Recognition: unknown
OmniShotCut: Holistic Relational Shot Boundary Detection with Shot-Query Transformer
Pith reviewed 2026-05-08 04:11 UTC · model grok-4.3
The pith
OmniShotCut reframes shot boundary detection as joint relational prediction of shot ranges and their intra- and inter-shot relations via a query-based video Transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Formulating SBD as structured relational prediction, the shot query-based dense video Transformer jointly estimates shot ranges together with intra-shot relations and inter-shot relations, trained on synthetic transitions that supply exact boundaries and diverse variants.
What carries the argument
Shot query-based dense video Transformer that performs holistic relational prediction over shot ranges, intra-shot relations, and inter-shot relations.
If this is right
- Joint prediction of ranges and relations yields more interpretable shot structures and fewer missed subtle discontinuities.
- The synthetic pipeline supplies precise boundaries and parameterized transition variants without manual annotation effort.
- OmniShotCutBench enables diagnostic evaluation that exposes specific weaknesses across diverse video domains.
- Avoiding reliance on noisy low-diversity labels improves consistency on transitions that prior methods handle poorly.
Where Pith is reading between the lines
- The relational formulation could transfer to related video tasks such as cut-aware summarization or editing assistance.
- Scaling the synthetic generator to additional transition families might further reduce the need for real annotated data.
- Diagnostic benchmarks of this style could be adapted to measure progress on other temporal video segmentation problems.
Load-bearing premise
The fully synthetic transition synthesis pipeline produces transitions whose statistics and failure modes match those of real-world video edits closely enough that models trained on it will generalize.
What would settle it
Running the trained OmniShotCut model on a large collection of real-world videos that have independently verified shot boundaries and finding substantially lower accuracy or different error patterns than on the synthetic test set.
Figures

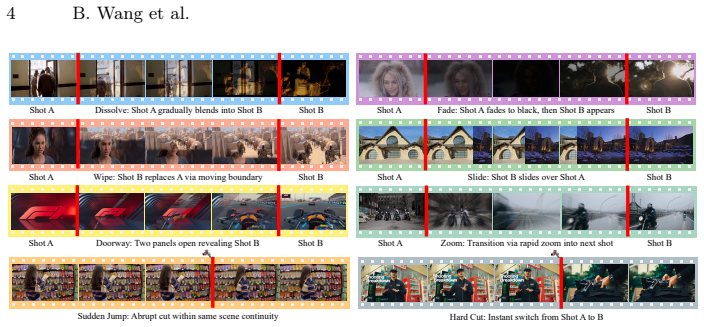
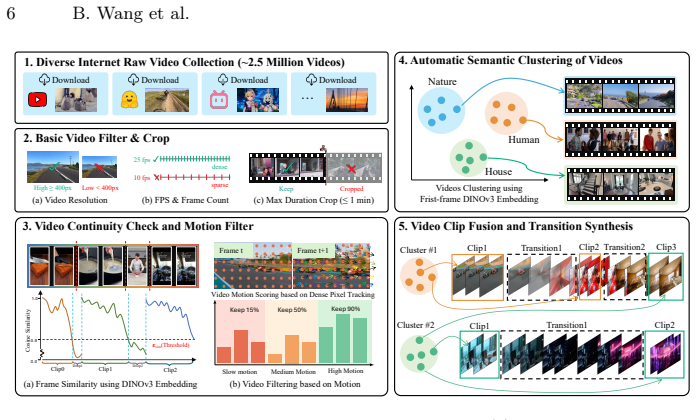
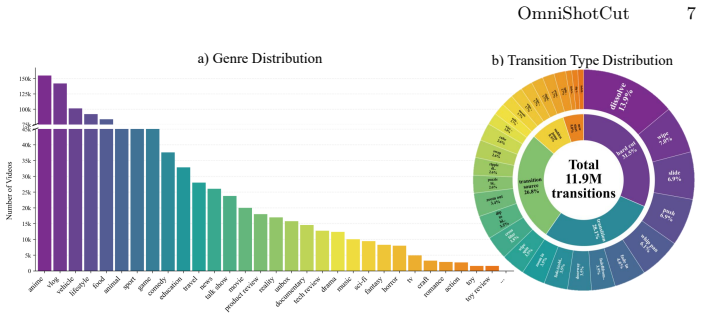
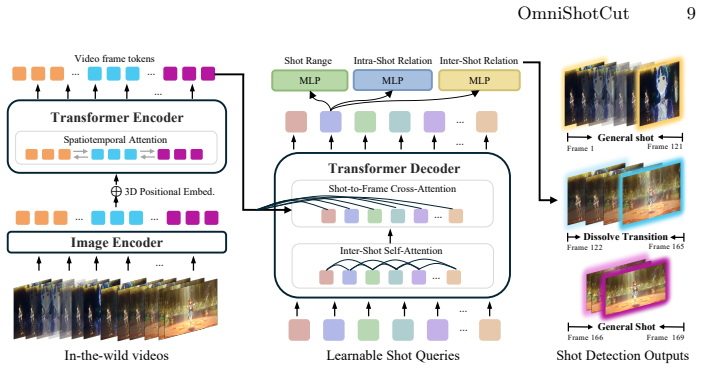






read the original abstract
Shot Boundary Detection (SBD) aims to automatically identify shot changes and divide a video into coherent shots. While SBD was widely studied in the literature, existing state-of-the-art methods often produce non-interpretable boundaries on transitions, miss subtle yet harmful discontinuities, and rely on noisy, low-diversity annotations and outdated benchmarks. To alleviate these limitations, we propose OmniShotCut to formulate SBD as structured relational prediction, jointly estimating shot ranges with intra-shot relations and inter-shot relations, by a shot query-based dense video Transformer. To avoid imprecise manual labeling, we adopt a fully synthetic transition synthesis pipeline that automatically reproduces major transition families with precise boundaries and parameterized variants. We also introduce OmniShotCutBench, a modern wide-domain benchmark enabling holistic and diagnostic evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OmniShotCut, a shot-query-based dense video Transformer that reformulates shot boundary detection (SBD) as structured relational prediction. It jointly estimates shot ranges together with intra-shot and inter-shot relations. To mitigate noisy manual labels, the method uses a fully synthetic transition synthesis pipeline that generates precise boundaries and parameterized variants of major transition families, and introduces the OmniShotCutBench benchmark for holistic and diagnostic evaluation.
