Recognition: unknown
CMGL: Confidence-guided Multi-omics Graph Learning for Cancer Subtype Classification
Pith reviewed 2026-05-08 04:13 UTC · model grok-4.3
The pith
CMGL separates modality reliability estimation from graph-based classification to reduce noise in multi-omics cancer subtyping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
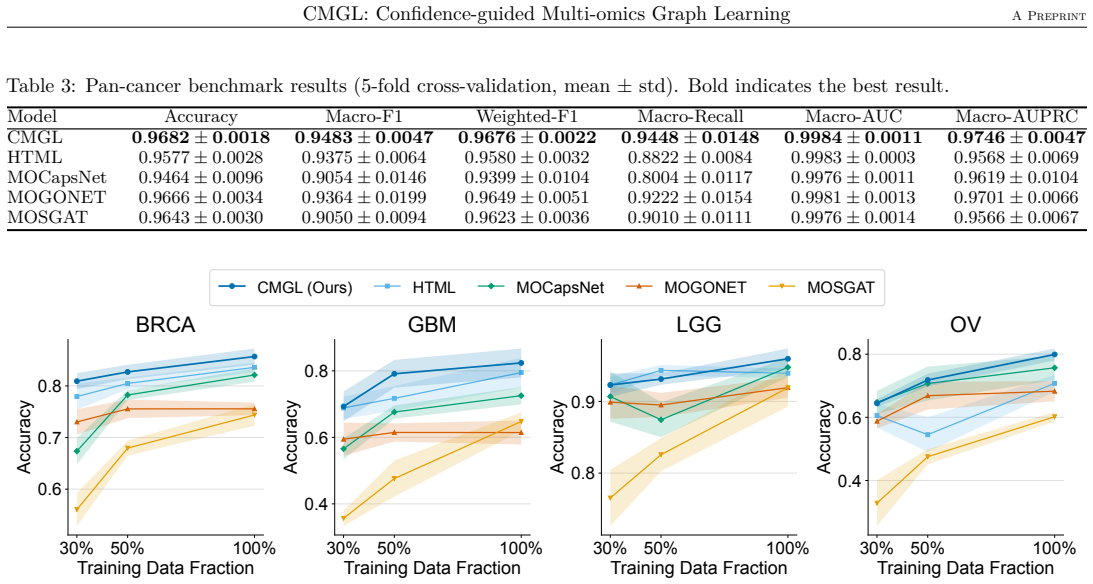
CMGL estimates per-sample modality reliability through evidential deep learning and uses the frozen confidence scores to guide cross-omics fusion and graph construction, leading to improved accuracy on cancer subtype tasks, recovery of PAM50 subtypes in BRCA, and zero-shot transfer to KIRC for prognostic grouping.
What carries the argument
Frozen per-sample confidence scores from evidential deep learning that guide cross-omics fusion and patient similarity graph construction.
If this is right
- Average accuracy on four single-cancer tasks rises by 4.03 percent compared to the best prior method.
- Learned representations recover the PAM50 intrinsic subtypes for breast invasive carcinoma.
- A model trained only on breast cancer data transfers to kidney cancer and separates patients by survival differences.
- The approach accounts for patient-specific and cancer-specific differences in data quality.
Where Pith is reading between the lines
- This two-stage process could be applied to other multi-modal problems where some data sources are noisier than others for certain samples.
- The observed transferability hints at building more generalizable models across related cancer types.
- If the confidence estimates prove robust, they might serve as a way to flag patients for whom certain tests are less informative.
- Testing on additional cancer types or with different omics combinations would clarify the method's scope.
Load-bearing premise
The reliability estimates from the first stage remain accurate and useful when frozen rather than being adjusted together with the classification goal.
What would settle it
Running an ablation where confidence scores are jointly optimized instead of frozen, and checking if performance drops on the same tasks.
