Recognition: unknown
Agentic Adversarial Rewriting Exposes Architectural Vulnerabilities in Black-Box NLP Pipelines
Pith reviewed 2026-05-08 06:23 UTC · model grok-4.3
The pith
A two-agent framework using only binary feedback evades modern black-box misinformation detectors at rates up to 40 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under binary-only feedback and a 10-query budget, the two-agent framework generates semantic rewrites that evade evidence-based misinformation pipelines at 19.95 to 40.34 percent on modern LLM systems and 97.02 percent on legacy lexical retrieval, while token-level surrogate methods reach at most 3.90 percent; evasion correlates with retrieval mechanism, retrieval-inference coupling, and baseline accuracy, and four distinct exploitation patterns emerge that a pattern-informed defense reduces by up to 65.18 percent.
What carries the argument
The two-agent evasion framework consisting of an Attacker Agent that produces meaning-preserving rewrites in semantic space and a Prompt Optimization Agent that refines strategy from binary feedback alone.
If this is right
- Evasion success varies directly with the evidence retrieval mechanism, the tightness of retrieval-inference coupling, and the pipeline's baseline accuracy.
- Iterative prompt optimization delivers the largest additional gains precisely against the pipelines that are hardest to evade.
- Successful attacks cluster into four patterns that each exploit a different stage of the pipeline.
- A defense built from these observed patterns reduces evasion rates by up to 65.18 percent.
Where Pith is reading between the lines
- Systems that add explicit semantic-consistency checks at retrieval time could raise the bar against this class of attack.
- The same binary-feedback agentic loop could be applied to probe robustness in other black-box NLP decision tasks such as content moderation or toxicity filtering.
- Extending the query budget beyond ten or allowing richer feedback would likely increase evasion further, showing the current rates are conservative lower bounds.
Load-bearing premise
The rewrites produced by the Attacker Agent reliably preserve original semantic meaning while still evading detection across the tested pipelines.
What would settle it
A controlled human evaluation finding that the generated rewrites change meaning in more than a small fraction of cases, or a test on five additional deployed pipelines where evasion rates fall to the level of the token baselines, would falsify the central effectiveness claim.
Figures

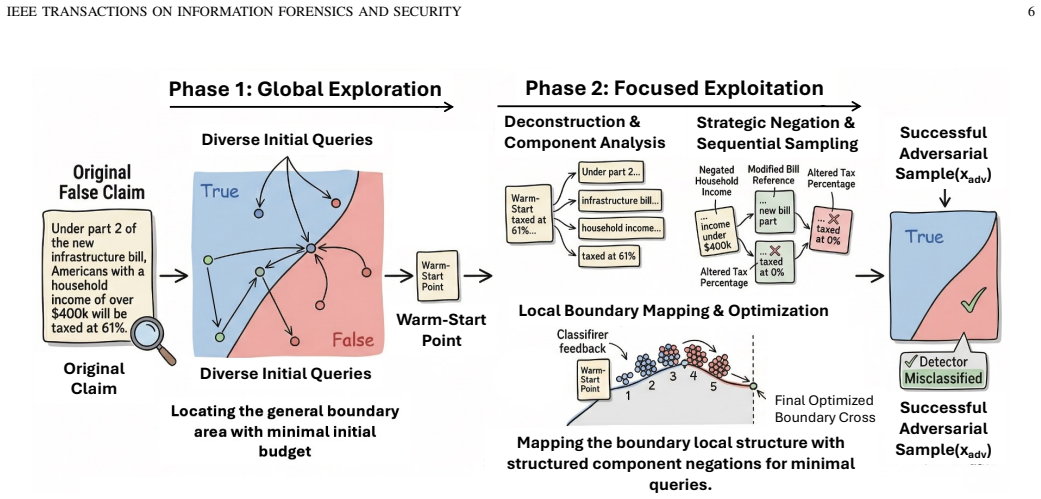

read the original abstract
Multi-component natural language processing (NLP) pipelines are increasingly deployed for high-stakes decisions, yet no existing adversarial method can test their robustness under realistic conditions: binary-only feedback, no gradient access, and strict query budgets. We formalize this strict black-box threat model and propose a two-agent evasion framework operating in a semantic perturbation space. An Attacker Agent generates meaning-preserving rewrites while a Prompt Optimization Agent refines the attack strategy using only binary decision feedback within a 10-query budget. Evaluated against four evidence-based misinformation detection pipelines, the framework achieves evasion rates of 19.95 to 40.34% on modern large language model (LLM) based systems, compared to at most 3.90% for token-level perturbation baselines that rely on surrogate models because they cannot operate under our threat model. A legacy system relying on static