Recognition: unknown
Elderly-Contextual Data Augmentation via Speech Synthesis for Elderly ASR
Pith reviewed 2026-05-10 13:56 UTC · model grok-4.3
The pith
Augmenting elderly speech data with LLM paraphrases and TTS cuts recognition errors by up to 58%
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
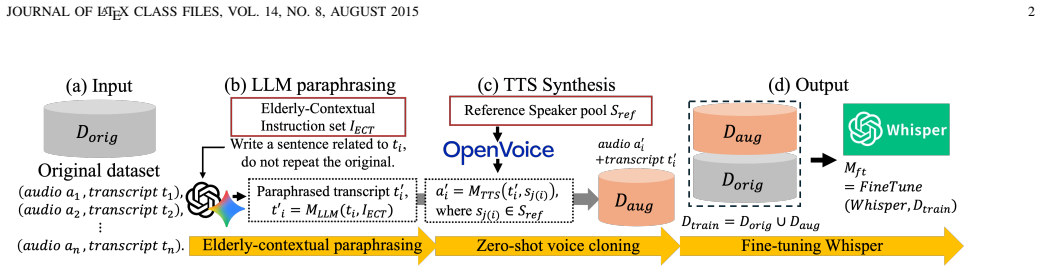
The central discovery is that fine-tuning Whisper on original elderly speech combined with synthetic data generated from LLM-paraphrased elderly-contextual transcripts synthesized via TTS with elderly reference speakers produces up to a 58.2% reduction in word error rate on elderly ASR tasks.
What carries the argument
The elderly-contextual data augmentation pipeline using LLM transcript paraphrasing and TTS synthesis with elderly reference speakers to create additional training examples.
If this is right
- The method achieves consistent performance gains on both English and Korean elderly speech datasets.
- It outperforms conventional augmentation baselines in low-resource settings.
- Results depend on the chosen augmentation ratio and the composition of reference speakers used in synthesis.
- No modifications to the Whisper model architecture are required.
Where Pith is reading between the lines
- Similar augmentation could improve ASR for other data-scarce demographics such as young children or speakers with specific accents.
- The findings suggest that matching both acoustic and linguistic context in synthetic data is key to effective augmentation.
- Future tests could explore whether this pipeline helps in multi-speaker or noisy environments typical for elderly users.
Load-bearing premise
The TTS synthesis using elderly reference speakers must faithfully reproduce the acoustic and prosodic characteristics of actual elderly speech, while the LLM paraphrases must preserve appropriate elderly linguistic patterns without introducing training artifacts.
What would settle it
If the word error rate on real elderly test data does not decrease after fine-tuning with the augmented dataset, or if it increases, the effectiveness of this augmentation approach would be disproven.
Figures

read the original abstract
Despite recent progress in automatic speech recognition (ASR), elderly ASR (EASR) remains challenging due to limited training data and the distinct acoustic and linguistic characteristics of elderly speech. In this work, we address data scarcity in EASR through a data augmentation pipeline that combines large language model (LLM)-based transcript paraphrasing with text-to-speech (TTS) synthesis. Given an elderly speech dataset, the LLM first generates elderly-contextual paraphrases of the original transcripts, and the TTS model then synthesizes corresponding speech using elderly reference speakers. The resulting synthetic audio-text pairs are merged with the original data to fine-tune Whisper without architectural modification. We further analyze the effects of augmentation ratio and reference-speaker composition in low-resource EASR. Experiments on English and Korean elderly speech datasets from speakers aged 70 and above show that the proposed method consistently improves performance over conventional augmentation baselines, achieving up to a 58.2% reduction in word error rate (WER) compared with the Whisper baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an elderly-contextual data augmentation pipeline for elderly ASR that first uses an LLM to generate paraphrased transcripts preserving elderly linguistic patterns and then applies TTS synthesis conditioned on elderly reference speakers to produce matching audio. The resulting synthetic pairs are combined with the original elderly speech data to fine-tune Whisper without architectural changes. Experiments on English and Korean datasets from speakers aged 70+ report consistent gains over conventional augmentation baselines, with a peak relative WER reduction of 58.2% versus the Whisper baseline; the work additionally analyzes the effects of augmentation ratio and reference-speaker composition.