Significance. If the central claims hold, the work could advance SBD by moving beyond non-interpretable boundaries and subtle discontinuity misses toward relational, diagnostic outputs, while the synthetic pipeline and new benchmark address longstanding annotation and evaluation limitations. The approach is notable for its attempt at parameter-free synthetic data generation and structured prediction, but its impact depends on empirical validation of generalization from synthetic to real edits.
major comments (2)
- [Abstract / §3] Abstract and §3 (synthetic pipeline description): the assertion that the fully synthetic transition synthesis pipeline 'automatically reproduces major transition families with precise boundaries and parameterized variants' is load-bearing for all generalization claims, yet the manuscript provides no quantitative validation (e.g., histograms of transition duration, motion coherence, or artifact distributions) comparing synthetic outputs to real edits in OmniShotCutBench or external datasets. Without this, the risk that the relational prediction head overfits to synthetic-specific artifacts remains unaddressed.
- [Abstract / §5] Abstract and §5 (experiments): the abstract claims improvements over prior SBD limitations, but no quantitative results, ablation studies on the relational heads, or error analysis on subtle discontinuities are referenced. This absence prevents verification of whether the shot-query Transformer and joint relational formulation actually deliver the stated gains over existing methods.
minor comments (2)
- [Abstract] The abstract introduces OmniShotCutBench as 'a modern wide-domain benchmark enabling holistic and diagnostic evaluation' without specifying its scale, domain coverage, or the concrete diagnostic metrics used.
- [§3] Notation for intra-shot and inter-shot relations is introduced without an accompanying equation or diagram clarifying how these are encoded in the Transformer output heads.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on our manuscript. We appreciate the emphasis on strengthening the empirical support for our synthetic data pipeline and experimental claims. Below, we provide point-by-point responses to the major comments and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (synthetic pipeline description): the assertion that the fully synthetic transition synthesis pipeline 'automatically reproduces major transition families with precise boundaries and parameterized variants' is load-bearing for all generalization claims, yet the manuscript provides no quantitative validation (e.g., histograms of transition duration, motion coherence, or artifact distributions) comparing synthetic outputs to real edits in OmniShotCutBench or external datasets. Without this, the risk that the relational prediction head overfits to synthetic-specific artifacts remains unaddressed.
