Recognition: unknown
K-MetBench: A Multi-Dimensional Benchmark for Fine-Grained Evaluation of Expert Reasoning, Locality, and Multimodality in Meteorology
Pith reviewed 2026-05-08 03:23 UTC · model grok-4.3
The pith
Korean models outperform significantly larger global models in local meteorology contexts, showing that parameter scaling alone cannot resolve cultural dependencies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
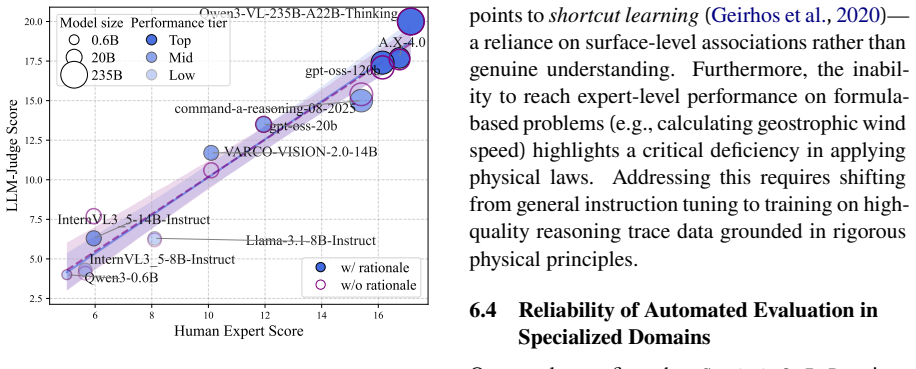
K-MetBench is introduced as a diagnostic benchmark grounded in national qualification exams to measure multimodal large language model performance on expert meteorology. It assesses four dimensions: expert visual reasoning of charts, logical validity via expert-verified rationales, Korean-specific geo-cultural comprehension, and fine-grained domain analysis. Results across 55 models show a modality gap in diagram interpretation and a reasoning gap where models hallucinate logic despite correct predictions. Korean models outperform significantly larger global models in local contexts, demonstrating that parameter scaling alone cannot resolve cultural dependencies.
What carries the argument
K-MetBench, the multi-dimensional benchmark constructed from national qualification exam questions to evaluate expert reasoning, locality, and multimodality in meteorology.
If this is right
- Practical multimodal assistants for weather forecasters must incorporate targeted fixes for chart interpretation and logical consistency.
- Cultural and locality factors require dedicated handling rather than relying on general model scaling.
- The benchmark offers a concrete roadmap for measuring and closing gaps in domain-specific AI development.
- Similar evaluation approaches could apply to other expert fields that rely on specialized visuals and regional knowledge.
Where Pith is reading between the lines
- Parallel benchmarks for other countries would allow direct tests of whether current global models generalize across cultural boundaries.
- Fine-tuning large models on localized meteorology data may close performance gaps more efficiently than further scaling.
- Deployment in actual forecasting workflows could reveal whether benchmark scores predict real utility for professionals.
Load-bearing premise
That performance on national qualification exam questions accurately measures expert-level meteorology reasoning and that the four evaluation dimensions fully capture the relevant gaps in current models.
What would settle it
A head-to-head comparison in which professional Korean meteorologists use high-scoring models versus low-scoring models on real forecast tasks and measure differences in accuracy or decision quality.
Figures





























read the original abstract
The development of practical (multimodal) large language model assistants for Korean weather forecasters is hindered by the absence of a multidimensional, expert-level evaluation framework grounded in authoritative sources. To address this, we introduce K-MetBench, a diagnostic benchmark grounded in national qualification exams. It exposes critical gaps across four dimensions: expert visual reasoning of charts, logical validity via expert-verified rationales, Korean-specific geo-cultural comprehension, and fine-grained domain analysis. Our evaluation of 55 models reveals a profound modality gap in interpreting specialized diagrams and a reasoning gap where models hallucinate logic despite correct predictions. Crucially, Korean models outperform significantly larger global models in local contexts, demonstrating that parameter scaling alone cannot resolve cultural dependencies. K-MetBench serves as a roadmap for developing reliable, culturally aware expert AI agents. The dataset is available at https://huggingface.co/datasets/soyeonbot/K-MetBench .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces K-MetBench, a diagnostic benchmark for meteorology LLMs grounded in Korean national qualification exams. It evaluates 55 models across four dimensions—expert visual reasoning of charts, logical validity via expert-verified rationales, Korean-specific geo-cultural comprehension, and fine-grained domain analysis—reporting a modality gap in diagram interpretation, reasoning hallucinations despite correct answers, and superior performance by Korean models over larger global models in local contexts. The authors conclude that parameter scaling alone cannot resolve cultural dependencies and release the dataset publicly.
