Recognition: unknown
MTRouter: Cost-Aware Multi-Turn LLM Routing with History-Model Joint Embeddings
Pith reviewed 2026-05-08 06:12 UTC · model grok-4.3
The pith
MTRouter selects the right LLM at each turn of a long task by embedding the full history jointly with each candidate model and predicting which choice will yield the best outcome.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
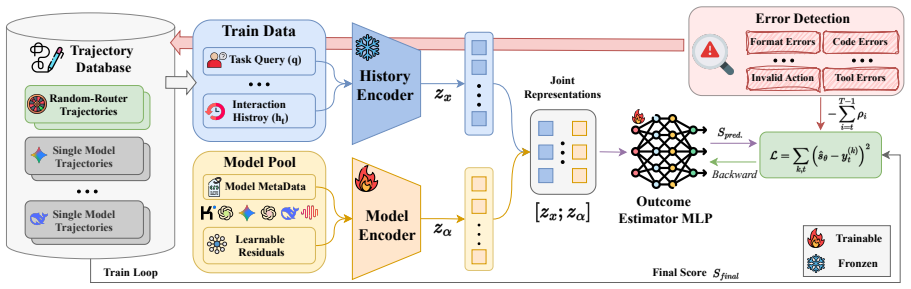
MTRouter encodes the interaction history and each candidate model into joint embeddings and trains an outcome estimator on logged trajectories to predict turn-level model utility; at inference time it repeatedly selects the model that maximizes the predicted utility subject to the remaining budget, producing a better performance-cost frontier than any fixed model.
What carries the argument
Joint history-model embeddings together with a learned outcome estimator that scores expected utility for the current turn.
If this is right
- On ScienceWorld the method surpasses GPT-5 success rate while cutting total inference cost by 58.7 percent.
- On Humanity's Last Exam it reaches competitive accuracy at 43.4 percent lower cost than GPT-5.
- Performance gains transfer to held-out tasks outside the training distribution.
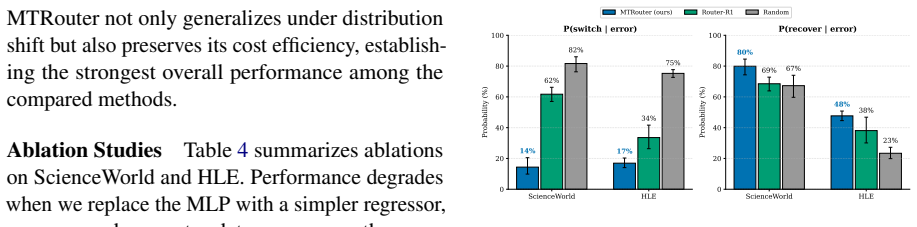
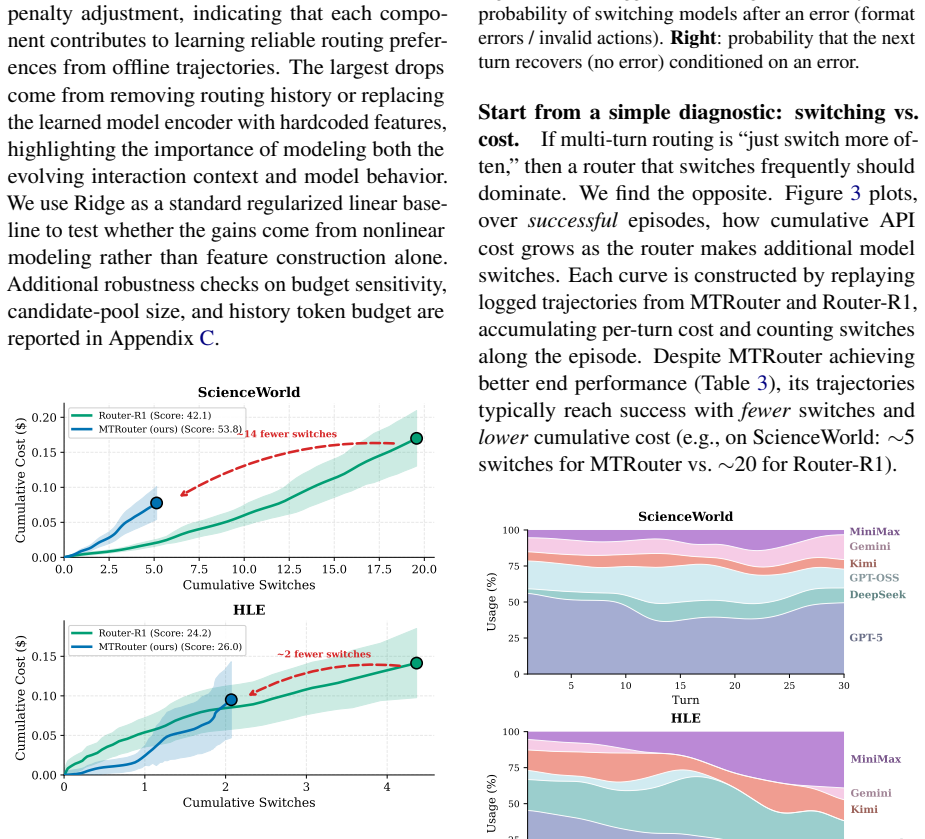
- The router produces fewer model switches and recovers from transient errors more effectively than prior multi-turn routers.
