Recognition: unknown
Query2Diagram: Answering Developer Queries with UML Diagrams
Pith reviewed 2026-05-08 05:58 UTC · model grok-4.3
The pith
Fine-tuned LLMs generate UML diagrams that answer specific developer queries about code with higher accuracy and fewer defects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fine-tuning an LLM on a modest collection of manually corrected triples—code files, natural-language developer queries, and corresponding UML diagrams encoded in structured JSON—yields models that produce diagrams with the highest F1 scores for relevant elements and defect rates below those of state-of-the-art untuned LLMs, while ensuring the output remains semantically aligned with the original query.
What carries the argument
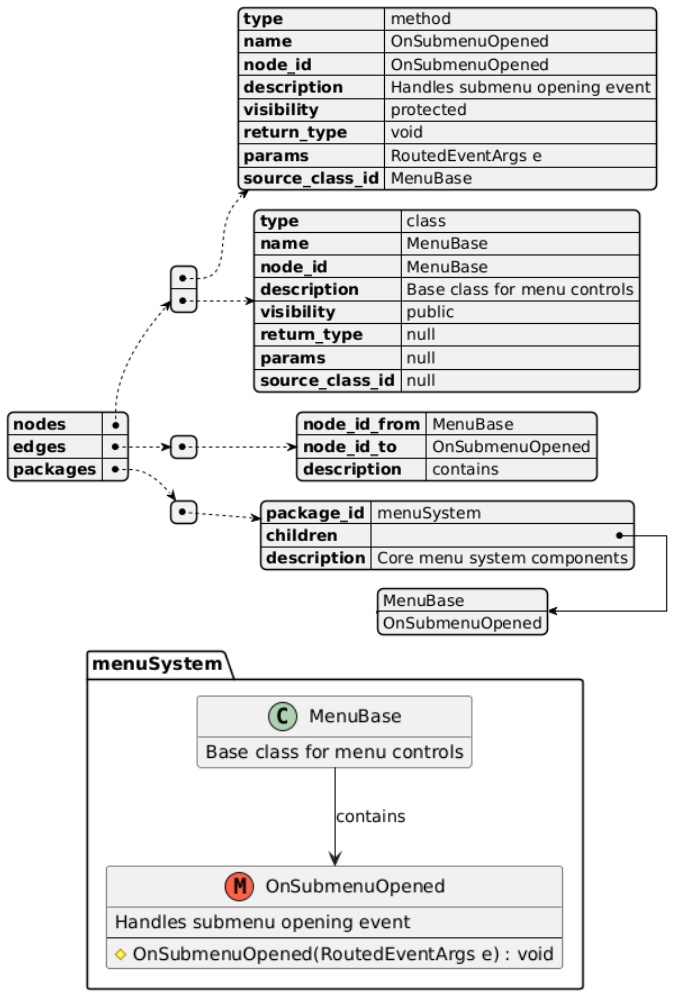
The query-driven UML generation process that maps a code file and a natural language query to a focused JSON diagram containing only pertinent classes, relationships, and contextual descriptions.
If this is right
- Developers gain on-demand access to precise visual documentation without manually updating or sifting through full diagrams.
- Maintenance tasks become easier because queries about specific system aspects return only the relevant structural information.
- The need for exhaustive reverse-engineering tools decreases when intent-aware generation is available.
- Modest amounts of human-corrected data can produce reliable specialized models for software documentation tasks.
Where Pith is reading between the lines
- The same curation-plus-fine-tuning pattern could be applied to other visual artifacts such as sequence or component diagrams if comparable datasets are built.
- Embedding the model inside an IDE would let developers receive diagrams in response to inline questions while editing code.
- The approach underscores that domain-specific performance in software engineering often benefits more from targeted data cleaning than from larger general-purpose models.
Load-bearing premise
The small set of manually corrected training examples reflects the distribution of real developer questions and code structures the model will see after deployment.
What would settle it
Running the best fine-tuned model on a large collection of previously unseen real developer queries drawn from open-source projects and checking whether the generated diagrams maintain higher F1 scores and lower defect rates than baseline LLMs would directly test the claim.
