CAPSULE: Control-Theoretic Action Perturbations for Safe Uncertainty-Aware Reinforcement Learning
Pith reviewed 2026-05-08 06:28 UTC · model grok-4.3
The pith
Offline learning of a probabilistic control-affine model allows construction of uncertainty-aware control barrier functions that enforce hard safety constraints during reinforcement learning through online action correction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
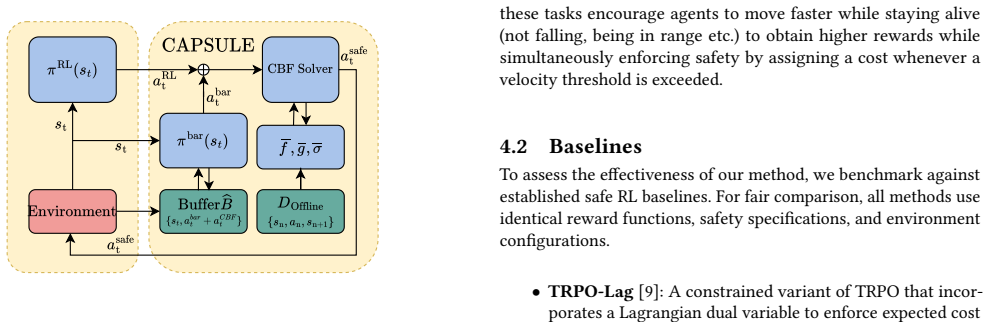
The paper claims that a probabilistic control-affine dynamics model learned offline can be used to construct control barrier functions that incorporate model uncertainty, yielding conservative safety constraints that are enforced by an online constraint-based action correction mechanism, thereby enabling safe reinforcement learning with hard guarantees and without large losses in task performance.
What carries the argument
Control barrier functions constructed from the learned probabilistic control-affine model, which embed uncertainty bounds to produce conservative safety constraints enforced by online action correction.
If this is right
- The method supplies hard, constraint-based safety guarantees rather than safety only in expectation.
- Safe exploration becomes feasible in high-dimensional continuous-control tasks with unknown dynamics.
- Task returns remain comparable to those of existing safe reinforcement learning baselines.
- Empirical safety violations drop substantially on nonlinear benchmarks while performance is preserved.
Where Pith is reading between the lines
- The same offline-to-CBF pipeline could be applied to model-based planning methods outside reinforcement learning.
- If the learned model is periodically updated, the framework might support gradual relaxation of conservatism as uncertainty decreases.
- The online correction step could be combined with other constraint solvers to handle additional state or input limits.
Load-bearing premise
That the probabilistic model learned from offline data is accurate enough to produce control barrier functions whose safety constraints remain valid for the true unknown dynamics.
What would settle it
A recorded safety violation on a test trajectory where the offline data covered the operating region and the model's uncertainty bounds were respected yet the barrier condition was breached.
Figures



read the original abstract
Ensuring safe exploration in high-dimensional systems with unknown dynamics remains a significant challenge. Existing safe reinforcement learning methods often provide safety guarantees only in expectation, which can still lead to safety violations. Control-theoretic approaches, in contrast, offer hard constraint-based safety guarantees but typically assume access to known system dynamics or require accurate estimation of control-affine models. In this paper, we propose a safe reinforcement learning framework that learns a probabilistic control-affine dynamics model in an offline setting. The learned model is leveraged to explicitly construct control barrier functions (CBFs) that incorporate model uncertainty to provide conservative safety constraints. These CBF constraints are enforced through an online constraint-based action correction mechanism, enabling safe exploration without overly restricting task performance. Empirical evaluations on nonlinear, complex continuous-control benchmarks demonstrate that our approach achieves returns comparable to those of existing baselines while significantly reducing safety violations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CAPSULE, a safe RL framework that learns a probabilistic control-affine dynamics model offline from data. This model is used to construct control barrier functions (CBFs) incorporating model uncertainty for conservative safety constraints. These constraints are enforced online via a constraint-based action correction mechanism (likely a QP) to enable safe exploration in high-dimensional continuous control without severely limiting task performance. Empirical results on nonlinear benchmarks are reported to show returns comparable to baselines with significantly fewer safety violations.
