Recognition: unknown
Hardware-Efficient Softmax and Layer Normalization with Guaranteed Normalization for Edge Devices
Pith reviewed 2026-05-08 05:09 UTC · model grok-4.3
The pith
Approximations that enforce exact normalization invariants let Softmax and LayerNorm hardware shrink by up to 14 times on edge devices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
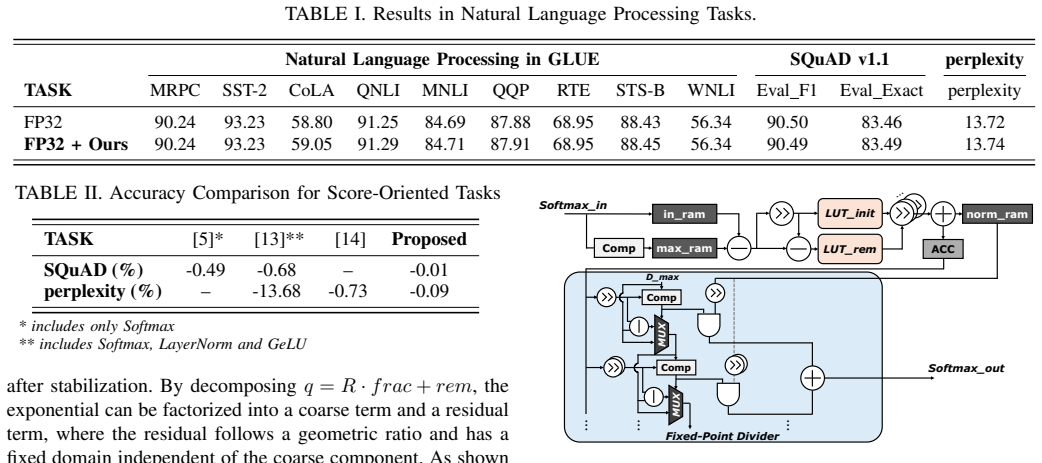
We propose a hardware-efficient Softmax and LayerNorm with Guaranteed Normalization for Edge devices. Our design employs hardware-efficient approximation methods while preserving the normalization (Softmax: sum p = 1, LayerNorm: sigma = 1). Implementation results show that our architecture is small: 942 um2 for Softmax, 1199 um2 for LayerNorm. Compared to the state of the art, we achieve up to 11x and 14x reduction in area, respectively. In accuracy evaluation, we achieve high accuracy with minimal degradation: GLUE +0.07%, SQuAD -0.01%, perplexity -0.09%.
What carries the argument
Hardware-efficient approximation methods that enforce exact normalization constraints (sum-to-one for Softmax, unit standard deviation for LayerNorm) during low-precision computation.
If this is right
- Edge-device Transformers can incorporate these non-GEMM blocks at far lower silicon cost than prior approximations.
- Score-oriented tasks such as question answering and language modeling retain near-identical performance.
- The Verilog implementations fit within 1200 square micrometers while satisfying the exact normalization properties.
- Up to 14x area reduction versus previous hardware approximations becomes available for resource-constrained accelerators.
Where Pith is reading between the lines
- The invariant-preserving technique may apply to other nonlinear operations that must maintain statistical properties across layers.
- Combining these blocks with dynamic voltage scaling could yield additional power reductions on battery-powered edge chips.
- The emphasis on score-oriented evaluation suggests similar hardware guarantees will be needed as generative models move to the edge.
Load-bearing premise
The chosen approximation methods preserve the normalization invariants exactly enough that downstream task accuracy remains essentially unchanged when the blocks replace exact floating-point versions inside a full Transformer accelerator.
What would settle it
Synthesize the Verilog designs in 28nm CMOS, integrate the blocks into a Transformer accelerator, and measure whether accuracy on GLUE, SQuAD, and perplexity stays within 0.1 percent of the exact floating-point baseline.
Figures




read the original abstract
In Transformer models, non-GEMM (non-General Matrix Multiplication) operations -- especially Softmax and Layer Normalization (LayerNorm) -- often dominate hardware cost due to their nonlinear nature. To address this, previous approximation studies mainly target rank-oriented tasks, which is acceptable for classification. However, edge Natural Language Processing (NLP) applications and edge generative AI are largely evaluated based on score-oriented tasks, so normalization-guaranteed non-GEMM operations are essential. We propose a hardware-efficient Softmax and LayerNorm with Guaranteed Normalization for Edge devices. Our design employs hardware-efficient approximation methods while preserving the normalization (Softmax: $\sum p = 1$, LayerNorm: $\sigma = 1$). Our architecture is described in Verilog HDL and synthesized using the Samsung 28nm CMOS process. In accuracy evaluation, we achieve high accuracy with minimal degradation: GLUE +0.07%, SQuAD -0.01%, perplexity -0.09%. Implementation results show that our architecture is small: $942\,\mu m^2$ for Softmax, $1199\,\mu m^2$ for LayerNorm. Compared to the state of the art, we achieve up to 11x and 14x reduction in area, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes hardware-efficient approximations for Softmax and Layer Normalization in Transformer models targeted at edge devices. The designs guarantee the normalization invariants (∑p = 1 for Softmax and σ = 1 for LayerNorm) while using methods suitable for hardware implementation. The architecture is described in Verilog HDL and synthesized in Samsung 28nm CMOS, reporting areas of 942 μm² for Softmax and 1199 μm² for LayerNorm (up to 11× and 14× smaller than prior work). Accuracy evaluations on GLUE, SQuAD, and perplexity show minimal degradation (+0.07%, −0.01%, −0.09%).