Figures






read the original abstract
Motivation: Multi-omics integration can improve cancer subtyping, but modality informativeness and noise vary across cancer types and patients. Existing graph-based methods optimize modality weights jointly with the classification objective and therefore lack independent reliability estimates, so low-quality omics distort patient similarity graphs and amplify noise through message passing. Results: We propose CMGL, a two-stage framework that estimates per-sample modality reliability through evidential deep learning and uses the frozen confidence scores to guide cross-omics fusion and graph construction. On four MLOmics cancer-subtype tasks and the 32-class pan-cancer task, CMGL consistently improves over the strongest baseline, surpassing it by 4.03% in average accuracy on the four single-cancer tasks. Its representations recover the PAM50 intrinsic subtypes of breast invasive carcinoma (BRCA), and the BRCA-trained model transfers without fine-tuning to kidney renal clear cell carcinoma (KIRC), stratifying patients into prognostically distinct groups.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CMGL, a two-stage framework for multi-omics cancer subtype classification. Stage one uses evidential deep learning to produce per-sample, per-modality reliability scores. These scores are frozen and fed into stage two to guide cross-omics fusion and patient similarity graph construction before graph neural network classification. On four single-cancer subtype tasks the method reports a 4.03% average accuracy gain over the strongest baseline; the learned representations recover PAM50 subtypes in BRCA and the BRCA-trained model transfers zero-shot to KIRC, producing prognostically distinct strata.
Significance. If the reported gains are shown to stem from the decoupled reliability mechanism rather than standard GNN training, and if the transfer result generalizes, the work would offer a practical advance in multi-omics integration by mitigating distortion from low-quality modalities. The explicit two-stage design with frozen scores is a clear methodological strength that lowers circular-optimization risk relative to joint-training baselines. The zero-shot cross-cancer transfer is a notable empirical contribution that merits further exploration.
major comments (2)
- [Methods (evidential stage)] Methods section on evidential deep learning: the central claim that frozen per-sample modality reliability scores are independent of the subtype classification objective is load-bearing. The manuscript does not state whether the evidential models are trained on the same labeled patient samples later used for graph supervision and evaluation. If labels are used, the scores can still encode task-specific information, weakening the argument that the two-stage pipeline prevents circular fitting. An explicit training protocol, loss function, or ablation demonstrating orthogonality to subtype labels is required.
- [Experiments / Results] Results section and associated tables: the 4.03% average accuracy improvement is presented without the number of independent runs, standard deviations, or statistical significance tests (e.g., paired t-test p-values) against the strongest baseline. Without these, it is impossible to assess whether the gain is robust or attributable to the confidence-guided fusion rather than implementation variance. The KIRC transfer experiment similarly lacks detail on graph construction without fine-tuning and the exact survival metrics used to confirm prognostic stratification.
minor comments (2)
- [Abstract] Abstract: the four single-cancer tasks are not named; listing the cancer types and cohort sizes would improve readability and allow immediate assessment of scope.
- [Figure 1] Figure 1 (pipeline diagram): arrows indicating the flow of frozen confidence scores into fusion and graph construction should be explicitly labeled to clarify information boundaries between stages.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which help clarify key aspects of our two-stage framework. We address each major comment below and will revise the manuscript to incorporate the requested details and clarifications.
read point-by-point responses
-
Referee: Methods section on evidential deep learning: the central claim that frozen per-sample modality reliability scores are independent of the subtype classification objective is load-bearing. The manuscript does not state whether the evidential models are trained on the same labeled patient samples later used for graph supervision and evaluation. If labels are used, the scores can still encode task-specific information, weakening the argument that the two-stage pipeline prevents circular fitting. An explicit training protocol, loss function, or ablation demonstrating orthogonality to subtype labels is required.
Authors: We agree that explicit details on the evidential stage are necessary to substantiate the independence claim. The evidential models are trained separately on each modality using the subtype labels available for that modality, but the resulting per-sample reliability scores are computed from the Dirichlet evidence parameters and then frozen prior to any graph construction or GNN training. This separation ensures that the fusion stage cannot back-propagate into the confidence estimation. To strengthen the manuscript, we will expand the Methods section with the precise training protocol, the evidential loss function (based on the Dirichlet distribution as in Sensoy et al.), and an additional ablation comparing learned confidences against random or uniform scores. These changes will be made in the revised version. revision: yes
-
Referee: Results section and associated tables: the 4.03% average accuracy improvement is presented without the number of independent runs, standard deviations, or statistical significance tests (e.g., paired t-test p-values) against the strongest baseline. Without these, it is impossible to assess whether the gain is robust or attributable to the confidence-guided fusion rather than implementation variance. The KIRC transfer experiment similarly lacks detail on graph construction without fine-tuning and the exact survival metrics used to confirm prognostic stratification.
