Recognition: unknown
AgentEval: DAG-Structured Step-Level Evaluation for Agentic Workflows with Error Propagation Tracking
Pith reviewed 2026-05-08 05:51 UTC · model grok-4.3
The pith
Modeling agent executions as DAGs with dependency tracking doubles failure detection recall over end-to-end checks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
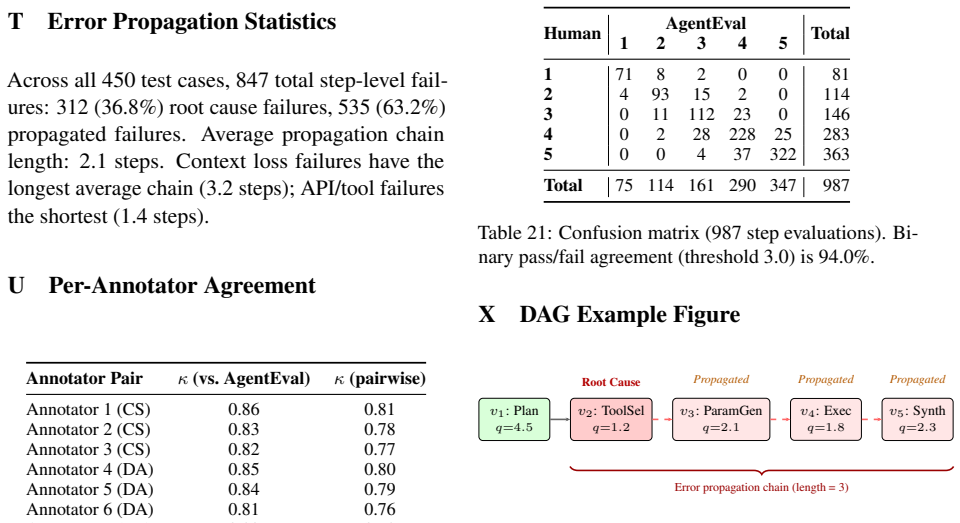
AgentEval formalizes agent executions as evaluation directed acyclic graphs where each node carries typed quality metrics assessed by a calibrated GPT-4o judge, classified through a hierarchical failure taxonomy of three levels and 21 subcategories, and linked to upstream dependencies so that observed failures can be attributed to originating steps through automated propagation tracking.
What carries the argument
The evaluation DAG in which nodes hold failure classifications and edges represent dependencies that enable automated upstream root-cause attribution.
If this is right
- Failure detection recall rises from 0.41 to 0.89 compared with end-to-end evaluation.
- Root cause accuracy reaches 72 percent against an 81 percent human ceiling.
- The same taxonomy and rubrics transfer to tau-bench and SWE-bench traces at recall of at least 0.78.
- CI/CD integration reduces median root-cause identification time from 4.2 hours to 22 minutes.
Where Pith is reading between the lines
- The same dependency-tracing approach could be applied to other multi-step AI pipelines such as automated data pipelines or planning systems.
- Adding a lightweight human override loop on ambiguous nodes might close more of the remaining gap to human-level root-cause accuracy.
- If new failure modes appear that fall outside the current 21 categories, the fixed taxonomy would require extension to maintain performance.
Load-bearing premise
A single fixed LLM judge and unchanging failure taxonomy produce consistent, unbiased assessments across agent architectures and domains.
What would settle it
Re-running the ablation study on a new set of workflows and finding that the DAG structure adds no measurable gain in recall or root-cause accuracy over identical flat step evaluation would falsify the central claim.
