Recognition: unknown
Financial Market as a Self-Organized Ecosystem: Simulation via Learning with Heterogeneous Preferences
Pith reviewed 2026-05-07 17:16 UTC · model grok-4.3
The pith
Learning under heterogeneous preferences drives agents to develop specialized trading roles whose interactions generate fat-tailed prices and volatility clustering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
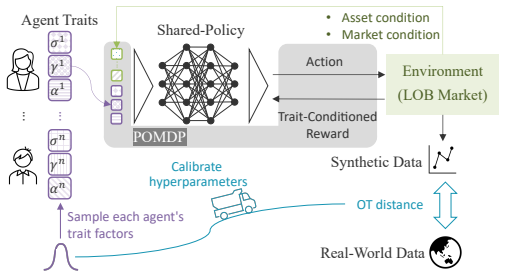
In a multi-agent reinforcement learning market, agents endowed with heterogeneous risk aversion, time discounting, and information access learn trading strategies interactively. The learning process produces functionally differentiated strategies that result in role specialization among agents. Interactions among these differentiated agents prove essential for the emergence of fat-tailed price fluctuations and volatility clustering, thereby providing a computational realization of markets as self-organized ecosystems under the Adaptive Market Hypothesis.
What carries the argument
Interactive multi-agent reinforcement learning in which agents with heterogeneous preferences adapt their strategies through repeated market interactions, producing emergent role specialization.
If this is right
- Agents develop trading strategies through interaction rather than by directly following their initial preference traits.
- Role specialization is required for the appearance of fat tails and volatility clustering.
- The market self-organizes into an ecology of differentiated participants without external assignment of roles.
- This joint design of preferences and learning supplies a computational model of adaptive market behavior.
Where Pith is reading between the lines
- Markets with greater diversity in investor types may exhibit more stable role structures that buffer against uniform shocks.
- The same learning-plus-heterogeneity mechanism could be tested in non-financial domains such as resource allocation or social coordination where agents adapt to shared environments.
- Altering the distribution of preferences while keeping the learning rule fixed would provide a direct test of whether specialization persists across different heterogeneity levels.
Load-bearing premise
The observed role specialization and realistic market dynamics are produced by the joint presence of heterogeneous preferences and interactive learning rather than by particular choices in the price-formation rule or reward function.
What would settle it
A version of the simulation in which all agents are given identical preferences yet still produce the same fat-tailed returns and volatility clustering would falsify the necessity of heterogeneity for those dynamics.
Figures


read the original abstract
Agent-based models provide a constructive approach to studying emergent dynamics in life-like systems composed of interacting, adaptive agents. Financial markets serve as a canonical example of such systems, where collective price dynamics arise from individual decision-making. In this modeling tradition, investor behavior has typically been captured by two distinct mechanisms -- learning and heterogeneous preferences -- which have been explored as separate paradigms in prior studies. However, the impact of their joint modeling on the resulting collective dynamics remains largely unexplored. We develop a multi-agent reinforcement learning framework in which agents endowed with heterogeneous risk aversion, time discounting, and information access learn trading strategies interactively within an artificial market. The experiment reveals that (i) learning under heterogeneous preferences drives agents to develop functionally differentiated strategies through interaction, rather than trait-specific rules, resulting in role specialization, and (ii) the interactions by the differentiated agents are essential for the emergence of realistic market dynamics such as fat-tailed price fluctuations and volatility clustering. Overall, this study demonstrates that the joint design of heterogeneous preferences and learning mechanisms enables the synthesis of an artificial market in which adaptive interactions drive the self-organization of a market ecology, providing a computational realization of the Adaptive Market Hypothesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a multi-agent reinforcement learning model of an artificial financial market in which agents endowed with heterogeneous risk aversion, time-discount factors, and information-access parameters interactively learn trading strategies. It reports that this joint setup produces emergent functional role specialization among agents (rather than trait-specific rules) and, through their interactions, generates realistic aggregate statistics including fat-tailed returns and volatility clustering, thereby providing a computational realization of the Adaptive Market Hypothesis.
Significance. If the central claims are supported by appropriate controls, the work would usefully integrate two previously separate modeling traditions in agent-based finance and supply a concrete demonstration that heterogeneous preferences plus interactive learning can endogenously generate differentiated trading roles and stylized facts without explicit programming of those outcomes.
major comments (2)
- [Results / Experimental Setup] The manuscript contains no ablation experiment in which all agents share identical risk-aversion, discounting, and information-access parameters while retaining the same market-clearing rule and reinforcement-learning algorithm. Without this control, it is impossible to isolate whether the reported role specialization and the emergence of fat tails/volatility clustering are caused by the heterogeneity-plus-learning design or by the price-formation mechanism, reward function, or chosen parameter ranges alone. This directly undermines the causal attribution in the abstract's claims (i) and (ii).