Authors: We acknowledge that the manuscript currently lacks quantitative statistical comparisons between the synthetic transitions and real-world edits, which would better substantiate the generalization from synthetic training data. The description in §3 focuses on the design of the parameterized synthesis to cover major transition families with precise boundaries, supported by qualitative visualizations. To address this concern directly, we will add a new subsection or appendix with quantitative analyses, including histograms of transition durations, motion coherence metrics, and artifact distributions, comparing synthetic samples to real edits from OmniShotCutBench and other datasets. This will help demonstrate that the synthetic pipeline does not introduce overfitting risks. revision: yes
-
Referee: [Abstract / §5] Abstract and §5 (experiments): the abstract claims improvements over prior SBD limitations, but no quantitative results, ablation studies on the relational heads, or error analysis on subtle discontinuities are referenced. This absence prevents verification of whether the shot-query Transformer and joint relational formulation actually deliver the stated gains over existing methods.
Authors: The experiments in §5 do include quantitative comparisons of OmniShotCut against state-of-the-art SBD methods on OmniShotCutBench, reporting metrics for shot boundary detection accuracy and relational prediction performance. However, we agree that the abstract does not explicitly reference these numbers, and dedicated ablations isolating the contribution of the relational heads (intra-shot and inter-shot) as well as targeted error analysis on subtle discontinuities are not prominently featured. In the revised manuscript, we will update the abstract to reference key quantitative improvements, expand §5 with ablation studies on the relational components, and include a detailed error analysis section focusing on cases of subtle discontinuities to provide clearer verification of the gains. revision: yes
Circularity Check
No circularity: new architecture and synthetic pipeline are independent contributions
full rationale
The paper presents OmniShotCut as a new shot-query Transformer formulation for structured relational SBD prediction and adopts a fully synthetic transition synthesis pipeline to generate training data with precise boundaries. No equations, derivations, or central claims reduce by construction to fitted parameters, self-definitions, or self-citation chains; the method and benchmark are introduced as standalone proposals without load-bearing reliance on prior self-referential results. The derivation chain is self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic transitions with parameterized variants reproduce the distribution of real shot changes sufficiently for model training and evaluation.
invented entities (1)
-
Shot-Query Transformer
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Cosmos World Foundation Model Platform for Physical AI
Agarwal, N., Ali, A., Bala, M., Balaji, Y., Barker, E., Cai, T., Chattopadhyay, P., Chen, Y., Cui, Y., Ding, Y., et al.: Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575 (2025)
work page internal anchor Pith review arXiv 2025
-
[3]
In: TREC video retrieval evaluation (TRECVID) (2017)
Awad, G., Butt, A.A., Fiscus, J., Joy, D., Delgado, A., Mcclinton, W., Michel, M., Smeaton, A.F., Graham, Y., Kraaij, W., et al.: Trecvid 2017: evaluating ad-hoc and instance video search, events detection, video captioning, and hyperlinking. In: TREC video retrieval evaluation (TRECVID) (2017)
2017
-
[4]
In: Proceedings of the 23rd ACM international conference on Multimedia
Baraldi, L., Grana, C., Cucchiara, R.: A deep siamese network for scene detection in broadcast videos. In: Proceedings of the 23rd ACM international conference on Multimedia. pp. 1199–1202 (2015)
2015
-
[5]
In: International conference on computer analysis of images and patterns
Baraldi, L., Grana, C., Cucchiara, R.: Shot and scene detection via hierarchical clustering for re-using broadcast video. In: International conference on computer analysis of images and patterns. pp. 801–811. Springer (2015)
2015
-
[6]
arXiv preprint arXiv:2512.21778 (2025)
Berman, N., Botach, A., Ben-Baruch, E., Hakimi, S.H., Gendler, A., Naiman, I., Yosef, E., Kviatkovsky, I.: Scene-vlm: Multimodal video scene segmentation via vision-language models. arXiv preprint arXiv:2512.21778 (2025)