Authors: We acknowledge that the current reporting lacks the statistical rigor needed to evaluate robustness. In our experiments, all results were obtained from 5 independent runs with different random seeds; we will add the corresponding means, standard deviations, and paired t-test p-values against the strongest baseline to the tables and text. For the KIRC zero-shot transfer, the patient similarity graph is constructed exactly as in the BRCA setting using the frozen BRCA-derived confidence scores with no fine-tuning or label access on KIRC; we will explicitly describe this protocol and report the precise survival metrics (log-rank test p-values and Kaplan-Meier stratification details) in the revised Results section. revision: yes
Circularity Check
No significant circularity; two-stage frozen pipeline keeps reliability estimates independent of final graph supervision
full rationale
The paper explicitly describes a two-stage process: evidential deep learning first produces per-sample modality reliability scores, which are then frozen before being used to guide cross-omics fusion and patient similarity graph construction. The central claims (accuracy gains of 4.03% and transfer performance) are presented as empirical results on external benchmarks rather than algebraic identities or fitted parameters renamed as predictions. No equation or step reduces the output to the input by construction, no self-citation chain is load-bearing for the uniqueness of the approach, and the separation of stages is stated to avoid joint optimization with the classification objective. This structure is self-contained against the reported external validation tasks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Evidential deep learning produces reliable per-sample modality confidence scores independent of the classification loss
Reference graph
Works this paper leans on
-
[1]
A. R. Brannon, A. Reddy, M. Seiler, A. Arreola, D. T. Moore, R. S. Pruthi, E. M. Wallen, M. E. Nielsen, H. Liu, K. L. Nathanson, et al. Molecular stratification of clear cell renal cell carcinoma by consensus clustering reveals distinct subtypes and survival patterns. Genes & Cancer, 1: 0 152--163, 2010
2010
-
[2]
Cheerla and O
A. Cheerla and O. Gevaert. Deep learning with multimodal representation for pancancer prognosis prediction. Bioinformatics, 35: 0 i446--i454, 2019
2019
-
[3]
E. Y. Chen, C. M. Tan, Y. Kou, Q. Duan, Z. Wang, G. V. Meirelles, N. R. Clark, and A. Ma'ayan. Enrichr : interactive and collaborative HTML5 gene list enrichment analysis tool. BMC Bioinformatics, 14: 0 128, 2013
2013
-
[4]
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton. A simple framework for contrastive learning of visual representations. In International Conference on Machine Learning (ICML), pages 1597--1607, 2020
2020
-
[5]
W. Du, L. Zhang, A. Brett-Morris, et al. HIF drives lipid deposition and cancer in ccRCC via repression of fatty acid metabolism. Nature Communications, 8: 0 1769, 2017
2017
-
[6]
Gal and Z
Y. Gal and Z. Ghahramani. Dropout as a B ayesian approximation: Representing model uncertainty in deep learning. In International Conference on Machine Learning (ICML), pages 1050--1059, 2016
2016
-
[7]
C. Guo, G. Pleiss, Y. Sun, and K. Q. Weinberger. On calibration of modern neural networks. In International Conference on Machine Learning (ICML), pages 1321--1330, 2017
2017
-
[8]
W. L. Hamilton, R. Ying, and J. Leskovec. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems (NeurIPS), pages 1024--1034, 2017
2017
-
[9]
Z. Han, C. Zhang, H. Fu, and J. T. Zhou. Trusted multi-view classification with dynamic evidential fusion. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45: 0 2551--2566, 2023
2023
-
[10]
Hasin, M
Y. Hasin, M. Seldin, and A. Lusis. Multi-omics approaches to disease. Genome Biology, 18: 0 83, 2017
2017
-
[11]
K. A. Hoadley, C. Yau, T. Hinoue, D. M. Wolf, A. J. Lazar, E. Drill, R. Shen, A. M. Taylor, A. D. Cherniack, V. Thorsson, et al. Cell-of-origin patterns dominate the molecular classification of 10,000 tumors from 33 types of cancer. Cell, 173: 0 291--304, 2018
