Recognition: unknown
Deep Learning of Solver-Aware Turbulence Closures from Nudged LES Dynamics
Pith reviewed 2026-05-08 05:14 UTC · model grok-4.3
The pith
Nudging sparse DNS observations into LES lets neural networks learn stable turbulence closures without backpropagating through the solver.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors show that a neural network closure can be trained a-priori by using nudging to incorporate sparse DNS data as observations in the LES equations, allowing the model to learn the required subgrid forcing that captures correct statistics and ensures stability over extended simulations, while generalizing across various numerical and temporal schemes without the need for adjoints or solver differentiation.
What carries the argument
The nudging-based forcing term derived from continuous data assimilation, which the deep learning model learns to provide as the turbulence closure for coarse-grid LES.
If this is right
- The trained closures can be deployed in existing LES solvers without any modifications or differentiability requirements.
- Models trained this way remain stable and accurate for long integration times across different numerical discretizations.
- Generalization to unseen schemes becomes possible, reducing the need for scheme-specific retraining.
- Comparisons show improved handling of numerical errors compared to traditional algebraic closure models.
Where Pith is reading between the lines
- This method could extend to training closures for flows with complex boundaries where full DNS is prohibitive.
- Integrating such learned closures with operational data assimilation systems might improve forecast accuracy in atmospheric modeling.
- The lack of backpropagation might enable faster iteration in exploring different network architectures for closure modeling.
Load-bearing premise
Nudging with sparse DNS observations trains closures that correct for both filtering and numerical discretization errors without causing new instabilities or requiring per-scheme adjustments.
What would settle it
Running long-term LES with the learned closure on a new numerical scheme and observing whether the solution remains bounded and matches DNS statistics or diverges.
Figures















read the original abstract
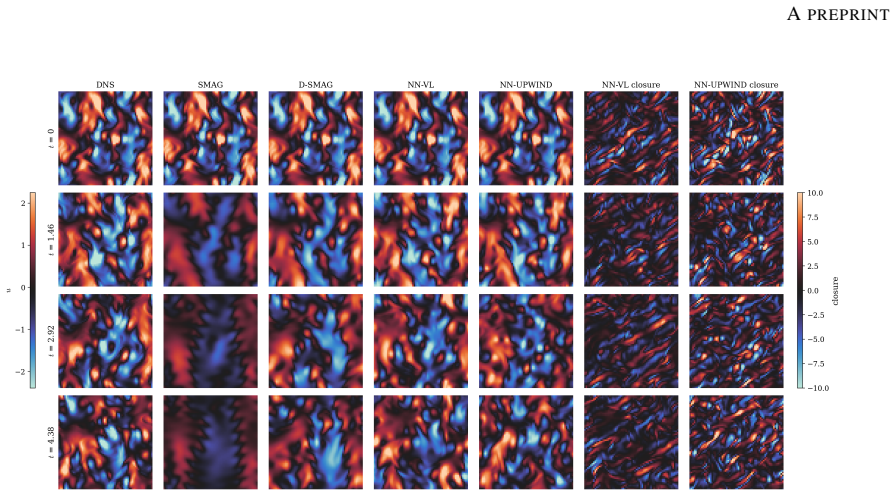
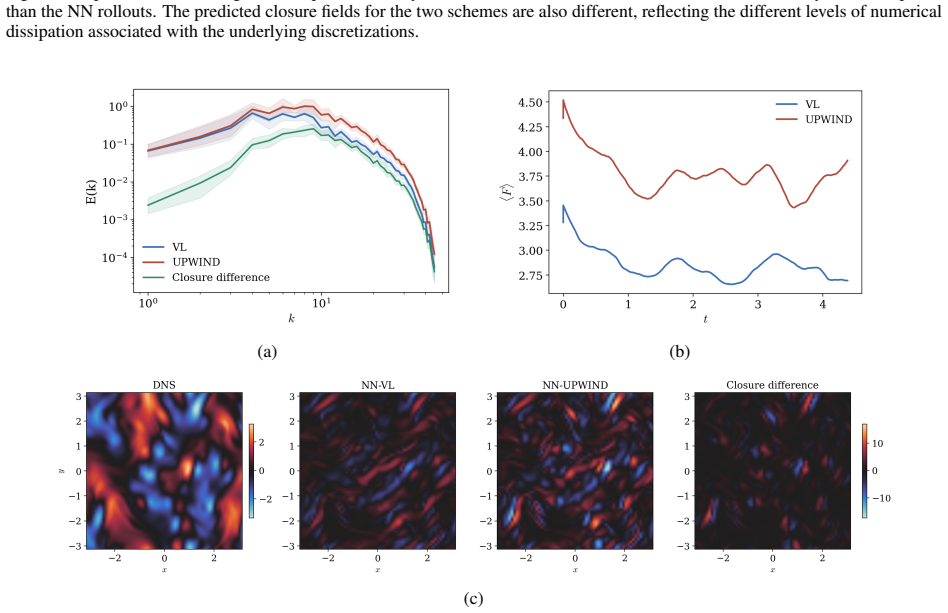
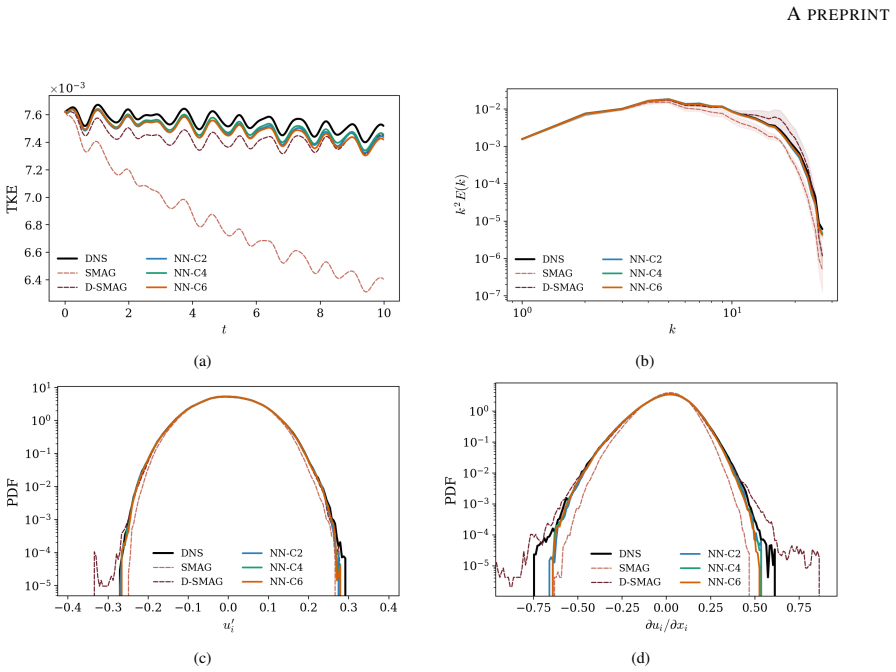