Significance. If the central findings hold after addressing potential confounds, this benchmark would be a useful contribution to expert-domain and multilingual evaluation in NLP. It provides concrete evidence of modality and reasoning gaps in current models and highlights the limits of scale for localized expert knowledge, offering a practical roadmap for culturally aware AI assistants. The public Hugging Face dataset release supports reproducibility and follow-on work.
major comments (2)
- [Evaluation results and discussion of Korean vs. global models] The headline claim that 'parameter scaling alone cannot resolve cultural dependencies' (abstract) is load-bearing but rests on performance differences without reported controls for pretraining data overlap, decontamination statistics, or exam-format familiarity. If global models simply saw less Korean meteorological text, the result does not isolate irreducible cultural/geo-local gaps from corpus exposure.
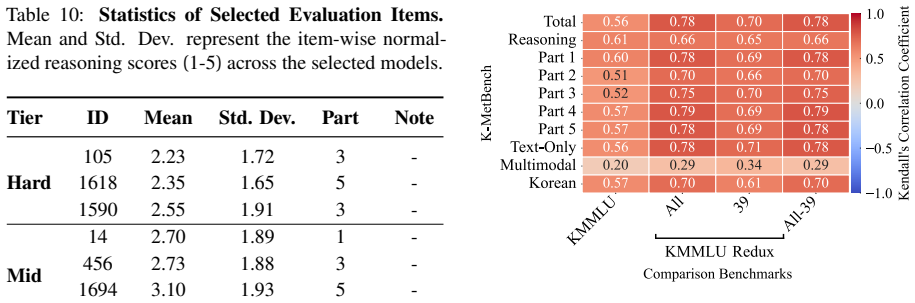
- [Benchmark construction and evaluation protocol] The soundness of the reported gaps (modality, reasoning, locality) cannot be fully assessed because the manuscript provides no detailed scoring rubrics, inter-annotator agreement for expert-verified rationales, error bars on the 55-model results, or full methodology for the four dimensions.
minor comments (2)
- [Introduction] The abstract and introduction would benefit from a brief comparison table positioning K-MetBench against existing meteorology or expert-reasoning benchmarks (e.g., those focused on charts or scientific QA).
- [Results] Figure captions and axis labels for any performance plots should explicitly state the number of questions per dimension and whether results are averaged across multiple runs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation results and discussion of Korean vs. global models] The headline claim that 'parameter scaling alone cannot resolve cultural dependencies' (abstract) is load-bearing but rests on performance differences without reported controls for pretraining data overlap, decontamination statistics, or exam-format familiarity. If global models simply saw less Korean meteorological text, the result does not isolate irreducible cultural/geo-local gaps from corpus exposure.
Authors: We acknowledge that explicit controls for pretraining data overlap and decontamination would provide stronger isolation of cultural effects. However, the observed pattern—smaller Korean models significantly outperforming much larger global models on Korean-specific meteorology tasks—persists despite the global models' likely exposure to some multilingual data. We will revise the discussion to explicitly note this as a potential confound, discuss the limitations of our analysis given proprietary training data, and qualify the claim to emphasize that localized optimization appears necessary beyond scale alone. The core empirical finding of locality advantages remains valid as reported. revision: partial
-
Referee: [Benchmark construction and evaluation protocol] The soundness of the reported gaps (modality, reasoning, locality) cannot be fully assessed because the manuscript provides no detailed scoring rubrics, inter-annotator agreement for expert-verified rationales, error bars on the 55-model results, or full methodology for the four dimensions.
