Recognition: unknown
SFT-then-RL Outperforms Mixed-Policy Methods for LLM Reasoning
Pith reviewed 2026-05-08 06:39 UTC · model grok-4.3
The pith
Once implementation bugs are fixed, the standard SFT-then-RL pipeline outperforms published mixed-policy methods for LLM reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
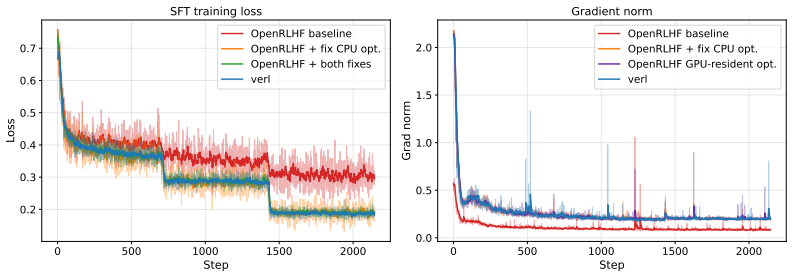
The central discovery is that two implementation bugs in widely used frameworks caused the standard SFT-then-RL pipeline to underperform in prior evaluations. The DeepSpeed bug drops intermediate micro-batches during gradient accumulation when using CPU offloading, and the OpenRLHF bug incorrectly weights per-mini-batch losses. With these corrected, SFT-then-RL surpasses mixed-policy methods by 3.8 points on Qwen2.5-Math-7B and 22.2 points on Llama-3.1-8B math benchmarks, and a truncated 50-step RL variant still leads while consuming fewer FLOPs.
What carries the argument
The corrected SFT-then-RL training pipeline, after removing the effects of the DeepSpeed optimizer bug and OpenRLHF loss aggregation bug.
If this is right
- The standard SFT-then-RL approach achieves superior performance on math reasoning benchmarks compared to mixed-policy methods.
- A minimal RL phase of only 50 steps in SFT-then-RL is sufficient to outperform mixed-policy methods at lower computational cost.
- Prior publications claiming advantages for mixed-policy methods relied on invalid SFT baselines due to the identified bugs.
- The majority of the performance gap was caused by the DeepSpeed optimizer bug, with the loss aggregation bug contributing less.
Where Pith is reading between the lines
- Training frameworks used in LLM research should be audited for similar silent bugs that could skew method comparisons.
- Future studies on policy optimization should report results with both original and corrected baselines to ensure fair evaluation.
- Practitioners may prefer the simpler SFT-then-RL pipeline for reasoning tasks unless mixed methods demonstrate benefits beyond the fixed baseline.
Load-bearing premise
The bugs identified are the main reason for the observed gaps and that the corrections restore the true performance of SFT-then-RL without introducing favoring changes.
What would settle it
Independent reproduction of the SFT-then-RL and mixed-policy training runs using the corrected code versions on the same math benchmarks and models to verify the performance ordering.
Figures




read the original abstract
Recent mixed-policy optimization methods for LLM reasoning that interleave or blend supervised and reinforcement learning signals report improvements over the standard SFT-then-RL pipeline. We show that numerous recently published research papers rely on a faulty baseline caused by two distinct bugs: a CPU-offloaded optimizer bug in DeepSpeed that silently drops intermediate micro-batches during gradient accumulation (affecting multiple downstream frameworks including TRL, OpenRLHF and Llama-Factory), and a loss aggregation bug in OpenRLHF that incorrectly weights per-mini-batch losses. Together they suppress SFT performance, with the optimizer bug accounting for most of the gap and the loss aggregation bug contributing a smaller additional effect. Once corrected, the standard SFT-then-RL pipeline surpasses every published mixed-policy method we evaluate by +3.8 points on math benchmarks with Qwen2.5-Math-7B and by +22.2 points with Llama-3.1-8B. Even a truncated variant with just 50 RL steps outperforms mixed-policy methods on math benchmarks while using fewer FLOPs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that apparent gains from recent mixed-policy optimization methods over the standard SFT-then-RL pipeline for LLM reasoning are artifacts of two bugs in baseline implementations: a DeepSpeed CPU-offloaded optimizer that silently drops micro-batches during gradient accumulation (affecting TRL, OpenRLHF, Llama-Factory) and an incorrect per-mini-batch loss weighting in OpenRLHF. After correcting these, SFT-then-RL outperforms all evaluated mixed-policy methods by +3.8 points on math benchmarks with Qwen2.5-Math-7B and +22.2 points with Llama-3.1-8B; even a 50-step RL truncation is superior while using fewer FLOPs.