- [Simulation Experiments] No sensitivity analysis or reporting of statistical controls (e.g., variation across random seeds, parameter sweeps, or formal tests for the presence of fat tails and clustering) is described. The abstract states that realistic dynamics 'emerge,' yet without evidence that the target statistics were not used to guide parameter selection, the result risks being a fitted reproduction rather than an independent prediction.
minor comments (2)
- [Model Description] The description of the market price-formation rule and the precise reward function used in the RL update should be expanded with explicit equations to allow replication.
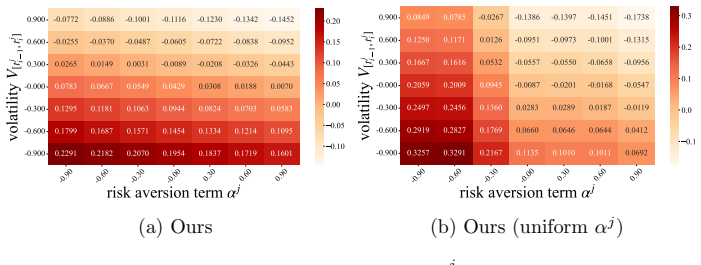
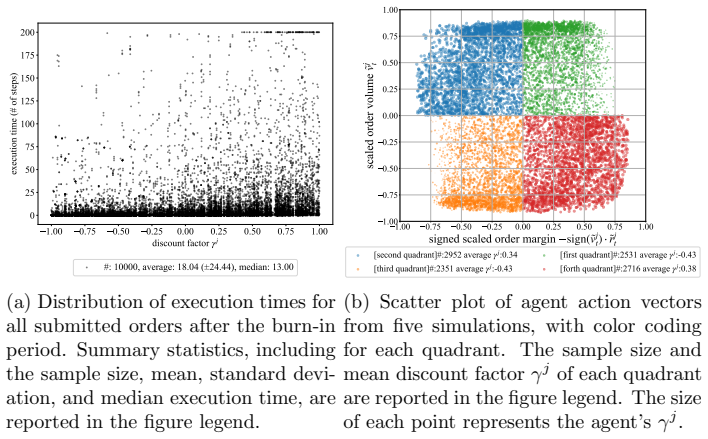
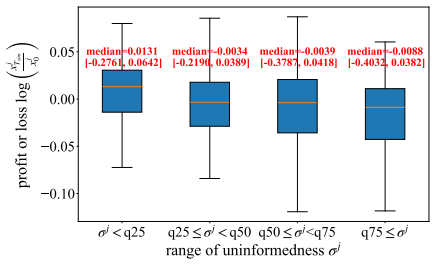
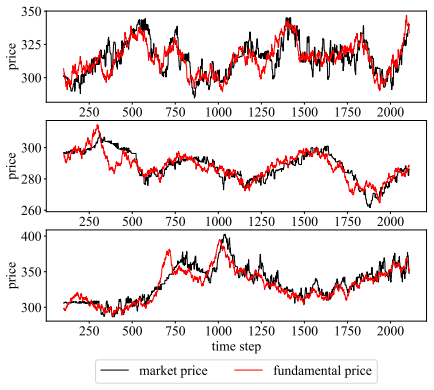
- [Figures] Figure captions and axis labels for the role-specialization and return-distribution plots would benefit from additional detail on the exact metrics plotted and the number of independent runs averaged.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where additional controls would strengthen the causal interpretation and robustness of our results. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: The manuscript contains no ablation experiment in which all agents share identical risk-aversion, discounting, and information-access parameters while retaining the same market-clearing rule and reinforcement-learning algorithm. Without this control, it is impossible to isolate whether the reported role specialization and the emergence of fat tails/volatility clustering are caused by the heterogeneity-plus-learning design or by the price-formation mechanism, reward function, or chosen parameter ranges alone. This directly undermines the causal attribution in the abstract's claims (i) and (ii).