Figures


read the original abstract
Agentic systems that chain reasoning, tool use, and synthesis into multi-step workflows are entering production, yet prevailing evaluation practices like end-to-end outcome checks and ad-hoc trace inspection systematically mask the intermediate failures that dominate real-world error budgets. We present AgentEval, a framework that formalizes agent executions as evaluation directed acyclic graphs (DAGs), where each node carries typed quality metrics assessed by a calibrated LLM judge (GPT-4o), classified through a hierarchical failure taxonomy (3 levels, 21 subcategories), and linked to upstream dependencies for automated root cause attribution. An ablation study isolates the impact of DAG-based dependency modeling: it alone contributes +22 percentage points to failure detection recall and +34 pp to root cause accuracy over flat step-level evaluation with identical judges and rubrics. Across three production workflows (450 test cases, two agent model families, predominantly sequential architectures with a 12% non-DAG trace rate), AgentEval achieves 2.17x higher failure detection recall than end-to-end evaluation (0.89 vs. 0.41), Cohen's kappa = 0.84 agreement with human experts, and 72% root cause accuracy against an 81% human ceiling. Cross-system evaluation on tau-bench and SWE-bench traces confirms transferability (failure detection recall >= 0.78) without taxonomy or rubric modification. A 4-month pilot with 18 engineers detected 23 pre-release regressions through CI/CD-integrated regression testing, reducing median root-cause identification time from 4.2 hours to 22 minutes and driving measurable failure rate reductions in two workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentEval, a framework that represents agent executions as evaluation DAGs. Each node is assessed by a calibrated GPT-4o LLM judge using a fixed 3-level, 21-subcategory hierarchical failure taxonomy, with upstream dependency links enabling automated root-cause attribution. An ablation isolates the DAG component as contributing +22 pp to failure-detection recall and +34 pp to root-cause accuracy over flat step-level evaluation. On 450 test cases from three production workflows (predominantly sequential, 12% non-DAG traces), the method reports 0.89 recall (2.17× end-to-end), Cohen’s κ=0.84 with humans, and 72% root-cause accuracy (human ceiling 81%). Cross-benchmark results on tau-bench and SWE-bench show recall ≥0.78 without taxonomy changes, and a four-month pilot with 18 engineers demonstrates reduced debugging time and pre-release regression detection.
Significance. If the central claims hold, the work offers a concrete, deployable advance over end-to-end and ad-hoc trace inspection by supplying structured, dependency-aware failure analysis. The production pilot with quantified time savings (4.2 h → 22 min) and regression detection, together with the empirical ablation and cross-benchmark transfer, constitute genuine strengths that could influence evaluation practices for agentic systems.
major comments (4)
- [Abstract] Abstract: The ablation attributes +22 pp recall and +34 pp root-cause accuracy gains solely to DAG dependency modeling, yet both the DAG and flat conditions employ the identical GPT-4o judge and rubrics. Without reported analysis of judge bias or variance specifically on dependency attribution, the measured DAG benefit cannot be isolated from judge-specific behavior.
- [Abstract / Evaluation Setup] Abstract / Evaluation Setup: No protocol is supplied for calibrating the GPT-4o judge, constructing or validating the 21-subcategory taxonomy, or measuring inter-annotator reliability and per-category agreement. These omissions directly affect the claim that the judge transfers across workflows and benchmarks without retuning.
- [Results on Production Workflows] Results on Production Workflows: Only a single Cohen’s κ=0.84 is reported for human agreement on failure detection. No corresponding statistics are given for root-cause attribution accuracy or per-category reliability, leaving the 72% root-cause accuracy figure without supporting evidence of consistency.
- [Cross-benchmark Evaluation] Cross-benchmark Evaluation: Transfer to tau-bench and SWE-bench is asserted with recall ≥0.78 and no taxonomy modification, but the manuscript supplies no details on the number of traces, how DAG structures were instantiated for those benchmarks, or differences in agent architectures that might affect generalizability.
minor comments (2)
- [Abstract] The 12% non-DAG trace rate is stated but its quantitative impact on the overall metrics and on the reported DAG benefit is not analyzed.
- Clarify whether the production workflows and benchmark traces were evaluated with the same judge prompt template and temperature settings, and report any sensitivity analysis.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each of the major comments point by point below, indicating the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The ablation attributes +22 pp recall and +34 pp root-cause accuracy gains solely to DAG dependency modeling, yet both the DAG and flat conditions employ the identical GPT-4o judge and rubrics. Without reported analysis of judge bias or variance specifically on dependency attribution, the measured DAG benefit cannot be isolated from judge-specific behavior.
Authors: The ablation is designed to isolate the effect of dependency modeling by comparing two conditions that use the exact same GPT-4o judge, prompts, and rubrics: one with flat step-level evaluation and one with DAG-structured evaluation that incorporates dependency links. The performance gains are therefore attributable to the use of the DAG structure for error propagation tracking. To further address concerns about judge-specific behavior on dependency attribution, we will include an additional analysis of judge variance, such as consistency checks across multiple runs on attribution tasks. revision: yes
-
Referee: [Abstract / Evaluation Setup] Abstract / Evaluation Setup: No protocol is supplied for calibrating the GPT-4o judge, constructing or validating the 21-subcategory taxonomy, or measuring inter-annotator reliability and per-category agreement. These omissions directly affect the claim that the judge transfers across workflows and benchmarks without retuning.
