Recognition: unknown
When to Commit? Towards Variable-Size Self-Contained Blocks for Discrete Diffusion Language Models
Pith reviewed 2026-05-08 04:39 UTC · model grok-4.3
The pith
Discrete diffusion language models reduce premature token commitments by selecting variable-size blocks only when predictions remain consistent with or without future context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
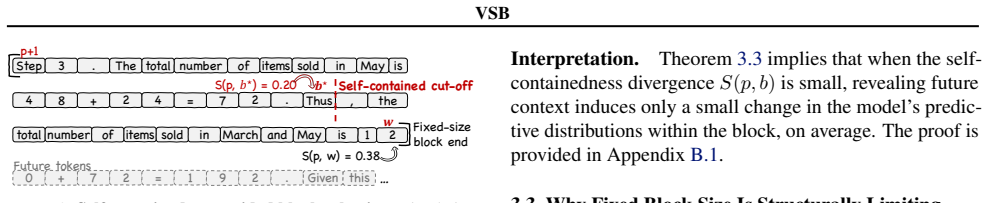
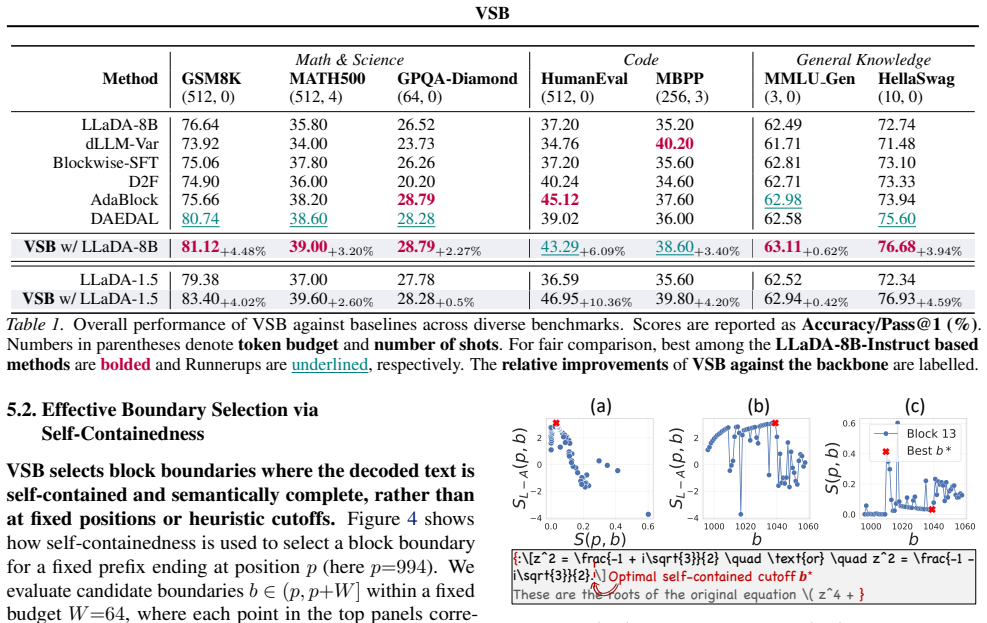
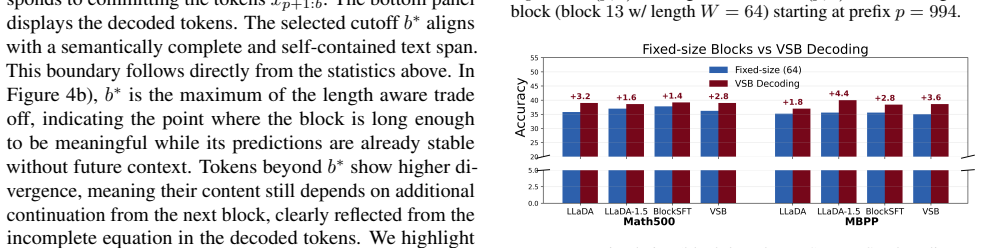
The paper claims that self-containedness, measured as predictive consistency between no-future (NF) and future-aware (FA) conditioning, provides a principled way to choose block boundaries for blockwise decoding in discrete diffusion language models. VSB scores candidate boundaries by the divergence between these two distributions at each token and commits only those blocks whose predictions are unlikely to change once future tokens are visible. Theoretical justification links low divergence to blocks whose commitments will not be altered by later context, and experiments confirm that variable blocks chosen this way outperform both fixed-size and heuristic blockwise baselines.