Significance. If the results hold, the work has high significance by exposing implementation errors in widely adopted frameworks that have affected multiple published papers, thereby redirecting research toward reliable SFT-then-RL pipelines. The concrete, named deltas and efficiency claim constitute falsifiable predictions; the explicit naming of the two bugs and affected frameworks is a clear strength that enables targeted follow-up.
major comments (2)
- [Bug correction and experimental details] The central claim that bug corrections alone explain the gaps and restore intended SFT-then-RL behavior is load-bearing. The manuscript must supply side-by-side verification (e.g., code diffs or isolated runs) confirming that hyperparameters, data loaders, gradient accumulation steps, and evaluation protocols remain identical to the original baselines; without this, the +3.8 / +22.2 point margins and 50-step result could partly reflect ancillary implementation changes introduced during the fix.
- [Results / Abstract] The abstract states that the optimizer bug accounts for most of the gap while the loss bug contributes less, yet no quantitative ablation isolating each bug's effect (with error bars) appears in the provided text. A dedicated table or figure in the results section is required to support this breakdown and the overall attribution.
minor comments (2)
- [Tables] Performance tables should report standard deviations or multiple random seeds to substantiate the statistical reliability of the reported deltas.
- [Introduction] All mixed-policy papers whose results are re-evaluated should be explicitly listed with their original reported numbers for direct comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential impact of identifying these implementation bugs. We address each major comment below and will incorporate the requested additions and verifications into the revised manuscript.
read point-by-point responses
-
Referee: [Bug correction and experimental details] The central claim that bug corrections alone explain the gaps and restore intended SFT-then-RL behavior is load-bearing. The manuscript must supply side-by-side verification (e.g., code diffs or isolated runs) confirming that hyperparameters, data loaders, gradient accumulation steps, and evaluation protocols remain identical to the original baselines; without this, the +3.8 / +22.2 point margins and 50-step result could partly reflect ancillary implementation changes introduced during the fix.
Authors: We agree that isolating the bug fixes from any other potential changes is essential for the load-bearing claim. In the revision, we will add explicit side-by-side comparisons of the original buggy baseline implementations against the corrected versions. These will be accompanied by code diffs that highlight only the minimal changes required to address the DeepSpeed CPU-offloaded optimizer bug and the OpenRLHF loss aggregation bug. We will confirm in the text and supplementary material that all other elements—hyperparameters, data loaders, gradient accumulation steps, and evaluation protocols—remain identical to those used in the original baselines. This directly addresses the concern regarding possible ancillary implementation changes. revision: yes
-
Referee: [Results / Abstract] The abstract states that the optimizer bug accounts for most of the gap while the loss bug contributes less, yet no quantitative ablation isolating each bug's effect (with error bars) appears in the provided text. A dedicated table or figure in the results section is required to support this breakdown and the overall attribution.