Significance. If the uncertainty-aware CBF construction can be shown to yield reliable conservative bounds that preserve forward invariance under the true dynamics, the approach would meaningfully advance the integration of offline model learning with control-theoretic safety in RL. It targets the gap between expectation-based safety methods and hard guarantees, potentially enabling safer deployment in systems with unknown dynamics while avoiding excessive conservatism.
major comments (2)
- [Abstract and §3] Abstract and §3 (method overview): The central claim of 'hard constraint-based safety guarantees' via conservative CBFs is not supported by a formal theorem establishing forward invariance of the safe set under the true (unknown) dynamics. The description relies on posterior bounds or quantiles over the learned p(f,g|D_offline), but without a proof that the true dynamics lie in the uncertainty set along all visited trajectories with high probability, the online QP correction provides only heuristic safety rather than the stated hard guarantees.
- [§4] §4 (CBF construction and uncertainty propagation): The Lie derivative condition for the CBF is made conservative using the probabilistic model, but the specific mechanism (e.g., worst-case over support, quantile bound, or Gaussian process variance) is not shown to be calibrated for the true model error. In high-dimensional continuous control, sparse offline coverage away from the training distribution can cause posterior variance to underestimate error, violating the invariance condition; the paper reports only empirical violation counts, not a calibration test or robustness result for this step.
minor comments (2)
- [§3] Notation for the probabilistic model p(f,g|D) and the resulting CBF h(x) should be introduced with explicit definitions of the uncertainty set used in the Lie derivative bound to improve readability.
- [§5] The experimental section would benefit from reporting the exact form of the action correction QP (including how the CBF constraint is linearized) and ablation on the uncertainty quantile level to clarify sensitivity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our paper. We address each of the major comments in detail below and have updated the manuscript accordingly to improve clarity and precision regarding the safety guarantees.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method overview): The central claim of 'hard constraint-based safety guarantees' via conservative CBFs is not supported by a formal theorem establishing forward invariance of the safe set under the true (unknown) dynamics. The description relies on posterior bounds or quantiles over the learned p(f,g|D_offline), but without a proof that the true dynamics lie in the uncertainty set along all visited trajectories with high probability, the online QP correction provides only heuristic safety rather than the stated hard guarantees.
Authors: We agree with the referee that a formal theorem establishing forward invariance under the true dynamics is absent from the manuscript. The conservative CBF construction uses uncertainty bounds from the learned probabilistic model to enforce constraints via the QP, but this yields safety with respect to the model rather than a rigorous guarantee for the true system without additional assumptions on model coverage. We have revised the abstract and Section 3 to replace 'hard constraint-based safety guarantees' with 'conservative safety constraints that incorporate model uncertainty' and added a paragraph discussing the conditions under which stronger guarantees could hold. These changes clarify the nature of the provided safety without overstating the theoretical results. revision: yes
-
Referee: [§4] §4 (CBF construction and uncertainty propagation): The Lie derivative condition for the CBF is made conservative using the probabilistic model, but the specific mechanism (e.g., worst-case over support, quantile bound, or Gaussian process variance) is not shown to be calibrated for the true model error. In high-dimensional continuous control, sparse offline coverage away from the training distribution can cause posterior variance to underestimate error, violating the invariance condition; the paper reports only empirical violation counts, not a calibration test or robustness result for this step.
