Recognition: unknown
Defusing the Trigger: Plug-and-Play Defense for Backdoored LLMs via Tail-Risk Intrinsic Geometric Smoothing
Pith reviewed 2026-05-08 03:04 UTC · model grok-4.3
The pith
TIGS defends backdoored LLMs at inference time by screening attention for trigger-induced collapse and applying targeted geometric smoothing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TIGS rests on the observation that successful backdoor triggers produce localized attention collapse inside the semantic content region. The defense therefore runs content-aware tail-risk screening to flag suspicious heads and rows, then applies intrinsic geometric smoothing consisting of a weak content-domain correction for semantic anchoring and a stronger full-row contraction to disrupt trigger-dominant routing. A controlled full-row write-back finally reconstructs the attention matrix. The resulting procedure suppresses attack success rates while strictly preserving clean reasoning and semantic consistency, and the same security-utility-latency profile holds for dense, reasoning-oriented
What carries the argument
Tail-risk Intrinsic Geometric Smoothing (TIGS): a two-stage attention-matrix correction that first screens for tail-risk collapse patterns and then applies differential row contraction to break trigger routing inside the native forward pass.
Load-bearing premise
Successful backdoor triggers consistently induce localized attention collapse within the semantic content region of the attention matrix.
What would settle it
A backdoor attack that achieves high success rates on a target model yet produces no detectable localized attention collapse in the semantic-content rows during the forward pass.
Figures


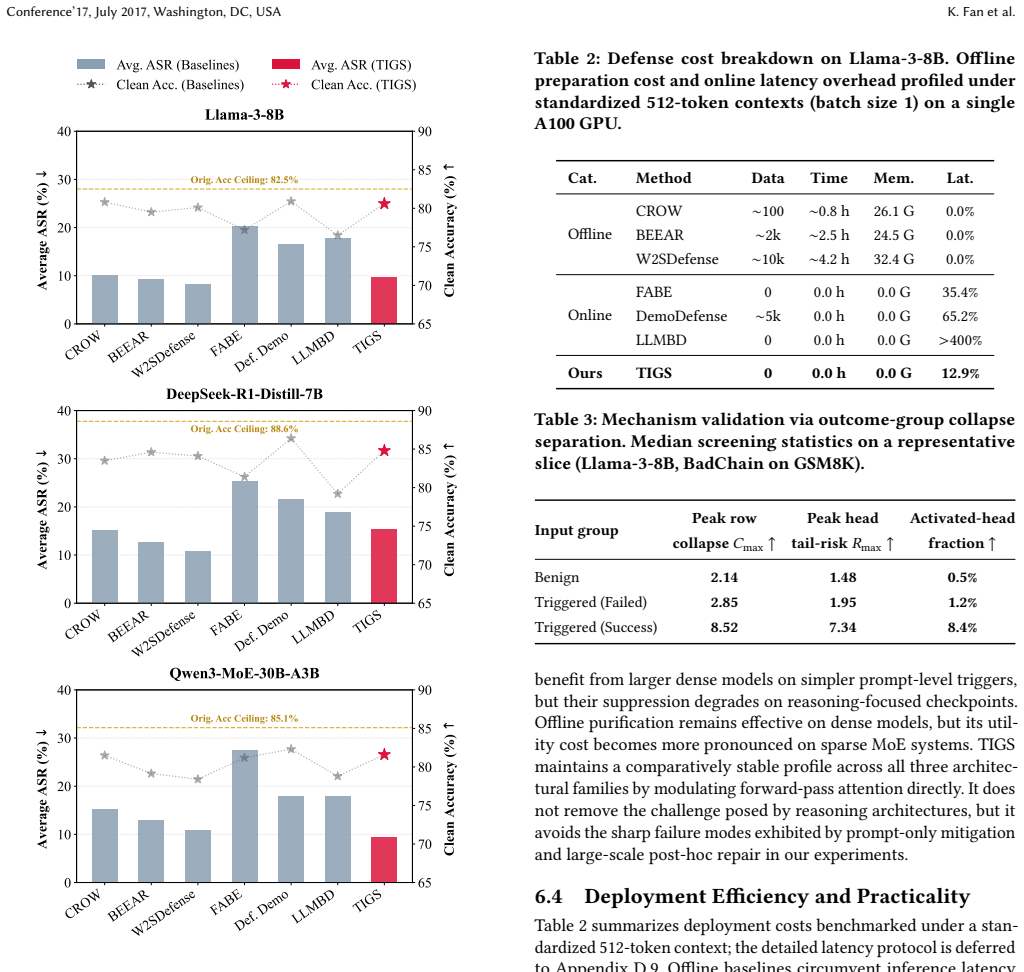


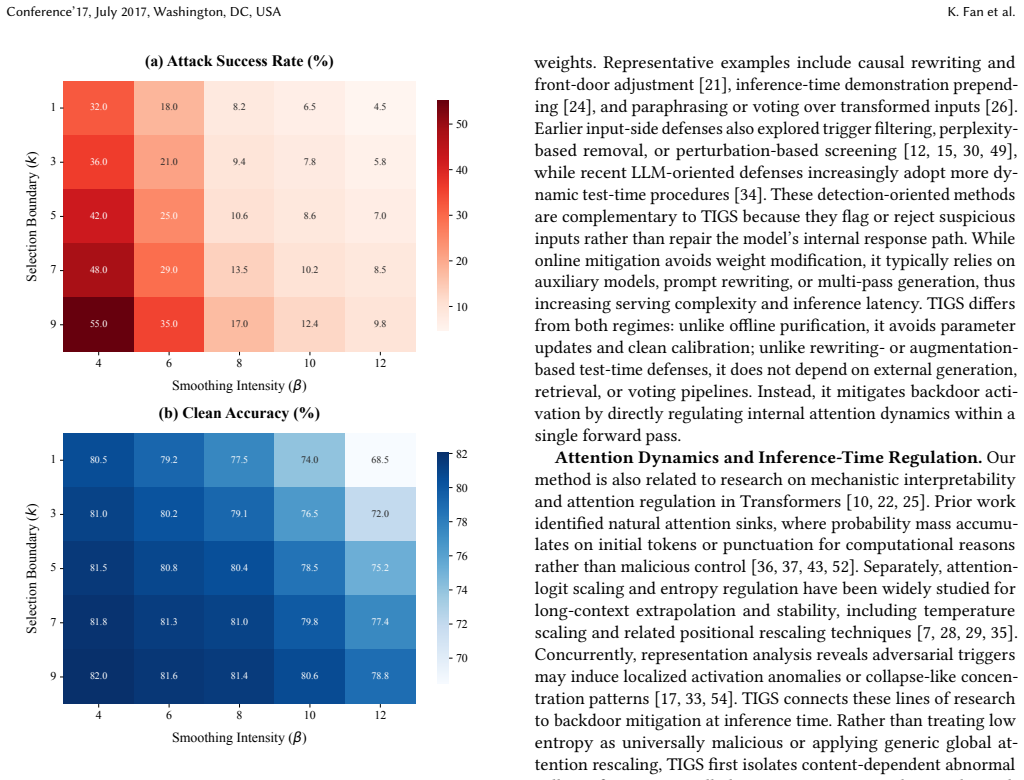

read the original abstract
Defending against backdoor attacks in large language models remains a critical practical challenge. Existing defenses mitigate these threats but typically incur high preparation costs and degrade utility via offline purification, or introduce severe latency via complex online interventions. To overcome this dichotomy, we present Tail-risk Intrinsic Geometric Smoothing (TIGS), a plug-and-play inference-time defense requiring no parameter updates, external clean data, or auxiliary generation. TIGS leverages the