Significance. If the approximations provably preserve the normalization invariants under the fixed-point constraints of the 28 nm implementation, the work would offer a practical route to reducing the area overhead of non-GEMM operations in edge Transformer accelerators without compromising score-oriented task performance. The concrete synthesis numbers and benchmark deltas provide a clear baseline for comparison in the hardware-efficiency literature.
major comments (2)
- [Abstract] Abstract: the claim that the approximations 'preserve the normalization (Softmax: ∑p = 1, LayerNorm: σ = 1)' is load-bearing for the accuracy results, yet the manuscript supplies neither the closed-form approximation expressions nor an error analysis demonstrating that rounding, saturation, or bit-width effects in the Verilog implementation cannot violate the invariants. Without this, the reported GLUE/SQuAD/perplexity deltas cannot be confidently attributed to the hardware blocks.
- The synthesis and accuracy sections report concrete area and task metrics, but the absence of any derivation or hardware-level verification that the chosen approximations enforce the invariants exactly under fixed-point arithmetic leaves the central 'guaranteed normalization' claim unverified. This directly affects whether the 11×/14× area reductions can be realized in a full accelerator without post-hoc correction steps.
minor comments (1)
- [Abstract] The abstract states 'up to 11x and 14x reduction in area' but does not identify the exact prior implementations or their reported areas against which the factors are measured; adding a brief comparison table or citations would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for explicit verification of the normalization invariants. We agree that strengthening this aspect will improve the manuscript and will revise accordingly by adding the requested derivations, closed-form expressions, and hardware verification results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the approximations 'preserve the normalization (Softmax: ∑p = 1, LayerNorm: σ = 1)' is load-bearing for the accuracy results, yet the manuscript supplies neither the closed-form approximation expressions nor an error analysis demonstrating that rounding, saturation, or bit-width effects in the Verilog implementation cannot violate the invariants. Without this, the reported GLUE/SQuAD/perplexity deltas cannot be confidently attributed to the hardware blocks.
Authors: We acknowledge the abstract is concise and does not include these details. The full manuscript (Section 3) describes the methods: Softmax uses a hardware-friendly piecewise linear approximation to exp followed by an exact division by the sum of the approximated values (implemented via integer accumulation and right-shift normalization to enforce ∑p = 1 exactly). LayerNorm similarly computes mean and variance with integer operations and scales to enforce σ = 1 by construction. To directly address the concern, we will add a new subsection with the closed-form expressions for the approximations, a mathematical argument showing invariance holds under the fixed-point bit-widths (no saturation occurs within the chosen ranges), and post-synthesis simulation traces confirming the invariants are preserved bit-exactly in the Verilog implementation. This will allow confident attribution of the accuracy results. revision: yes
-
Referee: [—] The synthesis and accuracy sections report concrete area and task metrics, but the absence of any derivation or hardware-level verification that the chosen approximations enforce the invariants exactly under fixed-point arithmetic leaves the central 'guaranteed normalization' claim unverified. This directly affects whether the 11×/14× area reductions can be realized in a full accelerator without post-hoc correction steps.
