AdapTime: Enabling Adaptive Temporal Reasoning in Large Language Models
Pith reviewed 2026-05-08 03:41 UTC · model grok-4.3
The pith
AdapTime lets LLMs dynamically select among reformulate, rewrite, and review steps for temporal questions via an internal planner.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AdapTime is an adaptive temporal reasoning method that dynamically executes reasoning steps based on the input context. It involves three temporal reasoning actions: reformulate, rewrite and review, with an LLM planner guiding the reasoning process. AdapTime integrates seamlessly with state-of-the-art LLMs and significantly enhances their temporal reasoning capabilities without relying on external support.
What carries the argument
An LLM planner that selects and sequences the three actions (reformulate, rewrite, review) to match the needs of each temporal question.
Load-bearing premise
The LLM planner can reliably and correctly decide which actions or sequence is needed for any given temporal question, and that this dynamic choice works better than fixed pipelines for both simple and complex cases.
What would settle it
A side-by-side evaluation on temporal reasoning benchmarks where replacing the planner with a fixed sequence of all three actions produces equal or higher accuracy than the full AdapTime method.
Figures


read the original abstract
Large language models have demonstrated strong reasoning capabilities in general knowledge question answering. However, their ability to handle temporal information remains limited. To address this limitation, existing approaches often involve external tools or manual verification and are tailored to specific scenarios, leading to poor generalizability. Moreover, these methods apply a fixed pipeline to all questions, overlooking the fact that different types of temporal questions require distinct reasoning strategies, which leads to unnecessary processing for simple cases and inadequate reasoning for complex ones. To this end, we propose AdapTime, an adaptive temporal reasoning method that dynamically executes reasoning steps based on the input context. Specifically, it involves three temporal reasoning actions: reformulate, rewrite and review, with an LLM planner guiding the reasoning process. AdapTime integrates seamlessly with state-of-the-art LLMs and significantly enhances their temporal reasoning capabilities without relying on external support. Extensive experiments demonstrate the effectiveness of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AdapTime, a method for adaptive temporal reasoning in LLMs. It uses an LLM planner to dynamically choose and sequence among three actions—reformulate, rewrite, and review—depending on the input temporal question's complexity. The approach is presented as integrating directly with existing LLMs, avoiding external tools or fixed pipelines, and the abstract states that extensive experiments confirm it significantly improves temporal reasoning capabilities.
Significance. If the central claims hold—specifically that the planner makes reliable, superior decisions and that this yields measurable gains over fixed strategies—AdapTime would offer a lightweight, generalizable way to enhance LLMs on temporal tasks without added infrastructure. This could be useful for applications like timeline extraction or event-based QA, by avoiding overkill on simple cases while providing deeper reasoning where needed.
major comments (3)
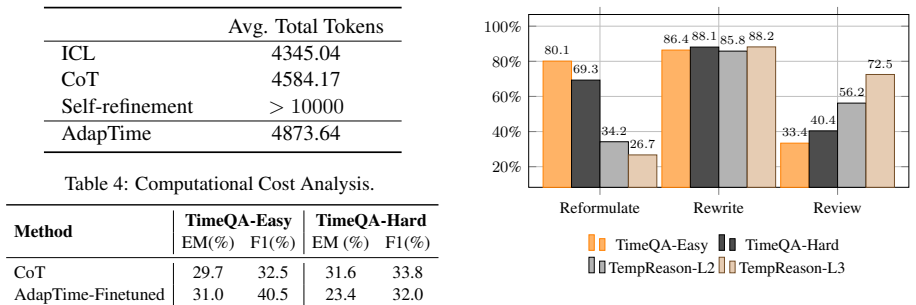
- [Abstract] The abstract claims 'extensive experiments demonstrate the effectiveness' yet reports no baselines, metrics (e.g., accuracy, F1), error bars, or ablations. This is load-bearing for the central claim, as the value of adaptivity cannot be assessed without evidence that the planner's dynamic choices outperform always applying all three actions or fixed pipelines.
- [Method (planner description)] No details are provided on the LLM planner's prompt, decision accuracy, or how it selects among reformulate/rewrite/review (or sequences). Without empirical validation of planner reliability (e.g., human or automatic evaluation of action choices on a held-out set), the adaptivity advantage reduces to standard multi-step prompting.
- [Experiments] The experiments section (assuming standard structure) must include an ablation isolating the planner's contribution versus fixed application of all actions; absent this, gains cannot be attributed to adaptivity rather than simply using more reasoning steps.
minor comments (2)
- [Method] Clarify whether the three actions are mutually exclusive or can be sequenced, and provide the exact planner prompt template used.