observation that successful backdoor triggers consistently induce localized attention collapse within the semantic content region. Operating entirely within the native forward pass, TIGS first performs content-aware tail-risk screening to identify suspicious attention heads and rows using sample-internal signals. It then applies intrinsic geometric smoothing: a weak content-domain correction preserves semantic anchoring, while a stronger full-row contraction disrupts trigger-dominant routing. Finally, a controlled full-row write-back reconstructs the attention matrix to ensure inference stability. Extensive evaluations demonstrate that TIGS substantially suppresses attack success rates while strictly preserving clean reasoning and open-ended semantic consistency. Crucially, this favorable security-utility-latency equilibrium persists across diverse architectures, including dense, reasoning-oriented, and sparse mixture-of-experts models. By structurally disrupting adversarial routing with marginal latency overhead, TIGS establishes a highly practical, deployment-ready defense standard for state-of-the-art LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Tail-risk Intrinsic Geometric Smoothing (TIGS), a plug-and-play inference-time defense against backdoor attacks in LLMs. It is motivated by the observation that successful triggers induce localized attention collapse in the semantic content region. TIGS uses content-aware tail-risk screening on attention heads/rows, followed by weak content-domain smoothing to preserve semantics and stronger full-row contraction to disrupt trigger routing, with a controlled write-back for stability. The authors claim this suppresses attack success rates (ASR) while strictly preserving clean reasoning and semantic consistency, with low latency, across dense, reasoning-oriented, and sparse MoE architectures, without any parameter updates, clean data, or auxiliary generation.
Significance. If the core attention-collapse observation generalizes and the claimed empirical results hold with the reported utility preservation, TIGS would be a significant practical contribution: an inference-only defense that avoids the high preparation costs and utility degradation of offline methods or the latency of complex online interventions, potentially establishing a deployment-ready standard for state-of-the-art LLMs.