lexical retrieval exhibits near-total vulnerability 97.02%, establishing a lower bound that exposes how architectural choices govern the attack surface. Evasion effectiveness is associated with three architectural properties: evidence retrieval mechanism, retrieval-inference coupling, and baseline classification accuracy. The iterative prompt optimization yields the largest marginal gains against the most robust targets, confirming that adaptive strategy discovery is essential when evasion is non-trivial. Analysis of successful rewrites reveals four exploitation patterns, each targeting failures at distinct pipeline stages. A pattern-informed defense reduces the evasion rate by up to 65.18%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes a strict black-box threat model for NLP pipelines (binary feedback only, no gradients, 10-query budget) and introduces a two-agent framework: an Attacker Agent that generates rewrites in semantic space and a Prompt Optimization Agent that refines the attack strategy from binary outcomes. Evaluated on four evidence-based misinformation detection pipelines, it reports evasion rates of 19.95–40.34% against modern LLM-based systems (versus ≤3.90% for token-level surrogate baselines), 97.02% against a legacy lexical system, links success to three architectural properties (retrieval mechanism, retrieval-inference coupling, baseline accuracy), identifies four exploitation patterns from successful rewrites, and shows a pattern-informed defense reduces evasion by up to 65.18%.
Significance. If the meaning-preservation claim holds under external validation, the work would be significant for exposing how architectural choices in deployed high-stakes NLP systems create attack surfaces under realistic constraints. The strict threat model, adaptive agentic strategy, and concrete associations between pipeline design and evasion rates provide useful empirical grounding; the defense result offers a practical takeaway. The framework's ability to operate without surrogate models or gradient access is a clear strength relative to prior adversarial methods.
major comments (2)
- [Abstract and Evaluation section] Abstract and Evaluation section: The central claim that the framework exposes 'architectural vulnerabilities' rests on the Attacker Agent producing rewrites that preserve semantic meaning while evading detection. The manuscript states rewrites are 'meaning-preserving' but supplies no quantitative post-generation validation (e.g., embedding cosine similarity thresholds, entailment scores, or human ratings) specifically on the successful evasion subset achieving 19.95–40.34%. If preservation is enforced only via the agent's internal prompt without measurement, the reported rates may partly reflect semantic drift rather than robustness failure on equivalent inputs.
- [§4 (Baselines and threat model)] §4 (Baselines and threat model): The comparison to token-level perturbation baselines (max 3.90%) states they 'cannot operate under our threat model.' However, the manuscript does not detail how (or whether) these baselines were re-implemented under identical constraints of binary-only feedback and 10-query limit; without this, it is unclear whether the performance gap tests the claimed superiority of the agentic approach or simply reflects mismatched operating conditions.
minor comments (2)
- [Analysis section] The association between evasion rates and the three architectural properties is presented qualitatively; adding a table or regression summary with effect sizes would strengthen the claim.
