Recognition: unknown
Green-Red Watermarking for Recommender Systems
Pith reviewed 2026-05-08 05:29 UTC · model grok-4.3
The pith
A secret key partitions items into green and red sets to create a detectable output bias that verifies model ownership without any data injection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GREW partitions the item space with a secret key into green items for promotion and red items as anchors. The watermark is injected through Semantic-Consistent Hashing that clusters green items, Decision-Aligned Masking that restricts changes to competitive subsets, and Confidence-Aware Scaling that adjusts strength by model uncertainty. Ownership is confirmed by keyed re-partitioning followed by hypothesis testing on aggregated black-box outputs.
What carries the argument
The secret-key green-red partition of the item space, which induces a verifiable output bias through three integrated modules that operate inside the ranking process.
If this is right
- Recommender models receive ownership protection without any need to inject synthetic training data.
- Verification requires only black-box access to ranked outputs rather than model internals or training sets.
- The embedded bias remains detectable after common extraction attacks that remove memorization-based watermarks.
- Original recommendation performance stays unchanged because signal injection is confined to competitive item subsets.
Where Pith is reading between the lines
- The same keyed partition idea could be tested on non-recommendation ranking tasks such as search or retrieval systems.
- If natural item popularity already correlates with the green set, detection power may drop and require more queries.
- Long-term fine-tuning on user data could gradually erode the bias, suggesting periodic re-verification schedules.
Load-bearing premise
The statistical hypothesis test on aggregated black-box outputs will reliably distinguish the keyed green-red bias from natural variation even after model extraction or fine-tuning attacks.
What would settle it
Extract a GREW-protected model through black-box queries, then test whether the same key still produces a statistically significant green-red output shift on fresh queries at the claimed detection threshold.
Figures


read the original abstract
The widespread open-sourcing of advanced recommendation algorithms and the rising threat of model extraction attacks have made safeguarding the intellectual property of recommender systems an imperative task. While watermarking serves as a potent defense, existing methods primarily rely on forcing models to memorize pre-defined interaction patterns. Such memorization-based approaches often require excessive synthetic data injection and are vulnerable to removal attacks due to their detectable statistical deviations from natural user behavior. To address these limitations, we propose GREW, a novel Green-REd Watermarking framework for recommender systems. GREW leverages a secret key to partition the item space into "green" items for soft promotion and "red" items as anchors, thereby shifting the paradigm from fragile memorization to a stealthy, key-controlled output bias. By integrating watermark signals directly into the intrinsic ranking process, GREW employs three recommendation-tailored modules: (1) Semantic-Consistent Hashing, which utilizes the secret key to cluster green items for performance-aware stealthiness; (2) Decision-Aligned Masking, which confines signal injection to the competitive item subset to preserve ranking logic; and (3) Confidence-Aware Scaling, which dynamically modulates injection intensity based on model uncertainty. Ownership verification is performed via statistical hypothesis testing on aggregated black-box outputs, enabled by the keyed re-partitioning of the item space. Experiments on multiple base models demonstrate that GREW achieves strong ownership verification and robustness against extraction attacks compared to existing baselines while requiring no data injection. Our code is available at https://github.com/Loche2/GREW.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce GREW, a novel Green-Red Watermarking framework for recommender systems that avoids data injection by using a secret key to partition the item space into green items (softly promoted) and red items (as anchors). This creates a stealthy, key-controlled bias in the ranking outputs through three tailored modules: Semantic-Consistent Hashing, Decision-Aligned Masking, and Confidence-Aware Scaling. Ownership is verified using statistical hypothesis testing on aggregated black-box outputs with keyed re-partitioning. The authors report that experiments on multiple base models show strong ownership verification and robustness against extraction attacks compared to existing baselines.