major comments (3)
- [Abstract] Abstract: The abstract asserts that 'extensive evaluations demonstrate that TIGS substantially suppresses attack success rates while strictly preserving clean reasoning' but provides no quantitative results (e.g., ASR deltas, baseline comparisons, error bars, or ablation details), making it impossible to evaluate the magnitude or statistical reliability of the security-utility tradeoff.
- [Method (TIGS procedure)] The central premise (that backdoor triggers reliably produce localized attention collapse inside the semantic content region, distinct from natural clean-input variance) is used to justify the tail-risk screening step, yet no statistical tests, variance analysis, or cross-attack/model evidence is referenced to establish its generality; if this pattern is attack- or model-specific, the screening could either miss triggers or perturb clean attention, directly threatening both ASR suppression and the 'strictly preserving' utility claim.
- [Method (TIGS procedure)] The method introduces free parameters (tail-risk screening threshold and smoothing strength parameters) that must be set for the content-aware screening and weak/strong smoothing steps; this appears to contradict the 'plug-and-play' and 'no parameter updates' framing unless the paper shows these can be fixed universally without per-model tuning or validation data.
minor comments (1)
- [Abstract] The abstract's phrasing 'strictly preserving' is strong; a minor clarification on the precise metrics (e.g., exact match on reasoning tasks, semantic similarity thresholds) used to support this would improve precision.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of TIGS's potential significance and for the constructive major comments. We address each point below, agreeing where revisions are needed to enhance clarity and rigor, and provide explanations for the methodological choices.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts that 'extensive evaluations demonstrate that TIGS substantially suppresses attack success rates while strictly preserving clean reasoning' but provides no quantitative results (e.g., ASR deltas, baseline comparisons, error bars, or ablation details), making it impossible to evaluate the magnitude or statistical reliability of the security-utility tradeoff.
