Recognition: unknown
Representational Curvature Modulates Behavioral Uncertainty in Large Language Models
Pith reviewed 2026-05-08 03:42 UTC · model grok-4.3
The pith
Contextual curvature of representational trajectories in LLMs correlates with and causally modulates next-token entropy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
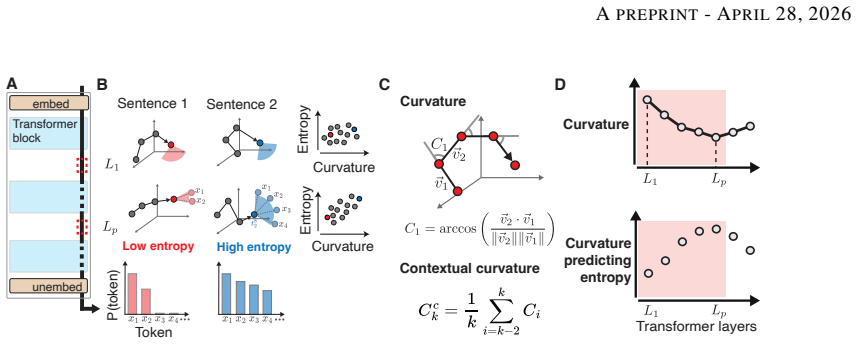
Contextual curvature—a geometric measure of how sharply the representational trajectory bends over recent context—is correlated with next-token entropy across GPT-2 XL and Pythia-2.8B. The correlation emerges over the course of training. Trajectory-aligned perturbations that change curvature reliably alter entropy, while geometrically misaligned perturbations leave entropy unchanged. Regularizing representations to be straighter during training modestly reduces token-level entropy without degrading validation loss.
What carries the argument
Contextual curvature, the geometric measure of how sharply the representational trajectory bends over recent context, which links internal geometry to behavioral uncertainty.
If this is right
- The relationship between curvature and entropy strengthens as training proceeds, indicating it is acquired rather than present from initialization.
- Only perturbations that preserve the geometric alignment of the trajectory affect entropy, showing that the effect is not explained by generic changes to representation magnitude or direction.
- Adding a straightening regularizer to the training objective lowers next-token entropy at no cost to validation loss.
- The same curvature-entropy link appears in two architecturally distinct models, suggesting it is not an artifact of one specific network family.
Where Pith is reading between the lines
- If curvature can be read out from hidden states, it may offer a low-cost way to estimate local prediction uncertainty without sampling multiple tokens.
- The finding raises the possibility that other geometric descriptors of trajectories, such as torsion or speed, could relate to additional behavioral quantities like calibration or hallucination rates.
- Training objectives that explicitly penalize curvature might be tested as a lightweight alternative to temperature scaling or other post-hoc uncertainty adjustments.
Load-bearing premise
Trajectory-aligned interventions change only curvature and leave all other unmeasured representational properties that could affect entropy untouched.
What would settle it
If a trajectory-aligned perturbation that successfully alters measured curvature produces no change in next-token entropy, or if a misaligned perturbation produces a reliable entropy change, the claimed selective dependence would be falsified.
Figures




read the original abstract
In autoregressive large language models (LLMs), temporal straightening offers an account of how the next-token prediction objective shapes representations. Models learn to progressively straighten the representational trajectory of input sequences across layers, potentially facilitating next-token prediction via linear extrapolation. However, a direct link between this trajectory and token-level behavior has been missing. We provide such a link by relating contextual curvature-a geometric measure of how sharply the representational trajectory bends over recent context-to next-token entropy. Across two models (GPT-2 XL and Pythia-2.8B), contextual curvature is correlated with entropy, and this relationship emerges during training. Perturbation experiments reveal selective dependence: manipulating curvature through trajectory-aligned interventions reliably modulates entropy, while geometrically misaligned perturbations have no effect. Finally, regularizing representations to be straighter during training modestly reduces token-level entropy without degrading validation loss. These results identify trajectory curvature as a task-aligned representational feature that influences behavioral uncertainty in LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in autoregressive LLMs, contextual curvature—a geometric measure of bending in the representational trajectory over recent context—directly modulates next-token entropy. It reports positive correlations between curvature and entropy in GPT-2 XL and Pythia-2.8B, shows the relationship emerging during training, demonstrates selective entropy modulation via trajectory-aligned perturbations (but not misaligned ones), and finds that regularizing representations toward straighter trajectories during training reduces entropy without increasing validation loss.