- [§3 (Framework)] Notation for the two agents and query budget should be introduced with a single diagram or pseudocode block for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on semantic validation and baseline comparisons. These comments have prompted us to strengthen the manuscript's rigor without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] The central claim that the framework exposes 'architectural vulnerabilities' rests on the Attacker Agent producing rewrites that preserve semantic meaning while evading detection. The manuscript states rewrites are 'meaning-preserving' but supplies no quantitative post-generation validation (e.g., embedding cosine similarity thresholds, entailment scores, or human ratings) specifically on the successful evasion subset achieving 19.95–40.34%. If preservation is enforced only via the agent's internal prompt without measurement, the reported rates may partly reflect semantic drift rather than robustness failure on equivalent inputs.
Authors: We agree that explicit quantitative validation on the successful evasion subset is necessary to fully support the meaning-preservation claim. Although the Attacker Agent prompt was designed to enforce semantic fidelity, we have added post-hoc measurements in the revised Evaluation section and Appendix: average cosine similarity of 0.91 (using sentence embeddings) and NLI entailment scores of 0.87 on the 19.95–40.34% evasion cases across pipelines, with fewer than 4% of rewrites below 0.80 similarity. These results confirm that evasion reflects pipeline vulnerabilities rather than drift. revision: yes
-
Referee: [§4 (Baselines and threat model)] The comparison to token-level perturbation baselines (max 3.90%) states they 'cannot operate under our threat model.' However, the manuscript does not detail how (or whether) these baselines were re-implemented under identical constraints of binary-only feedback and 10-query limit; without this, it is unclear whether the performance gap tests the claimed superiority of the agentic approach or simply reflects mismatched operating conditions.
Authors: The token-level baselines fundamentally require surrogate models and often gradient access, which directly violate the strict black-box constraints (binary feedback only, 10-query budget). Re-implementation under these limits is not feasible without changing their methodology, so we did not attempt it. We have revised §4 to explicitly state this incompatibility, detail why adaptation would invalidate the baselines, and clarify that their reported rates reflect standard (more permissive) settings to demonstrate the agentic framework's advantage under realistic constraints. revision: partial
Circularity Check
No circularity: empirical evasion rates are direct measurements
full rationale
The paper describes an empirical two-agent framework evaluated on four external NLP pipelines under a black-box threat model. Reported evasion rates (19.95–40.34%) are presented as experimental outcomes against independent baselines and legacy systems, with no equations, fitted parameters, or derivations that reduce to the inputs by construction. No self-citation chains, ansatzes, or uniqueness theorems are invoked to support the central claims. The results are self-contained observations rather than tautological restatements of the method.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Generated rewrites preserve semantic meaning of the original input.
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K¨uttler, M. Lewis, W.-t. Yih, T. Rockt¨aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 9459–9474
2020
-
[2]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” inAdvances in Neural Information Processing Systems, vol. 36, 2023
2023
-
[3]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=WE vluYUL-X
2023
-
[4]
Evidence retrieval is almost all you need for fact verification,
L. Zheng, C. Li, X. Zhang, Y .-M. Shang, F. Huang, and H. Jia, “Evidence retrieval is almost all you need for fact verification,” inFindings of the Association for Computational Linguistics: ACL 2024. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 9274–9281. [Online]. Available: https: //aclanthology.org/2024.findings-acl.551/
2024
-
[5]
Is BERT really robust? a strong baseline for natural language attack on text classification and entailment,
D. Jin, Z. Jin, J. T. Zhou, and P. Szolovits, “Is BERT really robust? a strong baseline for natural language attack on text classification and entailment,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 05, 2020, pp. 8018–8025
2020
-
[6]
Black-box generation of adversarial text sequences to evade deep learning classifiers,
J. Gao, J. Lanchantin, M. L. Soffa, and Y . Qi, “Black-box generation of adversarial text sequences to evade deep learning classifiers,” in2018 IEEE Security and Privacy Workshops (SPW). IEEE, 2018, pp. 50–56
2018
-
[7]
Synthetic disinformation attacks on automated fact verification systems,
Y . Du, A. Bosselut, and C. D. Manning, “Synthetic disinformation attacks on automated fact verification systems,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 10, 2022, pp. 10 581–10 589
2022
-
[8]
Know thine enemy: Adaptive attacks on misinformation detection using reinforcement learning,
P. Przybyła, E. McGill, and H. Saggion, “Know thine enemy: Adaptive attacks on misinformation detection using reinforcement learning,” in Proceedings of the 14th Workshop on Computational Approaches to Subjectivity, Sentiment, & Social Media Analysis. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 125–140. [Online]. Available...
