Recognition: unknown
LearnPruner: Rethinking Attention-based Token Pruning in Vision Language Models
Pith reviewed 2026-05-08 04:37 UTC · model grok-4.3
The pith
LearnPruner prunes vision tokens in vision-language models to 5.5 percent while preserving 95 percent performance and achieving 3.2 times faster inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that by applying a learnable pruning module immediately after the vision encoder to remove redundant vision tokens and then using text-to-vision attention scores from the middle layers of the large language model to keep only the task-relevant ones, vision-language models can retain about 95 percent of their original performance while operating on just 5.5 percent of the vision tokens and running 3.2 times faster during inference.
What carries the argument
The two-stage LearnPruner framework consisting of a learnable pruning module post-vision-encoder for initial redundancy removal and middle-layer text-to-vision attention for task-specific token retention.
If this is right
- If the central claim holds, vision-language models could scale to longer visual sequences or higher resolutions with manageable compute costs.
- The accuracy-efficiency trade-off improves over prior methods that rely solely on attention from either the encoder or the full LLM.
- Inference acceleration of 3.2 times becomes achievable without major retraining of the base model.
- Pruning can be made more robust by separating the handling of general redundancy from task-specific importance.
Where Pith is reading between the lines
- The method might be adapted to prune tokens in other multimodal architectures like audio-visual models.
- If middle-layer attention is key, developers could design models with lighter early layers to save more computation upfront.
- This staged approach could be combined with quantization or other efficiency techniques for even greater gains.
- Further work might test whether the learnable module can be made architecture-agnostic for plug-and-play use.
Load-bearing premise
The learnable pruning module generalizes well across different tasks and base models without overfitting to the training data, and middle-layer attention scores stay effective indicators of importance after early pruning steps.
What would settle it
Running LearnPruner on a different vision-language model or on a task not seen during its training and observing that performance falls significantly below 95 percent of the full model at the 5.5 percent token level would disprove the generality of the approach.
Figures





read the original abstract
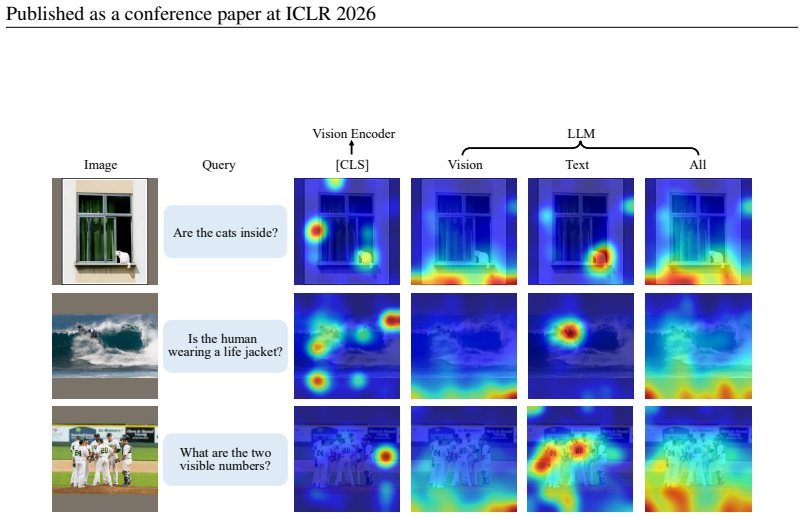
Vision-Language Models (VLMs) have recently demonstrated remarkable capabilities in visual understanding and reasoning, but they also impose significant computational burdens due to long visual sequence inputs. Recent works address this issue by pruning unimportant visual tokens, achieving substantial computational reduction while maintaining model performance. The core of token pruning lies in determining token importance, with current approaches primarily relying on attention scores from vision encoders or Large Language Models (LLMs). In this paper, we analyze the effectiveness of attention mechanisms in both vision encoders and LLMs. We find that vision encoders suffer from attention sink, leading to poor focus on informative foreground regions, while in LLMs, although prior studies have identified attention bias toward token positions, text-to-vision attention demonstrates resistance to this bias and enables effective pruning guidance in middle layers. Based on these observations, we propose LearnPruner, a two-stage token pruning framework that first removes redundant vision tokens via a learnable pruning module after the vision encoder, then retains only task-relevant tokens in the LLM's middle layer. Experimental results show that our LearnPruner can preserve approximately 95% of the original performance while using only 5.5% of vision tokens, and achieve 3.2$\times$ inference acceleration, demonstrating a superior accuracy-efficiency trade-off.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes attention behaviors in VLMs, observing attention sink in vision encoders and positional-bias resistance in middle-layer text-to-vision attention of LLMs. It proposes LearnPruner, a two-stage pruning method: a learnable module prunes redundant vision tokens immediately after the vision encoder, after which middle-layer text-to-vision attention scores select task-relevant tokens for the LLM. Experiments report retention of ~95% original performance at 5.5% vision tokens with 3.2× inference speedup, claiming a superior accuracy-efficiency trade-off over prior attention-based pruning approaches.