Authors: We acknowledge that the current manuscript does not include a dedicated quantitative ablation with error bars to isolate the individual contributions of each bug. We will add a new table (or figure) in the results section that reports performance when applying each bug fix in isolation, as well as their combined effect. This ablation will be based on multiple independent runs to include error bars, enabling a precise breakdown of the relative impact of the optimizer bug versus the loss bug and thereby supporting the attribution statements in the abstract. revision: yes
Circularity Check
Empirical bug identification and re-evaluation contains no circular derivation
full rationale
The paper's central claim rests on identifying two specific bugs in external libraries (DeepSpeed CPU-offload optimizer dropping micro-batches and OpenRLHF loss weighting), applying corrections, and re-running the standard SFT-then-RL pipeline against published mixed-policy baselines. No mathematical equations, fitted parameters renamed as predictions, or self-citation chains are invoked to derive the performance margins. The +3.8 / +22.2 point improvements and 50-step truncation result are presented as direct empirical outcomes of the corrected implementations, not reductions to inputs defined within the paper itself. This is a standard empirical re-evaluation and scores at the low end of the range.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OpenAI, Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Chi, Quoc V Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022
2022
-
[3]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[4]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1.5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Christopher Wilhelm, Luca Soldaini, Noah A
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James Validad Miranda, Alisa Liu, Nouha Dziri, Xinxi Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Christopher Wilhelm, Luca Soldaini, Noah A. Smith, Yizhong Wang, Pradeep Dasigi, and Hannaneh...
2025
-
[6]
SFT memorizes, RL generalizes: A comparative study of foundation model post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. SFT memorizes, RL generalizes: A comparative study of foundation model post-training. InForty-second International Conference on Machine Learning, 2025
2025
-
[7]
Injecting new knowledge into large language models via supervised fine-tuning
Nick Mecklenburg, Yiyou Lin, Xiaoxiao Li, Daniel Holstein, Leonardo Nunes, Sara Malvar, Bruno Silva, Ranveer Chandra, Vijay Aski, Pavan Kumar Reddy Yannam, Tolga Aktas, and Todd Hendry. Injecting new knowledge into large language models via supervised fine-tuning. arXiv preprint arXiv:2404.00213, 2024
-
[8]
Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[9]
Kakade, Cengiz Pehlevan, Samy Jelassi, and Eran Malach
Rosie Zhao, Alexandru Meterez, Sham M. Kakade, Cengiz Pehlevan, Samy Jelassi, and Eran Malach. Echo chamber: RL post-training amplifies behaviors learned in pretraining. InSecond Conference on Language Modeling, 2025
2025
-
[10]
RL squeezes, SFT expands: A comparative study of reasoning LLMs
Kohsei Matsutani, Shota Takashiro, Gouki Minegishi, Takeshi Kojima, Yusuke Iwasawa, and Yutaka Matsuo. RL squeezes, SFT expands: A comparative study of reasoning LLMs. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[11]
Learning to reason under off-policy guidance
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. Learning to reason under off-policy guidance. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 10
2025
-
[12]
Learning what reinforcement learning can’t: Interleaved online fine-tuning for hardest questions
Lu Ma, Hao Liang, Meiyi Qiang, Lexiang Tang, Xiaochen Ma, Zhen Hao Wong, Junbo Niu, Chengyu Shen, Runming He, Yanhao Li, Wentao Zhang, and Bin CUI. Learning what reinforcement learning can’t: Interleaved online fine-tuning for hardest questions. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[13]
SRFT: A single-stage method with super- vised and reinforcement fine-tuning for reasoning