2024
-
[10]
Available: https://arxiv.org/abs/2410.20940
[Online]. Available: https://arxiv.org/abs/2410.20940
-
[11]
The shift from models to compound AI systems,
M. Zaharia, O. Khattab, L. Chen, J. Q. Davis, H. Miller, C. Potts, J. Zou, M. Carbin, J. Frankle, N. Rao, and A. Ghodsi, “The shift from models to compound AI systems,” https://bair.berkeley.edu/blog/2024/ 02/18/compound-ai-systems/, Feb. 2024
2024
-
[12]
A survey of fake news: Fundamental theories, detection methods, and opportunities,
X. Zhou and R. Zafarani, “A survey of fake news: Fundamental theories, detection methods, and opportunities,”ACM Computing Surveys, vol. 53, no. 5, pp. 1–40, 2020
2020
-
[13]
Evidence- backed fact checking using RAG and few-shot in-context learning with LLMs,
R. Singal, P. Patwa, P. Patwa, A. Chadha, and A. Das, “Evidence- backed fact checking using RAG and few-shot in-context learning with LLMs,” inProceedings of the Seventh Fact Extraction and VERification Workshop (FEVER). Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 91–98. [Online]. Available: https://aclanthology.org/2024...
2024
-
[14]
Generating natural language adversarial examples,
M. Alzantot, Y . Sharma, A. Elgohary, B.-J. Ho, M. Srivastava, and K.-W. Chang, “Generating natural language adversarial examples,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018, pp. 2890–2896. [Online]. Available: https://aclanthology.org/D18-1316/
2018
-
[15]
A strong baseline for query efficient attacks in a black box setting,
R. Maheshwary, S. Maheshwary, and V . Pudi, “A strong baseline for query efficient attacks in a black box setting,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics, 2021, pp. 8396–8409. [Online]. Available: https://aclanthology.or...
2021
-
[16]
BAE: BERT-based adversarial examples for text classification,
S. Garg and G. Ramakrishnan, “BAE: BERT-based adversarial examples for text classification,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Online: Association for Computational Linguistics, 2020, pp. 6174–6181. [Online]. Available: https://aclanthology.org/2020.emnlp-main.498/
2020
-
[17]
BERT-ATTACK: Adversarial attack against BERT using BERT,
L. Li, R. Ma, Q. Guo, X. Xue, and X. Qiu, “BERT-ATTACK: Adversarial attack against BERT using BERT,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Online: Association for Computational Linguistics, 2020, pp. 6193–6202. [Online]. Available: https://aclanthology.org/2020. emnlp-main.500/
2020
-
[18]
SemAttack: Natural textual attacks via different semantic spaces,
B. Wang, C. Xu, X. Liu, Y . Cheng, and B. Li, “SemAttack: Natural textual attacks via different semantic spaces,” inFindings of the Association for Computational Linguistics: NAACL 2022. Seattle, United States: Association for Computational Linguistics, 2022, pp. 176–205. [Online]. Available: https://aclanthology.org/2022. findings-naacl.14/ IEEE TRANSACT...