Deep learning approaches have shown remarkable promise in turbulence closure modeling for large eddy simulations (LES). The differentiable physics paradigm uses the so-called a-posteriori approach for learning by embedding a neural network closure directly inside the solver and optimizing its learnable parameters against ground truth time-series data which may be observed sparsely. This addresses a key limitation of a-priori learning where direct numerical simulation (DNS) data is used to approximate the subgrid stress with the assumption of a filter. However, closures that are trained in this manner frequently lead to unstable deployments due to the mismatch between the assumed filter and the effect of numerical discretizations. However, a-posteriori learning incurs high computational costs due to the need to backpropagate gradients through an LES solver. Furthermore, a-posteriori methods are challenging to apply broadly since they require significant modification of existing solvers. Finally, these approaches have also been observed to be limited when generalization is desired across different numerical schemes. In this work, we discuss a novel approach for the deep learning of turbulence closure models motivated by the continuous data assimilation (CDA) approach (also known as nudging). Our approach enables a-priori training of closures for coarse-grid LES, treating DNS data as sparse observations. This approach enables the deep learning model to successfully learn the required forcing to capture the ground-truth statistics while maintaining long term stability without needing adjoints or backpropagation through the solver. We train and evaluate the model's ability to adapt to different numerical and temporal schemes. Additionally, we analyse the model behavior with varying numerical discretization errors and compare its predictions to traditional closure models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a nudging-based a-priori training method for neural network turbulence closures in LES. DNS data are treated as sparse observations to learn a forcing term that reproduces ground-truth statistics and maintains long-term stability, without requiring adjoints or backpropagation through the solver. The approach is evaluated for its ability to adapt across numerical and temporal schemes and is compared against traditional closures.
