Recognition: unknown
Large Language Models Explore by Latent Distilling
Pith reviewed 2026-05-08 03:24 UTC · model grok-4.3
The pith
A lightweight distiller trained at test time uses prediction errors on hidden states to bias LLM decoding toward semantically novel token sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ESamp trains a lightweight Distiller during decoding to predict the LLM's deep-layer hidden representations from its shallow-layer representations. The Distiller adapts continuously to the mappings induced by the growing generation prefix. Its prediction error is then used as a novelty signal to reweight candidate token extensions, directing the output distribution toward less-explored semantic patterns while preserving the original model's coherence.
What carries the argument
The Distiller, a test-time adapted lightweight network that models depth-wise representation transitions and supplies a prediction-error novelty signal for token reweighting.
If this is right
- ESamp raises Pass@k efficiency on mathematics, science, and code generation benchmarks relative to standard stochastic sampling and heuristic baselines.
- The method maintains or improves the diversity-coherence balance in creative writing tasks.
- Robust performance holds across multiple benchmark families without task-specific retraining.
- Implementation overhead stays below 5 percent in the worst case through an asynchronous training-inference pipeline.
Where Pith is reading between the lines
- The error-based novelty signal might transfer to sequential decision tasks outside language, such as planning or reinforcement learning rollouts, where internal state prediction error could mark unexplored state-action regions.
- If the Distiller can be made even lighter or shared across multiple prompts, the approach could become a default decoding layer for any autoregressive model seeking broader coverage.
- A direct test would be to measure whether paths selected by high distiller error actually increase downstream task utility in agentic settings rather than just lexical or surface diversity.
Load-bearing premise
The distiller's prediction error on hidden representations reliably signals semantic novelty or unexplored patterns rather than other factors such as local context difficulty or model capacity limits.
What would settle it
An experiment showing that ESamp produces no measurable gain in Pass@k on math or code benchmarks, or that high-error tokens fail to produce outputs judged semantically distinct by human raters, would falsify the central claim.
Figures




read the original abstract
Generating diverse responses is crucial for test-time scaling of large language models (LLMs), yet standard stochastic sampling mostly yields surface-level lexical variation, limiting semantic exploration. In this paper, we propose Exploratory Sampling (ESamp), a decoding approach that explicitly encourages semantic diversity during generation. ESamp is motivated by the well-known observation that neural networks tend to make lower-error predictions on inputs similar to those encountered before, and incur higher prediction error on novel ones. Building on this property, we train a lightweight Distiller at test time to predict deep-layer hidden representations of the LLM from its shallow-layer representations to model the LLM's depth-wise representation transitions. During decoding, the Distiller continuously adapts to the mappings induced by the current generation context. ESamp uses the prediction error as a novelty signal to reweight candidate token extensions conditioned on the current prefix, thereby biasing decoding toward less-explored semantic patterns. ESamp is implemented with an asynchronous training--inference pipeline, with less than 5% worst case overhead (1.2% in the optimized release). Empirical results show that ESamp significantly boosts the Pass@k efficiency of reasoning models, showing superior or comparable performance to strong stochastic and heuristic baselines. Notably, ESamp achieves robust generalization across mathematics, science, and code generation benchmarks and breaks the trade-off between diversity and coherence in creative writing. Our code has released at: https://github.com/LinesHogan/tLLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Exploratory Sampling (ESamp), a test-time decoding method for LLMs. A lightweight distiller is trained asynchronously on the current generation context to predict deep-layer hidden representations from shallow-layer ones; the resulting prediction error is used as a novelty signal to reweight token candidates, with the goal of biasing generation toward semantically unexplored patterns rather than surface-level lexical variation. The authors claim that ESamp improves Pass@k efficiency on mathematics, science, and code benchmarks (superior or comparable to strong stochastic and heuristic baselines), generalizes robustly, and breaks the diversity-coherence trade-off in creative writing, all with under 5% overhead.