2022
-
[19]
LeapAttack: Hard- label adversarial attack on text via gradient-based optimization,
M. Ye, J. Chen, C. Miao, T. Wang, and F. Ma, “LeapAttack: Hard- label adversarial attack on text via gradient-based optimization,” in Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ACM, 2022, pp. 2307–2315
2022
-
[20]
Contextualized perturbation for textual adversarial attack,
D. Li, Y . Zhang, H. Peng, L. Chen, C. Brockett, M.-T. Sun, and B. Dolan, “Contextualized perturbation for textual adversarial attack,” inProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Online: Association for Computational Linguistics, 2021, pp. 5053–5069. [On...
2021
-
[21]
TextBugger: Generating adversarial text against real-world applications,
J. Li, S. Ji, T. Du, B. Li, and T. Wang, “TextBugger: Generating adversarial text against real-world applications,” in Proceedings of the 26th Annual Network and Distributed System Security Symposium (NDSS). Internet Society, 2019. [Online]. Available: https://www.ndss-symposium.org/ndss-paper/ textbugger-generating-adversarial-text-against-real-world-app...
2019
-
[22]
TextAttack: A framework for adversarial attacks, data augmentation, and adversarial training in NLP,
J. Morris, E. Lifland, J. Y . Yoo, J. Grigsby, D. Jin, and Y . Qi, “TextAttack: A framework for adversarial attacks, data augmentation, and adversarial training in NLP,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Online: Association for Computational Linguistics, 2020, pp. 119–126. [Onl...
2020
-
[23]
Generating natural language attacks in a hard label black box setting,
R. Maheshwary, S. Maheshwary, and V . Pudi, “Generating natural language attacks in a hard label black box setting,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 15, 2021, pp. 13 525–13 533
2021
-
[24]
TextHoaxer: Budgeted hard-label adversarial attacks on text,
M. Ye, C. Miao, T. Wang, and F. Ma, “TextHoaxer: Budgeted hard-label adversarial attacks on text,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 4, 2022, pp. 3877–3884
2022
-
[25]
PAT: Geometry- aware hard-label black-box adversarial attacks on text,
M. Ye, J. Chen, C. Miao, H. Liu, T. Wang, and F. Ma, “PAT: Geometry- aware hard-label black-box adversarial attacks on text,” inProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ACM, 2023, pp. 3093–3104
2023
-
[26]
HQA-Attack: Toward high quality black-box hard-label adversarial attack on text,
H. Liu, Z. Xu, X. Zhang, F. Zhang, F. Ma, H. Chen, H. Yu, and X. Zhang, “HQA-Attack: Toward high quality black-box hard-label adversarial attack on text,” inAdvances in Neural Information Processing Systems, vol. 36, 2023. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2023/hash/ a124b5e7385d35e5c8ad05d192106e19-Abstract-Conference.html
2023
-
[27]
LimeAttack: Local explainable method for textual hard-label adversarial attack,
H. Zhu, Q. Zhao, W. Shang, Y . Wu, and K. Liu, “LimeAttack: Local explainable method for textual hard-label adversarial attack,” inProceed- ings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 17, 2024, pp. 19 759–19 767
2024
-
[28]
Hard label adversarial attack with high query efficiency against NLP models,
S. Qiu, Q. Liu, S. Zhou, M. Gou, Y . Zeng, Z. Zhang, and Z. Wu, “Hard label adversarial attack with high query efficiency against NLP models,” Scientific Reports, vol. 15, p. 9378, 2025
2025
-
[29]
HyGloadAttack: Hard-label black-box textual adversarial attacks via hybrid optimization,
Z. Liu, X. Xiong, Y . Li, Y . Yu, J. Lu, S. Zhang, and F. Xiong, “HyGloadAttack: Hard-label black-box textual adversarial attacks via hybrid optimization,”Neural Networks, vol. 178, p. 106461, 2024
2024
-
[30]
FastTextDodger: Decision-based adversarial attack against black-box NLP models with extremely high efficiency,
