Recognition: unknown
Cortex-Inspired Continual Learning: Unsupervised Instantiation and Recovery of Functional Task Networks
Pith reviewed 2026-05-08 03:59 UTC · model grok-4.3
The pith
Functional task networks use brain-inspired masks to isolate task-specific neurons and achieve near-zero forgetting in continual learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
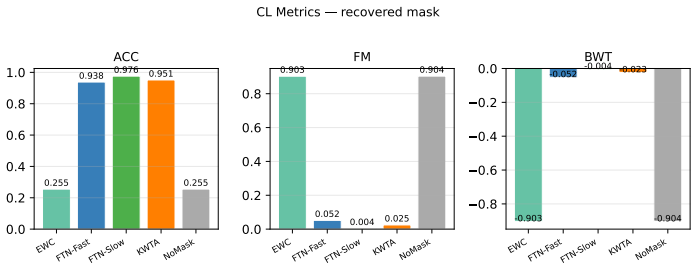
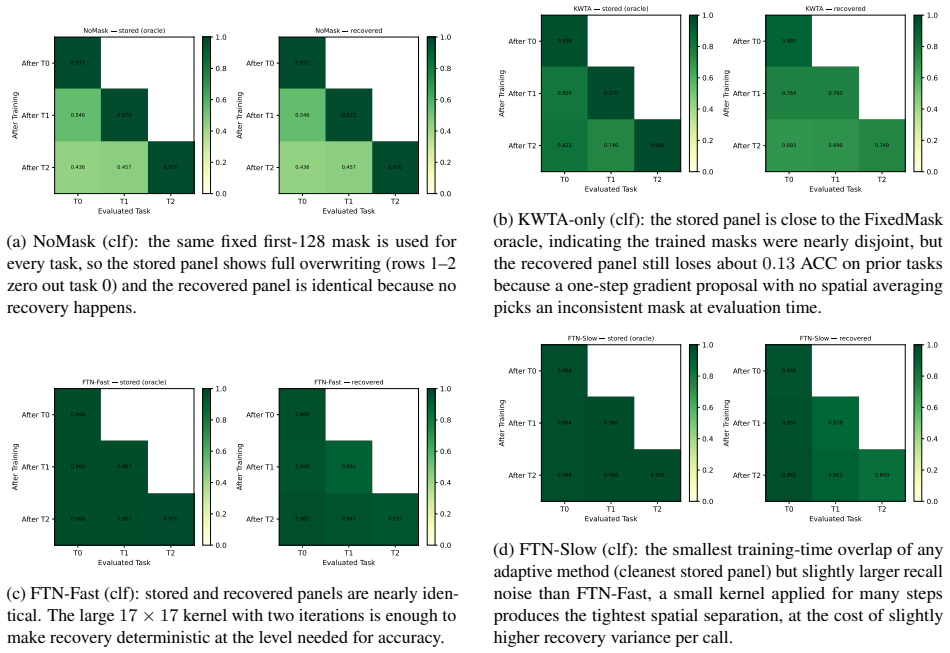
FTN with fine-grained smoothing produces binary masks that assign disjoint, functionally complete groups of neurons to each task; the masks are recovered unsupervised at inference time, yielding structural isolation of gradient updates and nearly zero forgetting on a synthetic multi-task generator, shuffled-label MNIST, and Permuted MNIST.
