Recognition: unknown
Generating Place-Based Compromises Between Two Points of View
Pith reviewed 2026-05-08 03:32 UTC · model grok-4.3
The pith
Using iterative empathic similarity feedback generates more acceptable compromises between opposing viewpoints than standard chain-of-thought reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
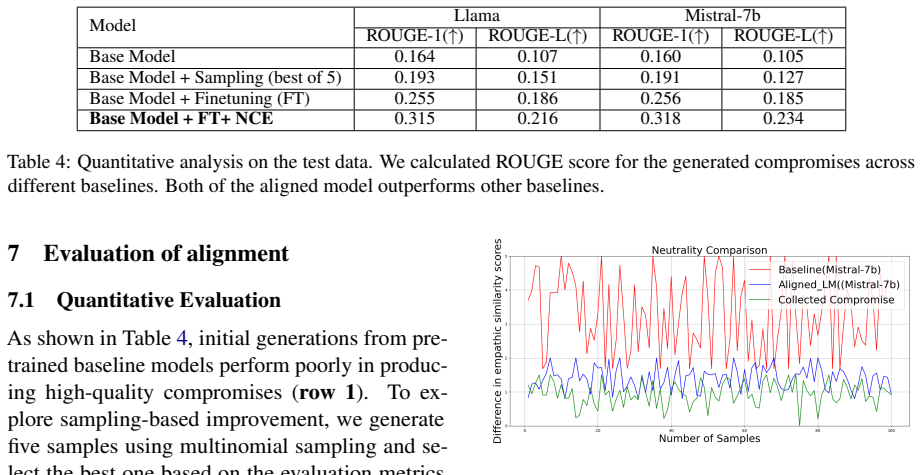
The authors demonstrate that an iterative process incorporating external assessments of empathic similarity to both viewpoints produces compromises with higher acceptability ratings in a human evaluation study than those generated via standard chain-of-thought prompting, and that the resulting dataset supports training smaller models through margin-based preference alignment for efficient deployment.
What carries the argument
The iterative empathic similarity feedback mechanism, which evaluates proposed compromises for their neutrality by measuring similarity to each original viewpoint and uses this to guide further generation.
If this is right
- Compromises from the empathic feedback method receive higher acceptability scores from human evaluators than those from chain-of-thought.
- Smaller models trained on the generated dataset achieve comparable performance while eliminating the need for empathy estimation at inference.
- The method improves the social intelligence of LLMs in handling viewpoint conflicts on shared places.
- Margin-based alignment allows efficient transfer of the compromise generation capability to compact models.
Where Pith is reading between the lines
- Similar feedback techniques might enhance compromise generation in non-place-based disputes if appropriate similarity metrics are defined.
- Integration into dialogue systems could help mediate online disagreements in real time using the trained smaller models.
- Expanding the dataset with more diverse viewpoints could reduce potential biases in the trained models.
Load-bearing premise
The 50-participant acceptability study accurately measures compromise quality without bias from the specific participants or the presentation of the viewpoints.
What would settle it
Conducting an acceptability study with a much larger and demographically diverse participant group that shows no advantage for the empathic similarity method over standard chain-of-thought prompting.
Figures




read the original abstract
Large Language Models (LLMs) excel academically but struggle with social intelligence tasks, such as creating good compromises. In this paper, we present methods for generating empathically neutral compromises between two opposing viewpoints. We first compared four different prompt engineering methods using Claude 3 Opus and a dataset of 2,400 contrasting views on shared places. A subset of the gen erated compromises was evaluated for acceptability in a 50-participant study. We found that the best method for generating compromises between two views used external empathic similarity between a compromise and each viewpoint as iterative feedback, outperforming stan dard Chain of Thought (CoT) reasoning. The results indicate that the use of empathic neutrality improves the acceptability of compromises. The dataset of generated compromises was then used to train two smaller foundation models via margin-based alignment of human preferences, improving efficiency and removing the need for empathy estimation during inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes prompt-engineering methods for generating empathically neutral compromises between opposing viewpoints on shared places. Using Claude 3 Opus and a dataset of 2,400 contrasting views, it compares four methods and identifies iterative external empathic similarity feedback as superior to standard Chain-of-Thought reasoning. A 50-participant acceptability study supports the claim that empathic neutrality improves compromise quality. The generated dataset is then used to train smaller models via margin-based alignment of human preferences, enabling efficient inference without ongoing empathy estimation.