Figures





read the original abstract
Software documentation frequently becomes outdated or fails to exist entirely, yet developers need focused views of their codebase to understand complex systems. While automated reverse engineering tools can generate UML diagrams from code, they produce overwhelming detail without considering developer intent. We introduce query-driven UML diagram generation, where LLMs create diagrams that directly answer natural language questions about code. Unlike existing methods, our approach produces semantically focused diagrams containing only relevant elements with contextual descriptions. We fine-tune Qwen2.5-Coder-14B on a curated dataset of code files, developer queries, and corresponding diagram representations in a structured JSON format, evaluating with both automatic detection of structural defects and human assessment of semantic relevance. Results demonstrate that fine-tuning on a modest amount of manually corrected data yields dramatic improvements: our best model achieves the highest F1 scores while reducing defect rates below state-of-the-art LLMs, generating diagrams that are both structurally sound and semantically faithful to developer queries. Thus, we establish the feasibility of using LLMs for scalable contextual, on-demand documentation generation. We make our code and dataset publicly available at https://github.com/i-need-a-pencil/query2diagram.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Query2Diagram, a method for generating focused UML diagrams from natural language developer queries about codebases. It fine-tunes Qwen2.5-Coder-14B on a manually curated dataset of code files, queries, and structured JSON diagram representations, then evaluates using automatic structural defect detection and human semantic assessment. The central claim is that this yields dramatic improvements, with the best model achieving highest F1 scores, lower defect rates than state-of-the-art LLMs, and diagrams that are both structurally sound and semantically faithful; code and dataset are released publicly.
Significance. If the results hold under proper evaluation, the work demonstrates feasibility of scalable, query-driven documentation generation to address outdated or missing software docs. The public release of code and dataset is a clear strength, enabling reproducibility and extension by others.
major comments (2)
- [Abstract] Abstract: The claims of 'dramatic improvements,' 'highest F1 scores,' and 'reducing defect rates below state-of-the-art LLMs' are unsupported by any quantitative results, dataset statistics (size, splits), exact metrics, baseline implementations, or significance tests. This absence is load-bearing for the empirical central claim.
- [Dataset construction and evaluation sections] Dataset construction and evaluation sections: No details are given on the number of training examples, query/codebase selection criteria, diversity of sources, or any distributional validation against real developer queries (e.g., from issue trackers). The generalization to 'semantically faithful' diagrams in deployment therefore rests on an unverified assumption about representativeness of the manually curated data.
minor comments (1)
- [Abstract] Abstract: The phrase 'a modest amount of manually corrected data' is used without any indication of scale (e.g., example count), which would help readers assess the practicality of the fine-tuning approach.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and will revise the manuscript to incorporate additional details supporting the central claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of 'dramatic improvements,' 'highest F1 scores,' and 'reducing defect rates below state-of-the-art LLMs' are unsupported by any quantitative results, dataset statistics (size, splits), exact metrics, baseline implementations, or significance tests. This absence is load-bearing for the empirical central claim.
Authors: We agree that the abstract should be self-contained and include quantitative support. The current abstract uses qualitative phrasing without specific numbers. In revision we will add key results including the F1 scores, defect rates for our model versus baselines, dataset size and splits, and a brief mention of the evaluation approach. We will also report any statistical significance tests performed or note their omission as a limitation. revision: yes
-
Referee: [Dataset construction and evaluation sections] Dataset construction and evaluation sections: No details are given on the number of training examples, query/codebase selection criteria, diversity of sources, or any distributional validation against real developer queries (e.g., from issue trackers). The generalization to 'semantically faithful' diagrams in deployment therefore rests on an unverified assumption about representativeness of the manually curated data.