What carries the argument
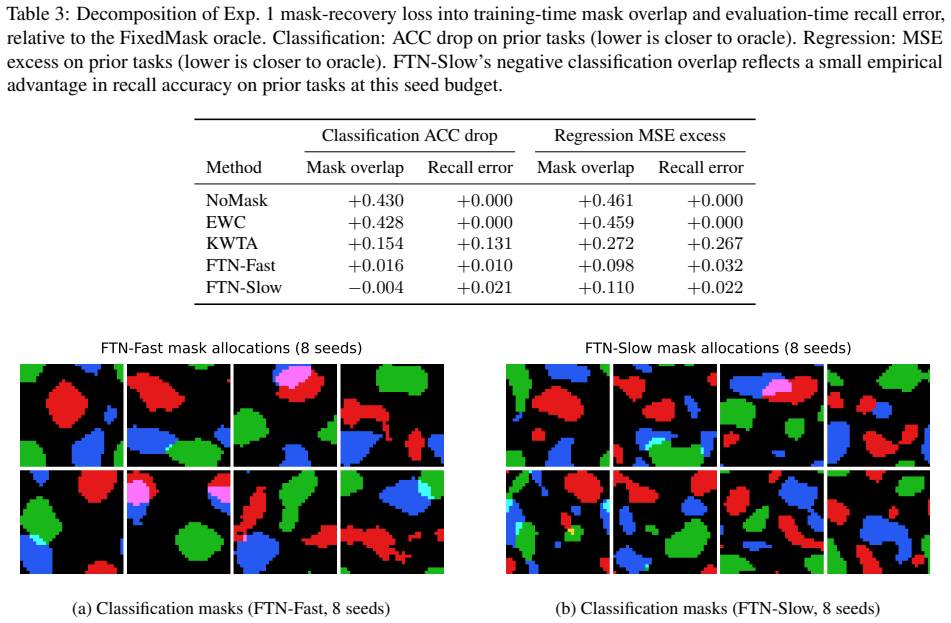
Three-stage mask procedure: gradient descent on a continuous mask to identify task-relevant neurons, followed by a smoothing kernel that biases toward spatial contiguity, then k-winner-take-all binarization at a fixed capacity budget.
If this is right
- Disjoint masks deliver exact separation of gradient updates across tasks, eliminating interference by construction.
- A single gradient step on the mask recovers the subnetwork for any previously learned task without requiring task labels.
- The spatial smoothing step reduces the mask search from combinatorial subset selection to a near-linear scan over compact neighborhoods.
- FTN-Fast trades some retention for speed by using a larger kernel and fewer smoothing iterations.
Where Pith is reading between the lines
- The fixed per-task capacity budget implies a trade-off: as the number of tasks grows, either total network size must increase or average subnetwork size must shrink, which could be tested by scaling the number of tasks while holding total neurons fixed.
- Because each neuron is itself a small deep network, the approach naturally composes with mixture-of-experts style routing but replaces learned routers with the recovered mask.
- The emphasis on spatial contiguity suggests that imposing topographic organization on artificial networks might confer similar efficiency gains in other sequence-learning settings.
Load-bearing premise
The combination of gradient descent on a continuous mask, smoothing kernel, and fixed-capacity k-winner-take-all binarization will reliably produce disjoint, functionally complete task subnetworks without significant capacity waste or overlap across tasks.
What would settle it
A controlled experiment on a new benchmark where successive tasks share many input features but require different output mappings; measure whether the generated masks remain largely disjoint and whether forgetting stays near zero.
Figures




read the original abstract
Block-sequential continual learning demands that a single model both protect prior solutions from catastrophic forgetting and efficiently infer at inference time which prior solution matches the current input without task labels. We present Functional Task Networks (FTN), a parameter-isolation method inspired by structural and dynamical motifs found in the mammalian neocortex. Similar to mixture-of-experts, this method uses a high dimensional, self-organizing binary mask over a large population of small but deep networks, inspired by dendritic models of pyramidal neurons. The mask is produced by a three-stage procedure: (1) gradient descent on a continuous mask identifies task-relevant neurons, (2) a smoothing kernel biases the result toward spatial contiguity, (3) and k-winner-take-all binarizes the resulting group at a fixed capacity budget. Like mixture-of-experts, each neuron is an independent deep network, so disjoint masks give exactly disjoint gradient updates, providing structural guarantees against catastrophic forgetting. This three-stage procedure recovers the sub-network of a previously-trained task in a single gradient step, providing unsupervised task segmentation at inference time. We test it on three continual-learning benchmarks: (1) a synthetic multi-task classification/regression generator, (2) MNIST with shuffled class labels (pure concept shift), and (3) Permuted MNIST (domain shift). On all three, FTN with fine grained smoothing (FTN-Slow) results in nearly zero forgetting. FTN with a large kernel and only 2 iterations of smoothing (FTN-Fast) trades off some retention for increased speed. We show that the spatial organization mechanism reduces the effective mask search from the combinatorial top-k subset problem in O(C(H,K)) to the complexity of a near-linear scan in O(H) over compact cortical neighborhoods, which is parallelized by the gradient-based update.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Functional Task Networks (FTN), a cortex-inspired parameter-isolation method for block-sequential continual learning. It uses a high-dimensional binary mask over a population of small deep networks, generated via a three-stage procedure: (1) gradient descent on a continuous mask to identify task-relevant neurons, (2) application of a smoothing kernel to bias toward spatial contiguity, and (3) k-winner-take-all binarization at a fixed capacity budget k. Disjoint masks ensure non-interfering gradient updates, providing structural protection against catastrophic forgetting. The method also claims to recover prior task sub-networks in a single gradient step for unsupervised inference-time task segmentation. Experiments on a synthetic multi-task generator, shuffled-label MNIST, and Permuted MNIST report nearly zero forgetting for the fine-grained smoothing variant (FTN-Slow), with a faster but lower-retention variant (FTN-Fast) using a larger kernel and fewer iterations. The spatial mechanism is claimed to reduce mask search complexity from combinatorial to near-linear.