Significance. If the empirical findings hold after proper validation, the work offers a concrete technique for enhancing LLMs on social-intelligence tasks such as compromise generation. The distillation step to smaller models is a practical strength that could improve deployability. The iterative empathic-feedback approach is a potentially reusable idea for prompt design in value-laden domains.
major comments (2)
- [Evaluation section (and abstract)] The 50-participant acceptability study is load-bearing for the central claim that the empathic method outperforms CoT and improves acceptability, yet the manuscript provides no details on participant recruitment, blinding, inter-rater agreement, exact scoring protocol, or statistical tests (e.g., no mention of p-values, effect sizes, or power analysis).
- [Model training and alignment section] Training the smaller foundation models on compromises generated by the same empathic method under evaluation creates a circularity risk: any systematic artifacts or biases in the original LLM outputs are inherited by the fine-tuned models rather than validated against independent human or external benchmarks.
minor comments (2)
- [Abstract] Abstract contains typographical errors (e.g., 'gen erated', 'stan dard') that should be corrected for clarity.
- [Methods] The description of the four prompt-engineering methods would benefit from explicit pseudocode or example prompts to allow replication.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We have carefully considered the major comments and provide point-by-point responses below. We will revise the manuscript accordingly to address the concerns raised.
read point-by-point responses
-
Referee: The 50-participant acceptability study is load-bearing for the central claim that the empathic method outperforms CoT and improves acceptability, yet the manuscript provides no details on participant recruitment, blinding, inter-rater agreement, exact scoring protocol, or statistical tests (e.g., no mention of p-values, effect sizes, or power analysis).
Authors: We agree that additional details on the human evaluation are necessary for reproducibility and to support the claims. In the revised manuscript, we will expand the Evaluation section to include: participant recruitment method and demographics, blinding procedures (if any), inter-rater agreement statistics, the precise scoring protocol used, and results of statistical tests including p-values and effect sizes. We will also include a power analysis if feasible based on the collected data. This will be added without altering the core findings. revision: yes
-
Referee: Training the smaller foundation models on compromises generated by the same empathic method under evaluation creates a circularity risk: any systematic artifacts or biases in the original LLM outputs are inherited by the fine-tuned models rather than validated against independent human or external benchmarks.
Authors: This is a valid concern regarding potential propagation of biases from the generator LLM. However, the alignment process relies on human preference judgments collected on the generated compromises, using a margin-based loss to train the smaller models. These human preferences serve as an independent signal. We will revise the Model training and alignment section to explicitly describe the human annotation process, clarify how it mitigates circularity, and add a discussion of limitations, including the need for future work with human-generated compromises as benchmarks. revision: partial
Circularity Check
No significant circularity; evaluation rests on independent human study
full rationale
The paper's core result—that external empathic similarity feedback outperforms standard CoT—is established by comparing four prompt methods on 2,400 view pairs and then measuring acceptability via a separate 50-participant human study. This human rating serves as an external benchmark rather than a self-referential metric. The subsequent step of training smaller models on the generated dataset via margin-based alignment of human preferences is a downstream distillation task; it does not redefine or presuppose the superiority claim, nor does it create a fitted-input-called-prediction loop. No self-citations, uniqueness theorems, or definitional equivalences appear in the described chain, so the derivation remains self-contained against the external human evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review arXiv 2023
-
[4]
AI Anthropic. 2023. Introducing claude
2023
-
[5]
Mohammad Gheshlaghi Azar, Zhaohan Daniel Guo, Bilal Piot, Remi Munos, Mark Rowland, Michal Valko, and Daniele Calandriello. 2024. A general theoretical paradigm to understand learning from human preferences. In International Conference on Artificial Intelligence and Statistics, pages 4447--4455. PMLR
2024
-
[6]
Michiel Bakker, Martin Chadwick, Hannah Sheahan, Michael Tessler, Lucy Campbell-Gillingham, Jan Balaguer, Nat McAleese, Amelia Glaese, John Aslanides, Matt Botvinick, et al. 2022. Fine-tuning language models to find agreement among humans with diverse preferences. Advances in Neural Information Processing Systems, 35:38176--38189
2022
-
[7]
Krisztian Balog, John Palowitch, Barbara Ikica, Filip Radlinski, Hamidreza Alvari, and Mehdi Manshadi. 2024. Towards realistic synthetic user-generated content: A scaffolding approach to generating online discussions. CoRR
2024
-
[8]
Cristina Bicchieri. 2005. The grammar of society: The nature and dynamics of social norms. Cambridge University Press
2005
-
[9]
Paola Cascante-Bonilla, Khaled Shehada, James Seale Smith, Sivan Doveh, Donghyun Kim, Rameswar Panda, Gul Varol, Aude Oliva, Vicente Ordonez, Rogerio Feris, et al. 2023. Going beyond nouns with vision & language models using synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 20155--20165
2023
-
[10]
Francine Chen, Scott Carter, Tatiana Lau, Nayeli Suseth Bravo, Sumanta Bhattacharyya, Kate Sieck, and Charlene C Wu. 2025. Empathy prediction from diverse perspectives. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8959--8974
2025
- [11]
- [12]
- [13]
-
[14]
Zheng Chu, Jingchang Chen, Qianglong Chen, Weijiang Yu, Tao He, Haotian Wang, Weihua Peng, Ming Liu, Bing Qin, and Ting Liu. 2024. Navigate through enigmatic labyrinth a survey of chain of thought reasoning: Advances, frontiers and future. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), p...