Authors: We agree that additional details on the evaluation protocol are needed for full assessment and reproducibility. In the revised manuscript, we will add an appendix containing the complete scoring rubrics for each dimension, report inter-annotator agreement statistics for the expert-verified rationales, include error bars or standard deviations on the model performance results, and expand the methodology section with a step-by-step description of how the four dimensions were constructed, sourced from national exams, and validated. revision: yes
Circularity Check
No circularity: benchmark construction and empirical evaluation are independent of results
full rationale
The paper introduces K-MetBench as a new diagnostic dataset sourced from external national qualification exams, then reports direct model performance measurements across four dimensions. No equations, fitted parameters, or derivations are present that would reduce any claim to the benchmark inputs by construction. Performance gaps (including Korean vs. global model comparisons) are presented as observed outcomes rather than predictions derived from the evaluation framework itself. Self-citations, if any, are not load-bearing for the central empirical findings, and the work does not invoke uniqueness theorems or ansatzes from prior author work to justify its methodology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption National qualification exams provide a valid proxy for expert-level meteorology reasoning.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.10105
Varco-vision-2.0 technical report. arXiv preprint arXiv:2509.10105. Jian Chen, Peilin Zhou, Yining Hua, Dading Chong, Meng Cao, Y aowei Li, Wei Chen, Bing Zhu, Junwei Liang, and Zixuan Yuan. 2025. Climateiqa: A new dataset and benchmark to advance vision-language models in meteorology anomalies analysis. In Pro- ceedings of the 31st ACM SIGKDD Conference ...
-
[2]
LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods
Llms-as-judges: a comprehensive survey on llm-based evaluation methods. arXiv preprint arXiv:2412.05579. Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Y asunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Ku- mar, and 1 others. 2022. Holistic evaluation of lan- guage models. arXiv preprint arXiv:2211.09110. Chengqi...
work page internal anchor Pith review arXiv 2022
-
[3]
Weatherqa: Can multimodal language models reason about severe weather?
Weatherqa: Can multimodal language mod- els reason about severe weather? arXiv preprint arXiv:2406.11217. Veeramakali Vignesh Manivannan, Y asaman Jafari, Srikar Eranky, Spencer Ho, Rose Yu, Duncan Watson-Parris, Yian Ma, Leon Bergen, and Taylor Berg-Kirkpatrick. 2024. Climaqa: An automated evaluation framework for climate question answer- ing models. arX...
-
[4]
Show Your Work: Scratchpads for Intermediate Computation with Language Models
Show your work: Scratchpads for interme- diate computation with language models . arXiv preprint arXiv:2112.00114. OpenAI. 2025. Update to gpt-5 system card: Gpt-5.2 . Accessed: 2026-01-04. A Y ang Qwen, Baosong Y ang, B Zhang, B Hui, B Zheng, B Yu, Chengpeng Li, D Liu, F Huang, H Wei, and 1 others. 2024. Qwen2. 5 technical re- port. arXiv preprint. LG Re...
work page internal anchor Pith review arXiv 2025
-
[5]
Galactica: A Large Language Model for Science
Galactica: A large language model for science. arXiv preprint arXiv:2211.09085. Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Mil- lican, and 1 others. 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805. Miles Turpin, J...
work page internal anchor Pith review arXiv 2023
-
[6]
Qwen3 technical report. arXiv preprint arXiv:2505.09388. Kang Min Y oo, Jaegeun Han, Sookyo In, Heewon Jeon, Jisu Jeong, Jaewook Kang, Hyunwook Kim, Kyung- Min Kim, Munhyong Kim, Sungju Kim, and 1 others
work page internal anchor Pith review arXiv
-
[7]
arXiv preprint arXiv:2404.01954
Hyperclova x technical report. arXiv preprint arXiv:2404.01954. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Y onghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, and 1 others
-
[8]
Advances in neural information pro- cessing systems, 36:46595–46623
Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information pro- cessing systems, 36:46595–46623. Appendix Table of Contents A Dataset Examples 15 B Case Study of Reasoning Answer 15 C Prompts and Questionnaires for Benchmark Construction 15 C.1 Question Paraphrasing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ...
