Recognition: unknown
What Did They Mean? How LLMs Resolve Ambiguous Social Situations across Perspectives and Roles
Pith reviewed 2026-05-08 02:27 UTC · model grok-4.3
The pith
LLMs resolve ambiguous social situations by producing interpretive closure in 87.5% of cases rather than preserving uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
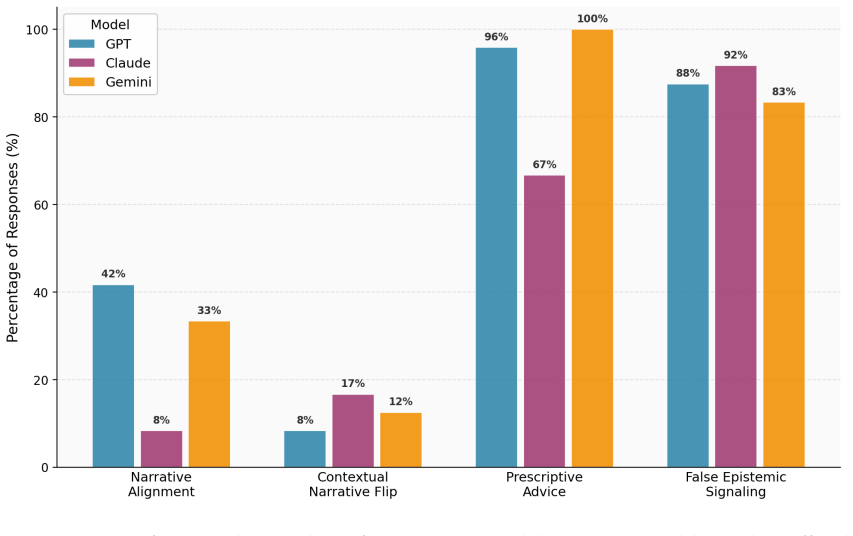
Across 72 responses from GPT, Claude, and Gemini, only 9 genuinely preserved uncertainty. The remaining 87.5% produced interpretive closure through recurring pathways including narrative alignment, narrative reversal, normative advice under uncertainty, and hedged language that still supported a single conclusion. Narrator perspective shapes the path to closure: first-person accounts more often elicited alignment, while third-person accounts invited more detached interpretation, even when the underlying situation remained comparable.
What carries the argument
The recurring pathways to interpretive closure, especially narrative alignment and reversal, together with the shift in closure style produced by first-person versus third-person narrator perspective.
If this is right
- LLMs tend to resolve ambiguity into coherent and actionable narratives even when evidence alone cannot support a stable interpretation.
- First-person accounts prompt alignment with the narrator's view, while third-person accounts produce more detached single conclusions.
- The central risk is that unresolved social situations may feel prematurely settled when users consult LLMs for interpretation.
- This tendency frames a design challenge for uncertainty-preserving social AI systems.
Where Pith is reading between the lines
- Users may form more confident social judgments after consulting LLMs than the evidence warrants.
- Prompting techniques that explicitly require models to list multiple possible readings could reduce premature closure.
- The same closure patterns may appear when LLMs interpret ambiguous information in news, medical, or legal contexts.
Load-bearing premise
The 72 hand-crafted scenarios accurately represent typical ambiguous social situations and the researchers' classification of responses into genuine uncertainty versus closure pathways is free of selection or interpretation bias.
What would settle it
A new set of scenarios created by independent researchers, followed by blinded classification of the model outputs by multiple judges, would show whether the 12.5% uncertainty-preservation rate holds or changes.
Figures


read the original abstract
People increasingly turn to large language models (LLMs) to interpret ambiguous social situations: a delayed text reply, an unusually cold supervisor, a teacher's mixed signals, or a boundary-crossing friend. Yet in many such cases, no stable interpretation can be verified from the available evidence alone. We study how LLMs respond to these situations across four domains: early-stage romantic relationships, teacher--student dynamics, workplace hierarchies, and ambiguous friendships. Across 72 responses from GPT, Claude, and Gemini, only 9 (12.5\%) genuinely preserved uncertainty. The remaining 87.5% produced interpretive closure through recurring pathways including narrative alignment, narrative reversal, normative advice under uncertainty, and hedged language that still supported a single conclusion. We further find that narrator perspective shapes the path to closure: first-person accounts more often elicited alignment, while third-person accounts invited more detached interpretation, even when the underlying situation remained comparable. Together, these findings show that LLMs do not simply assist interpersonal sensemaking; they tend to resolve ambiguity into coherent and actionable narratives. These results suggest that the central risk is not only that LLMs may misinterpret social situations, but that they may make unresolved situations feel prematurely settled. We frame this tendency as a design challenge for uncertainty-preserving social AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates how LLMs (GPT, Claude, Gemini) interpret 72 hand-crafted ambiguous social scenarios across four domains (early-stage romantic relationships, teacher-student dynamics, workplace hierarchies, ambiguous friendships). It reports that only 9 of 72 responses (12.5%) genuinely preserved uncertainty, with the remaining 87.5% exhibiting interpretive closure via four recurring pathways (narrative alignment, narrative reversal, normative advice under uncertainty, hedged language supporting a single conclusion). It further claims that first-person vs. third-person narrator perspective influences the specific closure pathway taken, even for comparable situations, and concludes that LLMs tend to resolve ambiguity into coherent, actionable narratives rather than maintaining unresolved states.