-
[7]
In: European conference on computer vision
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: European conference on computer vision. pp. 213–229. Springer (2020)
2020
-
[8]
Castellano, B.: Pyscenedetect: Python and opencv-based scene cut/transition de- tection program & library.https://github.com/Breakthrough/PySceneDetect (2025), software
2025
-
[9]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, S., Nie, X., Fan, D., Zhang, D., Bhat, V., Hamid, R.: Shot contrastive self-supervised learning for scene boundary detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9796–9805 (2021)
2021
-
[10]
arXiv preprint arXiv:1705.03281 (2017)
Hassanien,A.,Elgharib,M.,Selim,A.,Bae,S.H.,Hefeeda,M.,Matusik,W.:Large- scale, fast and accurate shot boundary detection through spatio-temporal convo- lutional neural networks. arXiv preprint arXiv:1705.03281 (2017)
-
[11]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016) 16 B. Wang et al
2016
-
[12]
arXiv preprint arXiv:2511.13715 (2025)
Hu, H., Ying, K., Ding, H.: Segment anything across shots: A method and bench- mark. arXiv preprint arXiv:2511.13715 (2025)
-
[13]
In: European conference on computer vision
Huang, Q., Xiong, Y., Rao, A., Wang, J., Lin, D.: Movienet: A holistic dataset for movie understanding. In: European conference on computer vision. pp. 709–727. Springer (2020)
2020
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video gener- ative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024)
2024
-
[15]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Jeelani, M., Cheema, N., Illgner-Fehns, K., Slusallek, P., Jaiswal, S., et al.: Expand- ing synthetic real-world degradations for blind video super resolution. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1199–1208 (2023)
2023
-
[16]
Artificial Intelligence Review57(4), 104 (2024)
Kar, T., Kanungo, P., Mohanty, S.N., Groppe, S., Groppe, J.: Video shot-boundary detection: issues, challenges and solutions. Artificial Intelligence Review57(4), 104 (2024)
2024
-
[17]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Karaev, N., Makarov, Y., Wang, J., Neverova, N., Vedaldi, A., Rupprecht, C.: Cotracker3: Simpler and better point tracking by pseudo-labelling real videos. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6013–6022 (2025)
2025
-
[18]
Naval research logistics quarterly2(1-2), 83–97 (1955)
Kuhn, H.W.: The hungarian method for the assignment problem. Naval research logistics quarterly2(1-2), 83–97 (1955)
1955
-
[19]
Advances in Neural Information Processing Systems34, 11846–11858 (2021)
Lei, J., Berg, T.L., Bansal, M.: Detecting moments and highlights in videos via natural language queries. Advances in Neural Information Processing Systems34, 11846–11858 (2021)
2021
-
[20]
Sekai: A video dataset towards world exploration.arXiv preprint arXiv:2506.15675, 2025
Li, Z., Li, C., Mao, X., Lin, S., Li, M., Zhao, S., Xu, Z., Li, X., Feng, Y., Sun, J., et al.: Sekai: A video dataset towards world exploration. arXiv preprint arXiv:2506.15675 (2025)
-
[21]
Towards un- derstanding camera motions in any video.arXiv preprint arXiv:2504.15376,
Lin, Z., Cen, S., Jiang, D., Karhade, J., Wang, H., Mitra, C., Ling, T., Huang, Y., Liu, S., Chen, M., et al.: Towards understanding camera motions in any video. arXiv preprint arXiv:2504.15376 (2025)
-
[22]
Shotbench: Expert-level cinematic understanding in vision-language models,
Liu, H., He, J., Jin, Y., Zheng, D., Dong, Y., Zhang, F., Huang, Z., He, Y., Li, Y., Chen, W., et al.: Shotbench: Expert-level cinematic understanding in vision- language models. arXiv preprint arXiv:2506.21356 (2025)
-
[23]
Machine Intelligence Research21(5), 831–869 (2024)
Mumuni, A., Mumuni, F., Gerrar, N.K.: A survey of synthetic data augmentation methods in machine vision. Machine Intelligence Research21(5), 831–869 (2024)
2024
-
[24]
In: Proceedings of the Asian Conference on Computer Vision
Mun, J., Shin, M., Han, G., Lee, S., Ha, S., Lee, J., Kim, E.S.: Bassl: Boundary- aware self-supervised learning for video scene segmentation. In: Proceedings of the Asian Conference on Computer Vision. pp. 4027–4043 (2022)
2022
-
[25]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Nan, K., Xie, R., Zhou, P., Fan, T., Yang, Z., Chen, Z., Li, X., Yang, J., Tai, Y.: Openvid-1m: A large-scale high-quality dataset for text-to-video generation. arXiv preprint arXiv:2407.02371 (2024)