2024
-
[15]
Fida K Dankar and Mahmoud Ibrahim. 2021. Fake it till you make it: Guidelines for effective synthetic data generation. Applied Sciences, 11(5):2158
2021
- [16]
-
[17]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review arXiv 2024
-
[18]
Nicholas Epley and Thomas Gilovich. 2006. The anchoring-and-adjustment heuristic: Why the adjustments are insufficient. Psychological science, 17(4):311--318
2006
- [19]
-
[20]
Ernst Fehr and Urs Fischbacher. 2004. Social norms and human cooperation. Trends in cognitive sciences, 8(4):185--190
2004
-
[21]
Guhao Feng, Bohang Zhang, Yuntian Gu, Haotian Ye, Di He, and Liwei Wang. 2024. Towards revealing the mystery behind chain of thought: a theoretical perspective. Advances in Neural Information Processing Systems, 36
2024
- [22]
-
[23]
Rodney A Gabriel, Onkar Litake, Sierra Simpson, Brittany N Burton, Ruth S Waterman, and Alvaro A Macias. 2024. On the development and validation of large language model-based classifiers for identifying social determinants of health. Proceedings of the National Academy of Sciences, 121(39):e2320716121
2024
-
[24]
Hamideh Ghanadian, Isar Nejadgholi, and Hussein Al Osman. 2024. Socially aware synthetic data generation for suicidal ideation detection using large language models. IEEE Access
2024
-
[25]
Zhiqiang Gong, Ping Zhong, and Weidong Hu. 2019. Diversity in machine learning. Ieee Access, 7:64323--64350
2019
- [26]
- [27]
-
[28]
Michael Gutmann and Aapo Hyv \"a rinen. 2010. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, pages 297--304. JMLR Workshop and Conference Proceedings
2010
-
[29]
Michael U Gutmann and Aapo Hyv \"a rinen. 2012. Noise-contrastive estimation of unnormalized statistical models, with applications to natural image statistics. Journal of machine learning research, 13(2)
2012
-
[30]
Md Rakibul Hasan, Md Zakir Hossain, Tom Gedeon, and Shafin Rahman. 2024. Llm-gem: Large language model-guided prediction of people’s empathy levels towards newspaper article. In Findings of the Association for Computational Linguistics: EACL 2024, pages 2215--2231
2024
- [31]
-
[32]
Asen Hikov and Laura Murphy. 2024. Information retrieval from textual data: Harnessing large language models, retrieval augmented generation and prompt engineering. Journal of AI, Robotics & Workplace Automation, 3(2):142--150
2024
- [33]
- [34]
- [35]
-
[36]
Dieuwke Hupkes, Mario Giulianelli, Verna Dankers, Mikel Artetxe, Yanai Elazar, Tiago Pimentel, Christos Christodoulopoulos, Karim Lasri, Naomi Saphra, Arabella Sinclair, et al. 2022. State-of-the-art generalisation research in nlp: a taxonomy and review. arXiv preprint arXiv:2210.03050
-
[37]
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. 2023. Mistral 7b. arXiv preprint arXiv:2310.06825
work page internal anchor Pith review arXiv 2023
- [38]
- [39]
-
[40]
Solomon Kullback and Richard A Leibler. 1951. On information and sufficiency. The annals of mathematical statistics, 22(1):79--86
1951
-
[41]
Matthew Le, Y-Lan Boureau, and Maximilian Nickel. 2019. Revisiting the evaluation of theory of mind through question answering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 5872--5877
2019
- [42]
-
[43]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74--81
2004
- [44]
- [45]
- [46]
-
[47]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. 2024. Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems, 36
2024
- [48]
-
[49]
Stephen Merity, Nitish Shirish Keskar, James Bradbury, and Richard Socher. 2018. Scalable language modeling: Wikitext-103 on a single gpu in 12 hours. Proceedings of the SYSML, 18
2018
- [50]
-
[51]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730--27744
2022
- [52]
-
[53]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2024. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36
2024
-
[54]
N Reimers. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084