Authors: We concur that the abstract would benefit from including quantitative highlights to better illustrate the claimed tradeoffs. In the revised manuscript, we will modify the abstract to include key quantitative results such as ASR suppression levels, clean accuracy preservation rates, and references to baseline comparisons and ablations, while keeping the summary concise. revision: yes
-
Referee: [Method (TIGS procedure)] The central premise (that backdoor triggers reliably produce localized attention collapse inside the semantic content region, distinct from natural clean-input variance) is used to justify the tail-risk screening step, yet no statistical tests, variance analysis, or cross-attack/model evidence is referenced to establish its generality; if this pattern is attack- or model-specific, the screening could either miss triggers or perturb clean attention, directly threatening both ASR suppression and the 'strictly preserving' utility claim.
Authors: The full manuscript includes extensive evaluations across multiple LLMs and attack vectors showing the attention collapse pattern holds consistently for successful backdoors, with TIGS preserving utility on clean data. To strengthen this, we will add in the revision a new analysis subsection with variance statistics, cross-model comparisons, and formal tests (e.g., comparing attention entropy distributions between clean and triggered inputs) to rigorously support the generality of the observation. revision: yes
-
Referee: [Method (TIGS procedure)] The method introduces free parameters (tail-risk screening threshold and smoothing strength parameters) that must be set for the content-aware screening and weak/strong smoothing steps; this appears to contradict the 'plug-and-play' and 'no parameter updates' framing unless the paper shows these can be fixed universally without per-model tuning or validation data.
Authors: The parameters are not free in the sense of requiring tuning; they are set to fixed, universal values based on the intrinsic properties of attention distributions, as validated through our experiments on diverse architectures without any model-specific adjustment or clean data. We will revise the method description to explicitly list these default values, include a parameter sensitivity study demonstrating robustness, and clarify how the plug-and-play property is maintained. revision: yes
Circularity Check
No circularity: procedural defense defined from attention signals without self-referential reduction
full rationale
The paper defines TIGS as an inference-time procedure that screens attention heads/rows via tail-risk metrics on the native attention matrix and applies content-aware smoothing/write-back steps. These operations are specified directly from sample-internal attention values rather than from any fitted parameter, self-cited uniqueness result, or renamed prior pattern. The motivating observation of localized attention collapse is presented as an empirical premise external to the method itself; the subsequent steps do not derive or presuppose that observation in a closed loop. No equation or algorithmic step reduces to its own input by construction, and no load-bearing claim rests on author-overlapping citations.
Axiom & Free-Parameter Ledger
free parameters (2)
- tail-risk screening threshold
- smoothing strength parameters
axioms (1)
- domain assumption Backdoor triggers consistently produce localized attention collapse in the semantic content region
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review arXiv 2023
-
[2]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862(2022)
work page internal anchor Pith review arXiv 2022
-
[3]
Thomas Baumann. 2024. Universal jailbreak backdoors in large language model alignment. InNeurips Safe Generative AI Workshop 2024
2024
- [4]
-
[5]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168(2021)
work page internal anchor Pith review arXiv 2021
-
[6]
Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. 2023. Enhancing chat language models by scaling high-quality instructional conversations. InProceedings of the 2023 Con- ference on Empirical Methods in Natural Language Processing. 3029–3051
2023
- [7]
-
[8]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv e-prints(2024), arXiv–2407
2024
- [9]
-
[10]