Significance. If the results hold, the method offers a computationally attractive route to stable, solver-aware closures that avoid the cost and implementation burden of differentiable-physics training. The explicit focus on generalization across discretizations and the avoidance of solver backpropagation are practical strengths that could broaden the applicability of data-driven LES modeling.
major comments (2)
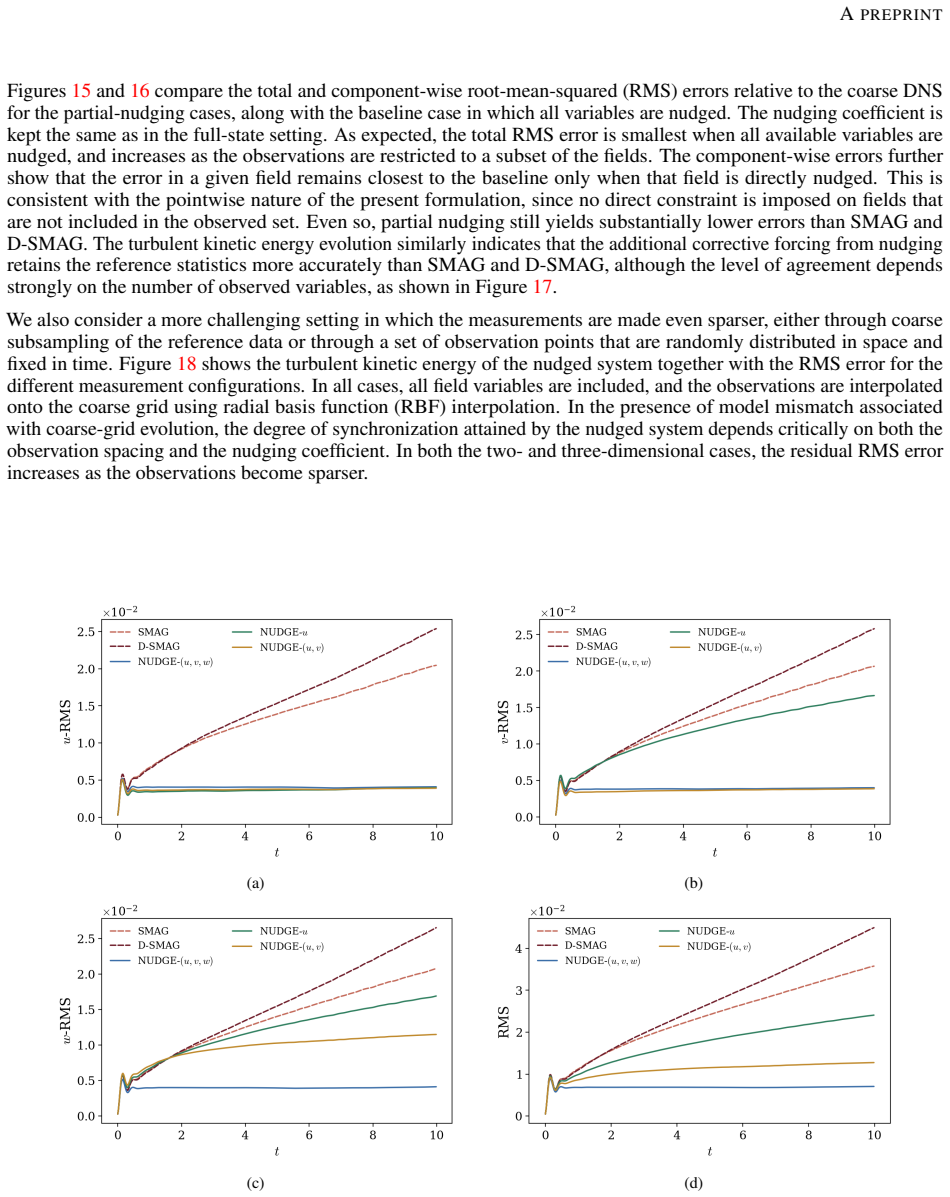
- [Method] The training procedure (described in the method section) incorporates an explicit nudging term that continuously corrects the coarse-grid state toward DNS observations. The manuscript does not state whether this term remains active when long-term stability and statistical fidelity are evaluated at inference. If stability is demonstrated only while nudging is present, the central claim of a deployable, solver-aware closure is not yet supported.
