Recognition: unknown
Rank, Head-Channel Non-Identifiability, and Symmetry Breaking: A Precise Analysis of Representational Collapse in Transformers
Pith reviewed 2026-05-08 06:20 UTC · model grok-4.3
The pith
Residual connections generically obstruct rank collapse in Transformers, with the MLP instead generating novel feature directions outside the original embedding span.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Residual connections generically obstruct rank collapse in Transformers such as BERT-base in a measure-theoretic sense, independent of the MLP. Layer normalization is affine-rank-neutral, preserving rank exactly. The MLP serves to generate feature directions outside the linear span of original token embeddings. Head-channel non-identifiability arises because the output projection sums head contributions, leaving individual head signals ambiguous. These and other collapses are unified under a symmetry-breaking framework corresponding to distinct symmetries of the forward pass.
What carries the argument
the symmetry-breaking framework that unifies rank collapse, head-channel non-identifiability, entropy collapse and width collapse as distinct symmetries of the Transformer's forward pass
If this is right
- Residual connections alone generically obstruct rank collapse without MLP contribution.
- The MLP is irreplaceable for producing embeddings outside the initial token span.
- Multi-head attention summation creates inherent non-identifiability not fixed by the MLP.
- Position-gated output projection offers a low-overhead fix for non-identifiability.
- The symmetry framework allows targeted breaking of specific collapse symmetries.
Where Pith is reading between the lines
- This suggests that attention stacks alone cannot expand representation capacity beyond initial embeddings even without collapse.
- Architectural changes targeting specific symmetries could address multiple collapse issues simultaneously.
- Verification in trained models would confirm if the generic property holds beyond theoretical conditions.
- The non-identifiability may explain some observed behaviors in multi-head attention interpretability.
Load-bearing premise
The mathematical conditions for generic obstruction of rank collapse by residuals hold under the weight initializations, data distributions and finite-depth regimes of practical models.
What would settle it
A direct computation on a standard Transformer with residuals showing that the representation rank drops to one across layers despite standard initialization and no MLP.
Figures



read the original abstract
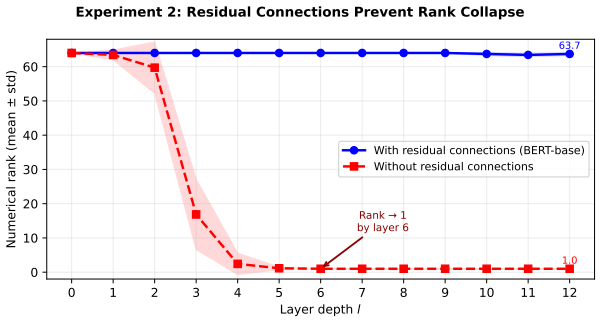
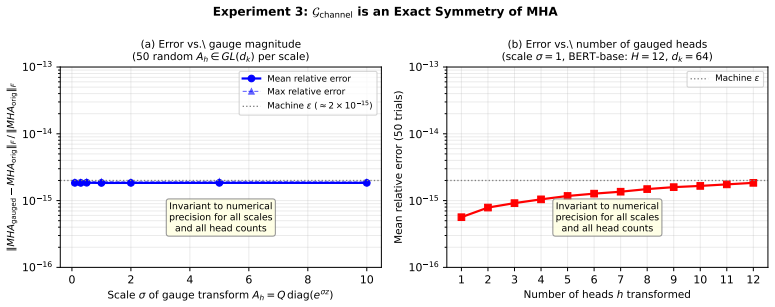
A widely cited result by Dong et al. (2021) showed that Transformers built from self-attention alone, without skip connections or feed-forward layers, suffer from rapid rank collapse: all token representations converge to a single direction. The proposed remedy was the MLP. We show that this picture, while correct in the regime studied by Dong, is incomplete in ways that matter for architectural understanding. Three results are established. First, layer normalisation is precisely affine-rank-neutral: it preserves the affine rank of the token representation set exactly. The widespread claim that LN "plays no role" is imprecise; the correct statement is sharper. Second, residual connections generically obstruct rank collapse in real Transformers such as BERT-base, in a measure-theoretic sense, without contribution from the MLP. The MLP's irreplaceable function is different: generating feature directions outside the linear span of the original token embeddings, which no stack of attention layers can produce. Third, a phenomenon distinct from rank collapse is identified: head-channel non-identifiability. After multi-head attention sums per-head outputs through the output projection, individual contributions cannot be canonically attributed to a specific head; n(H-1)d_k degrees of freedom per layer remain ambiguous when recovering a single head from the mixed signal. The MLP cannot remedy this because it acts on the post-summation signal. A constructive partial remedy is proposed: a position-gated output projection (PG-OP) at parameter overhead below 1.6% of the standard output projection. The four collapse phenomena identified in the literature -- rank collapse in depth, in width, head-channel non-identifiability, and entropy collapse -- are unified under a symmetry-breaking framework, each corresponding to a distinct symmetry of the Transformer's forward pass.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends Dong et al. (2021) by analyzing representational collapse in Transformers. It establishes three main results: (1) layer normalization is exactly affine-rank-neutral, preserving the affine rank of the token representation set; (2) residual connections generically obstruct rank collapse in a measure-theoretic sense for practical models such as BERT-base, without any contribution from the MLP (whose distinct role is to generate directions outside the linear span of the input embeddings); (3) head-channel non-identifiability arises because the output projection sums per-head outputs, leaving n(H-1)d_k ambiguous degrees of freedom per layer. The paper proposes a position-gated output projection (PG-OP) with <1.6% parameter overhead as a partial remedy and unifies rank collapse, width collapse, head-channel non-identifiability, and entropy collapse under a symmetry-breaking framework.