Authors: We acknowledge that the manuscript currently provides only high-level description of the curated dataset without exact counts or criteria. We will expand the relevant sections to specify the number of training examples, query and codebase selection process, sources used to promote diversity, and steps taken during manual curation. We will also add an explicit discussion of limitations, noting that formal distributional validation against issue-tracker queries was not performed and that generalization claims should be interpreted accordingly. revision: yes
Circularity Check
No circularity: standard fine-tuning and held-out evaluation
full rationale
The paper presents an empirical ML pipeline: fine-tune Qwen2.5-Coder-14B on a manually curated dataset of code-query-diagram triples, then evaluate with automatic structural defect detection and human semantic assessment. No equations, no fitted parameters renamed as predictions, no self-citation chains, and no uniqueness theorems are invoked. The central claims (highest F1, reduced defects, semantic faithfulness) rest on independent test-set performance rather than reducing to the training inputs by construction. This is the normal non-circular case for supervised learning papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs fine-tuned on structured JSON diagram representations will produce syntactically valid and semantically relevant UML diagrams for unseen queries
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, Sh. Anadkat, et al.,Gpt-4 technical report,https://arxiv. org/abs/2303.08774, 2023
work page internal anchor Pith review arXiv 2023
-
[2]
Amalfitano, M
D. Amalfitano, M. De Luca, T. Santilli, and P. Pelliccione,Automated software architec- ture design recovery from source code using llms, Software Architecture, Lecture Notes in Computer Science, vol. 15929, Springer, Cham, 2025, pp. 73–89
2025
-
[3]
Arisholm, L
E. Arisholm, L. C. Briand, S. E. Hove, and Y. Labiche,The impact of uml documentation on software maintenance: An experimental evaluation, IEEE Transactions on Software Engineering32(2006), no. 6, 365–381
2006
-
[4]
Babaalla, A
Z. Babaalla, A. Jakimi, and M. Oualla,Llm-driven mda pipeline for generating uml class diagrams and code, IEEE Access13(2025), 171266–171283
2025
-
[5]
Battulga, L
B. Battulga, L. Tsoodol, E. Dovdon, N. Bold, and O.-E. Namsrai,Metric-based defect prediction from class diagram, Array27(2025), 100438
2025
-
[6]
M. Ben Chaaben,Software modeling assistance with large language models, Proceed- ings of the ACM/IEEE 27th International Conference on Model Driven Engineering Languages and Systems, Association for Computing Machinery, 2024, pp. 188–191
2024
-
[7]
Boronat and J
A. Boronat and J. Mustafa,Mdre-llm: A tool for analyzing and applying llms in soft- ware reverse engineering, Proceedings of the 2025 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), IEEE, 2025, pp. 850–854
2025
-
[8]
C ´amara, J
J. C ´amara, J. Troya, L. Burgue ˜no, and A. Vallecillo,On the assessment of generative ai in modeling tasks: an experience report with chatgpt and uml, Software and Systems Modeling22(2023), no. 3, 781–793
2023
-
[9]
De Bari, G
D. De Bari, G. Garaccione, R. Coppola, M. Torchiano, and L. Ardito,Evaluating large language models in exercises of uml class diagram modeling, Proceedings of the 18th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (New York, NY, USA), ESEM ’24, Association for Computing Machinery, 2024, p. 393–399
2024
-
[10]
DeepSeek-AI-Team,Deepseek-r1: Incentivizing reasoning capability in llms via rein- forcement learning,https://arxiv.org/abs/2501.12948, 2025. 17
work page internal anchor Pith review arXiv 2025
-
[11]
Dettmers, A
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer,Qlora: Efficient finetuning of quantized llms, Advances in neural information processing systems36(2023), 10088–10115
2023
-
[12]
Egyed,Automated abstraction of class diagrams, ACM Transactions on Software Engineering and Methodology (TOSEM)11(2002), no
