Recognition: unknown
Reheat Nachos for Dinner? Evaluating AI Support for Cross-Cultural Communication of Neologisms
Pith reviewed 2026-05-08 06:15 UTC · model grok-4.3
The pith
AI explanations of slang improve non-native speakers' message writing to native speakers more than definitions or rewrites do.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
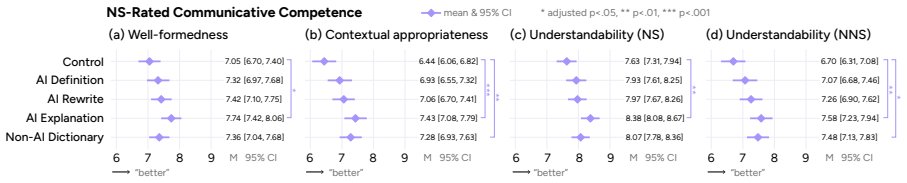
In the experiment, AI explanations of neologism meaning and usage produced the largest improvement in native-speaker-rated communicative competence of non-native speakers' writing compared with AI definitions, rewrites, or dictionary lookups, although non-native speakers' contextual appropriateness judgments remained similar across all conditions and their self-perceptions exceeded the external ratings.
What carries the argument
A controlled human-subjects study with 234 non-native speakers comparing four support types for learning neologisms before writing informal messages, evaluated through native-speaker competence scores and learner judgments.
If this is right
- Explanatory content in AI responses offers the strongest support for producing appropriate informal text with new words.
- Non-native speakers' internal sense of how well they are using slang does not align with native speakers' judgments.
- Even the best AI condition leaves a noticeable quality difference between native and non-native produced messages.
- Tool designers should focus on usage explanations rather than simple definitions or rewrites for slang learning.
Where Pith is reading between the lines
- Adding mechanisms for users to see how native speakers might react could reduce overestimation of competence.
- Testing the same supports in live chat or voice settings might expose different strengths and weaknesses.
- Similar gaps could appear in other informal language domains such as idioms or cultural references.
Load-bearing premise
The 234 non-native participants, selected neologisms, and native raters sufficiently represent typical everyday informal cross-cultural communication, and native speaker ratings serve as a valid measure of communicative success.
What would settle it
A new study using a different group of neologisms or more diverse participants that finds equivalent native-speaker ratings across all AI support conditions would show the advantage of explanations is not general.
Figures









read the original abstract
Neologisms and emerging slang are central to daily conversation, yet challenging for non-native speakers (NNS) to interpret and use appropriately in cross-cultural communication with native speakers (NS). NNS increasingly make use of Artificial Intelligence (AI) tools to learn these words. We study the utility of such tools in mediating an informal communication scenario through a human-subjects study (N=234): NNS participants learn English neologisms with AI support, write messages using the learned word to an NS friend, and judge contextual appropriateness of the neologism in two provided writing samples. Using both NS evaluator-rated communicative competence of NNS-produced writing and NNS' contextual appropriateness judgments, we compare three AI-based support conditions: AI Definition, AI Rewrite into simpler English, AI Explanation of meaning and usage, and Non-AI Dictionary for comparison. We show that AI Explanation yields the largest gains over no support in NS-rated competence, while contextual appropriateness judgments show indifference across support. NNS participants' self-reported perceptions tend to overestimate NS ratings, revealing a mismatch between perceived and actual competence. We further observe a significant gap between NNS- and NS-produced writing, highlighting the limitations of current AI tools and informing design for future tools.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from a human-subjects study (N=234 NNS participants) comparing three AI support conditions (Definition, Rewrite, Explanation) and a dictionary baseline for helping non-native speakers learn and use English neologisms in informal messages to native speakers. It claims that AI Explanation produces the largest gains in NS-rated communicative competence over no support, that NNS contextual appropriateness judgments are indifferent across conditions, that NNS self-perceptions overestimate NS ratings, and that a gap exists between NNS- and NS-produced writing.
Significance. If the empirical results hold after proper statistical reporting and validation of assumptions, the work provides concrete evidence on the relative utility of different AI explanation styles for cross-cultural neologism use, documents a perception-reality mismatch, and identifies current AI limitations, which can directly inform the design of more effective language-learning tools in NLP and HCI.
major comments (3)
- [Abstract / Results] Abstract and Results section: The directional claim that 'AI Explanation yields the largest gains over no support in NS-rated competence' is presented without any statistical tests, effect sizes, confidence intervals, participant demographics, neologism selection criteria, or error bars, rendering the central comparative result only partially verifiable.
- [Methods] Methods section: The assumption that the 234 NNS participants, selected neologisms, and NS raters are representative of typical informal NS-NNS exchanges is not justified or tested; without recruitment details, proficiency screening, or neologism sampling process, the superiority of AI Explanation cannot be generalized beyond the specific study artifacts.
- [Results] Results section: NS ratings are treated as a valid proxy for communicative competence without reported inter-rater reliability, rater instructions, or any validation that the judgments reflect real-world success rather than surface-level features or task-specific biases.
minor comments (2)
- [Title] The title is only loosely connected to the content on neologisms and could be revised for immediate clarity about the paper's focus.
- [Abstract] The abstract states that NNS perceptions 'tend to overestimate' NS ratings but provides no quantitative measure of the mismatch (e.g., correlation or mean difference), which would strengthen the presentation.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for improving the clarity and rigor of our manuscript. We address each major comment point by point below, with honest indications of where revisions will be incorporated.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and Results section: The directional claim that 'AI Explanation yields the largest gains over no support in NS-rated competence' is presented without any statistical tests, effect sizes, confidence intervals, participant demographics, neologism selection criteria, or error bars, rendering the central comparative result only partially verifiable.