Significance. If the performance gains are robust and attributable to elderly-specific characteristics rather than data volume alone, the approach would provide a practical, architecture-agnostic method for mitigating data scarcity in EASR using off-the-shelf LLM and TTS tools. The cross-lingual results and parameter analysis could inform low-resource adaptation strategies, but the significance hinges on verification that the synthetic data faithfully reproduces elderly acoustic and prosodic traits.
major comments (2)
- [Abstract] Abstract: The headline claim of up to 58.2% WER reduction versus the Whisper baseline supplies no information on statistical significance tests, exact baseline configurations (including any fine-tuning details), train/test data splits, or speaker-disjoint evaluation protocols. Without these, the central empirical claim cannot be verified or reproduced.
- [Methods and Results] Methods and Results sections: The attribution of WER gains to the 'elderly-contextual' nature of the augmentation rests on the unverified assumption that TTS outputs conditioned on elderly reference speakers match real 70+ speech in acoustic properties (formants, jitter, shimmer, tempo, spectral tilt) and that LLM paraphrases preserve appropriate linguistic patterns. No quantitative similarity metrics (e.g., KL divergence on pitch or formant histograms), perceptual listening tests, or distribution comparisons between real and synthetic elderly speech are reported, leaving open the possibility that observed improvements arise from generic data expansion rather than the proposed elderly-specific mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications from the manuscript and indicate where revisions will be made to improve verifiability and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of up to 58.2% WER reduction versus the Whisper baseline supplies no information on statistical significance tests, exact baseline configurations (including any fine-tuning details), train/test data splits, or speaker-disjoint evaluation protocols. Without these, the central empirical claim cannot be verified or reproduced.
Authors: The full manuscript specifies the baseline as the standard Whisper model fine-tuned on the original elderly speech data using the same optimization settings and data partitions as the augmented experiments. Speaker-disjoint splits are used throughout to avoid leakage, with details provided in the experimental setup. We report mean WER across multiple random seeds but omitted formal statistical tests. We will revise the abstract and add explicit configuration details plus significance testing (e.g., bootstrap intervals) in the next version. revision: yes
-
Referee: [Methods and Results] Methods and Results sections: The attribution of WER gains to the 'elderly-contextual' nature of the augmentation rests on the unverified assumption that TTS outputs conditioned on elderly reference speakers match real 70+ speech in acoustic properties (formants, jitter, shimmer, tempo, spectral tilt) and that LLM paraphrases preserve appropriate linguistic patterns. No quantitative similarity metrics (e.g., KL divergence on pitch or formant histograms), perceptual listening tests, or distribution comparisons between real and synthetic elderly speech are reported, leaving open the possibility that observed improvements arise from generic data expansion rather than the proposed elderly-specific mechanism.
Authors: The manuscript already contains ablations on augmentation ratio and reference-speaker age composition demonstrating that performance scales with the proportion of elderly-conditioned data and is stronger when elderly rather than younger reference speakers are used. These results indicate the gains exceed those expected from volume increase alone. We did not include acoustic distribution comparisons or listening tests. We will add pitch and formant histogram comparisons plus KL-divergence metrics between real and synthetic elderly utterances in the revised results section. revision: partial
Circularity Check
No circularity in empirical augmentation pipeline
full rationale
The paper presents a purely empirical data-augmentation pipeline (LLM paraphrasing of transcripts followed by TTS synthesis conditioned on elderly reference speakers, then fine-tuning of Whisper) and reports experimental WER results on English and Korean elderly datasets. No equations, derivations, fitted parameters renamed as predictions, or first-principles claims appear in the provided text. All performance claims rest on direct comparison against baselines rather than any self-referential reduction. Self-citations, if present, are not load-bearing for the central result. This is a standard empirical study whose validity can be assessed externally via replication of the reported experiments.
Axiom & Free-Parameter Ledger
free parameters (2)
- augmentation ratio
- reference-speaker composition
axioms (2)
- domain assumption TTS synthesis conditioned on elderly reference speakers produces audio whose acoustic features match those of real elderly speech sufficiently for ASR training.
- domain assumption LLM-generated paraphrases of elderly transcripts retain appropriate linguistic and contextual features of elderly speech.