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, et al. 2021. A mathematical framework for transformer circuits.Transformer Circuits Thread1, 1 (2021), 12
2021
-
[11]
Leilei Gan, Jiwei Li, Tianwei Zhang, Xiaoya Li, Yuxian Meng, Fei Wu, Yi Yang, Shangwei Guo, and Chun Fan. 2022. Triggerless backdoor attack for NLP tasks with clean labels. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies. 2942–2952
2022
-
[12]
Yansong Gao, Change Xu, Derui Wang, Shiping Chen, Damith C Ranasinghe, and Surya Nepal. 2019. Strip: A defence against trojan attacks on deep neural net- works. InProceedings of the 35th annual computer security applications conference. 113–125
2019
-
[13]
Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. 2017. Badnets: Identifying vulnerabilities in the machine learning model supply chain.arXiv preprint arXiv:1708.06733(2017)
work page internal anchor Pith review arXiv 2017
-
[14]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review arXiv 2025
- [15]
-
[16]
Keita Kurita, Paul Michel, and Graham Neubig. 2020. Weight poisoning attacks on pretrained models. InProceedings of the 58th annual meeting of the association for computational linguistics. 2793–2806
2020
-
[17]
Max Lamparth and Anka Reuel. 2024. Analyzing and editing inner mechanisms of backdoored language models. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency. 2362–2373
2024
- [18]
-
[19]
Yige Li, Xixiang Lyu, Nodens Koren, Lingjuan Lyu, Bo Li, and Xingjun Ma
- [20]
-
[21]
Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. 2018. Fine-pruning: De- fending against backdooring attacks on deep neural networks. InInternational symposium on research in attacks, intrusions, and defenses. Springer, 273–294
2018
-
[22]
Yiran Liu, Xiaoang Xu, Zhiyi Hou, and Yang Yu. 2024. Causality based front-door defense against backdoor attack on language models. InForty-first International Conference on Machine Learning
2024
-
[23]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in gpt.Advances in neural information processing systems35 (2022), 17359–17372
2022
- [24]
-
[25]
Wenjie Jacky Mo, Jiashu Xu, Qin Liu, Jiongxiao Wang, Jun Yan, Hadi Askari, Chaowei Xiao, and Muhao Chen. 2025. Test-time backdoor mitigation for black- box large language models with defensive demonstrations. InFindings of the Association for Computational Linguistics: NAACL 2025. 2232–2249
2025
-
[26]
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. 2022. In-context learning and induction heads.arXiv preprint arXiv:2209.11895(2022)
work page internal anchor Pith review arXiv 2022
-
[27]
Fei Ouyang, Di Zhang, Chunlong Xie, Hao Wang, and Tao Xiang. 2025. LLMBD: Backdoor defense via large language model paraphrasing and data voting in NLP. Knowledge-Based Systems324 (2025), 113737
2025
-
[28]
Xudong Pan, Mi Zhang, Beina Sheng, Jiaming Zhu, and Min Yang. 2022. Hidden trigger backdoor attack on {NLP} models via linguistic style manipulation. In 31st USENIX Security Symposium (USENIX Security 22). 3611–3628
2022
-
[29]
Bowen Peng and Jeffrey Quesnelle. 2023. Ntk-aware scaled rope allows llama models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation
2023
-
[30]
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. 2023. Yarn: Efficient context window extension of large language models.arXiv preprint arXiv:2309.00071(2023)
work page internal anchor Pith review arXiv 2023
-
[31]
Fanchao Qi, Yangyi Chen, Mukai Li, Yuan Yao, Zhiyuan Liu, and Maosong Sun
-
[32]
InProceedings of the 2021 conference on empirical methods in natural language processing
Onion: A simple and effective defense against textual backdoor attacks. InProceedings of the 2021 conference on empirical methods in natural language processing. 9558–9566
2021
-
[33]
Fanchao Qi, Yangyi Chen, Xurui Zhang, Mukai Li, Zhiyuan Liu, and Maosong Sun. 2021. Mind the style of text! adversarial and backdoor attacks based on text style transfer. InProceedings of the 2021 conference on empirical methods in natural language processing. 4569–4580
2021
-
[34]
Fanchao Qi, Mukai Li, Yangyi Chen, Zhengyan Zhang, Zhiyuan Liu, Yasheng Wang, and Maosong Sun. 2021. Hidden killer: Invisible textual backdoor attacks with syntactic trigger. InProceedings of the 59th Annual Meeting of the Associa- tion for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long...