-
[9]
500 hPa 일기도의 한랭기압골에서 등온선의 진폭이 등고선의 진폭보다 클 경우에는 그 기압골의 후방에 약한 상승기류가 있고, 전방에 약한 하강기류가 있다
-
[10]
300 hPa 면에서는 온도가 지형, 복사의 영향을 받으므로 전선분석이 용이하다
-
[11]
300 hPa 제트기류 출구의 좌측에 하강기류, 우측에 상승기류가 있으며, 입구에서는 좌측에 상승기류, 우측에 하강기류가 있다
-
[12]
500 hPa 기류가 지상 한랭전선에 수직으로 불면 이 전선은 활성으로서 악천이 나타난다
-
[13]
In a cold trough on a 500 hPa chart, if the amplitude of the isotherms is larger than the amplitude of the contours (geopotential height), there is a weak updraft behind the trough and a weak downdraft ahead of it
-
[14]
On the 300 hPa surface, temperature is affected by topography and radiation, making frontal analysis easy
-
[15]
At the exit of a 300 hPa jet stream, there is a downdraft on the left and an updraft on the right; at the entrance, there is an updraft on the left and a downdraft on the right
-
[16]
정답: 1 Ground Truth: 1 ID: 65, Part: 5 질문: 다음은 한국 지역에 영향을 주는 고기압의 특성을 설명한 것이다
If the 500 hPa airflow blows perpendicular to a surface cold front, the front becomes active and severe weather occurs. 정답: 1 Ground Truth: 1 ID: 65, Part: 5 질문: 다음은 한국 지역에 영향을 주는 고기압의 특성을 설명한 것이다. 내용이 옳지 않은 것은? Question: The following describes the characteristics of high-pressure systems affecting the Korean region. Which statement is incorrect?
-
[17]
시베리아 고기압은 겨울철의 춥고 건조한 날씨를 만든다
-
[18]
오호츠크해 고기압은 동해안 지방의 고온현상을 일으킨다
-
[19]
북태평양 고기압은 고온다습하며, 여름철의 무더운 날씨를 만든다
-
[20]
이동성 고기압의 영향을 받으면 봄에는 따뜻한 날씨, 가을에는 맑은 날씨가 된다
-
[21]
The Siberian High creates cold and dry weather during the winter
-
[22]
The Okhotsk Sea High causes high-temperature phenomena in the east coastal regions
-
[23]
The North Pacific High is hot and humid, creating sweltering weather during the summer
-
[24]
정답: 2 Ground Truth: 2 ID: 18, Part: 2 질문: 비열의 차원을 올바르게 나타낸 것은 무엇입니까? Question: What is the correct dimensional representation of specific heat?
Under the influence of migratory highs, the weather becomes warm in spring and clear in autumn. 정답: 2 Ground Truth: 2 ID: 18, Part: 2 질문: 비열의 차원을 올바르게 나타낸 것은 무엇입니까? Question: What is the correct dimensional representation of specific heat?
-
[25]
[$L^2T^2\theta^{-1}$]
-
[26]
[$L^2T^{-2}\theta^{-1}$]
-
[27]
Expert-Verified Rationale: Specific heat is the energy required to raise the temperature of a unit mass by one unit
[$ML^2T^{-2}$] 전문가 검증 참조 자료: 비열은 단위 질량당 단위 온도 상승에 필요한 에너지로서 차원은 (에너지)/(질량 · 온도)= $(ML^2T^{-2})/(M\theta) = L^2T^{-2}\theta^{-1}$ 이므로 2번이 맞고, 4번은 에너지 자체의 차원, 3번은 압력의 차원, 1번은 시간 지수가 부호가 반대라 틀립니다. Expert-Verified Rationale: Specific heat is the energy required to raise the temperature of a unit mass by one unit. Its dimension is (Energy)/(Mass · Temperature)...