- Different models emerge as specialists for distinct turn types within the same task.
Where Pith is reading between the lines
- If the estimator remains accurate, production agents could replace single-model pipelines with a mixed pool and still meet quality targets at lower average spend.
- The same joint-embedding approach might be tested for routing among open-source models of varying size without requiring new outcome labels.
- One could measure whether the learned specialization persists when the model pool changes after training.
Load-bearing premise
An outcome estimator trained on logged trajectories will accurately predict turn-level model utility and generalize to new multi-turn interactions and held-out tasks.
What would settle it
Deploying the trained router on a new collection of multi-turn tasks drawn from a different distribution and observing that its accuracy-cost curve lies strictly below the curve obtained by always calling GPT-5 would falsify the central claim.
Figures




read the original abstract
Multi-turn, long-horizon tasks are increasingly common for large language models (LLMs), but solving them typically requires many sequential model invocations, accumulating substantial inference costs. Here, we study cost-aware multi-turn LLM routing: selecting which model to invoke at each turn from a model pool, given a fixed cost budget. We propose MTRouter, which encodes the interaction history and candidate models into joint history-model embeddings, and learns an outcome estimator from logged trajectories to predict turn-level model utility. Experiments show that MTRouter improves the performance-cost trade-off: on ScienceWorld, it surpasses GPT-5 while reducing total cost by 58.7%; on Humanity's Last Exam (HLE), it achieves competitive accuracy while reducing total cost by 43.4% relative to GPT-5, and these gains even carry over to held-out tasks. Further analyses reveal several mechanisms underlying its effectiveness: relative to prior multi-turn routers, MTRouter makes fewer model switches, is more tolerant to transient errors, and exhibits emergent specialization across models. Code: https://github.com/ZhangYiqun018/MTRouter
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. MTRouter is proposed for cost-aware multi-turn LLM routing by encoding interaction history and candidate models into joint embeddings and learning an outcome estimator from logged trajectories to predict turn-level model utility. On the ScienceWorld benchmark, it surpasses GPT-5 while reducing total cost by 58.7%; on Humanity's Last Exam (HLE), it achieves competitive accuracy with a 43.4% cost reduction relative to GPT-5. These gains are reported to generalize to held-out tasks. Additional analyses show fewer model switches, greater tolerance to transient errors, and emergent model specialization compared to prior routers.
Significance. Should the reported improvements prove robust under scrutiny, the work would be significant for enabling more efficient use of LLMs in complex, long-horizon applications by balancing performance and inference costs. The provision of code at https://github.com/ZhangYiqun018/MTRouter enhances the potential for follow-up research and reproducibility.
major comments (2)
- [Abstract and §4 Experiments] Abstract and §4 Experiments: The abstract states specific percentage improvements (58.7% cost reduction on ScienceWorld surpassing GPT-5; 43.4% on HLE with competitive accuracy) and generalization to held-out tasks, yet provides no information on experimental controls, statistical significance, baseline details, or data exclusion rules. This absence prevents verification of the central empirical claims.