Significance. If the central causal link holds, the work supplies a concrete geometric account of how representational structure influences behavioral uncertainty, extending temporal straightening ideas to token-level predictions. The combination of correlational, developmental, interventional, and regularization evidence is a strength; the regularization result in particular offers a falsifiable, task-aligned manipulation with potential downstream utility for uncertainty control.
major comments (3)
- [Perturbation experiments] Perturbation experiments section: the claim that trajectory-aligned interventions selectively modulate curvature (and thereby entropy) while misaligned ones do not requires explicit verification that the two perturbation classes are matched on all other statistics that could affect entropy (e.g., activation magnitude, direction relative to the residual stream, or higher-order moments). Without such controls or an ablation showing that entropy changes scale with the curvature component alone, the selective dependence could arise from unintended side effects rather than curvature per se.
- [Methods] Methods / curvature definition: the exact operationalization of 'contextual curvature' (e.g., the precise formula for trajectory bending over recent context, choice of distance metric, and window size) is not stated with sufficient precision to allow independent replication or to rule out post-hoc parameter choices that could inflate the reported correlations.
- [Training dynamics] Results on emergence during training: the reported emergence of the curvature-entropy correlation lacks details on statistical controls (e.g., multiple-comparison correction across layers and checkpoints, sample sizes per checkpoint, and exclusion criteria for sequences), making it difficult to assess whether the developmental pattern is robust or sensitive to analysis decisions.
minor comments (3)
- [Abstract / Introduction] The abstract and introduction would benefit from a brief equation or pseudocode for the curvature metric to orient readers before the experimental claims.
- [Figures] Figure captions for the perturbation results should explicitly state the number of trials, error bars (e.g., SEM or 95% CI), and whether the aligned/misaligned conditions were yoked on perturbation magnitude.
- [Regularization results] The regularization experiment reports 'modest' entropy reduction; quantitative effect sizes and comparison to a matched baseline (e.g., random regularization) would strengthen the claim.
Simulated Author's Rebuttal
We are grateful to the referee for their detailed and insightful comments, which have helped us identify areas for improvement. We respond to each major comment below and will incorporate the suggested revisions to enhance the clarity and rigor of the manuscript.
read point-by-point responses
-
Referee: [Perturbation experiments] Perturbation experiments section: the claim that trajectory-aligned interventions selectively modulate curvature (and thereby entropy) while misaligned ones do not requires explicit verification that the two perturbation classes are matched on all other statistics that could affect entropy (e.g., activation magnitude, direction relative to the residual stream, or higher-order moments). Without such controls or an ablation showing that entropy changes scale with the curvature component alone, the selective dependence could arise from unintended side effects rather than curvature per se.
Authors: We acknowledge the importance of ruling out alternative explanations for the selective effects observed in our perturbation experiments. In the revised version, we will add explicit controls and matching statistics for the aligned and misaligned perturbations, including comparisons of activation magnitudes, directions in the residual stream, and higher-order moments. Additionally, we will include an ablation analysis demonstrating that the entropy modulation scales with the curvature change induced by the perturbations. revision: yes
-
Referee: [Methods] Methods / curvature definition: the exact operationalization of 'contextual curvature' (e.g., the precise formula for trajectory bending over recent context, choice of distance metric, and window size) is not stated with sufficient precision to allow independent replication or to rule out post-hoc parameter choices that could inflate the reported correlations.