Significance. If the central claims regarding robustness hold, this work represents a meaningful contribution to recommender system security by shifting from memorization-based watermarking to a performance-preserving output bias. This addresses key limitations of prior methods, such as vulnerability to removal attacks and the need for synthetic data. The public availability of the code is a positive aspect that supports reproducibility. The approach could have practical implications for protecting IP in open-sourced recommendation algorithms.
major comments (1)
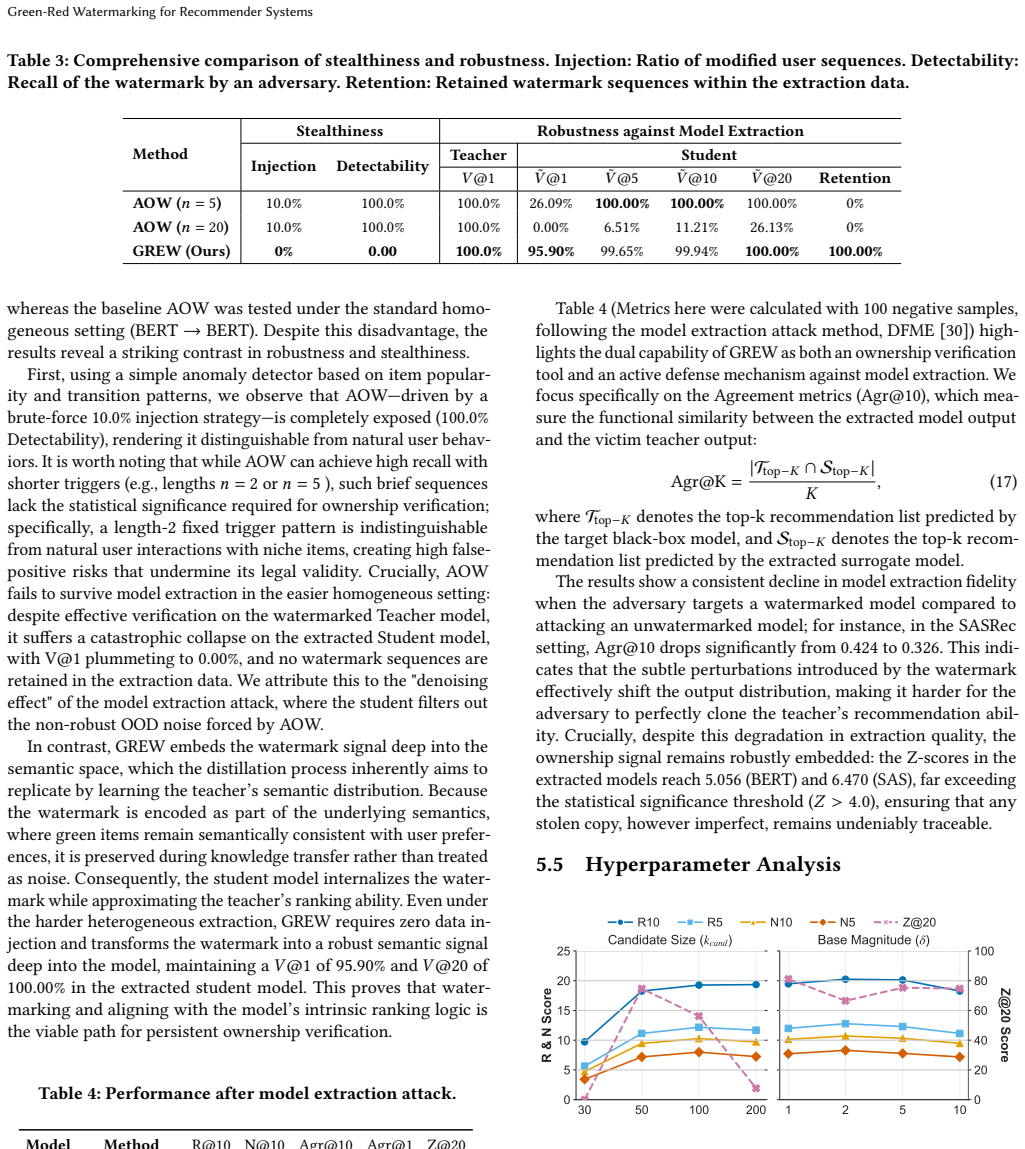
- [Section 3] The statistical hypothesis test for ownership verification lacks a closed-form bound on the required effect size or sample complexity to separate the keyed green-red bias from natural variation in recommender outputs, especially under extraction or fine-tuning attacks. This assumption is central to the robustness claims and requires further analysis or empirical validation with specific metrics.
minor comments (1)
- [Abstract] The abstract asserts 'strong' results without providing any quantitative metrics or details on the experiments, which would help readers assess the claims immediately.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We appreciate the emphasis on strengthening the statistical foundations of our ownership verification procedure. Below we respond to the major comment and outline the revisions we will make to address it.
read point-by-point responses
-
Referee: [Section 3] The statistical hypothesis test for ownership verification lacks a closed-form bound on the required effect size or sample complexity to separate the keyed green-red bias from natural variation in recommender outputs, especially under extraction or fine-tuning attacks. This assumption is central to the robustness claims and requires further analysis or empirical validation with specific metrics.