Yuqian Fu, Tinghong Chen, Jiajun Chai, Xihuai Wang, Songjun Tu, Guojun Yin, Wei Lin, Qichao Zhang, Yuanheng Zhu, and Dongbin Zhao. SRFT: A single-stage method with super- vised and reinforcement fine-tuning for reasoning. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[14]
Zeyu Huang, Tianhao Cheng, Zihan Qiu, Zili Wang, Yinghui Xu, Edoardo M. Ponti, and Ivan Titov. Blending supervised and reinforcement fine-tuning with prefix sampling.arXiv preprint arXiv:2507.01679, 2025
-
[15]
Towards a unified view of large language model post-training.arXiv preprint arXiv:2509.04419, 2025
Xingtai Lv, Yuxin Zuo, Youbang Sun, Hongyi Liu, Yuntian Wei, Zhekai Chen, Xuekai Zhu, Kaiyan Zhang, Bingning Wang, Ning Ding, and Bowen Zhou. Towards a unified view of large language model post-training.arXiv preprint arXiv:2509.04419, 2025
-
[16]
Xiangchi Yuan, Xiang Chen, Tong Yu, Dachuan Shi, Can Jin, Wenke Lee, and Saayan Mitra. Mitigating forgetting between supervised and reinforcement learning yields stronger reasoners. arXiv preprint arXiv:2510.04454, 2025
-
[17]
Zhong Guan, Likang Wu, Hongke Zhao, Jiahui Wang, and Le Wu. Recall-extend dynamics: Enhancing small language models through controlled exploration and refined offline integration. arXiv preprint arXiv:2508.16677, 2025
-
[18]
Ozdaglar
Mingyang Liu, Gabriele Farina, and Asuman E. Ozdaglar. UFT: Unifying supervised and reinforcement fine-tuning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[19]
On-policy RL meets off-policy experts: Harmonizing supervised fine-tuning and reinforcement learning via dynamic weighting
Wenhao Zhang, Yuexiang Xie, Yuchang Sun, Yanxi Chen, Guoyin Wang, Yaliang Li, Bolin Ding, and Jingren Zhou. On-policy RL meets off-policy experts: Harmonizing supervised fine-tuning and reinforcement learning via dynamic weighting. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[20]
Yihao Liu, Shuocheng Li, Lang Cao, Yuhang Xie, Mengyu Zhou, Haoyu Dong, Xiaojun Ma, Shi Han, and Dongmei Zhang. Superrl: Reinforcement learning with supervision to boost language model reasoning.arXiv preprint arXiv:2506.01096, 2025
-
[21]
Jack Chen, Fazhong Liu, Naruto Liu, Yuhan Luo, Erqu Qin, Harry Zheng, Tian Dong, Haojin Zhu, Yan Meng, and Xiao Wang. Step-wise adaptive integration of supervised fine-tuning and reinforcement learning for task-specific llms.arXiv preprint arXiv:2505.13026, 2025
-
[22]
Jinyang Wu, Chonghua Liao, Mingkuan Feng, Shuai Zhang, Zhengqi Wen, Haoran Luo, Ling Yang, Huazhe Xu, and Jianhua Tao. Templaterl: Structured template-guided reinforcement learning for llm reasoning.arXiv preprint arXiv:2505.15692, 2025
-
[23]
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, page 3505–3506, 2020
2020
-
[24]
OpenRLHF: A ray-based easy-to-use, scalable and high-performance RLHF framework
Jian Hu, Xibin Wu, Wei Shen, Jason Klein Liu, Weixun Wang, Songlin Jiang, Haoran Wang, Hao Chen, Bin Chen, Wenkai Fang, Xianyu, Yu Cao, Haotian Xu, and Yiming Liu. OpenRLHF: A ray-based easy-to-use, scalable and high-performance RLHF framework. In Ivan Habernal, Peter Schulam, and Jörg Tiedemann, editors,Proceedings of the 2025 Conference on Empirical Met...
2025
-
[25]
TRL: Transformers Rein- forcement Learning, 2020
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. TRL: Transformers Rein- forcement Learning, 2020. URLhttps://github.com/huggingface/trl. 11
2020
-
[26]
LlamaFactory: Unified efficient fine-tuning of 100+ language models
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, and Zheyan Luo. LlamaFactory: Unified efficient fine-tuning of 100+ language models. In Yixin Cao, Yang Feng, and Deyi Xiong, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 400–410, 2024
2024
-
[27]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, page 1279–1297, 2025
2025
-
[28]
Pytorch fsdp: Experiences on scaling fully sharded data parallel.Proceedings of the VLDB Endowment, 16 (12):3848–3860, 2023
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, and Shen Li. Pytorch fsdp: Experiences on scaling fully sharded data parallel.Proceedings of the VLDB Endowment, 16 (12):384...
