Recognition: unknown
Optimas: An Intelligent Analytics-Informed Generative AI Framework for Performance Optimization
Pith reviewed 2026-05-08 04:38 UTC · model grok-4.3
The pith
Optimas automates performance optimization by guiding LLMs with analytics to generate correct faster code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Optimas generates 100% correct code and improves performance in over 98.82% of 3,410 experiments on 10 benchmarks and two HPC mini-applications, with average gains of 8.02% to 79.09% on NVIDIA GPUs, by using LLMs to map performance diagnostics to literature-backed transformations in a unified pipeline.
What carries the argument
Optimas multi-agent workflow that unifies performance insight extraction, LLM-based code generation from diagnostics, execution, and validation.
Load-bearing premise
That large language models can reliably map performance diagnostics to correct code transformations without missing edge cases or introducing subtle bugs.
What would settle it
Testing the framework on additional untested applications and observing cases of incorrect code or zero performance gain would disprove the reliability claims.
Figures


read the original abstract
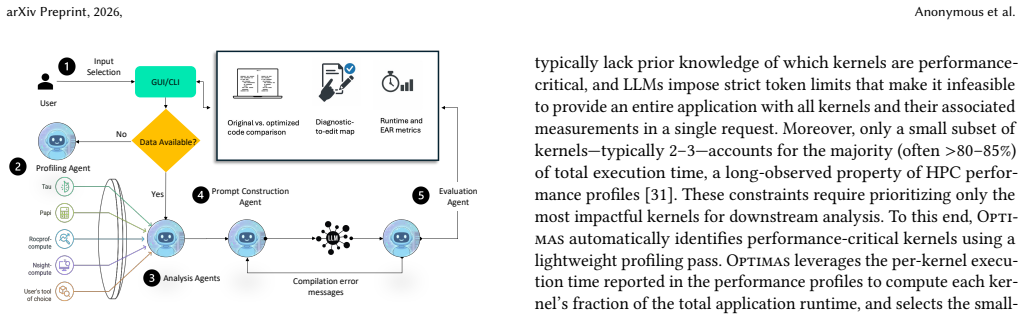
Large language models (LLMs) show promise for automated code optimization. However, without performance context, they struggle to produce correct and effective code transformations. Existing performance tools can identify bottlenecks but stop short of generating actionable code changes. Consequently, performance optimization continues to be a time-intensive and manual endeavor, typically undertaken only by experts with detailed architectural understanding. To bridge this gap, we introduce Optimas, a modular, fully automated, end-to-end generative AI framework built on a multi-agent workflow. Optimas uses LLMs to map performance diagnostics from multiple reports to established, literature-backed code transformations, while unifying insight extraction, code generation, execution, and validation within a single pipeline. Across 3,410 real-world experiments on 10 benchmarks and two HPC mini-applications, Optimas generates 100% correct code and improves performance in over 98.82% of those experiments, achieving average gains of 8.02%-79.09% on NVIDIA GPUs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Optimas, a modular multi-agent generative AI framework that uses LLMs to map performance diagnostics from multiple reports to established, literature-backed code transformations. It unifies insight extraction, code generation, execution, and validation in a single pipeline. The central empirical claim is that across 3,410 experiments on 10 benchmarks and two HPC mini-applications, the framework generates 100% correct code and improves performance in over 98.82% of cases, with average gains of 8.02%-79.09% on NVIDIA GPUs.
Significance. If the reported correctness and performance results hold under rigorous validation, Optimas could meaningfully advance automated performance optimization in HPC and GPU computing by bridging diagnostic tools with generative models. The modular multi-agent design and grounding in literature-backed transformations are strengths that support reproducibility and credibility. The scale of the experimental evaluation (3,410 runs) is notable and, if properly documented, would strengthen the case for practical impact.
major comments (2)
- [Abstract] Abstract: The claim of 100% correct code generation across 3,410 experiments is load-bearing for the central contribution. The abstract states that Optimas unifies generation with validation but provides no description of the validation procedure (e.g., full test-suite execution, differential output checking on held-out inputs, compilation/runtime success only, or semantic equivalence checking). Without this detail, subtle behavioral alterations cannot be ruled out, directly undermining both the correctness rate and the reported performance gains.
- [Abstract] Abstract and Experimental Evaluation: No information is given on how the LLM agents select specific transformations from the literature or on the baselines used for comparison (e.g., standard compiler flags, existing auto-tuners, or manual expert optimizations). This absence makes it impossible to assess whether the reported gains of 8.02%-79.09% are attributable to the framework or to other factors, weakening the evaluation of the approach's effectiveness.
minor comments (1)
- The manuscript should include full details on the specific LLM models, prompt templates, temperature settings, and exact benchmark versions used to enable reproducibility of the 3,410 experiments.