Authors: We agree that a closed-form bound on effect size and sample complexity would strengthen the theoretical guarantees. Deriving such a bound is non-trivial because recommender outputs are stochastic and depend on unobserved user-item distributions that resist simple parametric assumptions. Nevertheless, the paper already provides substantial empirical validation of the separation. In Section 5 we report verification success rates, p-value distributions, and false-positive rates across three base models and multiple attack settings (model extraction with 30-70% data overlap and fine-tuning for 5-20 epochs). These results show that the keyed green-red bias produces a statistically detectable shift (p < 0.01) with as few as 800 black-box queries, even after attacks. We will revise Section 3 to add (i) an explicit discussion of the observed effect sizes and their stability under attacks, (ii) practical sample-complexity guidelines derived from the empirical curves, and (iii) additional plots of score distributions under the null and alternative hypotheses. This constitutes a partial revision that augments the existing empirical evidence without claiming an unavailable closed-form result. revision: partial
Circularity Check
No significant circularity; derivation relies on independent modules and standard statistical testing.
full rationale
The paper's core chain defines GREW via three explicitly described modules (Semantic-Consistent Hashing, Decision-Aligned Masking, Confidence-Aware Scaling) that apply a keyed green-red partition to induce a soft bias during ranking, followed by ownership verification through ordinary statistical hypothesis testing on aggregated black-box outputs. No equations reduce the claimed detection power to a parameter fitted from the target data itself, no self-citation is invoked as a uniqueness theorem or load-bearing premise, and no ansatz or known result is renamed as a derivation. The approach is self-contained against external benchmarks such as existing watermarking baselines, with the statistical test operating on observable outputs after re-partitioning rather than on any internally fitted quantity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. Bobadilla, F. Ortega, A. Hernando, and A. Gutiérrez. 2013. Recommender systems survey.Knowledge-Based Systems46 (July 2013), 109–132. doi:10.1016/j. knosys.2013.03.012
work page doi:10.1016/j 2013
-
[2]
Jiawei Chen, Hande Dong, Xiang Wang, Fuli Feng, Meng Wang, and Xiangnan He
-
[3]
Bias and Debias in Recommender System: A Survey and Future Directions. ACM Trans. Inf. Syst.41, 3 (Feb. 2023), 67:1–67:39. doi:10.1145/3564284
-
[4]
Ingemar Cox, Matthew Miller, Jeffrey Bloom, and Chris Honsinger. 2002. Digital watermarking.Journal of Electronic Imaging11, 3 (2002), 414–414
2002
-
[5]
Xiaocui Dang, Priyadarsi Nanda, Heng Xu, Haiyu Deng, and Manoranjan Mo- hanty. 2024. Recommendation System Model Ownership Verification via Non- Influential Watermarking. In2024 17th International Conference on Security of Information and Networks (SIN). 1–8. doi:10.1109/SIN63213.2024.10871674
-
[6]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint arXiv:2502.18965 (2025)
work page internal anchor Pith review arXiv 2025
-
[7]
F. Maxwell Harper and Joseph A. Konstan. 2015. The MovieLens Datasets: History and Context.ACM Trans. Interact. Intell. Syst.5, 4 (Dec. 2015), 19:1–19:19. doi:10.1145/2827872
-
[8]
Frank Hartung and Martin Kutter. 2002. Multimedia watermarking techniques. Proc. IEEE87, 7 (2002), 1079–1107
2002
- [9]
-
[10]
William B Johnson, Joram Lindenstrauss, et al . 1984. Extensions of Lipschitz mappings into a Hilbert space.Contemporary mathematics26, 189-206 (1984), 1
1984
-
[11]