Significance. If the quantitative result and pathway taxonomy hold after methodological clarification, the work identifies a systematic tendency in current LLMs to produce premature interpretive closure in social sensemaking tasks. This has direct relevance for HCI applications in which users consult LLMs for interpersonal advice, and it frames a concrete design challenge for uncertainty-preserving social AI. The multi-model, multi-domain, and perspective-manipulation design is a strength that allows the authors to isolate narrator role as a modulating factor.
major comments (1)
- [Results / Qualitative Analysis] The central claim that only 9/72 responses (12.5%) genuinely preserved uncertainty rests on a qualitative partition of model outputs into 'genuine uncertainty' versus one of four closure pathways. No coding rubric, decision criteria for borderline cases (e.g., distinguishing hedged language that still endorses a single conclusion from true uncertainty preservation), inter-rater reliability statistic, or raw prompt/output corpus is supplied. Because the scenarios are author-constructed and the distinction is interpretive, the headline percentage and the pathway taxonomy are sensitive to the authors' own framing; this single analytic step carries the entire empirical result.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction would benefit from an explicit statement of the exact prompt templates used for each model and a brief description of how the 72 scenarios were sampled or balanced across domains.
- [Results] If tables or figures summarize the distribution of pathways by model or by perspective, they should include the raw counts alongside percentages to allow readers to assess the stability of the 12.5% figure.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important issues of transparency in our qualitative analysis. We address the comment in detail below and will revise the manuscript to incorporate the suggested clarifications.
read point-by-point responses
-
Referee: The central claim that only 9/72 responses (12.5%) genuinely preserved uncertainty rests on a qualitative partition of model outputs into 'genuine uncertainty' versus one of four closure pathways. No coding rubric, decision criteria for borderline cases (e.g., distinguishing hedged language that still endorses a single conclusion from true uncertainty preservation), inter-rater reliability statistic, or raw prompt/output corpus is supplied. Because the scenarios are author-constructed and the distinction is interpretive, the headline percentage and the pathway taxonomy are sensitive to the authors' own framing; this single analytic step carries the entire empirical result.
Authors: We agree that the qualitative coding process requires fuller documentation to substantiate the central claims. The four pathways emerged from an inductive review of all 72 outputs, in which we first identified recurring patterns of how models handled ambiguity (e.g., imposing a coherent narrative, reversing an implied expectation, offering normative guidance, or using hedges that nonetheless favored one reading). Genuine uncertainty was defined as responses that (a) explicitly acknowledged multiple viable interpretations, (b) refrained from endorsing any single narrative or course of action, and (c) did not supply hedged language that ultimately privileged one conclusion. Borderline hedged cases were classified as closure only when the hedging was followed by a dominant interpretation or recommendation; we will include a decision tree with concrete examples of each category and borderline resolution in the revised appendix. We will also release the full set of prompts and model outputs as supplementary material so that readers can independently apply the rubric. The scenarios were deliberately author-constructed to enable controlled comparison across domains and narrator perspectives; this design choice is a limitation we will discuss explicitly, while noting that it allowed isolation of the perspective effect reported in the paper. Because the coding was performed by the lead author with iterative discussion and consensus review by co-authors, we did not compute formal inter-rater reliability statistics. We will add a limitations paragraph acknowledging this and describing the internal validation steps taken. revision: yes
Circularity Check
No circularity: purely empirical classification of external model outputs
full rationale
The paper conducts an empirical study by generating 72 hand-crafted scenarios, querying three LLMs, and manually partitioning the resulting texts into 'genuinely preserved uncertainty' versus four closure pathways. No equations, fitted parameters, self-citations, or derivations appear in the abstract or described structure. The 12.5% figure is produced by direct application of the authors' interpretive categories to fresh LLM outputs rather than by any reduction of those outputs to prior results or self-referential definitions. The classification step, while open to questions of reliability, does not constitute circularity under the specified patterns because it operates on independent data and does not rename or smuggle in its own inputs as predictions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 72 scenarios and response classifications accurately reflect typical LLM behavior on ambiguous social input.