-
[28]
Soil moisture surplus
-
[29]
Soil moisture recharge
-
[30]
Soil moisture utilization
-
[31]
Soil moisture deficit 정답: 3 Ground Truth: 3 ID: 460, Part: 3 질문: 다음 그림이 보여주는 역전층의 종류로 옳은 것은? Question: Which of the following is the correct type of inversion layer shown in the figure below?
-
[32]
Turbulence inversion
-
[33]
Subsidence inversion 전문가 검증 참조 자료: 그림처럼 지표에서 바로 시작하는 얕은 역전층이 위로 갈수록 약화되는 형태는 야간 지표 복사냉각으로 생기는 복사역전의 전형이며, 침강역전은 고기압 하 하강류로 상층에 분리되어 나타나고 전선역전은 전선면을 따라 경사져 있으며 난류역전은 주간 혼합층 꼭대기에 형성되어 지표에서 시작하지 않으므로 그림과 다르다. Expert-Verified Rationale: As shown in the figure, a shallow inversion layer starting directly from the surface and weakening with height is typical of...
-
[34]
It increases as altitude increases
-
[35]
It decreases as latitude increases
-
[36]
It increases as pressure increases
-
[37]
Our country
It increases if air viscosity is high. 전문가 검증 참조 자료: 지균풍은 V g = | p|/(ρ f)이므로 기압경도와 밀도가 일정 하면 코리올리매개변수 f=2Ω sinφ만이 변수가 되어 위도가 증가할수록 f가 커 져 풍속은 감소하며, 절대 기압의 크기 (보기 3)나 고도(보기 1), 점성(보기 4) 은 이 관계식에 직접 등장하지 않는다. Expert-Verified Rationale: Since the geostrophic wind is defined as Vg = | p|/(ρ f), if the pressure gradient and den- sity are constant, the Corioli...
2025
-
[38]
List of Factual Errors
were precisely corrected based on expert consultation. Through this process, we secured the integrity of the final 141 reasoning evaluation sam- ples. Table 11 presents the specific questionnaire used for this expert verification process. C.7 Reasoning Prompt for Open-Source LLMs Figure 18 presents the system prompt utilized for generating reasoning paths...
2025
-
[39]
- (논리성) 추론이 정답을 명확하고 직접적으로 뒷받침하도록 설명하세요
핵심 추론 근거 생성(한 문장): - (정확성) 반드시 정답이 왜 맞는지 추론 내용이 기상학적 사실에 부합하게 설명하세요. - (논리성) 추론이 정답을 명확하고 직접적으로 뒷받침하도록 설명하세요. - (완결성) 문제의 핵심을 회피하지 않고 설명하세요. 가능하면, 가장 그럴듯한 오답 선택지가 왜 틀렸는지도 간단히 언급하여 정답의 논리를 강화하세요. - (간결성) 불필요한 내용 없이 한 문장으로 잘 요약하여 작성하세요
-
[40]
응답 규칙 - 반드시 아래 JSON 형식만 사용하여 답변해주세요
정답 결정: - 충분한 추론을 바탕으로, 최종적으로 정답 번호(선택지 번호)를 명확히 결정하세요. 응답 규칙 - 반드시 아래 JSON 형식만 사용하여 답변해주세요. - 추론 근거가 반드시 먼저 도출되고, 그 다음에 정답을 명시해야 합니다. - 각 항목은 모두 반드시 포함하며, 변수명 및 구조는 아래와 같이 한글로 작성해야 합니다. { {”생성된_추론_근거”: ”{한 문장, 논리적 설명. 정답이 왜 맞고 주요 오답이 왜 틀렸는지 포함. 학생이 쉽게 이해할 수 있게 간결하게 작성.} ”, ”정답”: ”{계산된 정답 번호(숫자만)} ” } Figure 16: System prompt used to generate a reasoning r...
-
[41]
- (Logicality) Explain the reasoning so that it clearly and directly supports the answer
Generate Core Reasoning Rationale (One Sentence): - (Factuality) Y ou must explain why the answer is correct based on meteorological facts. - (Logicality) Explain the reasoning so that it clearly and directly supports the answer. - (Depth) Do not avoid the core of the question. If possible, briefly mention why the most plausible distractors are wrong to s...