What carries the argument
Divergence between token-level predictive distributions under NF and FA conditioning, which scores how much each token's output would change if future context were added and thereby identifies self-contained block boundaries.
If this is right
- Generation avoids premature commitments that later context would reverse.
- Block sizes adapt automatically to local dependency structure instead of staying fixed.
- The training-inference mismatch shrinks because commitments occur only when NF and FA predictions agree.
- Overall sample quality improves relative to fixed-size or heuristic blockwise decoding.
Where Pith is reading between the lines
- The same divergence check could be inserted into other block-based or semi-autoregressive decoding schemes to decide when to commit.
- Longer sequences may benefit more from VSB because dependency lengths vary more widely than fixed blocks allow.
- One could test whether VSB reduces the frequency of post-hoc resampling or correction steps during generation.
- If the consistency criterion generalizes, similar variable-commitment logic might apply to continuous diffusion or multimodal models.
Load-bearing premise
Divergence between no-future and future-aware predictive distributions reliably flags blocks whose commitments remain stable once future context arrives.
What would settle it
On a held-out generation benchmark, VSB-selected blocks produce lower-quality or less consistent text than fixed-size blocks of comparable average length.
Figures







read the original abstract
Discrete diffusion language models (dLLMs) enable parallel token updates with bidirectional attention, yet practical generation typically adopts blockwise semi-autoregressive decoding. This switch creates a training-inference mismatch: training denoises with full-sequence context, while inference commits tokens within a bounded block without future context. Therefore, decoding with fixed-size or heuristic-based blocks can lead to premature token commitments, as decisions are made without full access to future context that could alter those choices. Motivated by this, we propose self-containedness as a principled criterion for block commitment. A block is self-contained if its predictions remain consistent with Future-Aware (FA) or without No-Future (NF) access to future context, reframing block boundary selection as a test of self-containedness rather than a heuristic choice. Based on this principle, we introduce Variable-size Self-contained Blocks (VSB) for dLLMs. VSB scores and selects block boundaries using the divergence between token-level predictive distributions under NF and FA conditioning, which quantifies how predictions would change if future context were revealed. We provide theoretical justification linking self-containedness to predictive consistency, and extensive experiments validate VSB's efficacy over fixed-size and heuristic blockwise decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a training-inference mismatch in discrete diffusion language models (dLLMs) when using blockwise semi-autoregressive decoding: training uses full-sequence context while inference commits tokens in bounded blocks without future context, risking premature commitments. It introduces self-containedness as a criterion for block boundaries, defined by consistency of token-level predictions under No-Future (NF) versus Future-Aware (FA) conditioning. Variable-size Self-contained Blocks (VSB) are proposed to score and select boundaries via divergence between these predictive distributions. The authors supply theoretical justification linking self-containedness to predictive consistency and report extensive experiments showing gains over fixed-size and heuristic baselines.
Significance. If the divergence-based selection reliably identifies blocks whose sampled tokens remain stable under full future context, VSB would offer a principled improvement to generation quality and consistency in dLLMs, reducing the mismatch that fixed blocks introduce. This could influence broader work on adaptive and parallel decoding strategies, with the experiments providing a concrete starting point for validation.
major comments (2)
- [Abstract] Abstract: the theoretical justification equates predictive consistency (low NF-FA divergence) with self-containedness, yet provides no explicit bound or inequality relating distribution divergence to the probability that sampled tokens inside the block will remain unchanged once the true future context is revealed. This link is load-bearing for the claim that VSB avoids premature commitments.
- [Method] Method description: FA conditioning is necessarily performed with an approximation to the future (current noisy state or partial denoising), so the measured divergence is not the divergence that would arise with the final generated future; without a correction or sensitivity analysis, block selections may still be suboptimal.
minor comments (2)
- [Notation] Notation for NF and FA conditioning should be introduced with explicit equations early in the paper to clarify how future context is approximated during the divergence computation.