X. Hu, G. Liu, B. Zheng, L. Zhao, Q. Wang, Y . Zhang, and M. Du, “FastTextDodger: Decision-based adversarial attack against black-box NLP models with extremely high efficiency,”IEEE Transactions on Information Forensics and Security, vol. 19, pp. 3553–3568, 2024
2024
-
[31]
TextCheater: A query-efficient textual adversarial attack in the hard-label setting,
H. Peng, S. Guo, D. Zhao, X. Zhang, J. Han, S. Ji, X. Yang, and M.- H. Zhong, “TextCheater: A query-efficient textual adversarial attack in the hard-label setting,”IEEE Transactions on Dependable and Secure Computing, vol. 21, no. 4, pp. 3901–3916, 2024
2024
-
[32]
SSPAttack: A simple and sweet paradigm for black- box hard-label textual adversarial attack,
H. Liu, Z. Xu, X. Zhang, X. Xu, F. Zhang, F. Ma, H. Chen, H. Yu, and X. Zhang, “SSPAttack: A simple and sweet paradigm for black- box hard-label textual adversarial attack,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 11, 2023, pp. 13 228– 13 235
2023
-
[33]
Red teaming language models with language models,
E. Perez, S. Huang, F. Song, T. Cai, R. Ring, J. Aslanides, A. Glaese, N. McAleese, and G. Irving, “Red teaming language models with language models,” inProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics, 2022, pp. 3419–
2022
-
[34]
Available: https://aclanthology.org/2022.emnlp-main
[Online]. Available: https://aclanthology.org/2022.emnlp-main. 225/
2022
-
[35]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review arXiv 2023
-
[36]
An LLM can fool itself: A prompt-based adversarial attack,
X. Xu, K. Kong, N. Liu, L. Cui, D. Wang, J. Zhang, and M. Kankanhalli, “An LLM can fool itself: A prompt-based adversarial attack,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=VVgGbB9TNV
2024
-
[37]
Fast adversarial attacks on language models in one GPU minute,
V . S. Sadasivan, S. Saha, G. Sriramanan, P. Kattakinda, A. Chegini, and S. Feizi, “Fast adversarial attacks on language models in one GPU minute,” inProceedings of the 41st International Conference on Machine Learning, 2024
2024
-
[38]
Not what you’ve signed up for: Compromising real-world LLM- integrated applications with indirect prompt injection,
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world LLM- integrated applications with indirect prompt injection,” inProceedings of the 16th ACM Workshop on Artificial Intelligence and Security. ACM, 2023
2023
-
[39]
PoisonedRAG: Knowledge corruption attacks to retrieval-augmented generation of large language models,
W. Zou, R. Geng, B. Wang, and J. Jia, “PoisonedRAG: Knowledge corruption attacks to retrieval-augmented generation of large language models,” in34th USENIX Security Symposium (USENIX Security 25). USENIX Association, 2025, pp. 3827–3844
2025
-
[40]
Phantom: General trigger attacks on retrieval augmented language generation,
H. Chaudhari, G. Severi, J. Abascal, M. Jagielski, C. A. Choquette-Choo, M. Nasr, C. Nita-Rotaru, and A. Oprea, “Phantom: General backdoor attacks on retrieval augmented language generation,”arXiv preprint arXiv:2405.20485, 2024
-
[41]
Trojanrag: Retrieval-augmented generation can be backdoor driver in large language models,
P. Cheng, Y . Ding, T. Ju, Z. Wu, W. Du, P. Yi, Z. Zhang, and G. Liu, “TrojanRAG: Retrieval-augmented generation can be backdoor driver in large language models,”arXiv preprint arXiv:2405.13401, 2024
-
[42]
Fact-Saboteurs: A taxonomy of evidence manipulation attacks against fact-verification systems,
S. Abdelnabi and M. Fritz, “Fact-Saboteurs: A taxonomy of evidence manipulation attacks against fact-verification systems,” in32nd USENIX Security Symposium (USENIX Security 23). Anaheim, CA: USENIX Association, 2023, pp. 6719–6736
2023
-
[43]
Evaluating adversarial attacks against multiple fact verification systems,
J. Thorne, A. Vlachos, C. Christodoulopoulos, and A. Mittal, “Evaluating adversarial attacks against multiple fact verification systems,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong, China: Association for Computational Linguis...