Wang-Cheng Kang and Julian McAuley. 2018. Self-Attentive Sequential Rec- ommendation. In2018 IEEE International Conference on Data Mining (ICDM). 197–206. doi:10.1109/ICDM.2018.00035 ISSN: 2374-8486
-
[12]
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. 2023. A Watermark for Large Language Models. InProceedings of the 40th International Conference on Machine Learning. PMLR, 17061–17084. https://proceedings.mlr.press/v202/kirchenbauer23a.html ISSN: 2640-3498
2023
-
[13]
Parikh, Nicolas Papernot, and Mohit Iyyer
Kalpesh Krishna, Gaurav Singh Tomar, Ankur P. Parikh, Nicolas Papernot, and Mohit Iyyer. 2019. Thieves on Sesame Street! Model Extraction of BERT-based APIs. https://openreview.net/forum?id=Byl5NREFDr
2019
-
[14]
Jing Li, Pengjie Ren, Zhumin Chen, Zhaochun Ren, Tao Lian, and Jun Ma. 2017. Neural attentive session-based recommendation. InProceedings of the 2017 ACM on Conference on Information and Knowledge Management. 1419–1428. https: //dl.acm.org/doi/abs/10.1145/3132847.3132926
- [15]
-
[16]
Fu Liu, Hui Zhang, Yuqin Lan, and Min Li. 2025. FewMEA: Few-shot Model Extraction Attack against Sequential Recommenders. InProceedings of the 2025 International Conference on Multimedia Retrieval (ICMR ’25). Association for Com- puting Machinery, New York, NY, USA, 917–925. doi:10.1145/3731715.3733340
-
[17]
Yijian Lu, Aiwei Liu, Dianzhi Yu, Jingjing Li, and Irwin King. 2024. An Entropy- based Text Watermarking Detection Method. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 11724–11735
2024
-
[18]
Minjia Mao, Dongjun Wei, Zeyu Chen, Xiao Fang, and Michael Chau. 2025. Watermarking Large Language Models: An Unbiased and Low-risk Method. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Co...
-
[19]
Alex Martinez, Mihnea Tufis, and Ludovico Boratto. 2024. Unmasking Privacy: A Reproduction and Evaluation Study of Obfuscation-based Perturbation Tech- niques for Collaborative Filtering. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’24). Association for Computing Machinery, New Y...
-
[20]
Jianmo Ni, Jiacheng Li, and Julian McAuley. 2019. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 188–197
2019
-
[21]
Michael-Andrei Panaitescu-Liess, Zora Che, Bang An, Yuancheng Xu, Pankayaraj Pathmanathan, Souradip Chakraborty, Sicheng Zhu, Tom Goldstein, and Furong Huang. 2025. Can Watermarking Large Language Models Prevent Copyrighted Text Generation and Hide Training Data?Proceedings of the AAAI Conference on Artificial Intelligence39, 23 (April 2025), 25002–25009....
-
[22]
Ali Rahimi and Benjamin Recht. 2007. Random features for large-scale kernel machines.Advances in neural information processing systems20 (2007)
2007
-
[23]
Preston K Robinette, Thuy Dung Nguyen, Samuel Sasaki, and Taylor T Johnson
-
[24]
InEuropean Symposium on Research in Computer Security
Trigger-Based Fragile Model Watermarking for Image Transformation Networks. InEuropean Symposium on Research in Computer Security. Springer, 346–365
-
[25]
Zijie Song, Jiawei Chen, Sheng Zhou, Qihao Shi, Yan Feng, Chun Chen, and Can Wang. 2023. CDR: Conservative doubly robust learning for debiased recommen- dation. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 2321–2330
2023
-
[26]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[27]
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Repre- sentations from Transformer. InProceedings of the 28th ACM International Confer- ence on Information and Knowledge Management (CIKM ’19). Association for Com- puting Machinery, New York, NY, USA, 1441–1450. doi:10.1145/3357384.3357895
-
[28]
Yihao Wang, Jiajie Su, Chaochao Chen, Meng Han, Chi Zhang, and Jun Wang
-
[29]
InProceedings of the AAAI Conference on Artificial Intelligence, Vol