Authors: We agree that the abstract would be strengthened by including supporting statistical details for the central claim. The full Results section reports ANOVA tests, post-hoc comparisons, effect sizes, and confidence intervals demonstrating the gains for the Explanation condition over no support. Participant demographics appear in Section 3.1 and neologism selection criteria in Section 3.2. We will revise the abstract to reference key statistical outcomes and ensure error bars are visible in figures. This addresses verifiability without altering the directional finding. revision: yes
-
Referee: [Methods] Methods section: The assumption that the 234 NNS participants, selected neologisms, and NS raters are representative of typical informal NS-NNS exchanges is not justified or tested; without recruitment details, proficiency screening, or neologism sampling process, the superiority of AI Explanation cannot be generalized beyond the specific study artifacts.
Authors: We will expand the Methods section to include explicit recruitment details (platform, screening for NNS English proficiency), the neologism sampling process (criteria based on recency and frequency in informal sources), and NS rater demographics. While we cannot empirically test full representativeness across all possible informal exchanges in a single study, these additions will allow readers to evaluate the scope of our findings on AI Explanation more accurately. revision: yes
-
Referee: [Results] Results section: NS ratings are treated as a valid proxy for communicative competence without reported inter-rater reliability, rater instructions, or any validation that the judgments reflect real-world success rather than surface-level features or task-specific biases.
Authors: We will add inter-rater reliability metrics (e.g., intraclass correlation) and a summary of rater instructions to the revised manuscript. On validation against real-world success, the study employs a controlled informal messaging task as a proxy; we will explicitly discuss this as a limitation and note potential influences of surface features. We maintain that NS ratings provide a valid and commonly used proxy in this domain, but acknowledge it does not fully capture longitudinal real-world outcomes. revision: partial
Circularity Check
Empirical human-subjects evaluation with external ratings; no derivation chain or fitted parameters
full rationale
The paper reports results from a human-subjects study (N=234) comparing AI support conditions on neologism use via NS-rated communicative competence and NNS judgments. No equations, parameters, or mathematical derivations appear in the abstract or described methods. Outcomes are measured from participant writing samples and external rater scores, which are independent data sources rather than reductions of the paper's own inputs. No self-citations are invoked as load-bearing for any uniqueness theorem or ansatz. The central claims rest on empirical observation, not on re-deriving inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Native-speaker ratings constitute a valid proxy for communicative competence in informal writing
- domain assumption The selected neologisms and message-writing task generalize to real cross-cultural conversations
Reference graph
Works this paper leans on
-
[1]
Michael Canale
Meaning, the central issue in cross-cultural hci design.Interacting with computers, 9(3):287–309. Michael Canale. 2014. From communicative compe- tence to communicative language pedagogy 1. In Language and communication, pages 2–27. Rout- ledge. Michael Canale and Merrill Swain. 1980. Theoreti- cal bases of communicative approaches to second language teac...
2014
-
[2]
Metrics for Explainable AI: Challenges and Prospects
From text to self: Users’ perception of aimc tools on interpersonal communication and self. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, CHI ’24, New York, NY , USA. Association for Computing Machinery. Gordon H. Guyatt, Marie Townsend, Leslie B. Berman, and Jana L. Keller. 1987. A comparison of likert and visual analog...
work page Pith review arXiv 2024
-
[3]
Relc Journal, 54(2):537–550
Chatgpt for language teaching and learning. Relc Journal, 54(2):537–550. Perihan Korkut, Mustafa Dolmacı, and Burcu Karaca
-
[4]
A study on communication breakdowns: Sources of misunderstanding in a cross-cultural set- ting.Eurasian Journal of Educational Research, 18(78):139–158. Alexandra Kuznetsova, Per B. Brockhoff, and Rune H. B. Christensen. 2017. lmerTest package: Tests in linear mixed effects models.Journal of Statistical Software, 82(13):1–26. Russell V . Lenth. 2025.emmea...
-
[5]
Martin J Pickering and Simon Garrod
Emo, love and god: making sense of Urban Dictionary, a crowd-sourced online dictionary.Royal Society Open Science, 5(5):172320. Martin J Pickering and Simon Garrod. 2013. An inte- grated theory of language production and comprehen- sion.Behavioral and brain sciences, 36(4):329–347. Yuval Pinter, Cassandra L. Jacobs, and Max Bittker
2013
-
[6]
InProceedings of the 28th Inter- national Conference on Computational Linguistics, pages 6509–6515, Barcelona, Spain (Online)
NYTWIT: A dataset of novel words in the New York Times. InProceedings of the 28th Inter- national Conference on Computational Linguistics, pages 6509–6515, Barcelona, Spain (Online). Inter- national Committee on Computational Linguistics. Anna Prokofieva and Julia Hirschberg. 2014. Hedging and speaker commitment. In5th Intl. Workshop on Emotion, Social Si...
2014
-
[7]
Translating across cultures: LLMs for in- tralingual cultural adaptation. InProceedings of the 28th Conference on Computational Natural Lan- guage Learning, pages 400–418, Miami, FL, USA. Association for Computational Linguistics. Alex Tamkin, Miles McCain, Kunal Handa, Esin Dur- mus, Liane Lovitt, Ankur Rathi, Saffron Huang, Al- fred Mountfield, Jerry Ho...
-
[8]
What happened (a short description)
-
[9]
Q1” through “Q6
A Message they sent to you using the word. If you’re unsure about the meaning of the neologism, please feel free to check the reference dictionary page provided in the beginning or use any resources you trust! Neologism:{word} Reference dictionary page:{dictionary URL} What happened:{scenario} Message from your friend:{message} Please indicate how much yo...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.