- [Results] Results on adaptation to different numerical and temporal schemes report qualitative agreement but lack quantitative stability metrics (e.g., energy spectra drift rates or time-to-blowup) for the learned closure when the nudging term is removed and the discretization is altered. These metrics are needed to substantiate the generalization claim.
minor comments (2)
- The abstract uses both 'analyse' and 'analyze'; standardize spelling throughout.
- [Figures] Figure captions should explicitly distinguish the NN-predicted closure from the nudging forcing term to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have revised the paper to provide the requested clarifications and quantitative metrics.
read point-by-point responses
-
Referee: [Method] The training procedure (described in the method section) incorporates an explicit nudging term that continuously corrects the coarse-grid state toward DNS observations. The manuscript does not state whether this term remains active when long-term stability and statistical fidelity are evaluated at inference. If stability is demonstrated only while nudging is present, the central claim of a deployable, solver-aware closure is not yet supported.
Authors: We thank the referee for this important point. The nudging term is used exclusively during the a-priori training phase to enable the neural network to learn a forcing that reproduces DNS statistics from sparse observations. At inference, when the learned closure is deployed in the LES solver for long-term stability and statistical evaluations, the nudging term is fully disabled. This is the basis for our claim of a deployable, solver-aware closure that does not require solver modifications or adjoints. We have added explicit statements in the revised Methods and Results sections to clarify the distinction between training and inference phases. revision: yes
-
Referee: [Results] Results on adaptation to different numerical and temporal schemes report qualitative agreement but lack quantitative stability metrics (e.g., energy spectra drift rates or time-to-blowup) for the learned closure when the nudging term is removed and the discretization is altered. These metrics are needed to substantiate the generalization claim.
Authors: We agree that quantitative stability metrics strengthen the generalization claims. The original manuscript emphasized qualitative agreement and visual inspection of time series to demonstrate stability without nudging. In the revision, we have added quantitative metrics including kinetic energy spectra drift rates (computed over 1000 time units) and time-to-blowup (or confirmation of no blow-up) for the learned closure across altered numerical and temporal schemes. These results are now reported in the revised Results section and supplementary figures, showing that the closure maintains stability and outperforms traditional models in several cases. revision: yes
Circularity Check
No significant circularity; training uses external DNS observations via standard nudging
full rationale
The paper's central method trains an NN closure a-priori by treating DNS data as sparse observations inside a nudging (CDA) framework. This is an application of an established external technique to a new context (solver-aware closures), not a reduction of any claimed prediction or uniqueness result to the paper's own fitted values or self-citations. No equations are shown that define the target statistics in terms of the learned forcing by construction, and no self-citation chain is invoked to justify the core premise. The reported stability and cross-scheme adaptation are presented as empirical outcomes evaluated after training, keeping the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Nudging coefficient