2019
-
[44]
A survey of adversarial defenses and robustness in NLP,
S. Goyal, S. Doddapaneni, M. M. Khapra, and B. Ravindran, “A survey of adversarial defenses and robustness in NLP,”ACM Computing Surveys, vol. 55, no. 14s, pp. 1–39, 2023
2023
-
[45]
SAFER: A structure-free approach for certified robustness to adversarial word substitutions,
M. Ye, C. Gong, and Q. Liu, “SAFER: A structure-free approach for certified robustness to adversarial word substitutions,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Online: Association for Computational Linguistics, 2020, pp. 3465–3475. [Online]. Available: https://aclanthology.org/2020. acl-main.317/
2020
-
[46]
Certified robustness to text adversarial attacks by randomized [MASK],
J. Zeng, J. Xu, X. Zheng, and X. Huang, “Certified robustness to text adversarial attacks by randomized [MASK],”Computational Linguistics, vol. 49, no. 2, pp. 395–427, Jun. 2023. [Online]. Available: https://aclanthology.org/2023.cl-2.5/
2023
-
[47]
Text adversarial purification as defense against adversarial attacks,
L. Li, D. Song, and X. Qiu, “Text adversarial purification as defense against adversarial attacks,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 338–350. [Online]. Available: https://aclanthology.org/2023.acl-long.20/
2023
-
[48]
Don’t retrain, just rewrite: Countering adversarial perturbations by rewriting text,
A. Gupta, C. Blum, T. Choji, Y . Fei, S. Shah, A. Vempala, and V . Srikumar, “Don’t retrain, just rewrite: Countering adversarial perturbations by rewriting text,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Toronto, Canada: Association for Computational Linguistics, Jul. 2023. [Online...
2023
-
[49]
TextGuard: Provable defense against backdoor attacks on text classification,
H. Pei, J. Jia, W. Guo, B. Li, and D. Song, “TextGuard: Provable defense against backdoor attacks on text classification,” inProceedings of the Network and Distributed System Security Symposium (NDSS). Internet Society, 2024. [Online]. Available: https://www.ndss-symposium.org/ndss-paper/ textguard-provable-defense-against-backdoor-attacks-on-text-classification/
2024
-
[50]
Sentence-BERT: Sentence embeddings using Siamese BERT-networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence embeddings using Siamese BERT-networks,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong, China: Association for Computational Linguistics, 2019, pp. 3982–3992. [Online]. Availab...
2019
-
[51]
Sentence transformers,
HuggingFace, “Sentence transformers,” https://huggingface.co/ sentence-transformers, 2023
2023
-
[52]
DeBERTa: Decoding-enhanced BERT with disentangled attention,
P. He, X. Liu, J. Gao, and W. Chen, “DeBERTa: Decoding-enhanced BERT with disentangled attention,” inInternational Conference on Learning Representations, 2021. [Online]. Available: https: //openreview.net/forum?id=XPZIaotutsD IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY 13
2021
-
[53]
Deberta-xlarge-mnli,
HuggingFace, “Deberta-xlarge-mnli,” https://huggingface.co/microsoft/ deberta-xlarge-mnli, 2021
2021
-
[54]
GPT-4o mini: Advancing cost-efficient intelligence,
OpenAI, “GPT-4o mini: Advancing cost-efficient intelligence,” https: //openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/, July 2024
2024
-
[55]
The measurement of observer agreement for categorical data,
J. R. Landis and G. G. Koch, “The measurement of observer agreement for categorical data,”Biometrics, vol. 33, no. 1, pp. 159–174, 1977
1977
-
[56]
Towards reliable misinformation mitigation: Generalization, uncertainty, and GPT-4,
K. Pelrine, A. Imouza, C. Thibault, M. Reksoprodjo, C. Gupta, J. Christoph, J.-F. Godbout, and R. Rabbany, “Towards reliable misinformation mitigation: Generalization, uncertainty, and GPT-4,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 6399...