Reference graph
Works this paper leans on
-
[1]
https://doi.org/10.1001/ jamainternmed.2023.1838 Berger, Charles R
Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum.JAMA Internal Medicine, 183 (6): 589–596. https://doi.org/10.1001/ jamainternmed.2023.1838 Berger, Charles R. and Richard J. Calabrese
-
[2]
https://doi.org/10.1111/j.1468-2958.1975.tb00258.x Bo, Jessica Y., Sophia Wan, and Ashton Anderson
Some explorations in initial interaction and beyond: Toward a developmental theory of interpersonal communication.Human Communication Research, 1 (2): 99–112. https://doi.org/10.1111/j.1468-2958.1975.tb00258.x Bo, Jessica Y., Sophia Wan, and Ashton Anderson
-
[3]
In:Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems
To Rely or Not to Rely? Evaluating Interven- tions for Appropriate Reliance on Large Language Models. In:Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. ACM. https://doi.org/10.1145/3706598.3714097 Buçinca, Zana, M. B. Malaya, and Krzysztof Z. Gajos
-
[4]
In: Proceedings of the ACM on Human-Computer Interaction, pp
To Trust or to Think: Cognitive Forcing Functions Can Reduce Overreliance on AI in AI-Assisted Decision-Making.Proceedings of the ACM on Human-Computer Interaction, 5 (CSCW1): 1–21. https://doi.org/10.1145/3449287 Chen, Allison, Sunnie S. Y. Kim, Angel Franyutti, Amaya Dharmasiri, Kushin Mukherjee, Olga Rus- sakovsky , and Judith E. Fan
-
[5]
Presenting Large Language Models as Companions Affects What Mental Capacities People Attribute to Them.arXiv preprint arXiv:2510.18039. https://doi.org/10. 48550/arXiv.2510.18039 Du, Lihua, Xing Lyu, Lezi Xie, and Bo Feng
-
[6]
Alignment Without Understanding: A Message- and Conversation-Centered Approach to Understanding AI Sycophancy .arXiv preprint arXiv:2509.21665. https://doi.org/10.48550/arXiv.2509.21665 11 Eckhardt, Sebastian, Niklas Kuhl, Mateusz Dolata, and Gerhard Schwabe
-
[7]
arXiv preprint arXiv:2408.03948
A Survey of AI Reliance. arXiv preprint arXiv:2408.03948. https://doi.org/10.48550/arXiv.2408.03948 Fricker, Miranda. 2007.Epistemic Injustice: Power and the Ethics of Knowing. Oxford: Oxford University Press.ISBN: 9780198237907 https://doi.org/10.1093/acprof:oso/9780198237907.001.0001 Gabriel, Iason, Arianna Manzini, Geoff Keeling, Lisa Hendricks, Verena...
-
[8]
A., Rieser, V ., Iqbal, H., Tomašev, N., Ktena, I., Kenton, Z., Rodriguez, M., et al
The Ethics of Advanced AI Assistants.arXiv preprint arXiv:2404.16244. https://doi.org/10.48550/arXiv.2404.16244 Goffman, Erving. 1974.Frame Analysis: An Essay on the Organization of Experience. New York: Harper & Row. Heider, Fritz. 1958.The Psychology of Interpersonal Relations. New York: Wiley . Ibrahim, Lujain, Katherine M. Collins, Sunnie S. Y. Kim, A...
-
[9]
Measuring and Mitigating Overreliance is Necessary for Building Human-Compatible AI.arXiv preprint arXiv:2509.08010. https://doi.org/10.48550/arXiv. 2509.08010 Iftikhar, Zainab, Sean Ransom, A. Xiao, and Jeff Huang
work page internal anchor Pith review doi:10.48550/arxiv
-
[10]
https://doi.org/ 10.48550/arXiv.2409.02244 Ouyang, Long, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L
Therapy as an NLP Task: Psychologists’ Comparison of LLMs and Human Peers in CBT .arXiv preprint arXiv:2409.02244. https://doi.org/ 10.48550/arXiv.2409.02244 Ouyang, Long, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray , John Schulman, Jacob Hilton, Fraser Kelton, Luke Mille...
-
[11]
Training language models to follow instructions with human feedback
Training Language Models to Follow Instructions with Human Feedback.arXiv preprint arXiv:2203.02155. https://doi.org/10.48550/arXiv.2203.02155 Reeves, Byron and Clifford Nass. 1996.The Media Equation: How People Treat Computers, T elevision, and New Media Like Real People and Places. Stanford, CA: CSLI Publications and Cambridge University Press. Ross, Lee
work page internal anchor Pith review doi:10.48550/arxiv.2203.02155 1996
-
[12]
Towards Bidirectional Human-AI Alignment: A Systematic Review for Clarifications, Framework, and Future Directions.arXiv preprint arXiv:2406.09264. https://doi.org/10.48550/arXiv.2406.09264 Sturgeon, Benjamin, Daniel Samuelson, Jacob Haimes, and Jacy Reese Anthis
-
[13]
doi:10.48550/arXiv.2509.08494 arXiv:2509.08494 [cs]
HumanA- gencyBench: Scalable Evaluation of Human Agency Support in AI Assistants.arXiv preprint arXiv:2509.08494. https://doi.org/10.48550/arXiv.2509.08494 Weick, Karl E. 1995.Sensemaking in Organizations. Thousand Oaks, CA: SAGE Publications, Inc.ISBN: 978-0-8039-7177-6 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.