Recognition: unknown
PhysCodeBench: Benchmarking Physics-Aware Symbolic Simulation of 3D Scenes via Self-Corrective Multi-Agent Refinement
Pith reviewed 2026-05-08 06:08 UTC · model grok-4.3
The pith
Self-corrective multi-agent framework generates physically accurate 3D scene simulations from language, scoring 67.7 on new benchmark versus 36.3 for prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
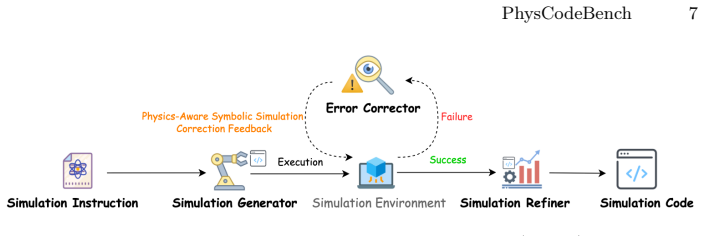
SMRF, consisting of a simulation generator, an error corrector, and a simulation refiner, collaborates iteratively with domain-specific checks to produce code that is both executable and physically faithful; on PhysCodeBench it attains an overall score of 67.7 points against 36.3 for the best evaluated baseline.
What carries the argument
The Self-Corrective Multi-Agent Refinement Framework (SMRF) with its three specialized agents that generate, correct, and refine simulation code through repeated domain-validated iterations.
If this is right
- Error correction is essential for producing physically accurate simulation code.
- Multi-agent collaboration outperforms single-agent generation across mechanics, fluid dynamics, and soft-body domains.
- The benchmark supplies a concrete standard for tracking progress in physics-aware code generation.
- Specialized agents help close the semantic gap between physical descriptions and simulation implementations.
Where Pith is reading between the lines
- Frameworks of this kind could support more reliable instruction-driven simulation in robotics and embodied AI systems.
- Applying the same multi-agent loop to other code-generation tasks that require domain knowledge might yield similar gains.
- Expanding the benchmark to additional physical regimes or real-world sensor data could expose further limits of current methods.
Load-bearing premise
The 700 manually crafted samples together with the automated and visual assessment framework provide an unbiased and complete measure of physical accuracy.
What would settle it
Evaluating SMRF and the baselines on a new collection of physics simulation tasks drawn from outside the original 700 samples and checking whether the performance advantage persists.
Figures




read the original abstract
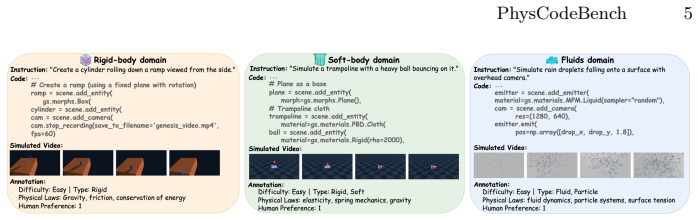
Physics-aware symbolic simulation of 3D scenes is critical for robotics, embodied AI, and scientific computing, requiring models to understand natural language descriptions of physical phenomena and translate them into executable simulation environments. While large language models (LLMs) excel at general code generation, they struggle with the semantic gap between physical descriptions and simulation implementation. We introduce PhysCodeBench, the first comprehensive benchmark for evaluating physics-aware symbolic simulation, comprising 700 manually-crafted diverse samples across mechanics, fluid dynamics, and soft-body physics with expert annotations. Our evaluation framework measures both code executability and physical accuracy through automated and visual assessment. Building on this, we propose a Self-Corrective Multi-Agent Refinement Framework (SMRF) with three specialized agents (simulation generator, error corrector, and simulation refiner) that collaborate iteratively with domain-specific validation to produce physically accurate simulations. SMRF achieves 67.7 points overall performance compared to 36.3 points for the best baseline among evaluated SOTA models, representing a 31.4-point improvement. Our analysis demonstrates that error correction is critical for accurate physics-aware symbolic simulation and that specialized multi-agent approaches significantly outperform single-agent methods across the tested physical domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PhysCodeBench, the first benchmark for physics-aware symbolic simulation of 3D scenes, consisting of 700 manually-crafted expert-annotated samples spanning mechanics, fluid dynamics, and soft-body physics. It proposes the Self-Corrective Multi-Agent Refinement Framework (SMRF) with three specialized agents (simulation generator, error corrector, and simulation refiner) that iteratively collaborate using domain-specific validation to produce executable and physically accurate code. SMRF achieves an overall score of 67.7, outperforming the best evaluated SOTA baseline by 31.4 points, with analysis showing the importance of error correction and multi-agent specialization.