-
[42]
Response Rules - Y ou must answer strictly using the JSON format below
Determine Correct Answer: - Based on sufficient reasoning, clearly determine the final answer number (option number). Response Rules - Y ou must answer strictly using the JSON format below. - The reasoning rationale must be derived first, followed by the answer. - All fields must be included, and variable names and structure must be written as shown below...
-
[43]
생성된 _ 추론 _ 근거
(“생성된 _ 추론 _ 근거”): 어떤 논리적 과정을 통해 정답을 선택했는지 간결한 문단 형태 로 작성합니 다. < scratchpad>의 내용을 그대로 복사하지 말고, 핵심만 요약하고 재구성해야 합니다. (정확성, 논리성, 간결성, 핵심 파악 기준 고려)
-
[44]
반드시 정수 숫자만 채워서 출력해야 합니다
(“정답”): 위 추론에 근거하여 최종 정답이라고 생각하는 선택지 번호를 하나 고릅니다. 반드시 정수 숫자만 채워서 출력해야 합니다. 전체 응답 형식 (Full Response Format) - 당신의 답변은 <scratchpad>블록과 JSON 코드 블록, 두 부분으로 구성되어야 합니다. - 아래 예시와 같이 < scratchpad>가 먼저 제시되고, 그 바로 다음에 반드시 JSON 코드 블록으로 감싸진 최종 답변이 와야 합니다. <scratchpad> 여기에 당신의 모든 생각 과정을 자유롭게 서술합니다. 예시: F = (C *9/5) + 32 공식 사용... </scratchpad> ‘‘‘json { ”생성된_추론_근거”: ”섭...
-
[45]
Generated_Rationale
(“Generated_Rationale”): Write a concise paragraph explaining the logical process used to select the answer. Do not copy the <scratchpad>content directly; summarize and restructure only the key points. (Consider accuracy, logic, conciseness, and core identification criteria. )
-
[46]
Must output only an integer
(“Answer”): Select the option number you think is the final correct answer based on the reasoning above. Must output only an integer. Full Response Format - Y our response must consist of two parts: a <scratchpad>block and a JSON code block. - As shown in the example below, the <scratchpad>must be presented first, immediately followed by the final answer ...
-
[47]
(질문, 선택지, 정답 포함)
<문제 정보>: 평가의 맥락이 되는 원본 객관식 문제입니다. (질문, 선택지, 정답 포함)
-
[48]
이 자료는 <평가 대상 답변>의 ’사실 오류’ 나 ’환각( Hallucination)’을 탐지하는 절대 기준으로 사용해야 합니다
<전문가 검증 참조 자료> : 100% 사실이 검증된 모범 해설 자료입니다. 이 자료는 <평가 대상 답변>의 ’사실 오류’ 나 ’환각( Hallucination)’을 탐지하는 절대 기준으로 사용해야 합니다
-
[49]
### 사고 과정 (Step-by-Step Thinking Process) 당신은 평가를 수행하기 전에 반드시 다음의 사고 과정을 거쳐야 합니다
<평가 대상 답변>: 당신이 채점해야 할 ’수험생 AI’가 생성한 추론 과정 및 정답입니다. ### 사고 과정 (Step-by-Step Thinking Process) 당신은 평가를 수행하기 전에 반드시 다음의 사고 과정을 거쳐야 합니다
-
[50]
[사실 확인] : <평가 대상 답변>의 모든 주장을 <전문가 검증 참조 자료>와 비교하여 사실 오류가 있는지 먼저 확인하고 목록을 작성합니다
-
[51]
[개별 축 평가] : 아래의 4가지 ‘평가 기준 및 척도’를 하나씩 읽고, 각 기준에 따라 <평가 대상 답변>이 몇 점에 해당하는지 근거와 함께 판단합니다
-
[52]
### 평가 기준 및 척도 (Evaluation Criteria and Scale ) 각 평가 축에 대해 1점(매우 부족)부터 5점(매우 우수)까지 정수 점수를 부여합니다
[종합 및 형식화]: 모든 판단이 끝나면, 그 내용을 종합하여 최종 출력 JSON 형식을 작성합니다. ### 평가 기준 및 척도 (Evaluation Criteria and Scale ) 각 평가 축에 대해 1점(매우 부족)부터 5점(매우 우수)까지 정수 점수를 부여합니다. * 1) 사실적 정확성 (Factual Accuracy) [1-5점] * 추론 내용이 기상학적 사실에 완벽하게 부합하며 오류가 없는가? * 5점: 모든 내용이 <전문가 검증 참조 자료 >에 기반하여 완벽하게 정확함. * 3점: 핵심 논리는 맞지만, 결론에 영향을 미치지 않는 사소한 오류나 부정확한 표현이 포함됨. * 1점: 결론의 정당성을 훼손하는 중대한 사실 ...