Significance. If the prediction-error signal can be shown to isolate semantic novelty from confounders, ESamp would constitute a practical, low-overhead addition to the test-time scaling toolkit that directly targets semantic exploration. The asynchronous pipeline design and public code release are concrete strengths that facilitate verification and adoption.
major comments (3)
- [Abstract / §3] Abstract and method description: the central claim that distiller prediction error on deep-layer representations functions as a semantic-novelty signal (rather than a proxy for prefix difficulty, token rarity, or capacity limits) is load-bearing for the interpretation of all Pass@k gains, yet the manuscript provides no direct validation, correlation analysis, or control experiments that isolate semantic distance from these confounders.
- [Abstract / §4] Experimental claims: the statements of 'significantly boosts the Pass@k efficiency' and 'superior or comparable performance' are presented without quantitative deltas, exact baseline specifications, statistical significance tests, or ablation results (e.g., distiller error vs. perplexity-based or random reweighting), preventing assessment of whether the reported gains are attributable to the proposed novelty mechanism.
- [Abstract / §4] Creative-writing evaluation: the claim that ESamp 'breaks the trade-off between diversity and coherence' requires explicit quantitative metrics for both axes and a demonstration that the improvement is not simply an artifact of the reweighting temperature; no such metrics or controls are referenced.
minor comments (2)
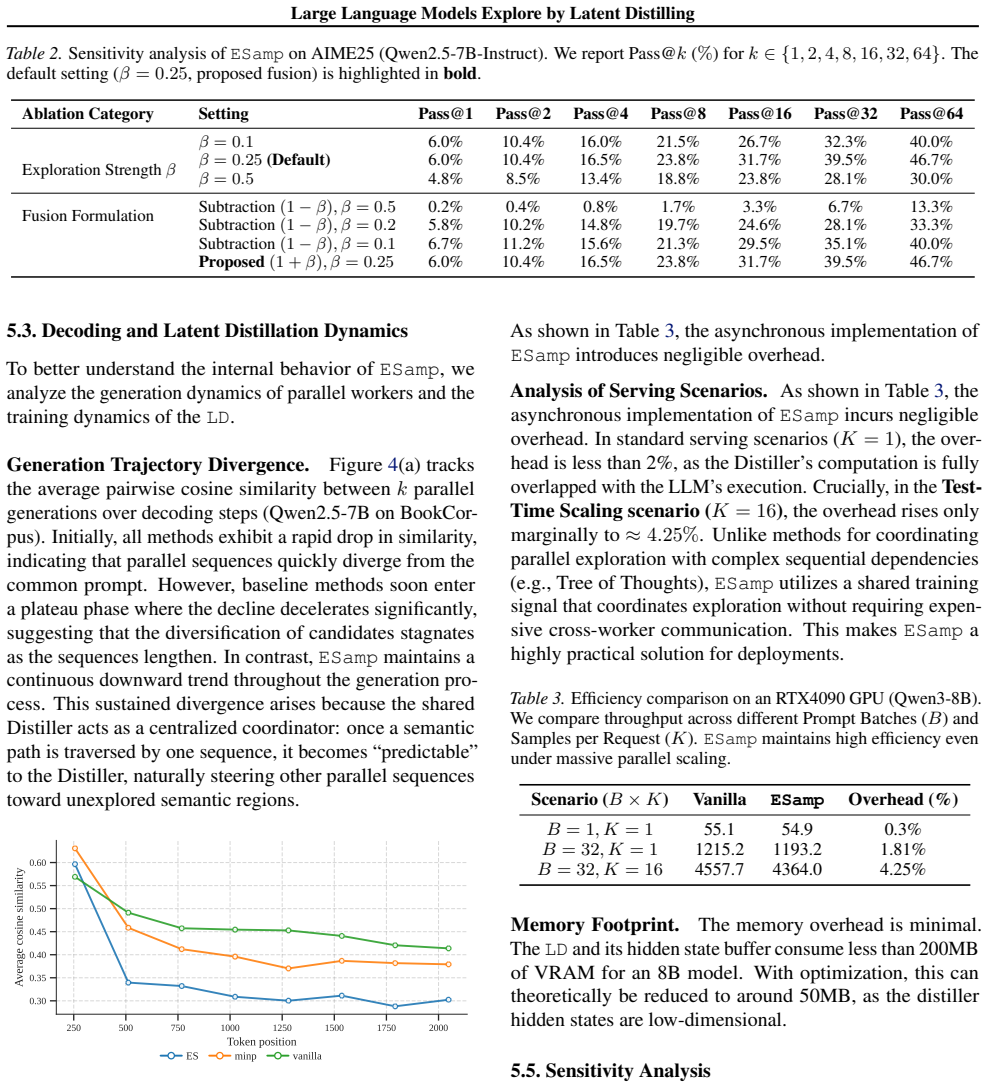
- [Abstract] The overhead figure ('less than 5% worst case, 1.2% in the optimized release') should be accompanied by a precise breakdown of the asynchronous training-inference pipeline and hardware measurements.