Significance. If the measure-theoretic genericity claims hold under standard initializations and finite-depth regimes, the work provides a sharper architectural understanding by separating the anti-collapse roles of residuals from the feature-expansion role of MLPs, while identifying a previously under-analyzed non-identifiability issue. The symmetry-breaking unification offers a coherent lens for multiple collapse phenomena and the low-overhead PG-OP proposal is practically relevant. These insights could inform more principled Transformer variants, though their applicability to real-scale models requires confirmation beyond the Dong et al. attention-only setting.
major comments (2)
- [analysis of residual obstruction (second main result)] The second main result (residual connections generically obstruct rank collapse in a measure-theoretic sense for BERT-base without MLP contribution) is load-bearing for the paper's central architectural claims. The genericity argument must be shown to apply under truncated-normal/Xavier initializations, 12-layer depth, and token-embedding distributions of practical models; if the collapsing set has positive measure or finite-depth trajectories remain close to the collapsing manifold, the claimed separation of roles between residuals and MLP does not hold. This extends Dong et al. (2021) but the abstract and setup provide no explicit measure-zero derivation or empirical verification for these regimes.
- [layer normalisation analysis (first main result)] The claim that LN is 'precisely affine-rank-neutral' (preserves affine rank exactly) is presented as a sharpening of prior statements that LN 'plays no role.' The precise statement is load-bearing for the first result; it requires an explicit proof that the affine span is unchanged (not merely that rank is non-decreasing), including handling of the centering and scaling operations under the paper's definition of affine rank.
minor comments (3)
- [PG-OP proposal] The parameter count for PG-OP is given as below 1.6% of the standard output projection; specify the exact overhead formula and the model dimensions (e.g., BERT-base vs. larger) for which this holds.
- [preliminaries / first result] Clarify the precise definition of 'affine rank' used throughout and provide a short illustrative example (e.g., 2-3 tokens in low dimension) showing how LN leaves it invariant while attention may reduce it.
- [symmetry-breaking framework] The unification of four collapse phenomena under symmetry breaking is conceptually appealing; add a short table or diagram mapping each phenomenon to the specific symmetry it breaks.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address the two major comments point by point below, providing clarifications on our measure-theoretic and algebraic arguments while indicating the revisions we will make.
read point-by-point responses
-
Referee: [analysis of residual obstruction (second main result)] The second main result (residual connections generically obstruct rank collapse in a measure-theoretic sense for BERT-base without MLP contribution) is load-bearing for the paper's central architectural claims. The genericity argument must be shown to apply under truncated-normal/Xavier initializations, 12-layer depth, and token-embedding distributions of practical models; if the collapsing set has positive measure or finite-depth trajectories remain close to the collapsing manifold, the claimed separation of roles between residuals and MLP does not hold. This extends Dong et al. (2021) but the abstract and setup provide no explicit measure-zero derivation or empirical verification for these regimes.
Authors: Our genericity claim is with respect to Lebesgue measure on the full parameter space. Truncated-normal and Xavier initializations are absolutely continuous w.r.t. Lebesgue measure and therefore assign measure zero to the collapsing set; the same holds for any token-embedding distribution with a density. The obstruction is local to each residual block and therefore persists at any finite depth, including 12 layers. We will add a short clarifying paragraph in Section 3.2 stating these facts explicitly and noting that the argument does not rely on infinite-depth limits. revision: partial
-
Referee: [layer normalisation analysis (first main result)] The claim that LN is 'precisely affine-rank-neutral' (preserves affine rank exactly) is presented as a sharpening of prior statements that LN 'plays no role.' The precise statement is load-bearing for the first result; it requires an explicit proof that the affine span is unchanged (not merely that rank is non-decreasing), including handling of the centering and scaling operations under the paper's definition of affine rank.