-
[53]
<Problem Information >: The original multiple-choice question serving as the context for evaluation (includes the question, options, and correct answer )
-
[54]
This material must be used as the absolute standard for detecting ‘factual errors’ or ‘hallucinations’ in the <Response for Evaluation >
<Expert Verification Reference Material >: Model explanation material with 100% verified facts. This material must be used as the absolute standard for detecting ‘factual errors’ or ‘hallucinations’ in the <Response for Evaluation >
-
[55]
### Step-by-Step Thinking Process Y ou must go through the following thinking process before performing the evaluation
<Response for Evaluation >: The reasoning process and answer generated by the ‘Examinee AI’ that you are required to grade. ### Step-by-Step Thinking Process Y ou must go through the following thinking process before performing the evaluation
-
[56]
Fully understand all input information
-
[57]
[Fact Check]: Compare every claim in the <Response for Evaluation >against the <Expert Verification Reference Material >to first identify any factual errors and compile a list
-
[58]
[Individual Axis Evaluation ]: Read the four ‘Evaluation Criteria and Scale ’ below one by one, and determine the score for the <Response for Evaluation >based on each criterion, along with the rationale
-
[59]
### Evaluation Criteria and Scale Assign an integer score from 1 (Very Poor) to 5 (Excellent) for each evaluation axis according to the criteria below
[Synthesis and Formatting ]: Once all judgments are complete, synthesize the content to create the final output JSON format. ### Evaluation Criteria and Scale Assign an integer score from 1 (Very Poor) to 5 (Excellent) for each evaluation axis according to the criteria below. * 1) Factual Accuracy [1-5 points] * Does the reasoning perfectly align with met...
-
[60]
{{Choice_1_text}} [{{Choice_1_image}}]
-
[61]
{{Choice_2_text}} [{{Choice_2_image}}]
-
[62]
{{Choice_3_text}} [{{Choice_3_image}}]
-
[63]
The placeholders enclosed in square brackets (e.g., [Question_image]) denote optional fields that are populated only when the corresponding image exists in the dataset
{{Choice_4_text}} [{{Choice_4_image}}] Figure 26: Text-Only/Multimodal MCQA user prompt template. The placeholders enclosed in square brackets (e.g., [Question_image]) denote optional fields that are populated only when the corresponding image exists in the dataset. This single template covers all four modality configurations (i.e., text-only, image-in-qu...
-
[64]
{{Choice_1_Text}} [**(선택지 1 이미지):** {{Choice_1_image}}]
-
[65]
{{Choice_2_Text}} [**(선택지 2 이미지):** {{Choice_2_image}}]
-
[66]
{{Choice_3_Text}} [**(선택지 3 이미지):** {{Choice_3_image}}]
-
[67]
The placeholders enclosed in square brackets denote op- tional image fields populated based on data availability
{{Choice_4_Text}} [**(선택지 4 이미지):** {{Choice_4_image}}] **정답:** {{Correct_Answer}} ### <전문가 검증 참조 자료 > {{Rationale_Content}}% populates ‘(자료 없음)’ if wo_rationale is True ### <평가 대상 답변 > **생성된 추론 근거:** {{Generated_Reasoning}} **답안:** {{Predicted_Answer}} — END INPUT DATA — Figure 27: Reasoning MCQA user prompt template. The placeholders enclosed in square ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.