Authors: We agree that the methods section requires greater precision for replicability. In the revision, we will provide the exact mathematical definition of contextual curvature, including the formula for trajectory bending, the distance metric employed (Euclidean distance in the representation space), and the specific window size used for the recent context. We will also include pseudocode and details on how parameters were selected to ensure transparency. revision: yes
-
Referee: [Training dynamics] Results on emergence during training: the reported emergence of the curvature-entropy correlation lacks details on statistical controls (e.g., multiple-comparison correction across layers and checkpoints, sample sizes per checkpoint, and exclusion criteria for sequences), making it difficult to assess whether the developmental pattern is robust or sensitive to analysis decisions.
Authors: We appreciate the referee's point regarding the need for rigorous statistical reporting. In the updated manuscript, we will include detailed information on the statistical analyses, such as the application of multiple-comparison corrections (e.g., Bonferroni or FDR), the sample sizes for each checkpoint and layer, and the criteria used for sequence inclusion or exclusion. This will allow readers to better evaluate the robustness of the emergence pattern. revision: yes
Circularity Check
No significant circularity; claims rest on empirical correlations and interventions
full rationale
The paper links contextual curvature to next-token entropy via direct measurements (correlations across models and training), perturbation experiments (trajectory-aligned vs. misaligned interventions), and a regularization experiment during training. No load-bearing step reduces by the paper's own equations or self-citations to a fitted parameter, self-defined quantity, or ansatz imported from the authors' prior work. The central results are externally falsifiable via the described experiments and do not rely on renaming known patterns or uniqueness theorems. This is the expected non-finding for an empirical study whose derivation chain consists of data collection and statistical tests rather than algebraic closure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://www.nature.com/articles/s41467-021-25939-z
doi: 10.1038/s41467-021-25939-z. URL https://www.nature.com/articles/s41467-021-25939-z . Publisher: Nature Publishing Group. Antonino Greco, Julia Moser, Hubert Preissl, and Markus Siegel. Predictive learning shapes the representational geometry of the human brain.Nature Communications, 15(1):9670, November 2024. ISSN 2041-1723. doi: 10 APREPRINT- APRIL2...
-
[2]
doi: 10.1016/j.cognition.2007.05.006. URL https://www.sciencedirect.com/science/article/pii/ S0010027707001436. Eghbal Hosseini and Evelina Fedorenko. Large language models implicitly learn to straighten neural sentence trajectories to construct a predictive representation of natural language. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S...
-
[3]
Understanding polysemanticity in neural networks through coding theory,
URLhttps://arxiv.org/abs/2401.17975. Eric Bigelow, Daniel Wurgaft, YingQiao Wang, Noah Goodman, Tomer Ullman, Hidenori Tanaka, and Ekdeep Singh Lubana. Belief dynamics reveal the dual nature of in-context learning and activation steering, 2025. URL https: //arxiv.org/abs/2511.00617. Ekdeep Singh Lubana, Can Rager, Sai Sumedh R. Hindupur, Valerie Costa, Gr...
-
[4]
arXiv preprint arXiv:2511.01836 , year=
URLhttps://arxiv.org/abs/2511.01836. Core Francisco Park, Andrew Lee, Ekdeep Singh Lubana, Yongyi Yang, Maya Okawa, Kento Nishi, Martin Wattenberg, and Hidenori Tanaka. ICLR: In-Context Learning of Representations, May 2025. URL http://arxiv.org/abs/ 2501.00070. arXiv:2501.00070 [cs]. Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J...
-
[5]
URLhttps://arxiv.org/abs/2602.22617. Ranganath Krishnan, Piyush Khanna, and Omesh Tickoo. Enhancing trust in large language models with uncertainty- aware fine-tuning, 2024. URLhttps://arxiv.org/abs/2412.02904. Adrien Bardes, Jean Ponce, and Yann LeCun. Vicreg: Variance-invariance-covariance regularization for self-supervised learning, 2022. URLhttps://ar...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.