- [Experiments] Experiments section: ensure all baseline implementations (fixed-size, heuristic) are described with identical hyperparameters and that tables report effect sizes or confidence intervals alongside raw metrics.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our work. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the theoretical justification equates predictive consistency (low NF-FA divergence) with self-containedness, yet provides no explicit bound or inequality relating distribution divergence to the probability that sampled tokens inside the block will remain unchanged once the true future context is revealed. This link is load-bearing for the claim that VSB avoids premature commitments.
Authors: Our theoretical justification in the paper defines self-containedness precisely through the consistency of predictions under NF and FA conditioning, with divergence serving as a quantitative measure of potential change. While this provides a direct conceptual link, we acknowledge that no explicit inequality bounding the probability of token alteration (e.g., using total variation distance or Pinsker's inequality) is derived. We will revise the manuscript to include such a reference or simple bound to strengthen this connection and clarify how low divergence reduces the risk of premature commitments. revision: partial
-
Referee: [Method] Method description: FA conditioning is necessarily performed with an approximation to the future (current noisy state or partial denoising), so the measured divergence is not the divergence that would arise with the final generated future; without a correction or sensitivity analysis, block selections may still be suboptimal.
Authors: We agree that FA conditioning during inference uses an approximation based on the current noisy or partially denoised state rather than the final future tokens. This is inherent to the diffusion process. To mitigate concerns about suboptimality, we will incorporate a sensitivity analysis in the revised version, evaluating VSB block selections and performance under varying degrees of future approximation. This will demonstrate the practical robustness of our approach. revision: yes
Circularity Check
No significant circularity in VSB derivation chain
full rationale
The paper defines self-contained blocks as those whose token-level predictions remain consistent between NF and FA conditioning, then directly uses the divergence between those same predictive distributions as the scoring mechanism for boundary selection. This is a methodological proposal rather than a derivation that reduces a claimed result to fitted inputs or prior self-citations by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from the authors' prior work are referenced in the abstract or description. The theoretical justification simply equates the new criterion with predictive consistency, which is definitional but does not create a self-referential loop in the central claim; experimental validation against fixed-size baselines provides independent content. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Predictive distributions under NF and FA conditioning can be directly compared to determine whether a block's commitments are stable.
invented entities (2)
-
Self-contained block
no independent evidence
-
VSB
no independent evidence
Forward citations
Cited by 3 Pith papers
-
Block-R1: Rethinking the Role of Block Size in Multi-domain Reinforcement Learning for Diffusion Large Language Models
Block-R1 formulates domain block size conflicts in multi-domain RL for dLLMs, releases a 41K-sample dataset with per-sample best block sizes and a conflict score, and provides a benchmark plus simple cross-domain trai...
-
Block-R1: Rethinking the Role of Block Size in Multi-domain Reinforcement Learning for Diffusion Large Language Models
Introduces Block-R1 benchmark, Block-R1-41K dataset, and a conflict score to handle domain-specific optimal block sizes in RL post-training of diffusion LLMs.
-
Dystruct: Dynamically Structured Diffusion Language Model Decoding via Bayesian Inference
Dystruct formulates flexible-length generation in diffusion language models as a dynamic structural inference problem solved via Bayesian integration of local uncertainty and structural signals.
Reference graph
Works this paper leans on
-
[1]
It separates stable prose from unstable math.Early blocks show VSB committing short-to-medium spans that finish a statement, then opening the next block for the upcoming construction (Blocks 0-2). This matches the intended behavior: prose clauses are often self-contained, while upcoming math (definitions, substitutions, quadratic-formula expansions) creat...
-
[2]
It avoids committing incomplete equations.Throughout Blocks 3-14, the decoded content alternates between explana- tory text and symbolic expansions. Candidate boundaries that would cut inside a formula tend to have higher divergence, while candidates that end at a natural closure (end of a displayed equation, after the full numerator/denominator is formed...
-
[3]
roots of unity
It remains consistent across the whole generation.In Blocks 15-20, the same pattern continues: VSB commits a self-contained definition of “roots of unity”, then postpones the claim about “6th roots” until the supporting context is in place. The final block includes the concluding sentence and answer, which is naturally self-contained and corresponds to lo...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.