Significance. If the empirical claims hold under rigorous controls, the work provides a biologically motivated parameter-isolation strategy that combines structural guarantees against forgetting with efficient unsupervised task recovery. The complexity reduction via spatial smoothing is a concrete technical contribution that could influence modular and sparse architectures in continual learning. The approach is falsifiable via mask-completeness ablations and would be strengthened by reproducible code or parameter-free derivations, though none are reported here.
major comments (2)
- [Abstract] Abstract: the central claim of 'nearly zero forgetting' on the three benchmarks is load-bearing for the paper's contribution, yet the abstract (and by extension the reported results) provides no baseline comparisons, statistical tests, error bars, or hyperparameter sensitivity analysis for the free parameters (smoothing kernel size, number of iterations, capacity budget k). Without these, it is impossible to determine whether the retention is attributable to the FTN mechanism or to under-tuned baselines.
- [Method and Experiments] Method (three-stage procedure) and Experiments: the zero-forgetting guarantee requires that each binarized mask selects a functionally complete subnetwork (performance of the isolated k-neuron subnetwork matches or approaches the joint model) while remaining disjoint across tasks. The procedure (GD on continuous mask + smoothing + fixed-k k-WTA) contains no explicit term enforcing completeness and no post-selection verification that later tasks avoid capacity exhaustion or forced overlap. The manuscript must add ablations measuring isolated-subnetwork accuracy versus full-network accuracy and track mask overlap statistics across tasks; absent this, the structural non-interference claim cannot be causally linked to the reported retention.
minor comments (1)
- [Abstract] Abstract: the description of unsupervised recovery 'in a single gradient step' is stated without the corresponding inference procedure or loss used for mask recovery, leaving the mechanism for task segmentation at inference time underspecified.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have prepared point-by-point responses to the major comments below. We agree that certain clarifications and additions will strengthen the presentation and have indicated the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'nearly zero forgetting' on the three benchmarks is load-bearing for the paper's contribution, yet the abstract (and by extension the reported results) provides no baseline comparisons, statistical tests, error bars, or hyperparameter sensitivity analysis for the free parameters (smoothing kernel size, number of iterations, capacity budget k). Without these, it is impossible to determine whether the retention is attributable to the FTN mechanism or to under-tuned baselines.
Authors: We agree that the abstract would benefit from additional context to support the central claim. In the revised manuscript we will expand the abstract to reference the quantitative retention results (including comparisons to standard continual-learning baselines such as EWC and SI) and note that error bars are derived from multiple independent runs. For the full experimental section, we will add a dedicated hyperparameter sensitivity analysis subsection that varies kernel size, iteration count, and capacity budget k while reporting mean and standard deviation across seeds. These changes will make explicit that the reported retention is attributable to the FTN procedure rather than baseline under-tuning. revision: partial
-
Referee: [Method and Experiments] Method (three-stage procedure) and Experiments: the zero-forgetting guarantee requires that each binarized mask selects a functionally complete subnetwork (performance of the isolated k-neuron subnetwork matches or approaches the joint model) while remaining disjoint across tasks. The procedure (GD on continuous mask + smoothing + fixed-k k-WTA) contains no explicit term enforcing completeness and no post-selection verification that later tasks avoid capacity exhaustion or forced overlap. The manuscript must add ablations measuring isolated-subnetwork accuracy versus full-network accuracy and track mask overlap statistics across tasks; absent this, the structural non-interference claim cannot be causally linked to the reported retention.