Authors: We agree that an ablation with homogeneous agents is required to isolate the contribution of preference heterogeneity. The current manuscript demonstrates emergence under heterogeneity but does not include the homogeneous control. In the revision we will add a new experiment in which all agents are assigned identical parameters (set to the means of the heterogeneous distributions) while keeping the market-clearing rule, reward function, and RL algorithm unchanged. We will report the resulting absence or attenuation of role specialization and stylized facts, thereby providing direct evidence that the joint heterogeneity-plus-learning mechanism is necessary for the reported outcomes. revision: yes
-
Referee: No sensitivity analysis or reporting of statistical controls (e.g., variation across random seeds, parameter sweeps, or formal tests for the presence of fat tails and clustering) is described. The abstract states that realistic dynamics 'emerge,' yet without evidence that the target statistics were not used to guide parameter selection, the result risks being a fitted reproduction rather than an independent prediction.
Authors: We acknowledge that the manuscript does not report sensitivity analyses or formal statistical controls. In the revised version we will add: (i) results averaged over at least 10 independent random seeds with standard deviations for all key statistics; (ii) parameter sweeps around the degree of heterogeneity, learning rates, and information-access parameters; and (iii) formal tests (excess kurtosis with p-values, Ljung-Box test on squared returns). We will also document that parameter ranges were selected from prior empirical literature on investor heterogeneity rather than tuned to reproduce the target statistics, and include a brief discussion of this choice to address concerns of post-hoc fitting. revision: yes
Circularity Check
No circularity: simulation outcomes generated from agent rules without reduction to fitted targets or self-definitions.
full rationale
The paper constructs an explicit multi-agent reinforcement learning environment with stated heterogeneous parameters (risk aversion, discounting, information access) and market price-formation rules, then runs interactive learning episodes to observe emergent role differentiation and statistics. No quoted step equates the reported fat tails or volatility clustering to a direct fit of those same statistics, nor does any derivation reduce by construction to the inputs via self-definition, ansatz smuggling, or load-bearing self-citation. The central claim rests on the simulation results themselves rather than on renaming or re-deriving the target patterns from the model definition.
Axiom & Free-Parameter Ledger
free parameters (3)
- risk aversion distribution
- time-discount factors
- information-access parameters
axioms (2)
- domain assumption Agents improve trading policies via reinforcement learning by maximizing expected cumulative reward.
- domain assumption Market prices form from the aggregate order flow of all agents in a closed artificial exchange.
invented entities (1)
-
functionally differentiated trading roles
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Paris December 2016 Finance Meeting EUROFIDAI - AFFI. Marcin Andrychowicz, Anton Raichuk, Piotr Sta´ nczyk, Manu Orsini, Ser- tan Girgin, Raphael Marinier, L´ eonard Hussenot, Matthieu Geist, Olivier Pietquin, Marcin Michalski, Sylvain Gelly, and Olivier Bachem. What matters in on-policy reinforcement learning? A large-scale empirical study,
2016
-
[2]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
URLhttps://arxiv.org/abs/1506.02438. Richard S. Sutton and Andrew G. Barto.Reinforcement learning: An in- troduction. The MIT Press,
work page internal anchor Pith review arXiv
-
[3]
Impact of high-frequency trading with an order book imbalance strategy on agent-based stock mar- kets.Complexity, 2023(1):3996948,
29 Isao Yagi, Mahiro Hoshino, and Takanobu Mizuta. Impact of high-frequency trading with an order book imbalance strategy on agent-based stock mar- kets.Complexity, 2023(1):3996948,
2023
-
[4]
B Our Method: Training Details In our experiment, the shared-policy was trained using proximal policy opti- mization [Schulman et al., 2017]
to transform the simulation outputs into one-minute bar series of prices and volumes. B Our Method: Training Details In our experiment, the shared-policy was trained using proximal policy opti- mization [Schulman et al., 2017]. Both the actor and critic networks (πθ and Cϕ) were implemented as three-layer neural networks with 512 hidden units per layer an...
2017
-
[5]
proposed the order decision of the FCN-Agent based on price prediction ˆpj t+τ j t , holding cash amountc j t ∈R, holding stock positionw j t ∈Z, and the risk-aversion termα j t ∈R + by assuming the constant absolute risk aversion (CARA) utility functionU j t : U j t =−exp n −αj t(wj t pt +c j t) o (19) 33 where∀j c j 1 ∼U(c min, cmax), w j 1 =⌈w j⌉, w j ...
2025
-
[6]
It includes order and execution series data, called tick data
D Data Description We used FLEX-FULL historical tick data provided by the Japan Exchange Group [Japan Exchange Group, 2025]. It includes order and execution series data, called tick data. By recording the mid price every minute, we obtained a one-minute bar price series with lengthT len = 300 per day. The data period was from January 5, 2015 to December 31,
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.