Reference graph
Works this paper leans on
-
[1]
Chapter 4 - Aging population: Challenges and opportunities in a life course perspective,
A. Scuteri and P. M. Nilsson, “Chapter 4 - Aging population: Challenges and opportunities in a life course perspective,” inEarly Vascular Aging (EVA), 2nd ed., P. G. Cunha, P. M. Nilsson, M. H. Olsen, P. Boutouyrie, and S. Laurent, Eds. Boston: Academic Press, 2024, pp. 35–39
2024
-
[2]
SeniorTalk: A Chinese conversation dataset with rich annotations for super-aged seniors,
Y . Chen, H. Wang, S. Wang, J. Chen, J. He, J. Zhou, X. Yang, Y . Wang, Y . Lin, and Y . Qin, “SeniorTalk: A Chinese conversation dataset with rich annotations for super-aged seniors,” inProc. 39th NeurIPS Datasets and Benchmarks Track, 2025. [Online]. Available: https://openreview.net/forum?id=QzWPUEuMKU
2025
-
[3]
E. Jo, Y .-H. Kim, S.-H. Ok, and D. A. Epstein, “Understanding public agencies’ expectations and realities of AI-driven chatbots for public health monitoring,” inProc. 2025 CHI, 2025, Art. no. 951, doi: 10.1145/3706598.3713593
-
[4]
Age-related changes in acoustic charac- teristics of adult speech,
P. Torre III and J. A. Barlow, “Age-related changes in acoustic charac- teristics of adult speech,”Journal of Communication Disorders, vol. 42, no. 5, pp. 324–333, 2009
2009
-
[5]
Acoustic analysis of breathy and rough voice characterizing elderly speech,
T. Miyazaki, M. Mizumachi, and K. Niyada, “Acoustic analysis of breathy and rough voice characterizing elderly speech,”Journal of Advanced Computational Intelligence and Intelligent Informatics, vol. 14, no. 2, pp. 135–141, 2010
2010
-
[6]
The aging voice: an acoustic, electroglottographic and perceptive analysis of male and female voices,
R. Winkler, M. Br ¨uckl, and W. Sendlmeier, “The aging voice: an acoustic, electroglottographic and perceptive analysis of male and female voices,” inProc. of ICPhS, vol. 3, 2003, pp. 2869–2872
2003
-
[7]
A corpus-based study of elderly and young speakers of European Portuguese: acoustic correlates and their impact on speech recognition performance,
T. Pellegrini, A. H ¨am¨al¨ainen, P. B. De Mare¨uil, M. Tjalve, I. Trancoso, S. Candeias, M. S. Dias, and D. Braga, “A corpus-based study of elderly and young speakers of European Portuguese: acoustic correlates and their impact on speech recognition performance,” inProc. Interspeech, 2013
2013
-
[8]
Common voice: A massively-multilingual speech corpus,
R. Ardila, M. Branson, K. Davis, M. Henretty, M. Kohler, J. Meyer, R. Morais, L. Saunders, F. M. Tyers, and G. Weber, “Com- mon voice: A massively-multilingual speech corpus,”arXiv preprint arXiv:1912.06670, 2019
-
[9]
Improving speech recognition for the elderly: A new corpus of elderly japanese speech and investigation of acoustic modeling for speech recognition,
M. Fukuda, H. Nishizaki, Y . Iribe, R. Nishimura, and N. Kitaoka, “Improving speech recognition for the elderly: A new corpus of elderly japanese speech and investigation of acoustic modeling for speech recognition,” inProc. Twelfth Language Resources and Evaluation Conference, 2020, pp. 6578–6585
2020
-
[10]
A new speech corpus of super-elderly Japanese for acoustic modeling,
M. Fukuda, R. Nishimura, H. Nishizaki, K. Horii, Y . Iribe, K. Ya- mamoto, and N. Kitaoka, “A new speech corpus of super-elderly Japanese for acoustic modeling,”Computer Speech & Language, vol. 77, p. 101424, 2023
2023
-
[11]
Brazilian Portuguese-Russian (BraPoRus) corpus: Automatic transcription and acoustic quality of elderly speech during the COVID-19 pandemic,
I. A. Sekerina, A. Smirnova Henriques, A. S. Skorobogatova, N. Tyulina, T. V . Kachkovskaia, S. Ruseishvili, and S. Madureira, “Brazilian Portuguese-Russian (BraPoRus) corpus: Automatic transcription and acoustic quality of elderly speech during the COVID-19 pandemic,” Linguistics Vanguard, vol. 9, no. s4, pp. 375–388, 2024