Authors: We will revise the manuscript to include a detailed protocol for judge calibration, which involved iterative refinement against human annotations on a development set. The 21-subcategory taxonomy was constructed based on a review of failure modes observed in prior agent evaluations and validated through expert consensus. Inter-annotator reliability was measured via Cohen's kappa on a subset of traces, and we will report per-category agreement statistics to support the transferability claims. revision: yes
-
Referee: [Results on Production Workflows] Results on Production Workflows: Only a single Cohen’s κ=0.84 is reported for human agreement on failure detection. No corresponding statistics are given for root-cause attribution accuracy or per-category reliability, leaving the 72% root-cause accuracy figure without supporting evidence of consistency.
Authors: The Cohen's κ=0.84 reflects agreement on the binary failure detection task. The 72% root-cause accuracy is computed by comparing AgentEval outputs to human expert root-cause labels on the production traces. We will add Cohen's kappa for the root-cause attribution task and per-category reliability metrics in the revised version to provide fuller evidence of consistency. revision: yes
-
Referee: [Cross-benchmark Evaluation] Cross-benchmark Evaluation: Transfer to tau-bench and SWE-bench is asserted with recall ≥0.78 and no taxonomy modification, but the manuscript supplies no details on the number of traces, how DAG structures were instantiated for those benchmarks, or differences in agent architectures that might affect generalizability.
Authors: We will expand the cross-benchmark section with specifics on the number of traces processed from tau-bench and SWE-bench, the procedure used to construct DAGs from their execution traces (e.g., inferring dependencies from tool calls and state transitions), and a discussion of how variations in agent architectures across benchmarks may influence results, thereby clarifying the generalizability. revision: yes
Circularity Check
No significant circularity; empirical comparisons only
full rationale
The paper presents an empirical evaluation framework whose headline results (ablation gains of +22pp recall and +34pp root-cause accuracy, 2.17x improvement over end-to-end, transfer to tau-bench/SWE-bench) are produced by direct side-by-side measurements against baselines that employ identical LLM judges, rubrics, and the same 3-level/21-subcategory taxonomy. No equations, fitted parameters, or first-principles derivations are present that reduce by construction to the target quantities; the DAG dependency modeling is an explicit structural input whose incremental effect is measured rather than assumed. Self-citation is absent from the load-bearing claims, and the single reported Cohen's kappa is an external human agreement statistic rather than a self-referential fit. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- LLM judge calibration settings
axioms (2)
- domain assumption Agent executions can be faithfully represented as DAGs whose nodes carry independent quality metrics
- domain assumption The 3-level 21-subcategory failure taxonomy comprehensively captures relevant error modes across agentic workflows
invented entities (2)
-
Evaluation DAG with upstream dependency links
no independent evidence
-
Hierarchical failure taxonomy (3 levels, 21 subcategories)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Why Do Multi-Agent LLM Systems Fail?
On the accuracy of spectrum-based fault local- ization. InTesting: Academic and Industrial Confer- ence Practice and Research Techniques - MUTATION (TAICPART-MUTATION 2007), page 89–98. IEEE. AgentOps, Inc. 2024. AgentOps: Observability and DevTool platform for AI agents. https://gith ub.com/AgentOps-AI/agentops. AI Security Institute, UK. 2024. Inspect a...
work page internal anchor Pith review arXiv 2007
-
[2]
InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024
Let’s verify step by step. InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. Open- Review.net. Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Ao- han Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tia...
2024
-
[3]
In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024
Agentbench: Evaluating llms as agents. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-eval: NLG evaluation using gpt-4 with better human align- ment. InProceedings of the 2023 Conference on...
2024
-
[4]
Solving math word problems with process- and outcome-based feedback
Solving math word problems with process- and outcome-based feedback.arXiv preprint, arXiv.2211.14275. Weights & Biases. 2024. W&B Weave: A toolkit for developing AI-powered applications. https://gi thub.com/wandb/weave. Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. 2023. Auto-...
work page internal anchor Pith review arXiv 2024
-
[5]
Where llm agents fail and how they can learn from failures,
OpenReview.net. Kunlun Zhu, Zijia Liu, Bingxuan Li, Muxin Tian, Yingx- uan Yang, Jiaxun Zhang, Pengrui Han, Qipeng Xie, Fuyang Cui, Weijia Zhang, Xiaoteng Ma, Xiaodong Yu, Gowtham Ramesh, Jialian Wu, Zicheng Liu, Pan Lu, James Zou, and Jiaxuan You. 2025. Where LLM agents fail and how they can learn from failures. arXiv preprint, arXiv.2509.25370. A Non-DA...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.