A. Egyed,Automated abstraction of class diagrams, ACM Transactions on Software Engineering and Methodology (TOSEM)11(2002), no. 4, 449–491
2002
-
[13]
Elmers,Code and Comment Consistency Classification with Large Language Mod- els, Master’s thesis, Eindhoven University of Technology, Eindhoven, Netherlands, October 2023
P. Elmers,Code and Comment Consistency Classification with Large Language Mod- els, Master’s thesis, Eindhoven University of Technology, Eindhoven, Netherlands, October 2023
2023
-
[14]
Ferrari, S
A. Ferrari, S. Abualhaijal, and Ch. Arora,Model generation with llms: From requirements to uml sequence diagrams, 2024 IEEE 32nd International Requirements Engineering Conference Workshops (REW), IEEE, 2024, pp. 291–300
2024
-
[15]
Genero, M
M. Genero, M. Piattini, and C. Calero,A survey of metrics for uml class diagrams, Journal of object technology4(2005), no. 9, 59–92
2005
-
[16]
T. A. Ghaleb, M. A. Alturki, and Kh. Aljasser,Program comprehension through reverse- engineered sequence diagrams: A systematic review, Journal of Software: Evolution and Process30(2018), no. 11, e1965
2018
-
[17]
Gu ´eh´eneuc,A reverse engineering tool for precise class diagrams, Proceedings of the 2004 conference of the Centre for Advanced Studies on Collaborative research, 2004, pp
Y.-G. Gu ´eh´eneuc,A reverse engineering tool for precise class diagrams, Proceedings of the 2004 conference of the Centre for Advanced Studies on Collaborative research, 2004, pp. 28–41
2004
-
[18]
Gu ´eh´eneuc, R
Y.-G. Gu ´eh´eneuc, R. Douence, and N. Jussien,No Java without Caffeine: A tool for dynamic analysis of Java programs, Proceedings 17th IEEE International Conference on Automated Software Engineering„ IEEE, 2002, pp. 117–126
2002
-
[19]
D. Han, M. Han, and Unsloth Team,Unsloth,http://github.com/unslothai/unsloth, 2023
2023
-
[20]
Hebig, T
R. Hebig, T. H. Quang, M. R. V. Chaudron, G. Robles, and M. A. Fernandez,The quest for open source projects that use uml: mining github, Proceedings of the ACM/IEEE 19th international conference on model driven engineering languages and systems, 2016, pp. 173–183
2016
-
[21]
J. Hong, N. Lee, and J. Thorne,Orpo: Monolithic preference optimization without reference model, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 11170–11189
2024
-
[22]
Hoque, P
E. Hoque, P. Kavehzadeh, and A. Masry,Chart question answering: State of the art and future directions, Computer Graphics Forum41(2022), no. 3, 555–572
2022
-
[23]
Jahan, M
M. Jahan, M. M. Hassan, R. Golpayegani, G. Ranjbaran, Ch. Roy, B. Roy, and K. Schnei- der,Automated derivation of uml sequence diagrams from user stories: Unleashing the power of generative ai vs. a rule-based approach, Proceedings of the ACM/IEEE 27th International Conference on Model Driven Engineering Languages and Systems (New York, NY, USA), MODELS ’...
2024
-
[24]
Jongeling, A
R. Jongeling, A. Cicchetti, and F. Ciccozzi,How are informal diagrams used in software engineering? an exploratory study of open-source and industrial practices, Software and Systems Modeling24(2025), no. 3, 601–613. 18
2025
-
[25]
V. Kan, M. P. Lnu, S. Berhe, C. El Kari, M. Maynard, and F. Khomh,Automated uml visualization of software ecosystems: Tracking versions, dependencies, and security updates, Procedia Computer Science, 8th International Conference on Emerging Data and Industry (EDI40), vol. 257, Elsevier, 2025, pp. 834–841
2025
-
[26]
Khiati, Dj
N. Khiati, Dj. Bouchiha, Y. Atig, and S. Boukli Hacene,Wa2ma: A model-driven approach for reengineering web applications into mobile applications, Edelweiss Applied Science and Technology9(2025), no. 6, 1530–1544
2025
-
[27]
Kwon, Zh
W. Kwon, Zh. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica,Efficient memory management for large language model serving with pagedattention, Proceedings of the 29th Symposium on Operating Systems Principles, 2023, pp. 611–626
2023
-
[28]
Lomshakov and S
V. Lomshakov and S. Nikolenko,Large language models for source code generation and editing, Zapiski Nauchnykh Seminarov POMI540(2024), 276–350
2024
-
[29]