Significance. If the benchmark and metrics prove robust, this work is significant for robotics, embodied AI, and scientific computing by addressing the semantic gap between natural language physical descriptions and executable simulations. The new dataset and combined executability-plus-physical-accuracy evaluation framework provide a valuable standardized testbed, while the empirical demonstration that a multi-agent self-corrective loop yields substantial gains over single-agent baselines offers a practical direction for improving LLM-based simulation generation.
major comments (1)
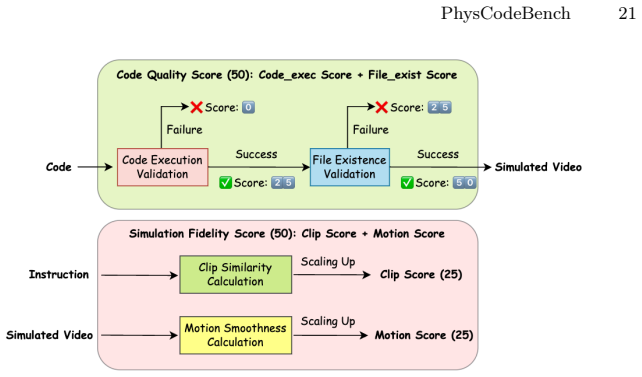
- [Evaluation Framework] The central performance claim (67.7 vs. 36.3) rests on the validity of the physical-accuracy component of the evaluation framework, yet the manuscript provides insufficient detail on the exact criteria, quantification method, and inter-rater reliability for the visual assessment component (mentioned in the abstract and evaluation description). This is load-bearing because without explicit scoring rubrics or examples of pass/fail cases, it is difficult to rule out bias or incomplete coverage of real-world physics phenomena in the 700 samples.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. We address the single major comment below and have revised the manuscript accordingly to strengthen the transparency of our evaluation framework.
read point-by-point responses
-
Referee: [Evaluation Framework] The central performance claim (67.7 vs. 36.3) rests on the validity of the physical-accuracy component of the evaluation framework, yet the manuscript provides insufficient detail on the exact criteria, quantification method, and inter-rater reliability for the visual assessment component (mentioned in the abstract and evaluation description). This is load-bearing because without explicit scoring rubrics or examples of pass/fail cases, it is difficult to rule out bias or incomplete coverage of real-world physics phenomena in the 700 samples.
Authors: We agree that the original manuscript provided insufficient detail on the visual assessment component of physical accuracy, which is central to validating the reported performance gains. In the revised manuscript, we have substantially expanded the Evaluation Framework section (and added an appendix) with: (1) an explicit scoring rubric defining physical-accuracy criteria per domain (e.g., correct Newtonian trajectories and collision responses for mechanics; conservation of mass/momentum and realistic viscosity for fluids; plausible elastic/plastic deformation for soft bodies); (2) the quantification method, in which each sample receives a 0-1 physical-accuracy score via expert visual comparison against the intended physical behavior (combined with automated executability checks); (3) inter-rater reliability computed on a 100-sample subset by two independent domain experts, reported via Cohen's kappa; and (4) concrete pass/fail examples for each physics category. We also discuss how the 700 samples were curated to cover representative phenomena while acknowledging coverage limitations. These additions directly address concerns about bias and reproducibility without altering the core results. revision: yes
Circularity Check
No significant circularity detected
full rationale
This is an empirical benchmark paper introducing PhysCodeBench (700 expert-annotated samples) and the SMRF multi-agent framework. The central claims are performance numbers obtained by running the proposed system and baselines on the new dataset, with no mathematical derivations, equations, fitted parameters, or self-referential definitions. The 31.4-point improvement is a direct empirical outcome rather than a quantity forced by construction from the inputs. No load-bearing self-citations, uniqueness theorems, or ansatzes appear in the provided text that would reduce the result to its own premises.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert annotations and automated/visual assessments correctly evaluate physical accuracy of generated simulations.