2024
-
[12]
Global prevalence of dementia: a Delphi consensus study,
C. P. Ferri, M. Prince, C. Brayne, H. Brodaty, L. Fratiglioni, M. Ganguli, K. Hall, K. Hasegawa, H. Hendrie, Y . Huang,et al., “Global prevalence of dementia: a Delphi consensus study,”The Lancet, vol. 366, no. 9503, pp. 2112–2117, 2005
2005
-
[13]
Ageing voices: The effect of changes in voice parameters on ASR performance,
R. Vipperla, S. Renals, and J. Frankel, “Ageing voices: The effect of changes in voice parameters on ASR performance,”EURASIP Journal on Audio, Speech, and Music Processing, vol. 2010, pp. 1–10, 2010
2010
-
[14]
Speech recognition in Alzheimer’s disease with personal assistive robots,
F. Rudzicz, R. Wang, M. Begum, and A. Mihailidis, “Speech recognition in Alzheimer’s disease with personal assistive robots,” inProc. 5th Work- shop on Speech and Language Processing for Assistive Technologies, 2014, pp. 20–28
2014
-
[15]
Speech recognition in Alzheimer’s disease and in its assessment,
L. Zhou, K. C. Fraser, F. Rudzicz,et al., “Speech recognition in Alzheimer’s disease and in its assessment,” inProc. Interspeech, 2016, pp. 1948–1952
2016
-
[16]
Development of the CUHK elderly speech recognition system for neurocognitive disorder detection using the Dementiabank corpus,
Z. Ye, S. Hu, J. Li, X. Xie, M. Geng, J. Yu, J. Xu, B. Xue, S. Liu, X. Liu,et al., “Development of the CUHK elderly speech recognition system for neurocognitive disorder detection using the Dementiabank corpus,” in2021 IEEE ICASSP, 2021, pp. 6433–6437
2021
-
[17]
Speaker adaptation using spectro-temporal deep features for dysarthric and elderly speech recognition,
M. Geng, X. Xie, Z. Ye, T. Wang, G. Li, S. Hu, X. Liu, and H. Meng, “Speaker adaptation using spectro-temporal deep features for dysarthric and elderly speech recognition,”IEEE/ACM TASLP, vol. 30, pp. 2597– 2611, 2022
2022
-
[18]
Exploring self-supervised pre-trained ASR models for dysarthric and elderly speech recognition,
S. Hu, X. Xie, Z. Jin, M. Geng, Y . Wang, M. Cui, J. Deng, X. Liu, and H. Meng, “Exploring self-supervised pre-trained ASR models for dysarthric and elderly speech recognition,” in2023 IEEE ICASSP, 2023, pp. 1–5
2023
-
[19]
Personalized adversarial data augmentation for dysarthric and elderly speech recognition,
Z. Jin, M. Geng, J. Deng, T. Wang, S. Hu, G. Li, and X. Liu, “Personalized adversarial data augmentation for dysarthric and elderly speech recognition,”IEEE/ACM TASLP, 2023
2023
-
[20]
Personalized adversarial data augmentation for dysarthric and elderly speech recognition,
Z. Jin, M. Geng, J. Deng, T. Wang, S. Hu, G. Li, and X. Liu, “Personalized adversarial data augmentation for dysarthric and elderly speech recognition,”IEEE/ACM TASLP, vol. 32, pp. 413–429, 2024
2024
-
[21]
M. Geng, X. Xie, J. Deng, Z. Jin, G. Li, T. Wang, S. Hu, Z. Li, H. Meng, and X. Liu, “Homogeneous speaker features for on-the-fly dysarthric and elderly speaker adaptation and speech recognition,”IEEE Trans. Audio Speech Lang. Process., vol. 33, pp. 1689–1705, 2025, doi: 10.1109/TASLPRO.2025.3547217
-
[22]
Generating synthetic audio data for attention-based speech recognition systems,
N. Rossenbach, A. Zeyer, R. Schl ¨uter, and H. Ney, “Generating synthetic audio data for attention-based speech recognition systems,” in2020 IEEE ICASSP, 2020, pp. 7069–7073
2020
-
[23]
Making more of little data: Improving low-resource automatic speech recognition using data augmentation,
M. Bartelds, N. San, B. McDonnell, D. Jurafsky, and M. Wieling, “Making more of little data: Improving low-resource automatic speech recognition using data augmentation,” inProc. 61st Annual Meeting of the ACL, 2023, pp. 715–729
2023
-
[24]