2021
- [35]
-
[36]
Guangyu Shen, Siyuan Cheng, Zhuo Zhang, Guanhong Tao, Kaiyuan Zhang, Hanxi Guo, Lu Yan, Xiaolong Jin, Shengwei An, Shiqing Ma, et al . 2025. Bait: Large language model backdoor scanning by inverting attack target. In2025 IEEE Symposium on Security and Privacy (SP). IEEE, 1676–1694
2025
-
[37]
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. 2024. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing568 (2024), 127063
2024
- [38]
- [39]
-
[40]
Eric Wallace, Tony Zhao, Shi Feng, and Sameer Singh. 2021. Concealed data poisoning attacks on NLP models. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 139–150
2021
-
[41]
Bolun Wang, Yuanshun Yao, Shawn Shan, Huiying Li, Bimal Viswanath, Haitao Zheng, and Ben Y Zhao. 2019. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In2019 IEEE symposium on security and privacy (SP). IEEE, 707–723
2019
-
[42]
Harmless
Lijin Wang, Jingjing Wang, Tianshuo Cong, Xinlei He, Zhan Qin, and Xinyi Huang. 2025. From Purity to Peril: Backdooring Merged Models From" Harmless" Benign Components. In34th USENIX Security Symposium (USENIX Security 25). 6339–6358
2025
-
[43]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2023. Jailbroken: How does llm safety training fail?Advances in neural information processing systems 36 (2023), 80079–80110
2023
- [44]
-
[45]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis
-
[46]
Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453(2023)
work page internal anchor Pith review arXiv 2023
-
[47]
Ming Xu. 2023. Text2vec: Text to vector toolkit. https://github.com/shibing624/ text2vec
2023
-
[48]
Jun Yan, Vikas Yadav, Shiyang Li, Lichang Chen, Zheng Tang, Hai Wang, Vijay Srinivasan, Xiang Ren, and Hongxia Jin. 2024. Backdooring instruction-tuned large language models with virtual prompt injection. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume...
2024
-
[49]
Nan Yan, Yuqing Li, Xiong Wang, Jing Chen, Kun He, and Bo Li. 2025. {EmbedX}:{Embedding-Based} {Cross-Trigger} backdoor attack against large 14 Defusing the Trigger Conference’17, July 2017, Washington, DC, USA language models. In34th USENIX Security Symposium (USENIX Security 25). 241–257
2025
-
[50]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review arXiv 2025
-
[51]
Wenkai Yang, Xiaohan Bi, Yankai Lin, Sishuo Chen, Jie Zhou, and Xu Sun. 2024. Watch out for your agents! investigating backdoor threats to llm-based agents. Advances in Neural Information Processing Systems37 (2024), 100938–100964
2024
-
[52]
Wenkai Yang, Yankai Lin, Peng Li, Jie Zhou, and Xu Sun. 2021. Rap: Robustness- aware perturbations for defending against backdoor attacks on nlp models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 8365–8381
2021
- [53]
-
[54]
Yi Zeng, Weiyu Sun, Tran Huynh, Dawn Song, Bo Li, and Ruoxi Jia. 2024. Beear: Embedding-based adversarial removal of safety backdoors in instruction-tuned language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 13189–13215
2024
-
[55]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. 2023. H2o: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems36 (2023), 34661–34710
2023
-
[56]
Shuai Zhao, Xiaobao Wu, Cong-Duy T Nguyen, Yanhao Jia, Meihuizi Jia, Feng Yichao, and Luu Anh Tuan. 2025. Unlearning backdoor attacks for llms with weak- to-strong knowledge distillation. InFindings of the Association for Computational Linguistics: ACL 2025. 4937–4952
2025
-
[57]
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al
-
[58]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation engineering: A top-down approach to ai transparency. arXiv preprint arXiv:2310.01405(2023). 15 Conference’17, July 2017, Washington, DC, USA K. Fan et al. A Theoretical Details This appendix collects the formal derivations deferred from the main text, including the entropy-collapse analysis, the content- domain intrinsic smoothing component...
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.