Authors: The referee correctly notes that explicit verification of subnetwork completeness and disjointness would strengthen the causal argument. Although the fixed-k k-WTA step guarantees disjoint masks by construction and the gradient stage selects task-relevant neurons, we acknowledge the lack of post-selection diagnostics. We will add two new ablation studies in the revised experiments: (1) direct comparison of task accuracy when using only the binarized subnetwork versus the full joint model, and (2) quantitative mask-overlap statistics (intersection size and Jaccard index) together with per-task capacity utilization to confirm that later tasks do not exhaust the budget or force overlap. These results will be reported for all three benchmarks and will directly link the structural properties to the observed retention. revision: yes
Circularity Check
No significant circularity; empirical results rest on independent mechanism and benchmarks
full rationale
The paper's central derivation consists of a three-stage mask procedure (gradient descent on continuous mask, smoothing kernel, k-WTA binarization) whose structural non-interference property follows logically from parameter isolation rather than from any self-referential definition or fitted quantity. Performance claims of near-zero forgetting are presented as outcomes of testing on three external benchmarks, not as quantities that reduce by construction to inputs or prior self-citations. The complexity argument for spatial organization is an independent analysis of the smoothing step and does not presuppose the target result. No load-bearing step equates the claimed outcomes to the method's own fitted values or to unverified self-referential premises.
Axiom & Free-Parameter Ledger
free parameters (3)
- smoothing kernel size
- number of smoothing iterations
- capacity budget k
axioms (2)
- domain assumption Disjoint masks over independent sub-networks guarantee no gradient interference between tasks
- domain assumption Gradient descent on a continuous mask can identify task-relevant neurons
invented entities (1)
-
Functional Task Network (FTN)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Task-free continual learning.IEEE CVPR, 2019
Rahaf Aljundi, Klaas Kelchtermans, and Tinne Tuytelaars. Task-free continual learning.IEEE CVPR, 2019
2019
-
[2]
Dynamics of pattern formation in lateral-inhibition type neural fields.Biological Cybernetics, 27(2):77–87, 1977
Shun-ichi Amari. Dynamics of pattern formation in lateral-inhibition type neural fields.Biological Cybernetics, 27(2):77–87, 1977. 11
1977
-
[3]
Single cortical neurons as deep artificial neural networks
David Beniaguev, Idan Segev, and Michael London. Single cortical neurons as deep artificial neural networks. Neuron, 109(17):2727–2739, 2021
2021
-
[4]
Branch-specific dendritic ca2+ spikes cause persistent synaptic plasticity
Joseph Cichon and Wen-Biao Gan. Branch-specific dendritic ca2+ spikes cause persistent synaptic plasticity. Nature, 520(7546):180–185, 2015
2015
-
[5]
Neuronal circuits of the neocortex.Annual Review of Neuroscience, 27: 419–451, 2004
Rodney J Douglas and Kevan AC Martin. Neuronal circuits of the neocortex.Annual Review of Neuroscience, 27: 419–451, 2004
2004
-
[6]
Aldo Faisal, Luc P
A. Aldo Faisal, Luc P. J. Selen, and Daniel M. Wolpert. Noise in the nervous system.Nature Reviews Neuroscience, 9(4):292–303, 2008
2008
-
[7]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23:1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23:1–39, 2022
2022
-
[8]
Frank, Bryan Loughry, and Randall C
Michael J. Frank, Bryan Loughry, and Randall C. O’Reilly. Interactions between frontal cortex and basal ganglia in working memory: A computational model.Cognitive, Affective, & Behavioral Neuroscience, 1(2):137–160, 2001
2001
-
[9]
Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4):128–135, 1999
Robert M French. Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4):128–135, 1999
1999
-
[10]
A survey on concept drift adaptation.ACM Computing Surveys, 46(4):1–37, 2014