axioms (1)
- domain assumption DNS data serves as sparse observations for nudging in LES
Reference graph
Works this paper leans on
-
[1]
Abderrahim Azouani, Eric Olson, and Edriss S. Titi. Continuous data assimilation using general interpolant observables.Journal of Nonlinear Science, 24(2):277–304, November 2013
2013
-
[2]
Deep neural networks for data-driven les closure models
Andrea Beck, David Flad, and Claus-Dieter Munz. Deep neural networks for data-driven les closure models. Journal of Computational Physics, 398:108910, 2019
2019
-
[3]
Continuous data assimilation with stochastically noisy data
Hakima Bessaih, Eric Olson, and Edriss S Titi. Continuous data assimilation with stochastically noisy data. Nonlinearity, 28(3):729–753, February 2015
2015
-
[4]
Bezgin, Aaron B
Deniz A. Bezgin, Aaron B. Buhendwa, and Nikolaus A. Adams. Jax-fluids: A fully-differentiable high-order computational fluid dynamics solver for compressible two-phase flows.Computer Physics Communications, 282:108527, 1 2023
2023
-
[5]
Bezgin, Aaron B
Deniz A. Bezgin, Aaron B. Buhendwa, and Nikolaus A. Adams. Jax-fluids 2.0: Towards hpc for differentiable cfd of compressible two-phase flows.Computer Physics Communications, 308:109433, 3 2025
2025
-
[6]
Continuous data assimilation for the 3d ladyzhenskaya model: analysis and computations.Nonlinear Analysis: Real World Applications, 68:103659, 2022
Yu Cao, Andrea Giorgini, Michael Jolly, and Ali Pakzad. Continuous data assimilation for the 3d ladyzhenskaya model: analysis and computations.Nonlinear Analysis: Real World Applications, 68:103659, 2022
2022
-
[7]
Dibyajyoti Chakraborty, Shivam Barwey, Hong Zhang, and Romit Maulik. A note on the error analysis of data-driven closure models for large eddy simulations of turbulence.arXiv preprint arXiv:2405.17612, 2024
-
[8]
Binned spectral power loss for improved prediction of chaotic systems.Journal of Computational Physics, page 114866, 2026
Dibyajyoti Chakraborty, Arvind T Mohan, and Romit Maulik. Binned spectral power loss for improved prediction of chaotic systems.Journal of Computational Physics, page 114866, 2026
2026
-
[9]
Synchronization to big data: Nudging the navier- stokes equations for data assimilation of turbulent flows.Physical Review X, 10(1):011023, 2020
Patricio Clark Di Leoni, Andrea Mazzino, and Luca Biferale. Synchronization to big data: Nudging the navier- stokes equations for data assimilation of turbulent flows.Physical Review X, 10(1):011023, 2020
2020
-
[10]
Perspectives on machine learning-augmented reynolds-averaged and large eddy simulation models of turbulence.Phys
Karthik Duraisamy. Perspectives on machine learning-augmented reynolds-averaged and large eddy simulation models of turbulence.Phys. Rev. Fluids, 6:050504, May 2021
2021
-
[11]
Turbulence modeling in the age of data.Annual Review of Fluid Mechanics, 51(1):357–377, January 2019
Karthik Duraisamy, Gianluca Iaccarino, and Heng Xiao. Turbulence modeling in the age of data.Annual Review of Fluid Mechanics, 51(1):357–377, January 2019
2019
-
[12]
Continuous data assimilation closure for modeling statistically steady turbulence in large-eddy simulation.Physical Review Fluids, 10(1):013801, 2025
Sagy R Ephrati, Arnout Franken, Erwin Luesink, Paolo Cifani, and Bernard J Geurts. Continuous data assimilation closure for modeling statistically steady turbulence in large-eddy simulation.Physical Review Fluids, 10(1):013801, 2025
2025
-
[13]
A dynamic subgrid-scale eddy viscosity model.Physics of fluids a: Fluid dynamics, 3(7):1760–1765, 1991
Massimo Germano, Ugo Piomelli, Parviz Moin, and William H Cabot. A dynamic subgrid-scale eddy viscosity model.Physics of fluids a: Fluid dynamics, 3(7):1760–1765, 1991