Sim4Rec: Data-Free Model Extraction Attack on Sequential Recommen- dation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 12766–12774. https://ojs.aaai.org/index.php/AAAI/article/view/33392 Issue: 12
-
[30]
Zeyu Wang, Yidan Song, Shihao Qin, Yu Shanqing, Yujin Huang, Qi Xuan, and Xin Zheng. 2025. Data-Free Model Extraction for Black-box Recommender Systems via Graph Convolutions. https://openreview.net/forum?id=eS3xJTjSgm
2025
-
[31]
Zhenyi Wang, Yihan Wu, and Heng Huang. 2024. Defense against model ex- traction attack by bayesian active watermarking. InForty-first International Conference on Machine Learning
2024
-
[32]
Zongwei Wang, Junliang Yu, Min Gao, Wei Yuan, Guanhua Ye, Shazia Sadiq, and Hongzhi Yin. 2024. Poisoning Attacks and Defenses in Recommender Systems: A Survey.CoRRabs/2406.01022 (2024). doi:10.48550/ARXIV.2406.01022 arXiv: 2406.01022
-
[33]
Enyue Yang, Weike Pan, Lixin Fan, Hanlin Gu, Zhitao Li, Qiang Yang, and Zhong Ming. 2025. Ownership Verification for Federated Recommendation.ACM Trans. Inf. Syst.43, 3 (March 2025), 69:1–69:27. doi:10.1145/3715320
-
[34]
Zhenrui Yue, Zhankui He, Huimin Zeng, and Julian McAuley. 2021. Black- Box Attacks on Sequential Recommenders via Data-Free Model Extraction. In Proceedings of the 15th ACM Conference on Recommender Systems (RecSys ’21). Association for Computing Machinery, New York, NY, USA, 44–54. doi:10.1145/ 3460231.3474275
-
[35]
Jie Zhang, Dongdong Chen, Jing Liao, Weiming Zhang, Huamin Feng, Gang Hua, and Nenghai Yu. 2021. Deep model intellectual property protection via deep watermarking.IEEE Transactions on Pattern Analysis and Machine Intelligence 44, 8 (2021), 4005–4020
2021
-
[36]
Jialong Zhang, Zhongshu Gu, Jiyong Jang, Hui Wu, Marc Ph Stoecklin, Heqing Huang, and Ian Molloy. 2018. Protecting intellectual property of deep neural networks with watermarking. InProceedings of the 2018 on Asia conference on computer and communications security. 159–172
2018
- [37]
-
[38]
Sixiao Zhang, Cheng Long, Wei Yuan, Hongxu Chen, and Hongzhi Yin. 2024. Wa- termarking Recommender Systems. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM ’24). Association for Computing Machinery, New York, NY, USA, 3217–3226. doi:10.1145/3627673. 3679617
-
[39]
Sixiao Zhang, Cheng Long, Wei Yuan, Hongxu Chen, and Hongzhi Yin. 2025. Data Watermarking for Sequential Recommender Systems. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 (KDD Lei Zhou, Min Gao, Zongwei Wang, Yibing Bai, and Wentao Li ’25). Association for Computing Machinery, New York, NY, USA, 3819–3830. doi...
-
[40]
Bin Zhao, Chuangbai Xiao, Yu Zhang, Peng Zhai, and Zhi Wang. 2019. Assess- ment of recommendation trust for access control in open networks.Cluster Computing22, 1 (Jan. 2019), 565–571. doi:10.1007/s10586-017-1338-x
-
[41]
Kaixiang Zhao, Lincan Li, Kaize Ding, Neil Zhenqiang Gong, Yue Zhao, and Yushun Dong. 2025. A Survey on Model Extraction Attacks and Defenses for Large Language Models. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 (KDD ’25). Association for Computing Machinery, New York, NY, USA, 6227–6236. doi:10.1145/3711896.3736573
-
[42]
Xu Zhao, Ruibo Ma, Jiaqi Chen, Weiqi Zhao, Ping Yang, and Yao Hu. 2025. Multi-Granularity Distribution Modeling for Video Watch Time Prediction via Exponential-Gaussian Mixture Network. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 309–318
2025
-
[43]
Lei Zhou, Min Gao, Zongwei Wang, and Yibing Bai. 2025. Budget and Frequency Controlled Cost-Aware Model Extraction Attack on Sequential Recommenders. InProceedings of the 34th ACM International Conference on Information and Knowledge Management (CIKM ’25). Association for Computing Machinery, New York, NY, USA, 4477–4486. doi:10.1145/3746252.3761032 A Dat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.