Authors: The specific mechanism in our implementation is the use of upper quantile bounds on the posterior distribution of the Lie derivatives to ensure a conservative estimate of the CBF condition. We acknowledge that this may not be perfectly calibrated in all regions, particularly with sparse data in high dimensions, and that posterior variance can underestimate true error. The manuscript relies on empirical evidence of fewer safety violations to support the approach. In the revision, we have expanded Section 4 to explicitly describe the quantile selection process and its rationale for conservatism, along with a brief discussion of potential limitations due to data coverage. A full calibration analysis or robustness test would necessitate new experiments and is noted as future work, but we believe the current empirical results and clarifications address the core concern. revision: partial
Circularity Check
No circularity detected in derivation chain
full rationale
The framework learns a probabilistic control-affine model offline via standard supervised learning, then applies established CBF theory to construct uncertainty-aware barriers and uses a QP for online correction. This chain depends on external results from dynamics learning and control barrier function literature rather than any self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation that reduces the safety claim to the inputs by construction. The derivation remains self-contained against independent benchmarks such as CBF forward-invariance theorems and offline RL methods.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption System dynamics can be represented as a probabilistic control-affine model
Reference graph
Works this paper leans on
-
[1]
Joshua Achiam, David Held, Aviv Tamar, and Pieter Abbeel. 2017. Constrained policy optimization. InInternational conference on machine learning. PMLR, 22– 31
2017
-
[2]
Aaron D Ames, Xiangru Xu, Jessy W Grizzle, and Paulo Tabuada. 2016. Control barrier function based quadratic programs for safety critical systems.IEEE Trans. Automat. Control62, 8 (2016), 3861–3876
2016
-
[3]
Richard Cheng, Gábor Orosz, Richard M Murray, and Joel W Burdick. 2019. End- to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks. InProceedings of the AAAI conference on artificial intelligence, Vol. 33. 3387–3395
2019
-
[4]
Yikun Cheng, Pan Zhao, and Naira Hovakimyan. 2023. Safe and efficient rein- forcement learning using disturbance-observer-based control barrier functions. InLearning for Dynamics and Control Conference. PMLR, 104–115
2023
-
[5]
Kurtland Chua, Roberto Calandra, Rowan McAllister, and Sergey Levine. 2018. Deep reinforcement learning in a handful of trials using probabilistic dynamics models.Advances in neural information processing systems31 (2018)
2018
-
[6]
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. 2018. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning. Pmlr, 1861–1870
2018
-
[7]
Jiaming Ji, Borong Zhang, Jiayi Zhou, Xuehai Pan, Weidong Huang, Ruiyang Sun, Yiran Geng, Yifan Zhong, Josef Dai, and Yaodong Yang. 2023. Safety gymnasium: A unified safe reinforcement learning benchmark.Advances in Neural Information Processing Systems36 (2023), 18964–18993
2023
-
[8]
Zahra Marvi and Bahare Kiumarsi. 2020. Safe off-policy reinforcement learning using barrier functions. In2020 American Control Conference (ACC). IEEE, 2176– 2181
2020
-
[9]
Alex Ray, Joshua Achiam, and Dario Amodei. 2019. Benchmarking safe explo- ration in deep reinforcement learning.arXiv preprint arXiv:1910.017087, 1 (2019), 2
work page internal anchor Pith review arXiv 2019
-
[10]
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz
-
[11]
InInternational conference on machine learning
Trust region policy optimization. InInternational conference on machine learning. PMLR, 1889–1897
-
[12]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[13]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review arXiv 2017
-
[14]
Minjun Sung, Sambhu Harimanas Karumanchi, Aditya Gahlawat, and Naira Hov- akimyan. 2024. Robust Model Based Reinforcement Learning Using 𝐿1 Adaptive Control. InThe Twelfth International Conference on Learning Representations
2024
-
[15]
1998.Reinforcement learning: An intro- duction
Richard S Sutton, Andrew G Barto, et al. 1998.Reinforcement learning: An intro- duction. Vol. 1. MIT press Cambridge
1998
-
[16]
Yixuan Wang, Simon Sinong Zhan, Ruochen Jiao, Zhilu Wang, Wanxin Jin, Zhuo- ran Yang, Zhaoran Wang, Chao Huang, and Qi Zhu. 2023. Enforcing hard constraints with soft barriers: Safe reinforcement learning in unknown stochastic environments. InInternational Conference on Machine Learning. PMLR, 36593– 36604
2023
-
[17]
Tsung-Yen Yang, Justinian Rosca, Karthik Narasimhan, and Peter J Ramadge. 2020. Projection-Based Constrained Policy Optimization. InInternational Conference on Learning Representations
2020
-
[18]
Yujie Yang, Yuxuan Jiang, Yichen Liu, Jianyu Chen, and Shengbo Eben Li. 2023. Model-free safe reinforcement learning through neural barrier certificate.IEEE Robotics and Automation Letters8, 3 (2023), 1295–1302
2023
-
[19]
Baohe Zhang, Yuan Zhang, Lilli Frison, Thomas Brox, and Joschka Bödecker
-
[20]
Constrained reinforcement learning with smoothed log barrier function. arXiv preprint arXiv:2403.14508(2024)
-
[21]
Yiming Zhang, Quan Vuong, and Keith Ross. 2020. First order constrained optimization in policy space.Advances in Neural Information Processing Systems 33 (2020), 15338–15349
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.