Wan, A. The super weight in large language models.arXiv preprint arXiv:2411.07191,
-
[11]
Experimental Protocol and Reproducibility This section gives the concrete setup behind the main re- sults: the models, metric estimation, pruning protocol, and evaluation setup
A. Experimental Protocol and Reproducibility This section gives the concrete setup behind the main re- sults: the models, metric estimation, pruning protocol, and evaluation setup. Models.Primary: Llama-3.1-8B (meta-llama/Llama-3.1-8B); additional vali- dation on Mistral-7B, Llama-2-7B, and Qwen2-7B; targeted scale validation on Llama-3.1-70B. We evaluate...
2048
-
[12]
Intuition.Because lower scores are pruned first, multiply- ing LP by a smaller protection value makes highly redundant halo channels more likely to be removed
Supernodes are excluded from the candi- date prune set for all variants. Intuition.Because lower scores are pruned first, multiply- ing LP by a smaller protection value makes highly redundant halo channels more likely to be removed. Channels with low redundancy (low rj) get Protectj ≈1 and retain their LP score. Channels with high redundancy, correspondin...
1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.