2023
-
[57]
“Liar, Liar pants on Fire
W. Y . Wang, ““Liar, Liar pants on Fire”: A new benchmark dataset for fake news detection,” inProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Vancouver, Canada: Association for Computational Linguistics, Jul. 2017, pp. 422–426. [Online]. Available: https://aclanthology.org/P17-2067/
2017
-
[58]
A. Yang, B. Yang, B. Hui, B. Zheng, B. Yu, C. Zhou, C. Li, C. Li, D. Liu, F. Huang, G. Dong, H. Wei, H. Lin, J. Tang, J. Wang, J. Yang, J. Tu, J. Zhang, J. Ma, J. Xu, J. Zhou, J. Bai, J. He, J. Lin, K. Dang, K. Lu, K.-Y . Chen, K. Yang, M. Li, M. Xue, N. Ni, P. Zhang, P. Wang, R. Peng, R. Men, R. Gao, R. Lin, S. Wang, S. Bai, S. Tan, T. Zhu, T. Li, T. Liu...
work page internal anchor Pith review arXiv 2024
-
[59]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, Y . Fan, K. Dang, M. Du, X. Ren, R. Men, D. Liu, C. Zhou, J. Zhou, and J. Lin, “Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution,”arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review arXiv 2024
-
[60]
ClaimBuster: The first-ever end-to-end fact-checking system,
N. Hassan, G. Zhang, F. Arslan, J. Caraballo, D. Jimenez, S. Gawsane, S. Hasan, M. Joseph, A. Kulkarni, A. K. Nayak, V . Sable, C. Li, and M. Tremayne, “ClaimBuster: The first-ever end-to-end fact-checking system,”Proceedings of the VLDB Endowment, vol. 10, no. 12, pp. 1945–1948, 2017
1945
-
[61]
ClaimBuster API docu- mentation,
iDIR Lab, University of Texas at Arlington, “ClaimBuster API docu- mentation,” https://idir.uta.edu/claimbuster/, 2017
2017
-
[62]
Sonar models documentation,
Perplexity AI, “Sonar models documentation,” https://docs.perplexity.ai/ getting-started/models/models/sonar, 2025
2025
-
[63]
Introducing PPLX online LLMs,
——, “Introducing PPLX online LLMs,” https://www.perplexity.ai/hub/ blog/introducing-pplx-online-llms, 2024
2024
-
[64]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V . Stoyanov, “RoBERTa: A robustly optimized BERT pretraining approach,”arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review arXiv 1907
-
[65]
RoBERTa-base model card,
Hugging Face, “RoBERTa-base model card,” https://huggingface.co/ roberta-base, 2024
2024
-
[66]
The curious case of neural text degeneration,
A. Holtzman, J. Buys, L. Du, M. Forbes, and Y . Choi, “The curious case of neural text degeneration,” inInternational Conference on Learning Representations, 2020. [Online]. Available: https: //openreview.net/forum?id=rygGQyrFvH
2020
-
[67]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review arXiv 2017
-
[68]
FEVER: a large-scale dataset for fact extraction and VERification,
J. Thorne, A. Vlachos, C. Christodoulopoulos, and A. Mittal, “FEVER: a large-scale dataset for fact extraction and VERification,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). New Orleans, Louisiana: Association for Computational Li...
2018
-
[69]
A VeriTeC: A dataset for real-world claim verification with evidence from the web,
M. Schlichtkrull, Z. Guo, and A. Vlachos, “A VeriTeC: A dataset for real-world claim verification with evidence from the web,” inAdvances in Neural Information Processing Systems, vol. 36, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.