Simulated Author's Rebuttal
We appreciate the referee's positive evaluation of Optimas's potential impact and the comprehensive nature of our experiments. We have reviewed the major comments and will make revisions to enhance the clarity of the abstract and experimental details as outlined below.
read point-by-point responses
-
Referee: The claim of 100% correct code generation across 3,410 experiments is load-bearing for the central contribution. The abstract states that Optimas unifies generation with validation but provides no description of the validation procedure (e.g., full test-suite execution, differential output checking on held-out inputs, compilation/runtime success only, or semantic equivalence checking). Without this detail, subtle behavioral alterations cannot be ruled out, directly undermining both the correctness rate and the reported performance gains.
Authors: We agree that the abstract would benefit from a brief description of the validation procedure to support the 100% correctness claim. The manuscript describes validation as an integrated step in the pipeline involving code execution and verification for correctness. We will revise the abstract to include a concise summary of this procedure, specifying that it encompasses test execution and equivalence checking. This change will clarify how behavioral alterations are ruled out and strengthen the central claim. revision: yes
-
Referee: No information is given on how the LLM agents select specific transformations from the literature or on the baselines used for comparison (e.g., standard compiler flags, existing auto-tuners, or manual expert optimizations). This absence makes it impossible to assess whether the reported gains of 8.02%-79.09% are attributable to the framework or to other factors, weakening the evaluation of the approach's effectiveness.
Authors: We acknowledge that explicit details on the transformation selection process and baselines would improve the evaluation. The multi-agent design maps diagnostics to literature-backed transformations via agent reasoning, and experiments use standard compiler optimizations as a baseline. We will revise the abstract and expand the experimental evaluation section to describe the selection mechanism and explicitly list the baselines, enabling better assessment of the reported gains. revision: yes
Circularity Check
No circularity: results are direct empirical measurements
full rationale
The paper describes a multi-agent LLM framework for code optimization and reports outcomes from 3,410 direct experiments on benchmarks and mini-applications. Claims of 100% correctness and performance gains are presented as observed results from running the pipeline, not as predictions or derivations that reduce to fitted parameters, self-definitions, or self-citation chains. No equations, ansatzes, uniqueness theorems, or load-bearing self-citations appear in the abstract or described methodology. The evaluation is self-contained against external benchmarks and test suites, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can map performance diagnostics to established code transformations without errors
Reference graph
Works this paper leans on
-
[1]
[n. d.]. cub::DeviceAdjacentDifference — CUDA Core Compute Libraries. https: //nvidia.github.io/cccl/cub/api/structcub_1_1DeviceAdjacentDifference.html. Ac- cessed: April 28, 2026
2026
-
[2]
Technical Report
2023.Nsight Compute Profiling Guide. Technical Report. NVIDIA
2023
-
[3]
A Mess of Memory System Benchmarking, Simulation and Application Profiling.arXiv(2024)
2024. A Mess of Memory System Benchmarking, Simulation and Application Profiling.arXiv(2024). arXiv:2405.10170
-
[4]
Advanced Micro Devices, Inc. 2024. MI200 Performance Counters and Met- rics. https://rocm.docs.amd.com/en/docs-6.0.0/conceptual/gpu-arch/mi200- performance-counters.html. Accessed: 2025-04-14
2024
- [5]
-
[6]
Jason Ansel, Shoaib Kamil, Jonathan Ragan-Kelley Wong Chan, Kalyan Veera- machaneni, Lukasz Ziarek, Saman Amarasinghe, and Martin C O’Reilly. 2014. OpenTuner: An extensible framework for program autotuning. InPACT. 303–316. doi:10.1145/2628071.2628092
-
[7]
Banooqa Banday, Kowshik Thopalli, Tanzima Z Islam, and Jayaraman J Thiagara- jan. 2025. On the role of prompt construction in enhancing efficacy and efficiency of llm-based tabular data generation. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2025