2023
-
[29]
Bugs in LLM training – gradient accumulation fix
Daniel Han and Michael Han. Bugs in LLM training – gradient accumulation fix. Unsloth Blog, October 2024. URLhttps://unsloth.ai/blog/gradient
2024
-
[30]
Fixing gradient accumulation
Lysandre Debut, Arthur Zucker, Zachary Mueller, Yih-Dar Shieh, Benjamin Bossan, and Pedro Cuenca. Fixing gradient accumulation. Hugging Face Blog, October 2024. URL https://huggingface.co/blog/gradient_accumulation
2024
-
[31]
Open r1: A fully open reproduction of deepseek-r1, January 2025
Hugging Face. Open r1: A fully open reproduction of deepseek-r1, January 2025. URL https://github.com/huggingface/open-r1
2025
-
[32]
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository,
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Costa Huang, Kashif Rasul, Longhui Yu, Albert Jiang, Ziju Shen, Zihan Qin, Bin Dong, Li Zhou, Yann Fleureau, Guillaume Lample, and Stanislas Polu. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository,
-
[33]
URLhttps://huggingface.co/datasets/AI-MO/NuminaMath-1.5
-
[34]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review arXiv 2024
-
[35]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review arXiv 2024
-
[36]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
2021
-
[37]
Solving quantitative reasoning problems with language models
Aitor Lewkowycz, Anders Johan Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Venkatesh Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with language models. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun ...
2022
-
[38]
OlympiadBench: A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. OlympiadBench: A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings ...
2024
-
[39]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018. 12
work page internal anchor Pith review arXiv 2018
-
[40]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024
2024
-
[41]
MMLU-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. MMLU-pro: A more robust and challenging multi-task language understanding benchmark. InThe Thirty-eight Conference on Neural Information Processin...
2024
-
[42]
Spurious rewards: Rethinking training signals in RLVR.arXiv preprint arXiv:2506.10947,
Rulin Shao, Shuyue Stella Li, Rui Xin, Scott Geng, Yiping Wang, Sewoong Oh, Simon Shaolei Du, Nathan Lambert, Sewon Min, Ranjay Krishna, Yulia Tsvetkov, Hannaneh Hajishirzi, Pang Wei Koh, and Luke Zettlemoyer. Spurious rewards: Rethinking training signals in rlvr. arXiv preprint arXiv:2506.10947, 2025
-
[43]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating Systems Principles, page 611–626, 2023
2023
-
[44]
DAPO: An open-source LLM reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, YuYue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao ...
2025
-
[45]
Understanding r1-zero-like training: A critical perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective. In2nd AI for Math Workshop @ ICML 2025, 2025
2025
-
[46]
BREAD: Branched rollouts from expert anchors bridge SFT & RL for reasoning
Xuechen Zhang, Zijian Huang, Yingcong Li, Chenshun Ni, Jiasi Chen, and Samet Oymak. BREAD: Branched rollouts from expert anchors bridge SFT & RL for reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[47]
Scaling LLM test-time com- pute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time com- pute optimally can be more effective than scaling parameters for reasoning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[48]
An empirical analysis of compute-optimal large language model training
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katherine Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Oriol Vinyals, Jack William Rae, and Laur...
2022
-
[49]
<think>\n {thoughts} </think>\n
Nikhil Sardana, Jacob Portes, Sasha Doubov, and Jonathan Frankle. Beyond chinchilla-optimal: Accounting for inference in language model scaling laws. InForty-first International Conference on Machine Learning, 2024. 13 A Technical Setup and Hyperparameters Technical setup.All experiments were conducted on 4 nodes of 4 NVIDIA GH200 GPUs (16 GPUs total). Al...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.