Reference graph
Works this paper leans on
-
[1]
Anthropic: Claude 3.5 sonnet (2024),https://www.anthropic.com/news/claude- 3-5-sonnet2, 6, 9, 31
2024
-
[2]
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao
Arenas, M.G., Xiao, T., Singh, S., Jain, V., Ren, A., Vuong, Q., Varley, J., Herzog, A., Leal, I., Kirmani, S., Prats, M., Sadigh, D., Sindhwani, V., Rao, K., Liang, J., Zeng, A.: How to prompt your robot: A promptbook for manipulation skills with code as policies. In: 2024 IEEE International Conference on Robotics and Automa- tion (ICRA). pp. 4340–4348 (...
-
[3]
Program Synthesis with Large Language Models
Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., et al.: Program synthesis with large language models. arXiv preprint arXiv:2108.07732 (2021) 4
work page internal anchor Pith review arXiv 2021
-
[4]
Physion: Evaluating physical prediction from vision in humans and machines
Bear, D.M., Wang, E., Mrowca, D., Binder, F.J., Tung, H.Y.F., Pramod, R., Hold- away, C., Tao, S., Smith, K., Sun, F.Y., et al.: Physion: Evaluating physical predic- tion from vision in humans and machines. arXiv preprint arXiv:2106.08261 (2021) 4
-
[5]
Oxford University Press (2006) 8
Carruthers, P.: The architecture of the mind. Oxford University Press (2006) 8
2006
-
[6]
Evaluating Large Language Models Trained on Code
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H.P.D.O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al.: Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 (2021) 2, 4, 8
work page internal anchor Pith review arXiv 2021
-
[7]
Teaching Large Language Models to Self-Debug
Chen, X., Lin, M., Schärli, N., Zhou, D.: Teaching large language models to self- debug. arXiv preprint arXiv:2304.05128 (2023) 4
work page internal anchor Pith review arXiv 2023
-
[8]
co / deepseek-ai/DeepSeek-R1-Distill-Qwen-32B9
DeepSeek: Deepseek-r1-distill-qwen-32b (2025),https : / / huggingface . co / deepseek-ai/DeepSeek-R1-Distill-Qwen-32B9
2025
-
[9]
google / technology / google-deepmind/google-gemini-ai-update-december-2024/6, 9, 31
Gemini: Introducing gemini 2.0 (2024),https : / / blog . google / technology / google-deepmind/google-gemini-ai-update-december-2024/6, 9, 31
2024
-
[10]
Github: Github copilot (2025),https://github.com/features/copilot6, 31
2025
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025) 4, 9 PhysCodeBench 33
work page internal anchor Pith review arXiv 2025
-
[12]
Hessel, J., Holtzman, A., Forbes, M., Bras, R.L., Choi, Y.: Clipscore: A reference- freeevaluationmetricforimagecaptioning.arXivpreprintarXiv:2104.08718(2021) 9, 12, 22
work page internal anchor Pith review arXiv 2021
-
[13]
Huang, W., Wang, C., Zhang, R., Li, Y., Wu, J., Fei-Fei, L.: Voxposer: Composable 3d value maps for robotic manipulation with language models (2023),https:// arxiv.org/abs/2307.059734
work page internal anchor Pith review arXiv 2023
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video gener- ative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024) 9, 22
2024
-
[15]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024) 2, 6, 9, 31
work page internal anchor Pith review arXiv 2024
-
[16]
arXiv preprint arXiv:2310.08992 (2023) 4
Le, H., Chen, H., Saha, A., Gokul, A., Sahoo, D., Joty, S.: Codechain: Towards modular code generation through chain of self-revisions with representative sub- modules. arXiv preprint arXiv:2310.08992 (2023) 4
-
[17]
arXiv preprint arXiv:2210.05359 (2022) 4
Liu, R., Wei, J., Gu, S.S., Wu, T.Y., Vosoughi, S., Cui, C., Zhou, D., Dai, A.M.: Mind’s eye: Grounded language model reasoning through simulation. arXiv preprint arXiv:2210.05359 (2022) 4
-
[18]
In: 2025 20th ACM/IEEE International Conference on Human-Robot Interaction (HRI)