Significance. If the reported trade-off holds under standard controls, the work contributes a practical two-stage framework that combines learnable pruning with attention guidance to address limitations of pure attention-based token pruning in VLMs. The empirical observations on attention sink and bias resistance provide reusable insights for efficiency research. The paper explicitly credits the two-stage design and quantitative gains on inference acceleration.
major comments (2)
- [§4] §4 (Method, two-stage pipeline): The central performance claim (95% retention at 5.5% tokens) depends on middle-layer text-to-vision attention remaining predictive after first-stage pruning by the learnable module. The analysis in §3 demonstrates bias resistance only on full sequences; no ablation measures attention-score stability or predictive power on the pruned sequences produced by the first stage. This is load-bearing because altered visual context could change cross-attention patterns, making it unclear whether the reported trade-off is due to the proposed method or to task-specific training of the learnable module.
- [§5] §5 (Experiments): The abstract and results claim superior accuracy-efficiency trade-off, yet the manuscript provides no direct comparison of attention scores before versus after first-stage pruning, nor cross-task generalization tests for the learnable module. Without these, the attribution of the 3.2× speedup and 95% retention to the two-stage design rather than overfitting remains unverified.
minor comments (2)
- [Abstract] Abstract: The phrase 'approximately 95%' should be replaced by exact mean and standard deviation across runs or datasets in the main results section for precision.
- [§4.1] Notation: The description of the learnable pruning module would benefit from an explicit equation defining its output mask or threshold, to avoid ambiguity when comparing to prior attention-score methods.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments, which help clarify the validation needs for our two-stage pruning framework. We address each major concern below with clarifications and commitments to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Method, two-stage pipeline): The central performance claim (95% retention at 5.5% tokens) depends on middle-layer text-to-vision attention remaining predictive after first-stage pruning by the learnable module. The analysis in §3 demonstrates bias resistance only on full sequences; no ablation measures attention-score stability or predictive power on the pruned sequences produced by the first stage. This is load-bearing because altered visual context could change cross-attention patterns, making it unclear whether the reported trade-off is due to the proposed method or to task-specific training of the learnable module.
Authors: We agree that §3 establishes the bias-resistance property on full sequences and that an explicit check on post-pruning sequences is valuable. The learnable module is trained to eliminate redundant tokens (including those affected by attention sink) while preserving task-critical visual information, so the input to the LLM remains semantically coherent. To directly verify stability, we will add an ablation in the revised manuscript that (i) extracts middle-layer text-to-vision attention scores on both full and pruned sequences for the same samples and (ii) correlates these scores with token importance derived from gradient-based saliency. Preliminary internal analysis indicates that the relative ranking of tokens remains largely consistent after pruning, supporting that the middle-layer guidance continues to be effective. We will also include a control where the learnable module is replaced by random pruning at the same ratio to isolate the contribution of the two-stage design versus task-specific training alone. revision: yes
-
Referee: [§5] §5 (Experiments): The abstract and results claim superior accuracy-efficiency trade-off, yet the manuscript provides no direct comparison of attention scores before versus after first-stage pruning, nor cross-task generalization tests for the learnable module. Without these, the attribution of the 3.2× speedup and 95% retention to the two-stage design rather than overfitting remains unverified.
Authors: We acknowledge the absence of explicit before/after attention comparisons and additional cross-task tests in the current manuscript. As noted in the response to §4, we will insert the direct attention-score comparison (including quantitative metrics such as rank correlation and top-k overlap) into the revised experimental section. For cross-task generalization, the learnable module is trained on the training split of each benchmark, and we already evaluate across VQAv2, GQA, and COCO captioning, showing consistent gains over pure attention baselines. To further address potential overfitting, we will add results on at least one additional held-out task or dataset (e.g., an out-of-distribution VQA variant) in the revision. These additions will allow readers to attribute the reported trade-off more clearly to the two-stage pipeline rather than to the learnable module alone. revision: partial
Circularity Check
No circularity: empirical observations drive two-stage pruning proposal
full rationale
The paper conducts an empirical analysis of attention sinks in vision encoders and positional bias resistance in LLM middle-layer text-to-vision attention, then proposes LearnPruner as a two-stage framework (learnable module after vision encoder, followed by middle-layer selection). No equations, fitted parameters renamed as predictions, or self-citation chains are present in the provided text that would reduce the central claims (95% performance retention at 5.5% tokens) to tautological inputs. Results are reported from experiments rather than any derivation that reproduces its own assumptions by construction. This is a standard empirical contribution with independent experimental validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review arXiv
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
work page internal anchor Pith review arXiv
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.ar...