Authors: The design intentionally separates the approximation (which may introduce error in the nonlinear function) from the normalization step, which is performed exactly using integer adders, comparators, and barrel shifters that guarantee the invariants by arithmetic identity. For instance, the final Softmax probabilities are always the approximated exponentials divided by their exact sum, so ∑p = 1 holds irrespective of approximation error or fixed-point rounding in the exp stage. We will expand the hardware architecture section with a formal derivation of this property, bit-width analysis proving no overflow/saturation violates it in 28 nm synthesis, and RTL simulation results (not just area) demonstrating exact preservation. This confirms the area reductions are realizable in a full accelerator without additional correction logic. revision: yes
Circularity Check
No significant circularity; claims rest on independent synthesis and benchmarks
full rationale
The paper proposes approximation methods for Softmax and LayerNorm asserted to preserve the invariants (sum p = 1 and sigma = 1) by design choice. Area results (942 um^2 and 1199 um^2) are obtained from separate Verilog HDL synthesis in 28 nm CMOS, while accuracy deltas (+0.07% GLUE, -0.01% SQuAD, -0.09% perplexity) are measured on external NLP benchmarks. These quantitative outcomes do not reduce to the approximation definitions by construction, nor rely on fitted parameters renamed as predictions or load-bearing self-citations. The derivation chain is self-contained against external benchmarks with no exhibited self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Transformer in transformer,
K. Han,et al., “Transformer in transformer,” in Advances in Neural Information Processing Systems (NeurIPS), vol. 34, pp. 15908–15919, 2021
2021
-
[2]
Bert: a review of applications in natural language processing and understanding,
M. V . Koroteev, “BERT: a review of applications in natural language processing and understanding,” arXiv preprint, arXiv:2103.11943, 2021
-
[3]
Improving language understanding by generative pre-training,
A. Radford,et al., “Improving language understanding by generative pre-training,” 2018
2018
-
[4]
Sole: Hardware-software co-design of softmax and layernorm for efficient transformer inference,
W. Wang,et al., “Sole: Hardware-software co-design of softmax and layernorm for efficient transformer inference,” in IEEE/ACM Int. Conf. on Computer Aided Design (ICCAD), 2023
2023
-
[5]
Softermax: Hardware/software co-design of an efficient softmax for transformers,
J. R. Stevens,et al., “Softermax: Hardware/software co-design of an efficient softmax for transformers,” in IEEE/ACM Design Automation Conf. (DAC), pp. 469–474, 2021
2021
-
[6]
A pseudo-softmax function for hardware-based high speed image classification,
G. C. Cardarilli,et al., “A pseudo-softmax function for hardware-based high speed image classification,” Scientific Reports, vol. 11, no. 1, pp. 15307, Jul. 2021
2021
-
[7]
Root mean square layer normalization,
B. Zhang,et al., “Root mean square layer normalization,” inAdvances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[8]
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
A. Wang,et al., “GLUE: A multi-task benchmark and analysis platform for natural language understanding,” arXiv preprint, arXiv:1804.07461, 2018
work page internal anchor Pith review arXiv 2018
-
[9]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
P. Rajpurkar,et al., “Squad: 100,000+ questions for machine compre- hension of text,” arXiv preprint, arXiv:1606.05250, 2016
work page internal anchor Pith review arXiv 2016
-
[10]
Language models are few-shot learners,
T. Brown,et al., “Language models are few-shot learners,” in Advances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 1877–1901, 2020
1901
-
[11]
The logarithmic error and Newton’s method for the square root,
R. F. King,et al., “The logarithmic error and Newton’s method for the square root,” Communications of the ACM , vol. 12, no. 2, pp. 87–88, Feb. 1969
1969
-
[12]
CoRN-LN: Compressed Reciprocal Newton Method for Efficient Layer Normalization,
D. Choi,et al., “CoRN-LN: Compressed Reciprocal Newton Method for Efficient Layer Normalization,” 2025 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), 2025
2025
-
[13]
Improving Transformer Inference Through Opti- mized Non-Linear Operations With Quantization-Approximation-Based Strategy,
W. Wang,et al., “Improving Transformer Inference Through Opti- mized Non-Linear Operations With Quantization-Approximation-Based Strategy,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2024
2024
-
[14]
SoftmAP: Software-Hardware Co-design for Integer- Only Softmax on Associative Processors,
M. Rakka,et al., “SoftmAP: Software-Hardware Co-design for Integer- Only Softmax on Associative Processors,” in Design, Automation & Test in Europe Conference (DATE), 2025
2025
-
[15]
Hardware-oriented algorithms for softmax and layer normalization of large language models,
W. Li,et al., “Hardware-oriented algorithms for softmax and layer normalization of large language models,”Science China Information Sciences, vol. 67, no. 10, pp. 200404, Oct. 2024
2024
-
[16]
An Efficient Layer Normalization Training Module With Dynamic Quantization for Transformers,
H. Shao,et al., “An Efficient Layer Normalization Training Module With Dynamic Quantization for Transformers,” IEEE Transactions on Circuits and Systems II: Express Briefs, Sep. 2025
2025
-
[17]
MBS: A High-Precision Approximation Method for Softmax and Efficient Hardware Implementation,
Y . Wu,et al., “MBS: A High-Precision Approximation Method for Softmax and Efficient Hardware Implementation,” IEEE Transactions on Circuits and Systems I: Regular Papers, Jul. 2025
2025
-
[18]
Efficient precision-adjustable architecture for softmax function in deep learning,
D. Zhu,et al., “Efficient precision-adjustable architecture for softmax function in deep learning,” IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 67, no. 12, pp. 3382–3385, Dec. 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.