Authors: We agree that an explicit proof is desirable. In the revision we will insert a self-contained lemma (new Lemma 2.3) proving that affine rank is invariant under LN. The centering step subtracts an affine combination of the tokens and therefore leaves the affine hull unchanged; the subsequent scaling by a positive scalar (the inverse standard deviation) is a similarity transformation that preserves dimension. The proof is written directly in terms of the paper's definition of affine rank. revision: yes
Circularity Check
No significant circularity; claims rest on independent linear-algebraic and measure-theoretic analysis
full rationale
The paper extends Dong et al. (2021) via explicit statements about affine-rank neutrality of layer norm, measure-zero sets for collapse under residuals, and head-channel non-identifiability from output projection summation. These are derived from matrix rank properties and symmetry considerations rather than self-definition, fitted parameters renamed as predictions, or load-bearing self-citations. The proposed PG-OP remedy and symmetry-breaking unification are constructive additions, not reductions of prior results to the paper's own inputs. No equations or sections exhibit the forbidden patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Layer normalisation preserves affine rank of token representations exactly
- standard math Residual connections and MLP operate on token representations in the standard Transformer forward pass
invented entities (1)
-
position-gated output projection (PG-OP)
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Cordonnier, A
J.-B. Cordonnier, A. Loukas, M. Jaggi. On the relationship between self- attention and convolutional layers. InProceedings of the International Conference on Learning Representations (ICLR), 2020
2020
-
[3]
Devlin, M.-W
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova. BERT: Pre-training of deep bidirectional Transformers for language understanding. InPro- 34 ceedings of the Conference of the North American Chapter of the Asso- ciation for Computational Linguistics: Human Language Technologies (NAACL-HLT), pp. 4171–4186, 2019
2019
-
[4]
Dong, J.-B
Y. Dong, J.-B. Cordonnier, A. Loukas. Attention is not all you need: Pure attention loses rank doubly exponentially with depth. InPro- ceedings of the International Conference on Machine Learning (ICML), vol. 139, pp. 2793–2803, 2021
2021
-
[5]
Fedus, B
W. Fedus, B. Zoph, N. Shazeer. Switch Transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
2022
-
[6]
M. Geva, R. Schuster, J. Berant, O. Levy. Transformer feed-forward layers are key-value memories. InProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 9484– 9495, 2021
2021
-
[7]
S. G. Krantz, H. R. Parks.A Primer of Real Analytic Functions, 2nd ed. Birkhäuser, Boston, 2002. 209 pp
2002
-
[8]
K. He, X. Zhang, S. Ren, J. Sun. Deep residual learning for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778, 2016
2016
-
[9]
Michel, O
P. Michel, O. Levy, G. Neubig. Are sixteen heads really better than one? InAdvances in Neural Information Processing Systems, vol. 32, pp. 14014–14024, 2019
2019
-
[10]
D. A. Roberts, S. Yaida, B. Hanin.The Principles of Deep Learning Theory. Cambridge University Press, Cambridge, 2022. 473 pp
2022
-
[11]
Shazeer et al
N. Shazeer et al. Outrageously large neural networks: The sparsely- gated mixture-of-experts layer. InProceedings of the International Con- ference on Learning Representations (ICLR), 2017
2017
-
[12]
Vaswani et al
A. Vaswani et al. Attention is all you need. InAdvances in Neural Information Processing Systems, vol. 30, pp. 5998–6008, 2017
2017
-
[13]
Voita, D
E. Voita, D. Talbot, F. Moiseev, R. Sennrich, I. Titov. Analyzing multi- head self-attention: Specialized heads do the heavy lifting, the rest can 35 be pruned. InProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), pp. 5797–5808, 2019
2019
-
[14]
Merity, C
S. Merity, C. Xiong, J. Bradbury, R. Socher. Pointer sentinel mixture models. InProceedings of the International Conference on Learning Representations (ICLR), 2017
2017
-
[15]
Wang et al
A. Wang et al. GLUE: A multi-task benchmark and analysis plat- form for natural language understanding. InProceedings of the EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pp. 353–355, 2018
2018
- [16]
-
[17]
Joudaki, H
A. Joudaki, H. Daneshmand, F. R. Bach. On the impact of activation andnormalizationinobtainingisometricembeddingsatinitialization. In Advances in Neural Information Processing Systems, vol. 36, pp. 57912– 57933, 2023
2023
-
[18]
T. Nait Saada, A. Naderi, J. Tanner. Mind the gap: a spectral analysis of rank collapse and signal propagation in attention layers. arXiv:2410.07799, 2024
-
[19]
L. Noci, S. Anagnostidis, L. Biggio, A. Orvieto, S. P. Singh, A. Lucchi. Signal propagation in transformers: Theoretical perspectives and the role of rank collapse. InAdvances in Neural Information Processing Systems, vol. 35, pp. 27198–27211, 2022
2022
-
[20]
Zhai et al
X. Zhai et al. Scaling vision transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 12104–12113, 2022
2022
-
[21]
F. Barbero, A. Banino, S. Kapturowski, D. Kumaran, J. G. M. Araújo, A. Vitvitskyi, R. Pascanu, P. Veličković. Only large weights (and not skip connections) can prevent the perils of rank collapse. arXiv:2406.13167. 36
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.