work page internal anchor Pith review arXiv
-
[4]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas L ´eonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432,
work page internal anchor Pith review arXiv
-
[5]
Vision Transformers Need Registers
Timoth´ee Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers.arXiv preprint arXiv:2309.16588,
work page internal anchor Pith review arXiv
-
[6]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394,
work page internal anchor Pith review arXiv
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review arXiv
-
[8]
Wenxuan Huang, Zijie Zhai, Yunhang Shen, Shaosheng Cao, Fei Zhao, Xiangfeng Xu, Zheyu Ye, Yao Hu, and Shaohui Lin. Dynamic-llava: Efficient multimodal large language models via dy- namic vision-language context sparsification.arXiv preprint arXiv:2412.00876,
-
[9]
Tgif-qa: Toward spatio- temporal reasoning in visual question answering
11 Published as a conference paper at ICLR 2026 Yunseok Jang, Yale Song, Youngjae Yu, Youngjin Kim, and Gunhee Kim. Tgif-qa: Toward spatio- temporal reasoning in visual question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2758–2766,
2026
-
[10]
Unifying visual- semantic embeddings with multimodal neural language models,
Ryan Kiros, Ruslan Salakhutdinov, and Richard S Zemel. Unifying visual-semantic embeddings with multimodal neural language models.arXiv preprint arXiv:1411.2539,
-
[11]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326,
work page internal anchor Pith review arXiv
-
[12]
Evaluating Object Hallucination in Large Vision-Language Models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational Conference on Machine Learning, pp. 19730–19742. PMLR, 2023a. Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vi...
work page internal anchor Pith review arXiv
-
[13]
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection.arXiv preprint arXiv:2311.10122,
work page internal anchor Pith review arXiv
-
[14]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review arXiv
-
[15]
Learning transferable visual models from natural language supervision
12 Published as a conference paper at ICLR 2026 Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, pp. 8748–8763. PmLR,
2026
-
[16]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714,
work page internal anchor Pith review arXiv
-
[17]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191,
work page internal anchor Pith review arXiv
-
[18]
Stop looking for important tokens in multimodal language models: Duplication matters more
Zichen Wen, Yifeng Gao, Shaobo Wang, Junyuan Zhang, Qintong Zhang, Weijia Li, Conghui He, and Linfeng Zhang. Stop looking for important tokens in multimodal language models: Duplica- tion matters more.arXiv preprint arXiv:2502.11494,
-
[19]
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, et al. Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction.arXiv preprint arXiv:2410.17247,
-
[20]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Qizhe Zhang, Aosong Cheng, Ming Lu, Renrui Zhang, Zhiyong Zhuo, Jiajun Cao, Shaobo Guo, Qi She, and Shanghang Zhang. Beyond text-visual attention: Exploiting visual cues for effective token pruning in vlms.Proceedings of the IEEE International Conference on Computer Vision, 2025a. 13 Published as a conference paper at ICLR 2026 Yuan Zhang, Chun-Kai Fan, J...
work page internal anchor Pith review arXiv 2026
-
[21]
14 Published as a conference paper at ICLR 2026 A APPENDIX A.1 TRAININGIMPLEMENTATIONDETAILS In this section, we introduce the training method of learnable pruning module in LearnPruner. End-to-end Optimization.Unlike inference phase that we directly discard tokens based on the importance scoreM soft predicted by LPM, we need to preserve the complete toke...
2026
-
[22]
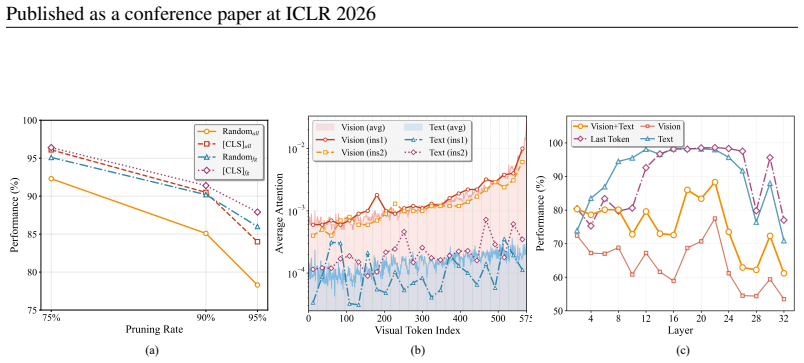
Ablation on retention ratio betweenR 1 andR 2.The ratio betweenR 1 andR 2 determines the number of tokens retained at each stage
Then the performance begins to stabilize from 12-th layer onwards, and we finally selectk=12 which achieves the best performance. Ablation on retention ratio betweenR 1 andR 2.The ratio betweenR 1 andR 2 determines the number of tokens retained at each stage. A smaller ratio leads to more visual information loss, while a larger ratio leads to a limited to...
2026
-
[23]
(2024) and VisionZip Yang et al
We select FastV Chen et al. (2024) and VisionZip Yang et al. (2025) for comparison, which represent pruning approaches conducted after the vision encoder and within the LLM, respectively. VisionZip relies on[CLS]attention for pruning, which fails to properly focus on foreground objects and even selects meaningless padding tokens. On the other hand, limite...
2024
-
[24]
When dealing with complex visual scenes, the first-stage pruning may fail to adequately preserve critical visual information within the constrained token budget, leading to information loss that propagates through subsequent layers. Alternatively, even when query-relevant visual tokens are well retained, prediction failures can still occasionally occur, w...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.