2018
-
[12]
Hongo, N
F. Hongo, N. Takaha, M. Oishi, T. Ueda, T. Nakamura, Y. Naitoh, Y. Naya, K. Kamoi, K. Okihara, T. Matsushima, S. Nakayama, H. Ishihara, T. Sakai, and T. Miki. CDK1 and CDK2 activity is a strong predictor of renal cell carcinoma recurrence. Urologic Oncology, 32: 0 1240--1246, 2014
2014
-
[13]
Hu et al
C. Hu et al. NDC80 status pinpoints mitotic kinase inhibitors as emerging therapeutic options in clear cell renal cell carcinoma. iScience, 26: 0 106531, 2023
2023
-
[14]
A. J sang. Subjective Logic: A Formalism for Reasoning Under Uncertainty. Springer, 2016
2016
-
[15]
Khosla, P
P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y. Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan. Supervised contrastive learning. In Advances in Neural Information Processing Systems (NeurIPS), pages 18661--18673, 2020
2020
-
[16]
M. V. Kuleshov, M. R. Jones, A. D. Rouillard, N. F. Fernandez, Q. Duan, Z. Wang, S. Koplev, S. L. Jenkins, K. M. Jagodnik, A. Lachmann, et al. Enrichr : a comprehensive gene set enrichment analysis web server 2016 update. Nucleic Acids Research, 44: 0 W90--W97, 2016
2016
-
[17]
Lakshminarayanan, A
B. Lakshminarayanan, A. Pritzel, and C. Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. In Advances in Neural Information Processing Systems (NeurIPS), pages 6402--6413, 2017
2017
-
[18]
B. Li, X. Xiao, C. Zhang, M. Xiao, and L. Zhang. DGHNN : a deep graph and hypergraph neural network for pan-cancer related gene prediction. Bioinformatics, 41 0 (7): 0 btaf379, 2025
2025
-
[19]
Li, F.-X
Y. Li, F.-X. Wu, and A. Ngom. A review on machine learning principles for multi-view biological data integration. Briefings in Bioinformatics, 19: 0 325--340, 2018
2018
-
[20]
Y. Lu, R. Peng, L. Dong, K. Xia, R. Wu, S. Xu, and J. Wang. Multiomics dynamic learning enables personalized diagnosis and prognosis for pancancer and cancer subtypes. Briefings in Bioinformatics, 24 0 (6): 0 bbad378, 2023
2023
-
[21]
Malinin and M
A. Malinin and M. Gales. Predictive uncertainty estimation via prior networks. In Advances in Neural Information Processing Systems (NeurIPS), pages 7047--7058, 2018
2018
-
[22]
M \"u ller, S
R. M \"u ller, S. Kornblith, and G. E. Hinton. When does label smoothing help? In Advances in Neural Information Processing Systems (NeurIPS), pages 4694--4703, 2019
2019
-
[23]
M. P. Naeini, G. F. Cooper, and M. Hauskrecht. Obtaining well calibrated probabilities using B ayesian binning. In AAAI Conference on Artificial Intelligence, pages 2901--2907, 2015
2015
-
[24]
C. M. Perou, T. S rlie, M. B. Eisen, M. van de Rijn, S. S. Jeffrey, C. A. Rees, J. R. Pollack, D. T. Ross, H. Johnsen, L. A. Akslen, et al. Molecular portraits of human breast tumours. Nature, 406: 0 747--752, 2000
2000
-
[25]
Picard, M.-P
M. Picard, M.-P. Scott-Boyer, A. Bodein, O. P \'e rin, and A. Droit. Integration strategies of multi-omics data for machine learning analysis. Computational and Structural Biotechnology Journal, 19: 0 3735--3746, 2021
2021
-
[26]
Platten, E
M. Platten, E. A. A. Nollen, U. F. R \"o hrig, F. Fallarino, and C. A. Opitz. Tryptophan metabolism as a common therapeutic target in cancer, neurodegeneration and beyond. Nature Reviews Drug Discovery, 18: 0 379--401, 2019
2019
-
[27]
A. Prat, E. Pineda, B. Adamo, P. Galv \'a n, A. Fern \'a ndez, L. Gaba, M. D \'i ez, M. Viladot, A. Arance, and M. Mu \ n oz. Clinical implications of the intrinsic molecular subtypes of breast cancer. The Breast, 24: 0 S26--S35, 2015
2015
-
[28]
Rappoport and R
N. Rappoport and R. Shamir. Multi-omic and multi-view clustering algorithms: review and cancer benchmark. Nucleic Acids Research, 46: 0 10546--10562, 2018
2018
-
[29]
M. D. Ritchie, E. R. Holzinger, R. Li, S. A. Pendergrass, and D. Kim. Methods of integrating data to uncover genotype--phenotype interactions. Nature Reviews Genetics, 16: 0 85--97, 2015
2015
-
[30]
P. J. Rousseeuw. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics, 20: 0 53--65, 1987