Nugroho and M
A. Nugroho and M. R. V. Chaudron,A survey into the rigor of uml use and its perceived impact on quality and productivity, Proceedings of the Second ACM-IEEE international symposium on Empirical software engineering and measurement, 2008, pp. 90–99
2008
-
[30]
,Evaluating the impact of uml modeling on software quality: An industrial case study, ACM/IEEE International Conference on Model Driven Engineering Languages and Systems, 2009
2009
-
[31]
,The impact of uml modeling on defect density and defect resolution time in a proprietary system, Empirical Software Engineering19(2014), 926–954
2014
-
[32]
Osman, A
H. Osman, A. van Zadelhoff, and M. R. V. Chaudron,Uml class diagram simplification- a survey for improving reverse engineered class diagram comprehension, Interna- tional Conference on Model-Driven Engineering and Software Development, vol. 2, SCITEPRESS, 2013, pp. 291–296
2013
-
[33]
Osman, A
H. Osman, A. van Zadelhoff, Dave R Stikkolorum, and Michel RV Chaudron,Uml class diagram simplification: What is in the developer’s mind?, Proceedings of the second edition of the international workshop on experiences and empirical studies in software modelling, 2012, pp. 1–6
2012
-
[34]
github.io/blog/qwq-32b-preview/, November 2024
QwenTeam,Qwq: Reflect deeply on the boundaries of the unknown,https://qwenlm. github.io/blog/qwq-32b-preview/, November 2024
2024
-
[35]
Shehata, B
M. Shehata, B. Lepore, H. Cummings, and E. Parra,Creating uml class diagrams with general-purpose llms, 2024 IEEE Working Conference on Software Visualization (VISSOFT), IEEE, 2024, pp. 157–158
2024
-
[36]
H. A. Siala and K. Lano,Leveraging llms for abstracting uml and ocl representations from java and python programs,https://papers.ssrn.com/sol3/papers.cfm?abstract_id= 5348203, 2025
2025
-
[37]
,Towards using llms in the reverse engineering of software systems to object con- straint language, Proceedings of the 2025 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), IEEE, 2025, pp. 885–890. 19
2025
-
[38]
,Using large language models to extract uml class diagrams from java programs, 8th International Conference on Software and System Engineering (ICoSSE 2025), IEEE, 2025, pp. 70–74
2025
-
[39]
ˇStˇep´anek, D
A. ˇStˇep´anek, D. Ku ˇt´ak, B. Kozl ´ıkov´a, and J. By ˇska,Helveg: Diagrams for software documentation, IEEE Transactions on Visualization and Computer Graphics31(2025), no. 10, 9079–9090
2025
-
[40]
Sutton and J
A. Sutton and J. I. Maletic,Recovering uml class models from c++: A detailed explanation, Information and Software Technology49(2007), no. 3, 212–229
2007
-
[41]
Copilot Team,Microsoft Copilot: Your AI companion,https://copilot.microsoft.com/, 2023, Accessed: 2025-07-04
2023
-
[42]
Cursor Team,Cursor — The AI Code Editor,https://cursor.com/, 2023, Accessed: 2025-07-04
2023
-
[43]
Tonella and A
P. Tonella and A. Potrich,Reverse engineering of the uml class diagram from c++ code in presence of weakly typed containers, Proceedings IEEE International Conference on Software Maintenance. ICSM 2001, IEEE, 2001, pp. 376–385
2001
-
[44]
Unhelkar,Verification and validation for quality of uml 2.0 models, John Wiley & Sons, 2005
Bh. Unhelkar,Verification and validation for quality of uml 2.0 models, John Wiley & Sons, 2005
2005
-
[45]
B. T. Willard and R. Louf,Efficient guided generation for large language models,https: //arxiv.org/abs/2307.09702, 2023
work page internal anchor Pith review arXiv 2023
-
[46]
A survey on large language models for software engineering.arXiv preprint arXiv:2312.15223, 2023
Q. Zhang, Ch. Fang, Y. Xie, Y. Zhang, Y. Yang, W. Sun, Sh. Yu, and Zh. Chen,A survey on large language models for software engineering,https://arxiv.org/abs/2312.15223, 2023
-
[47]
Zheng, R
Y. Zheng, R. Zhang, J. Zhang, Y. Ye, Zh. Luo, Zh. Feng, and Y. Ma,Llamafactory: Unified efficient fine-tuning of 100+ language models, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) (Bangkok, Thailand), Association for Computational Linguistics, 2024. 20
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.