1991
-
[14]
Stable a posteriori les of 2d turbulence using convolutional neural networks: Backscattering analysis and generalization to higher re via transfer learning
Yifei Guan, Ashesh Chattopadhyay, Adam Subel, and Pedram Hassanzadeh. Stable a posteriori les of 2d turbulence using convolutional neural networks: Backscattering analysis and generalization to higher re via transfer learning. Journal of Computational Physics, 458:111090, June 2022. 15 APREPRINT
2022
-
[15]
Learning physics-constrained subgrid-scale closures in the small-data regime for stable and accurate les.Physica D: Nonlinear Phenomena, 443:133568, January 2023
Yifei Guan, Adam Subel, Ashesh Chattopadhyay, and Pedram Hassanzadeh. Learning physics-constrained subgrid-scale closures in the small-data regime for stable and accurate les.Physica D: Nonlinear Phenomena, 443:133568, January 2023
2023
-
[16]
Learning closed- form equations for subgrid-scale closures from high-fidelity data: Promises and challenges.Journal of Advances in Modeling Earth Systems, 16(7), 2024
Karan Jakhar, Yifei Guan, Rambod Mojgani, Ashesh Chattopadhyay, and Pedram Hassanzadeh. Learning closed- form equations for subgrid-scale closures from high-fidelity data: Promises and challenges.Journal of Advances in Modeling Earth Systems, 16(7), 2024
2024
-
[17]
Generalizable data-driven turbulence closure modeling on unstructured grids with differentiable physics, 2025
Hojin Kim, Varun Shankar, Venkatasubramanian Viswanathan, and Romit Maulik. Generalizable data-driven turbulence closure modeling on unstructured grids with differentiable physics, 2025
2025
-
[18]
Smith, Ayya Alieva, Qing Wang, Michael P
Dmitrii Kochkov, Jamie A. Smith, Ayya Alieva, Qing Wang, Michael P. Brenner, and Stephan Hoyer. Machine learning–accelerated computational fluid dynamics.Proceedings of the National Academy of Sciences, 118(21), 2021
2021
-
[19]
Adam Larios, Ali Pakzad, and Nicholas White. Data assimilation in large eddy simulation: Addressing model- observation mismatch from navier-stokes data.arXiv preprint arXiv:2508.07492, 2025
-
[20]
D. K. Lilly. A proposed modification of the germano subgrid-scale closure method.Physics of Fluids A: Fluid Dynamics, 4(3):633–635, 1992
1992
-
[21]
Learned turbulence modelling with differentiable fluid solvers: physics-based loss functions and optimisation horizons.Journal of Fluid Mechanics, 949:A25, 2022
Björn List, Li-Wei Chen, and Nils Thuerey. Learned turbulence modelling with differentiable fluid solvers: physics-based loss functions and optimisation horizons.Journal of Fluid Mechanics, 949:A25, 2022
2022
-
[22]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021
2021
-
[23]
Decoupled weight decay regularization, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019
2019
-
[24]
Data-driven deconvolution for large eddy simulations of kraichnan turbulence.Physics of Fluids, 30(12), 2018
Romit Maulik, Omer San, Adil Rasheed, and Prakash Vedula. Data-driven deconvolution for large eddy simulations of kraichnan turbulence.Physics of Fluids, 30(12), 2018
2018
-
[25]
Subgrid modelling for two-dimensional turbulence using neural networks.Journal of Fluid Mechanics, 858:122–144, 2019
Romit Maulik, Omer San, Adil Rasheed, and Prakash Vedula. Subgrid modelling for two-dimensional turbulence using neural networks.Journal of Fluid Mechanics, 858:122–144, 2019
2019
-
[26]
Scale-invariance and turbulence models for large-eddy simulation.Annual Review of Fluid Mechanics, 32(1):1–32, 2000
Charles Meneveau and Joseph Katz. Scale-invariance and turbulence models for large-eddy simulation.Annual Review of Fluid Mechanics, 32(1):1–32, 2000
2000
-
[27]