1987
-
[31]
Sabour, N
S. Sabour, N. Frosst, and G. E. Hinton. Dynamic routing between capsules. In Advances in Neural Information Processing Systems (NeurIPS), pages 3856--3866, 2017
2017
-
[32]
Sensoy, L
M. Sensoy, L. Kaplan, and M. Kandemir. Evidential deep learning to quantify classification uncertainty. In Advances in Neural Information Processing Systems (NeurIPS), pages 3179--3189, 2018
2018
-
[33]
Tanaka et al
M. Tanaka et al. The endothelial adrenomedullin-- RAMP2 system regulates vascular integrity and suppresses tumour metastasis. Cardiovascular Research, 111 0 (4): 0 398--409, 2016
2016
-
[34]
Comprehensive genomic characterization defines human glioblastoma genes and core pathways
The Cancer Genome Atlas Network . Comprehensive genomic characterization defines human glioblastoma genes and core pathways. Nature, 455: 0 1061--1068, 2008
2008
-
[35]
Integrated genomic analyses of ovarian carcinoma
The Cancer Genome Atlas Network . Integrated genomic analyses of ovarian carcinoma. Nature, 474: 0 609--615, 2011
2011
-
[36]
Comprehensive molecular portraits of human breast tumours
The Cancer Genome Atlas Network . Comprehensive molecular portraits of human breast tumours. Nature, 490: 0 61--70, 2012
2012
-
[37]
Comprehensive molecular characterization of clear cell renal cell carcinoma
The Cancer Genome Atlas Network . Comprehensive molecular characterization of clear cell renal cell carcinoma. Nature, 499: 0 43--49, 2013
2013
-
[38]
Comprehensive, integrative genomic analysis of diffuse lower-grade gliomas
The Cancer Genome Atlas Network . Comprehensive, integrative genomic analysis of diffuse lower-grade gliomas. New England Journal of Medicine, 372: 0 2481--2498, 2015
2015
-
[39]
van der Maaten and G
L. van der Maaten and G. Hinton. Visualizing data using t-SNE . Journal of Machine Learning Research, 9: 0 2579--2605, 2008
2008
-
[40]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, . Kaiser, and I. Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems (NeurIPS), pages 5998--6008, 2017
2017
-
[41]
Wang et al
F.-A. Wang et al. TMO-Net : an explainable pretrained multi-omics model for multi-task learning in oncology. Genome Biology, 25: 0 149, 2024
2024
-
[42]
T. Wang, W. Shao, Z. Huang, H. Tang, J. Zhang, Z. Ding, and K. Huang. MOGONET integrates multi-omics data using graph convolutional networks allowing patient classification and biomarker identification. Nature Communications, 12: 0 3445, 2021
2021
-
[43]
W. Wu, S. Wang, Y. Zhang, W. Yin, Y. Zhao, and S. Pang. MOSGAT : Uniting specificity-aware GAT s and cross modal-attention to integrate multi-omics data for disease diagnosis. IEEE Journal of Biomedical and Health Informatics, 28 0 (9): 0 5624--5637, 2024
2024
-
[44]
M. Xie, Y. Kuang, M. Song, and E. Bao. Subtype-MGTP : a cancer subtype identification framework based on multi-omics translation. Bioinformatics, 40 0 (6): 0 btae360, 2024
2024
-
[45]
Y. Xie, X. Ma, L. Gu, H. Li, L. Chen, X. Li, Y. Gao, Y. Fan, Y. Zhang, Y. Yao, and X. Zhang. Prognostic and clinicopathological significance of survivin expression in renal cell carcinoma: a systematic review and meta-analysis. Scientific Reports, 6: 0 29794, 2016
2016
-
[46]
Z. Yang, R. Kotoge, et al. MLOmics : Cancer multi-omics database for machine learning. Scientific Data, 12: 0 913, 2025
2025
-
[47]
Zhang, F
Q. Zhang, F. Liu, and X. Lai. HallmarkGraph : a cancer hallmark informed graph neural network for classifying hierarchical tumor subtypes. Bioinformatics, 41 0 (9): 0 btaf444, 2025 a
2025
-
[48]
Y. Zhang, H. Zheng, X. Meng, Q. Wang, Z. Li, and W. Wu. MOCapsNet : Multiomics data integration for cancer subtype analysis based on dynamic self-attention learning and capsule networks. Journal of Chemical Information and Modeling, 65 0 (3): 0 1653--1665, 2025 b . doi:10.1021/acs.jcim.4c02130
-
[49]
J. Zhao, X. Xie, X. Xu, and S. Sun. Multi-view learning overview: Recent progress and new challenges. Information Fusion, 38: 0 43--54, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.