- [Experiments] Add a table comparing AdapTime against at least two strong baselines (e.g., standard CoT, self-consistency) on the temporal QA datasets used.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and constructive suggestions. We will revise the manuscript to provide more details on the experimental results, the planner's implementation, and additional ablations as requested.
read point-by-point responses
-
Referee: [Abstract] The abstract claims 'extensive experiments demonstrate the effectiveness' yet reports no baselines, metrics (e.g., accuracy, F1), error bars, or ablations. This is load-bearing for the central claim, as the value of adaptivity cannot be assessed without evidence that the planner's dynamic choices outperform always applying all three actions or fixed pipelines.
Authors: We acknowledge that the abstract is currently high-level. We will revise the abstract to include specific metrics such as accuracy and F1, mention the baselines (including fixed pipelines), and note the improvements with error bars. This will better substantiate the effectiveness claims. revision: yes
-
Referee: [Method (planner description)] No details are provided on the LLM planner's prompt, decision accuracy, or how it selects among reformulate/rewrite/review (or sequences). Without empirical validation of planner reliability (e.g., human or automatic evaluation of action choices on a held-out set), the adaptivity advantage reduces to standard multi-step prompting.
Authors: We will add the full prompt used by the LLM planner to the method section or appendix. We will also include an evaluation of the planner's decision accuracy on a held-out set, using automatic evaluation where feasible, to demonstrate that the adaptive choices are reliable and not equivalent to fixed multi-step prompting. revision: yes
-
Referee: [Experiments] The experiments section (assuming standard structure) must include an ablation isolating the planner's contribution versus fixed application of all actions; absent this, gains cannot be attributed to adaptivity rather than simply using more reasoning steps.
Authors: We agree that isolating the planner's contribution is important. We will add an ablation study in the experiments section that compares AdapTime to a non-adaptive version that applies all actions in a fixed sequence, as well as other fixed strategies. This will show that the dynamic selection by the planner provides benefits beyond additional reasoning steps. revision: yes
Circularity Check
No circularity in claimed derivation
full rationale
The paper describes AdapTime as an engineering method that combines existing LLM prompting capabilities via a planner selecting among reformulate/rewrite/review actions. No equations, fitted parameters, or mathematical derivations are present in the provided text. The approach is presented as a dynamic combination of standard LLM behaviors rather than a derivation that reduces to its own inputs by construction, self-citation chains, or renamed empirical patterns. The central claim rests on experimental validation of the adaptive pipeline, which is independent of any self-referential loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models possess sufficient internal reasoning and planning ability to act as both executor and planner for temporal questions.
Reference graph
Works this paper leans on
-
[1]
doi:10.48550/arXiv.2311.17667 , abstract =
A dataset for answering time-sensitive ques- tions. InProceedings of the Neural Information Pro- cessing Systems Track on Datasets and Benchmarks (NeurIPS Datasets and Benchmarks). Zheng Chu, Jingchang Chen, Qianglong Chen, Weijiang Yu, Haotian Wang, Ming Liu, and Bing Qin. 2023. Timebench: A comprehensive evaluation of temporal reasoning abilities in lar...
-
[2]
MILL: mutual verification with large language models for zero-shot query expansion. InProceed- ings of the 2024 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, Mexico, June 16-21, 2024, pages 2498–2518. Association for Computational L...
work page 2024
-
[3]
In Proceedings of the AAAI conference on artificial in- telligence, volume 38, pages 18608–18616
Flexkbqa: A flexible llm-powered framework for few-shot knowledge base question answering. In Proceedings of the AAAI conference on artificial in- telligence, volume 38, pages 18608–18616. Qidong Liu, Xian Wu, Wanyu Wang, Yejing Wang, Yuanshao Zhu, Xiangyu Zhao, Feng Tian, and Yefeng Zheng. 2025a. Llmemb: Large language model can be a good embedding gener...
work page 2025
-
[4]
InFindings of the Association for Compu- tational Linguistics: EMNLP 2024, pages 247–266
Snapntell: Enhancing entity-centric visual question answering with retrieval augmented multi- modal llm. InFindings of the Association for Compu- tational Linguistics: EMNLP 2024, pages 247–266. Zhenwei Shao, Zhou Yu, Meng Wang, and Jun Yu. 2023. Prompting large language models with answer heuris- tics for knowledge-based visual question answering. InProc...
work page 2024
-
[5]
Archivalqa: A large-scale benchmark dataset for open-domain question answering over historical news collections. InProceedings of the 45th Inter- national ACM SIGIR Conference on Research and Development in Information Retrieval, pages 3025– 3035. Yuhao Wang, Xiangyu Zhao, Bo Chen, Qidong Liu, Huifeng Guo, Huanshuo Liu, Yichao Wang, Rui Zhang, and Ruiming...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.