Liu, S.L.: Personalized caring: Integrating eeg/visual analysis with chatgpt for mci assistance. In: 2025 20th ACM/IEEE International Conference on Human-Robot Interaction (HRI). pp. 1463–1467 (2025).https://doi.org/10.1109/HRI61500. 2025.109738264
- [19]
-
[20]
Advances in neural information processing sys- tems35, 27730–27744 (2022) 4
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. Advances in neural information processing sys- tems35, 27730–27744 (2022) 4
2022
-
[21]
ChatDev: Communicative Agents for Software Development
Qian, C., Liu, W., Liu, H., Chen, N., Dang, Y., Li, J., Yang, C., Chen, W., Su, Y., Cong, X., et al.: Chatdev: Communicative agents for software development. arXiv preprint arXiv:2307.07924 (2023) 4
work page internal anchor Pith review arXiv 2023
-
[22]
Phybench: Holistic evaluation of physical perception and reasoning in large language models
Qiu, S., Guo, S., Song, Z.Y., Sun, Y., Cai, Z., Wei, J., Luo, T., Yin, Y., Zhang, H., Hu, Y., et al.: Phybench: Holistic evaluation of physical perception and reasoning in large language models. arXiv preprint arXiv:2504.16074 (2025) 4
-
[23]
Advances in Neural Information Processing Systems36, 53728–53741 (2023) 4, 8, 9
Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S., Finn, C.: Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems36, 53728–53741 (2023) 4, 8, 9
2023
-
[24]
Robbins, P.: Modularity of mind (2009) 8
2009
-
[25]
Code Llama: Open Foundation Models for Code
Roziere, B., Gehring, J., Gloeckle, F., Sootla, S., Gat, I., Tan, X.E., Adi, Y., Liu, J., Sauvestre, R., Remez, T., et al.: Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950 (2023) 2, 4
work page internal anchor Pith review arXiv 2023
-
[26]
Advances in Neural Information Processing Systems35, 1596–1611 (2022) 4
Takamoto, M., Praditia, T., Leiteritz, R., MacKinlay, D., Alesiani, F., Pflüger, D., Niepert, M.: Pdebench: An extensive benchmark for scientific machine learning. Advances in Neural Information Processing Systems35, 1596–1611 (2022) 4
2022
-
[27]
Team, Q.: Qwq-32b: Embracing the power of reinforcement learning (2025),https: //qwenlm.github.io/blog/qwq-32b/9
2025
-
[28]
In: 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems
Todorov, E., Erez, T., Tassa, Y.: Mujoco: A physics engine for model-based control. In: 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. pp. 5026–5033 (2012).https://doi.org/10.1109/IROS.2012.63861094 34 T. Xie et al
-
[29]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Wu, Q., Bansal, G., Zhang, J., Wu, Y., Li, B., Zhu, E., Jiang, L., Zhang, X., Zhang, S., Liu, J., et al.: Autogen: Enabling next-gen llm applications via multi- agent conversation. arXiv preprint arXiv:2308.08155 (2023) 4
work page internal anchor Pith review arXiv 2023
-
[30]
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., et al.: Qwen2. 5 technical report. arXiv preprint arXiv:2412.15115 (2024) 4, 9
work page internal anchor Pith review arXiv 2024
-
[31]
Clevrer: Collision events for video representation and reasoning
Yi, K., Gan, C., Li, Y., Kohli, P., Wu, J., Torralba, A., Tenenbaum, J.B.: Clevrer: Collision events for video representation and reasoning. arXiv preprint arXiv:1910.01442 (2019) 4
-
[32]
In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C
Zhou, Y., Simon, M., Peng, Z., Mo, S., Zhu, H., Guo, M., Zhou, B.: Simgen: Simulator-conditioned driving scene generation. In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C. (eds.) Advances in Neu- ral Information Processing Systems. vol. 37, pp. 48838–48874. Curran Associates, Inc. (2024),https://proceedings.neurips....
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.