work page internal anchor Pith review arXiv 2024
-
[26]
arXiv preprint arXiv:2405.07425 (2024)
Pan, Z.: Sakuga-42m dataset: Scaling up cartoon research. arXiv preprint arXiv:2405.07425 (2024)
-
[27]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rao, A., Xu, L., Xiong, Y., Xu, G., Huang, Q., Zhou, B., Lin, D.: A local-to- global approach to multi-modal movie scene segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10146– 10155 (2020)
2020
-
[28]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025) OmniShotCut 17
work page internal anchor Pith review arXiv 2025
-
[29]
In: Proceedings of the 32nd ACM International Confer- ence on Multimedia
Soucek, T., Lokoc, J.: Transnet v2: An effective deep network architecture for fast shot transition detection. In: Proceedings of the 32nd ACM International Confer- ence on Multimedia. pp. 11218–11221 (2024)
2024
-
[30]
Souček, T., Moravec, J., Lokoč, J.: Transnet: A deep network for fast detection of common shot transitions. arXiv preprint arXiv:1906.03363 (2019)
-
[31]
In: Proceedings of the 19th International Conference on Mining Software Repositories
Taesiri, M.R., Macklon, F., Bezemer, C.P.: Clip meets gamephysics: Towards bug identification in gameplay videos using zero-shot transfer learning. In: Proceedings of the 19th International Conference on Mining Software Repositories. pp. 270–281 (2022)
2022
-
[32]
Vidgen-1m: A large-scale dataset for text-to-video generation.arXiv preprint arXiv:2408.02629, 2024
Tan, Z., Yang, X., Qin, L., Li, H.: Vidgen-1m: A large-scale dataset for text-to- video generation. arXiv preprint arXiv:2408.02629 (2024)
-
[33]
In: Asian Conference on Computer Vision
Tang, S., Feng, L., Kuang, Z., Chen, Y., Zhang, W.: Fast video shot transition lo- calization with deep structured models. In: Asian Conference on Computer Vision. pp. 577–592. Springer (2018)
2018
-
[34]
arXiv preprint arXiv:2405.15613 (2024)
Vo, H.V., Khalidov, V., Darcet, T., Moutakanni, T., Smetanin, N., Szafraniec, M., Touvron, H., Couprie, C., Oquab, M., Joulin, A., et al.: Automatic data cu- ration for self-supervised learning: A clustering-based approach. arXiv preprint arXiv:2405.15613 (2024)
-
[35]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review arXiv 2025
-
[36]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Wang, B., Liu, B., Liu, S., Yang, F.: Vcisr: Blind single image super-resolution with video compression synthetic data. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 4302–4312 (2024)
2024
-
[37]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Wang, Q., Shi, Y., Ou, J., Chen, R., Lin, K., Wang, J., Jiang, B., Yang, H., Zheng, M., Tao, X., et al.: Koala-36m: A large-scale video dataset improving consistency between fine-grained conditions and video content. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 8428–8437 (2025)
2025
-
[38]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision
Wang, S.Y., Wang, O., Owens, A., Zhang, R., Efros, A.A.: Detecting photoshopped faces by scripting photoshop. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision. pp. 10072–10081 (2019)
2019
-
[39]
In: Proceedings of the IEEE/CVF in- ternational conference on computer vision
Wang, X., Xie, L., Dong, C., Shan, Y.: Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In: Proceedings of the IEEE/CVF in- ternational conference on computer vision. pp. 1905–1914 (2021)
1905
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Y., Xu, Z., Wang, X., Shen, C., Cheng, B., Shen, H., Xia, H.: End-to-end video instance segmentation with transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8741–8750 (2021)
2021
-
[41]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review arXiv 2025
-
[42]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
work page internal anchor Pith review arXiv 2024
-
[43]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhu, W., Huang, Y., Xie, X., Liu, W., Deng, J., Zhang, D., Wang, Z., Liu, J.: Autoshot: A short video dataset and state-of-the-art shot boundary detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2238–2247 (2023) 18 B. Wang et al. 7 Supplementary Overview Thissupplementarymaterialprovidesmoreimplementatio...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.