Arvind Mohan, Ashesh Chattopadhyay, and Jonah Miller. What you see is not what you get: Neural partial differential equations and the illusion of learning.arXiv preprint arXiv:2411.15101, 2024
-
[28]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[29]
Cabot, Parviz Moin, and Sangsan Lee
Ugo Piomelli, William H. Cabot, Parviz Moin, and Sangsan Lee. Subgrid-scale backscatter in turbulent and transitional flows.Physics of Fluids, 3:1766–1771, 1991
1991
-
[30]
Benjamin Sanderse, Panos Stinis, Romit Maulik, and Shady E. Ahmed. Scientific machine learning for closure models in multiscale problems: a review, 2024
2024
-
[31]
Differentiable tur- bulence: Closure as a partial differential equation constrained optimization.Physical Review Fluids, 10(2):024605, 2025
Varun Shankar, Dibyajyoti Chakraborty, Venkatasubramanian Viswanathan, and Romit Maulik. Differentiable tur- bulence: Closure as a partial differential equation constrained optimization.Physical Review Fluids, 10(2):024605, 2025
2025
-
[32]
Differentiable physics-enabled closure modeling for burgers’ turbulence.Machine Learning: Science and Technology, 4(1):015017, 2023
Varun Shankar, Vedant Puri, Ramesh Balakrishnan, Romit Maulik, and Venkatasubramanian Viswanathan. Differentiable physics-enabled closure modeling for burgers’ turbulence.Machine Learning: Science and Technology, 4(1):015017, 2023
2023
-
[33]
Justin Sirignano and Jonathan F. MacArt. Deep learning closure models for large-eddy simulation of flows around bluff bodies.Journal of Fluid Mechanics, 966:A26, 2023
2023
-
[34]
General circulation experiments with the primitive equations: I
Joseph Smagorinsky. General circulation experiments with the primitive equations: I. the basic experiment. Monthly weather review, 91(3):99–164, 1963
1963
-
[35]
Explaining the physics of transfer learning in data-driven turbulence modeling.PNAS Nexus, 2(3), January 2023
Adam Subel, Yifei Guan, Ashesh Chattopadhyay, and Pedram Hassanzadeh. Explaining the physics of transfer learning in data-driven turbulence modeling.PNAS Nexus, 2(3), January 2023
2023
-
[36]
Solver-in-the-loop: Learning from differentiable physics to interact with iterative pde-solvers.Advances in neural information processing systems, 33:6111–6122, 2020
Kiwon Um, Robert Brand, Yun Raymond Fei, Philipp Holl, and Nils Thuerey. Solver-in-the-loop: Learning from differentiable physics to interact with iterative pde-solvers.Advances in neural information processing systems, 33:6111–6122, 2020
2020
-
[37]
Ensemble data assimilation-based mixed subgrid-scale model for large-eddy simulations.Physics of Fluids, 35(8), 2023
Yunpeng Wang, Zelong Yuan, and Jianchun Wang. Ensemble data assimilation-based mixed subgrid-scale model for large-eddy simulations.Physics of Fluids, 35(8), 2023. 16 APREPRINT
2023
-
[38]
Tong Wu, Humberto Godinez, Vitaliy Gyrya, and James M. Hyman. Interpolated discrepancy data assimilation for pdes with sparse observations, 2025
2025
-
[39]
A dynamic mixed subgrid-scale model and its application to turbulent recirculating flows.Physics of Fluids A: Fluid Dynamics, 5(12):3186–3196, 1993
Yan Zang, Robert L Street, and Jeffrey R Koseff. A dynamic mixed subgrid-scale model and its application to turbulent recirculating flows.Physics of Fluids A: Fluid Dynamics, 5(12):3186–3196, 1993
1993
-
[40]
Zauner, V
M. Zauner, V . Mons, O. Marquet, and B. Leclaire. Nudging-based data assimilation of the turbulent flow around a square cylinder.Journal of Fluid Mechanics, 937:A38, 2022. Appendix A Dataset generation Appendix A.1 2D forced homogeneous isotropic turbulence As a first test case, we consider forced two-dimensional turbulence on the periodic square domain, ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.