W.-Z. Leung, M. Cross, A. Ragni, and S. Goetze, “Training data augmentation for dysarthric automatic speech recognition by text-to- dysarthric-speech synthesis,”arXiv preprint arXiv:2406.08568, 2024
-
[25]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inProc. ICML), 2023, pp. 28492–28518
2023
-
[26]
The evolution of male voice acoustics: A lifespan perspective,
A. Suprent, K. Samayan, and A. Mani, “The evolution of male voice acoustics: A lifespan perspective,”Audiology and Speech Research, vol. 21, no. 1, pp. 33–38, 2025
2025
-
[27]
Unveiling the dynamics of discourse production in healthy aging and its connection to cognitive skills,
A. Marini, F. Petriglia, S. D’Ortenzio, F. M. Bosco, and G. Gasparotto, “Unveiling the dynamics of discourse production in healthy aging and its connection to cognitive skills,”Discourse Processes, vol. 62, no. 6–7, pp. 479–501, 2025
2025
-
[28]
MOPSA: Mixture of prompt-experts based speaker adaptation for elderly speech recognition,
C. Deng, X. Xie, S. Hu, M. Geng, Y . Jiang, J. Zhao, J. Deng, G. Li, Y . Chen, H. Wanget al., “MOPSA: Mixture of prompt-experts based speaker adaptation for elderly speech recognition,”arXiv preprint arXiv:2505.24224, 2025
-
[29]
Frustratingly easy data augmentation for low-resource ASR,
K. Ibaraki and D. Chiang, “Frustratingly easy data augmentation for low-resource ASR,”arXiv preprint arXiv:2509.15373, 2025
-
[30]
Large language model data generation for enhanced intent recognition in German speech,
T. P. Rosin, B. C. Kaplan, and S. Wermter, “Large language model data generation for enhanced intent recognition in German speech,” inProc. 21st Conference on Natural Language Processing (KONVENS 2025), pp. 349–359, 2025
2025
-
[31]
Assessing lexical diversity and informativeness across the adult lifes- pan: A comprehensive investigation,
F. Petriglia, G. Gasparotto, S. D’Ortenzio, I. Gabbatore, and A. Marini, “Assessing lexical diversity and informativeness across the adult lifes- pan: A comprehensive investigation,”Research Methods in Applied Linguistics, vol. 4, no. 3, p. 100276, 2025
2025
-
[32]
Openvoice: Versatile instant voice cloning
Z. Qin, W. Zhao, X. Yu, and X. Sun, “Openvoice: Versatile instant voice cloning,”arXiv preprint arXiv:2312.01479, 2023
-
[33]
Improving domain-specific ASR with LLM- generated contextual descriptions,
J. Suh, I. Na, and W. Jung, “Improving domain-specific ASR with LLM- generated contextual descriptions,”arXiv preprint arXiv:2407.17874, 2024
-
[34]
C. A. Werner,The Older Population, 2010. US Department of Com- merce, Economics and Statistics Administration, 2011
2010
-
[35]
Reviewing the definition of ‘elderly’,
H. Orimo, H. Ito, T. Suzuki, A. Araki, T. Hosoi, and M. Sawabe, “Reviewing the definition of ‘elderly’,”Geriatrics & Gerontology In- ternational, vol. 6, no. 3, pp. 149–158, 2006
2006
-
[36]
M. Jang, S. Seo, D. Kim, J. Lee, J. Kim, and J.-H. Ahn, “VOTE400 (V oice Of The Elderly 400 Hours): A speech dataset to study voice interface for elderly-care,”arXiv preprint arXiv:2101.11469, 2021
-
[37]
Decoupled Weight Decay Regularization
I. Loshchilov, “Decoupled weight decay regularization,”arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
Individual comparisons by ranking methods,
F. Wilcoxon, “Individual comparisons by ranking methods,”Biometrics Bulletin, vol. 1, no. 6, pp. 80–83, 1945
1945
-
[39]
Audio augmentation for speech recognition,
T. Ko, V . Peddinti, D. Povey, and S. Khudanpur, “Audio augmentation for speech recognition,” inProc. Interspeech, 2015, pp. 3586–3589
2015
-
[40]
Specaugment: A simple data augmen- tation method for automatic speech recognition,
D. S. Park, W. Chan, Y . Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V . Le, “Specaugment: A simple data augmentation method for automatic speech recognition,”arXiv preprint arXiv:1904.08779, 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.