João Gama, Indr˙e Žliobait ˙e, Albert Bifet, Mykola Pechenizkiy, and Abdelhamid Bouchachia. A survey on concept drift adaptation.ACM Computing Surveys, 46(4):1–37, 2014
2014
-
[11]
Gilbert and Torsten N
Charles D. Gilbert and Torsten N. Wiesel. Clustered intrinsic connections in cat visual cortex.Journal of Neuroscience, 3(5):1116–1133, 1983
1983
-
[12]
Ian J. Goodfellow, Mehdi Mirza, Da Xiao, Aaron Courville, and Yoshua Bengio. An empirical investigation of catastrophic forgetting in gradient-based neural networks.arXiv preprint arXiv:1312.6211, 2013
-
[13]
Suchin Gururangan, Ana Marasovi´c, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. Smith. Don’t stop pretraining: Adapt language models to domains and tasks. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8342–8360. Association for Computational Linguistics, 2020
2020
-
[14]
Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex.The Journal of Physiology, 160(1):106–154, 1962
David H Hubel and Torsten N Wiesel. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex.The Journal of Physiology, 160(1):106–154, 1962
1962
-
[15]
Mikail Khona and Ila R. Fiete. Attractor and integrator networks in the brain.Nature Reviews Neuroscience, 23 (12):744–766, 2022
2022
-
[16]
Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
2017
-
[17]
Self-organized formation of topologically correct feature maps.Biological cybernetics, 43(1): 59–69, 1982
Teuvo Kohonen. Self-organized formation of topologically correct feature maps.Biological cybernetics, 43(1): 59–69, 1982
1982
-
[18]
Gradient episodic memory for continual learning.Advances in neural information processing systems, 30, 2017
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning.Advances in neural information processing systems, 30, 2017
2017
-
[19]
On the computational power of winner-take-all.Neural computation, 12(11):2519–2535, 2000
Wolfgang Maass. On the computational power of winner-take-all.Neural computation, 12(11):2519–2535, 2000
2000
-
[20]
Mainen and Terrence J
Zachary F. Mainen and Terrence J. Sejnowski. Reliability of spike timing in neocortical neurons.Science, 268 (5216):1503–1506, 1995
1995
-
[21]
Packnet: Adding multiple tasks to a single network by iterative pruning
Arun Mallya and Svetlana Lazebnik. Packnet: Adding multiple tasks to a single network by iterative pruning. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. 12
2018
-
[22]
Catastrophic interference in connectionist networks: The sequential learning problem.Psychology of learning and motivation, 24:109–165, 1989
Michael McCloskey and Neal J Cohen. Catastrophic interference in connectionist networks: The sequential learning problem.Psychology of learning and motivation, 24:109–165, 1989
1989
-
[23]
The basal ganglia: focused selection and inhibition of competing motor programs.Progress in Neurobiology, 50(4):381–425, 1996
Jonathan W Mink. The basal ganglia: focused selection and inhibition of competing motor programs.Progress in Neurobiology, 50(4):381–425, 1996
1996
-
[24]
Inhibitory connectivity defines the realm of excitatory plasticity.Nature neuroscience, 21(10):1463–1470, 2018
Gianluigi Mongillo, Simon Rumpel, and Yonatan Loewenstein. Inhibitory connectivity defines the realm of excitatory plasticity.Nature neuroscience, 21(10):1463–1470, 2018
2018
-
[25]
Moreno-Torres, Troy Raeder, Rocío Alaiz-Rodríguez, Nitesh V
Jose G. Moreno-Torres, Troy Raeder, Rocío Alaiz-Rodríguez, Nitesh V . Chawla, and Francisco Herrera. A unifying view on dataset shift in classification.Pattern Recognition, 45(1):521–530, 2012
2012
-
[26]
Sparse approximate solutions to linear systems.SIAM Journal on Computing, 24(2): 227–234, 1995
Balas Kausik Natarajan. Sparse approximate solutions to linear systems.SIAM Journal on Computing, 24(2): 227–234, 1995
1995
-
[27]
O’Reilly and Michael J
Randall C. O’Reilly and Michael J. Frank. Making working memory work: A computational model of learning in the prefrontal cortex and basal ganglia.Neural Computation, 18(2):283–328, 2006
2006
-
[28]
Continual lifelong learning with neural networks: A review.Neural Networks, 113:54–71, 2019