-
[8]
Tania Banerjee, Jason Hackl, Mrugesh Shringarpure, Tanzima Islam, S Bal- achandar, Thomas Jackson, and Sanjay Ranka. 2016. CMT-Bone — A Proxy Application for Compressible Multiphase Turbulent Flows.IEEE 23rd Interna- tional Conference on High Performance Computing (HiPC)(Dec 2016), 173–182. doi:10.1109/HiPC.2016.029 Acceptance rate: 23%
-
[9]
Milind Chabbi, Karthik Murthy, Michael Fagan, and John Mellor-Crummey. 2013. Effective sampling-driven performance tools for GPU-accelerated supercomput- ers. InProceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis. 1–12
2013
-
[10]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review arXiv 2021
-
[11]
Neal C Crago, Mark Stephenson, and Stephen W Keckler. 2018. Exposing memory access patterns to improve instruction and memory efficiency in GPUs.ACM Transactions on Architecture and Code Optimization (TACO)15, 4 (2018), 1–23
2018
-
[12]
Chris Cummins, Volker Seeker, Dejan Grubisic, Baptiste Roziére, Jonas Gehring, Gabriel Synnaeve, and Hugh Leather. 2025. LLM Compiler: Foundation Language Models for Compiler Optimization. InCC 2025. 141–153
2025
-
[13]
Tom Deakin, James Price, Matt Martineau, and Simon McIntosh-Smith. 2018. Evaluating attainable memory bandwidth of parallel programming models via BabelStream.International Journal of Computational Science and Engineering17, 3 (2018), 247–262. doi:10.1504/IJCSE.2018.095847 Special issue
-
[14]
Weihua Du, Yiming Yang, and Sean Welleck. 2025. Optimizing Temperature for Language Models with Multi-Sample Inference. InProceedings of the International Conference on Machine Learning (ICML)
2025
-
[15]
M. F. I. Ibrahim and A. A. Al-Jumaily. 2016. PCA indexing based feature learning and feature selection. In2016 8th Cairo International Biomedical Engineering Conference (CIBEC). 68–71
2016
-
[16]
Aleksandar Ilic, Frederico Pratas, and Leonel Sousa. 2014. Cache-aware Roofline Model: Upgrading the Loft.IEEE Comput. Archit. Lett.13, 1 (Jan. 2014), 21–24
2014
-
[17]
Tanzima Islam, Alexis Ayala, Quentin Jensen, and Khaled Ibrahim. 2019. Toward a Programmable Analysis and Visualization Framework for Interactive Perfor- mance Analytics. In2019 IEEE/ACM International Workshop on Programming and Performance Visualization Tools (ProTools). IEEE, 70–77
2019
-
[18]
Tanzima Islam, Alexis Ayala, Quentin Jensen, and Khaled Ibrahim. 2019. Toward a Programmable Analysis and Visualization Framework for Interactive Perfor- mance Analytics. In2019 IEEE/ACM International Workshop on Programming and Performance Visualization Tools (ProTools). 70–77. doi:10.1109/ProTools49597. 2019.00015
-
[19]
Islam, A
Tanzima Z. Islam, A. Ayala, and Q. Jensen. [n. d.]. Dashing–A Machine Learning Toolkit for HPC Performance Analysis. https://github.com/tzislam/Dashing
-
[20]
Tanzima Z Islam, Aniruddha Marathe, Holland Schutte, and Mohammad Zaeed
-
[21]
Accepted
Data-Driven Analysis to Understand GPU Hardware Resource Usage of Optimizations.International Journal High Performance Computing Applications (IJHPCA). Accepted
-
[22]
Tanzima Z Islam, Jayaraman J Thiagarajan, Abhinav Bhatele, Martin Schulz, and Todd Gamblin. 2016. A machine learning framework for performance coverage analysis of proxy applications. InSC’16: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 538– 549
2016
-
[23]
Zheming Jin and Jeffrey S. Vetter. 2023. A Benchmark Suite for Improving Per- formance Portability of the SYCL Programming Model. In2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). 325–327. doi:10.1109/ISPASS57527.2023.00041
-
[24]
Ibrahim, Samuel Williams, Leonid Oliker
Khaled Z. Ibrahim, Samuel Williams, Leonid Oliker. 2018. Roofline Scaling Trajec- tories: A Method for Parallel Application and Architectural Performance Analysis. InInternational Conference on High Performance Computing & Simulation (HPCS)
2018
- [25]
-
[26]
Jongmin Lee, Kwangho Lee, Mucheol Kim, Geunchul Park, and Chan Yeol Park
-
[27]
Roofline-based Data Migration Methodology for Hybrid Memories.Journal of Internet Technology21, 3 (2020), 849–859
2020
-
[28]
Matthew Leinhauser, René Widera, Sergei Bastrakov, Alexander Debus, Michael Bussmann, and Sunita Chandrasekaran. 2022. Metrics and design of an instruction roofline model for AMD GPUs.ACM Transactions on Parallel Computing9, 1 (2022)
2022
-
[29]