- [§3.2 (Outcome Estimator)] §3.2 (Outcome Estimator): The estimator is trained on external logged trajectories and evaluated on separate benchmarks. No metrics on estimator calibration, OOD prediction error, or ablation removing held-out data from training are reported, leaving the generalization step to new multi-turn interactions and held-out tasks insufficiently secured; this is load-bearing for the main results.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for highlighting areas where additional detail would strengthen the manuscript. We address each major comment below and commit to revisions that improve clarity and verifiability without altering the core claims or methodology.
read point-by-point responses
-
Referee: [Abstract and §4 Experiments] Abstract and §4 Experiments: The abstract states specific percentage improvements (58.7% cost reduction on ScienceWorld surpassing GPT-5; 43.4% on HLE with competitive accuracy) and generalization to held-out tasks, yet provides no information on experimental controls, statistical significance, baseline details, or data exclusion rules. This absence prevents verification of the central empirical claims.
Authors: We agree that the abstract, as a concise summary, omits granular experimental details. Section 4 of the manuscript already specifies the model pool, baselines (including GPT-5 and prior routers), the use of logged trajectories for training, and held-out task evaluation. To improve verifiability, we will revise the abstract to briefly reference the experimental controls and held-out evaluation protocol. In §4 we will add explicit reporting of statistical significance (e.g., confidence intervals or p-values for the reported cost reductions and accuracy differences), clearer enumeration of data exclusion criteria, and a consolidated table of baseline configurations. These changes will be made in the revised manuscript. revision: yes
-
Referee: [§3.2 (Outcome Estimator)] §3.2 (Outcome Estimator): The estimator is trained on external logged trajectories and evaluated on separate benchmarks. No metrics on estimator calibration, OOD prediction error, or ablation removing held-out data from training are reported, leaving the generalization step to new multi-turn interactions and held-out tasks insufficiently secured; this is load-bearing for the main results.
Authors: We acknowledge that additional diagnostics on the outcome estimator would better support the generalization claims. The current §3.2 describes training on logged trajectories and evaluation on the target benchmarks, with generalization results appearing in the experiments. In revision we will augment §3.2 with (i) calibration metrics such as expected calibration error and Brier score on the utility predictions, (ii) OOD prediction error measured on held-out tasks, and (iii) an ablation that withholds held-out task data from estimator training. These results will be reported alongside the existing generalization experiments to directly address the load-bearing concern. revision: yes
Circularity Check
No circularity: empirical gains on held-out benchmarks are independent of training inputs.
full rationale
The paper trains a history-model joint embedding and outcome estimator on logged trajectories, then evaluates the full MTRouter system on separate benchmarks (ScienceWorld, HLE) including held-out tasks. The reported cost reductions (58.7%, 43.4%) and accuracy claims are measured outcomes of the deployed router, not quantities that reduce by construction to the estimator's fitted parameters or to any self-citation. No equations equate predictions to inputs, no uniqueness theorem is imported from prior author work, and no ansatz is smuggled via citation. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GAIA: a benchmark for General AI Assistants
Gaia: a benchmark for general ai assistants. Preprint, arXiv:2311.12983. MiniMax. 2025. Minimax m2 & agent: Ingenious in simplicity. Official MiniMax release post. Accessed: 2026-04-18. OpenAI, :, Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyl...
work page internal anchor Pith review arXiv 2025
-
[2]
Advances in Neural Information Processing Systems, 37:52040–52094
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37:52040–52094. John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering.Advance...
-
[3]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854. A Dataset and Split Details A.1 ScienceWorld Task Types Table 5 lists the ScienceWorld task types used for training and out-of-distribution evaluation. Split Task Types Train (13) boil, melt, chemistry-mix, find-animal, find-plant, grow-plant, identify-li...
work page internal anchor Pith review arXiv 2025
-
[4]
Analyze the task in<think>...</think>tags
-
[5]
Select the best model using<select>model_name</select> Example <think>This is a simple math question. A cheaper model would suffice.</think> <select>deepseek/deepseek-v3.2</select> Rules • You MUST output exactly one<select>tag • The model name must match exactly from the available list • Consider: task complexity, model strengths, cost-effectiveness LLM ...
-
[6]
Content Scanning for Rationale: Locate thespecific sections/datadirectly related to the user’s goal within the webpage content
-
[7]
Output thefull original contextas much as possible (it can exceed three paragraphs)
Key Extraction for Evidence: Identify and extract themost relevant informationfrom the content; do not miss important information. Output thefull original contextas much as possible (it can exceed three paragraphs)
-
[8]
rational
Summary Output for Summary: Organize into a concise paragraph with logical flow, priori- tizing clarity and judging the contribution of the information to the goal. Output Format: JSON format containing"rational","evidence", and"summary"fields. HLE Judge Prompt Judge whether the following [response] to [question] is correct or not based on the precise and...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.