German I Parisi, Ronald Kemker, Jose L Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural Networks, 113:54–71, 2019
2019
-
[29]
Illuminating dendritic function with computational models.Nature Reviews Neuroscience, 21(6):303–321, 2020
Panayiota Poirazi and Athanasia Papoutsi. Illuminating dendritic function with computational models.Nature Reviews Neuroscience, 21(6):303–321, 2020
2020
-
[30]
Panayiota Poirazi, Terrence Brannon, and Bartlett W. Mel. Pyramidal neuron as two-layer neural network.Neuron, 37(6):989–999, 2003
2003
-
[31]
Lawrence, editors.Dataset Shift in Machine Learning
Joaquin Quiñonero-Candela, Masashi Sugiyama, Anton Schwaighofer, and Neil D. Lawrence, editors.Dataset Shift in Machine Learning. MIT Press, 2009
2009
-
[32]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
2017
-
[33]
Attractor networks.Wiley Interdisciplinary Reviews: Cognitive Science, 1(1):119–134, 2010
Edmund T Rolls. Attractor networks.Wiley Interdisciplinary Reviews: Cognitive Science, 1(1):119–134, 2010
2010
-
[34]
Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. Progressive neural networks.arXiv preprint arXiv:1606.04671, 2016
work page internal anchor Pith review arXiv 2016
-
[35]
A neural substrate of prediction and reward.Science, 275 (5306):1593–1599, 1997
Wolfram Schultz, Peter Dayan, and P Read Montague. A neural substrate of prediction and reward.Science, 275 (5306):1593–1599, 1997
1997
-
[36]
Overcoming catastrophic forgetting with hard attention to the task
Joan Serra, Didac Suris, Marius Miron, and Alexandros Karatzoglou. Overcoming catastrophic forgetting with hard attention to the task. InInternational Conference on Machine Learning, pages 4548–4557. PMLR, 2018
2018
-
[37]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.ICLR, 2017
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.ICLR, 2017
2017
-
[38]
Dropout: a simple way to prevent neural networks from overfitting.Journal of Machine Learning Research, 15(1):1929–1958, 2014
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting.Journal of Machine Learning Research, 15(1):1929–1958, 2014
1929
-
[39]
Gido M. van de Ven and Andreas S. Tolias. Three scenarios for continual learning.arXiv preprint arXiv:1904.07734, 2019
-
[40]
Wilson and Jack D
Hugh R. Wilson and Jack D. Cowan. Excitatory and inhibitory interactions in localized populations of model neurons.Biophysical Journal, 12(1):1–24, 1972
1972
-
[41]
Supermasks in superposition.Advances in Neural Information Processing Systems, 33:15173– 15184, 2020
Mitchell Wortsman, Vivek Ramanujan, Rosanne Liu, Aniruddha Kembhavi, Mohammad Rastegari, Jason Yosinski, and Ali Farhadi. Supermasks in superposition.Advances in Neural Information Processing Systems, 33:15173– 15184, 2020. 13
2020
-
[42]
Task representations in neural networks trained to perform many cognitive tasks.Nature neuroscience, 22(2):297–306, 2019
Guangyu Robert Yang, Madhura R Joglekar, H Francis Song, William T Newsome, and Xiao-Jing Wang. Task representations in neural networks trained to perform many cognitive tasks.Nature neuroscience, 22(2):297–306, 2019
2019
-
[43]
Investigating continual pretraining in large language models: Insights and implications,
Ça˘gatay Yıldız, Nishaanth Kanna Ravichandran, Nitin Sharma, Matthias Bethge, and Beyza Ermis. Investigating continual pretraining in large language models: Insights and implications.arXiv preprint arXiv:2402.17400, 2024
-
[44]
Lifelong learning with dynamically expandable networks.ICLR, 2018
Jaehong Yoon, Eunho Yang, Jeongtae Lee, and Sung Ju Hwang. Lifelong learning with dynamically expandable networks.ICLR, 2018
2018
-
[45]
Continual learning through synaptic intelligence
Friedemann Zenke, Ben Poole, and Surya Ganguli. Continual learning through synaptic intelligence. In International Conference on Machine Learning, pages 3987–3995. PMLR, 2017. A Per-method Performance Matrices: Stored vs Recovered This appendix collects the full 3×3 performance matrices for Experiment 1 across the four headline mask configurers, NoMask (t...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.