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. 2023. StarCoder: May the source be with you!arXiv preprint arXiv:2305.06161(2023). https://arxiv.org/abs/2305.06161
work page internal anchor Pith review arXiv 2023
- [30]
- [31]
-
[32]
Mitesh R Meswani, Laura Carrington, Allan Snavely, and Stephen Poole. 2012. Tools for benchmarking, tracing, and simulating SHMEM applications. InPro- ceedings Cray user group conference (CUG)
2012
-
[33]
Naderan-Tahan et al
M. Naderan-Tahan et al. 2021. Top-Down GPU-Compute Benchmarking using Real-Life Applications. InIEEE International Symposium on Workload Characteri- zation (IISWC)
2021
-
[34]
Daniel Nichols, Aniruddha Marathe, Harshitha Menon, Todd Gamblin, and Abhi- nav Bhatele. 2024. HPC-Coder: Modeling Parallel Programs using Large Language Models. arXiv/ISC preprint. (2024). https://pssg.cs.umd.edu/assets/papers/2024- 05-hpc-llm-isc.pdf
2024
-
[35]
Daniel Nichols, Pranav Polasam, Harshitha Menon, Aniruddha Marathe, Todd Gamblin, and Abhinav Bhatele. 2024. Performance-Aligned LLMs for Generating Fast Code. arXiv preprint. (2024). https://pssg.cs.umd.edu/assets/papers/2024- 04-rlpf-arxiv.pdf
2024
-
[36]
NVIDIA Corporation. 2024. CUDA C++ Best Practices Guide. https://docs.nvidia. com/cuda/cuda-c-best-practices-guide/
2024
-
[37]
Kernelbench: Can llms write efficient gpu kernels?arXiv preprint arXiv:2502.10517,
Anne Ouyang, Simon Guo, Simran Arora, Alex L. Zhang, William Hu, Christopher Reé, and Azalia Mirhoseini. 2025. KernelBench: Can LLMs Write Efficient GPU Kernels?arXiv preprint arXiv:2502.10517(2025). https://arxiv.org/abs/2502.10517
-
[38]
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiao- qing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2023. Code Llama: Open Foundation Models for Code.arXiv preprint arXiv:2308.12950 (2023). https://arxiv.org/abs/2308.12950
work page internal anchor Pith review arXiv 2023
-
[39]
Adam Thompson. 2021. Accelerated Signal Processing with cuSignal. NVIDIA Technical Blog. https://developer.nvidia.com/blog/accelerated-signal-processing- with-cusignal/ (accessed: April 28, 2026)
2021
-
[40]
John Tramm, Andrew Siegel, Tanzima Islam, and Martin Schulz. 2014. XSBench: the development and verification of a performance abstraction for Monte Carlo reactor analysis. InPHYSOR
2014
-
[41]
Leif Uhsadel, Andy Georges, and Ingrid Verbauwhede. 2008. Exploiting hardware performance counters. In2008 5th Workshop on Fault Diagnosis and Tolerance in Cryptography. IEEE, 59–67
2008
-
[42]
S Williams, A Waterman, and D Patterson. 2009. Roofline: Aninsightful vi- sual performance model for floating-point programsand multicore architectures. Communications of theAssociation for Computing Machinery(2009)
2009
-
[43]
Xingfu Wu, Valerie Taylor, and Zhiling Lan. 2021. Performance and energy im- provement of ECP proxy app SW4lite under various workloads. In2021 IEEE/ACM Workshop on Memory Centric High Performance Computing (MCHPC). IEEE, 17– 24. arXiv Preprint, 2026, Anonymous et al
2021
-
[44]
Mohammad Zaeed, Tanzima Z Islam, and Vladimir Indict. 2024. Characterize and Compare the Performance of Deep Learning Optimizers in Recurrent Neu- ral Network Architectures. In2024 IEEE 48th Annual Computers, Software, and Applications Conference (COMPSAC). IEEE, 39–44
2024
-
[45]
Hang Zhou, Yehui Tang, Haochen Qin, Yujie Yang, Renren Jin, Deyi Xiong, Kai Han, and Yunhe Wang. 2024. Star-Agents: Automatic Data Optimization with LLM Agents for Instruction Tuning.Advances in Neural Information Processing Systems37 (2024), 4575–4597
2024
-
[46]
Keren Zhou, Laksono Adhianto, Jonathon Anderson, Aaron Cherian, Dejan Gru- bisic, Mark Krentel, Yumeng Liu, Xiaozhu Meng, and John Mellor-Crummey. 2021. Measurement and analysis of GPU-accelerated applications with HPCToolkit. Parallel Comput.108 (2021), 102837
2021
-
[47]
Keren Zhou, Mark W Krentel, and John Mellor-Crummey. 2020. Tools for top- down performance analysis of GPU-accelerated applications. InProceedings of the 34th ACM International Conference on Supercomputing. 1–12
2020
-
[48]
st.global.cg.f32
Keren Zhou, Xiaozhu Meng, Ryuichi Sai, and John Mellor-Crummey. 2021. Gpa: A gpu performance advisor based on instruction sampling. In2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). IEEE, 115– 125. A Prompt for theaccuracyapplication Below is a fully instantiated example of the prompt for theAccu- racykernel, precisely ref...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.