work page internal anchor Pith review arXiv 2019
-
[55]
Sahand Sabour, Siyang Liu, Zheyuan Zhang, June M Liu, Jinfeng Zhou, Alvionna S Sunaryo, Juanzi Li, Tatia MC Lee, Rada Mihalcea, and Minlie Huang. 2024. Emobench: Evaluating the emotional intelligence of large language models. CoRR
2024
-
[56]
Sahand Sabour, Chujie Zheng, and Minlie Huang. 2022. Cem: Commonsense-aware empathetic response generation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 11229--11237
2022
-
[57]
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. 2019. Socialiqa: Commonsense reasoning about social interactions. arXiv preprint arXiv:1904.09728
work page internal anchor Pith review arXiv 2019
- [58]
-
[59]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347
work page internal anchor Pith review arXiv 2017
-
[60]
Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen. 2023. Synthetic prompting: Generating chain-of-thought demonstrations for large language models. In International Conference on Machine Learning, pages 30706--30775. PMLR
2023
-
[61]
Jocelyn Shen. 2023. Modeling empathic similarity in personal narratives. Ph.D. thesis, Massachusetts Institute of Technology
2023
- [62]
-
[63]
Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, and Houfeng Wang. 2024. Preference ranking optimization for human alignment. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 18990--18998
2024
- [64]
- [65]
-
[66]
Jinzhe Tan, Hannes Westermann, Nikhil Reddy Pottanigari, Jarom \' r S avelka, S \'e bastien Mee \`u s, Mia Godet, and Karim Benyekhlef. 2024. Robots in the middle: Evaluating llms in dispute resolution. In Legal Knowledge and Information Systems, pages 168--179. IOS Press
2024
-
[67]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca
2023
-
[68]
Michael Henry Tessler, Michiel A Bakker, Daniel Jarrett, Hannah Sheahan, Martin J Chadwick, Raphael Koster, Georgina Evans, Lucy Campbell-Gillingham, Tantum Collins, David C Parkes, et al. 2024. Ai can help humans find common ground in democratic deliberation. Science, 386(6719):eadq2852
2024
-
[69]
Philippe Van Parijs. 2012. What makes a good compromise? 1. Government and Opposition, 47(3):466--480
2012
- [70]
-
[71]
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. 2022. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533
work page internal anchor Pith review arXiv 2022
-
[72]
Xuena Wang, Xueting Li, Zi Yin, Yue Wu, and Jia Liu. 2023. Emotional intelligence of large language models. Journal of Pacific Rim Psychology, 17:18344909231213958
2023
-
[73]
Zhichao Wang, Bin Bi, Shiva Kumar Pentyala, Kiran Ramnath, Sougata Chaudhuri, Shubham Mehrotra, Xiang-Bo Mao, Sitaram Asur, et al. 2024 b . A comprehensive survey of llm alignment techniques: Rlhf, rlaif, ppo, dpo and more. arXiv preprint arXiv:2407.16216
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[74]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824--24837
2022
-
[75]
Anuradha Welivita, Yubo Xie, and Pearl Pu. 2021. A large-scale dataset for empathetic response generation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 1251--1264
2021
-
[76]
Daniel Wesego and Pedram Rooshenas. 2024. https://openreview.net/forum?id=JbuP6UV3Fk Score-based multimodal autoencoder . Transactions on Machine Learning Research
2024
- [77]
-
[78]
Yosuke Yamagishi and Yuta Nakamura. 2024. Utrad-nlp at\# smm4h 2024: Why llm-generated texts fail to improve text classification models. In Proceedings of The 9th Social Media Mining for Health Research and Applications (SMM4H 2024) Workshop and Shared Tasks, pages 42--47
2024
- [79]
-
[80]
Hongyi Yuan, Zheng Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. 2024. Rrhf: Rank responses to align language models with human feedback. Advances in Neural Information Processing Systems, 36
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.