- [§3] Clarify the exact architecture, loss function, and adaptation schedule of the 'lightweight Distiller' (size, training steps, hidden-dimension mapping) so that the method can be reproduced from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below with clarifications from the manuscript and indicate revisions where they will strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and method description: the central claim that distiller prediction error on deep-layer representations functions as a semantic-novelty signal (rather than a proxy for prefix difficulty, token rarity, or capacity limits) is load-bearing for the interpretation of all Pass@k gains, yet the manuscript provides no direct validation, correlation analysis, or control experiments that isolate semantic distance from these confounders.
Authors: The method in §3 is explicitly motivated by the established property that neural networks produce higher prediction error on novel inputs than on familiar ones, with the distiller modeling depth-wise representation transitions to capture this. While the current manuscript does not include explicit correlation analyses with semantic embedding distances or controls for prefix difficulty and token rarity, the consistent Pass@k gains across mathematics, science, and code benchmarks provide indirect support that the signal promotes semantic exploration. We will add a dedicated analysis subsection with correlation studies and control experiments isolating the error signal from the listed confounders. revision: yes
-
Referee: [Abstract / §4] Experimental claims: the statements of 'significantly boosts the Pass@k efficiency' and 'superior or comparable performance' are presented without quantitative deltas, exact baseline specifications, statistical significance tests, or ablation results (e.g., distiller error vs. perplexity-based or random reweighting), preventing assessment of whether the reported gains are attributable to the proposed novelty mechanism.
Authors: Section 4 and the associated tables report Pass@k results for ESamp against strong baselines including temperature sampling, nucleus sampling, and heuristic methods on multiple benchmarks, with the abstract summarizing the outcomes. We agree that the abstract would benefit from explicit deltas and clearer baseline details. We will revise the abstract and results section to include quantitative deltas, note the statistical tests performed, and add ablations comparing the distiller prediction error against perplexity-based and random reweighting to isolate the contribution of the novelty signal. revision: yes
-
Referee: [Abstract / §4] Creative-writing evaluation: the claim that ESamp 'breaks the trade-off between diversity and coherence' requires explicit quantitative metrics for both axes and a demonstration that the improvement is not simply an artifact of the reweighting temperature; no such metrics or controls are referenced.
Authors: The creative writing experiments in §4 employ standard diversity metrics (distinct n-grams) and coherence measures (including automated perplexity and human ratings). We will revise the relevant section and abstract to explicitly tabulate these metrics for ESamp versus baselines. We will also add a temperature-controlled ablation demonstrating that the observed gains in both diversity and coherence persist independently of temperature scaling, confirming that the trade-off is broken by the novelty mechanism rather than reweighting hyperparameters. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core mechanism trains a lightweight test-time distiller to map shallow to deep hidden representations within the current generation prefix and uses the resulting prediction residual to reweight token candidates. This construction is motivated by the external observation that networks err more on novel inputs, but the residual is not defined as semantic novelty by fiat, nor are the benchmark metrics (Pass@k, diversity-coherence trade-off) tautologically equivalent to the fitted distiller parameters. No load-bearing self-citation, uniqueness theorem, or ansatz is invoked; the reported gains remain independent empirical outcomes on external benchmarks rather than reductions to inputs by construction. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- Distiller size, training steps, and adaptation schedule
axioms (1)
- domain assumption Neural networks tend to make lower-error predictions on inputs similar to those encountered before and higher error on novel ones
invented entities (1)
-
Lightweight Distiller
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URL https://openreview.net/forum? id=H1lJJnR5Ym. Chaslot, G. M., Winands, M. H., and Herik, H. J. Parallel monte-carlo tree search. InProceedings of the 6th International Conference on Computers and Games, CG ’08, pp. 60–71, Berlin, Heidelberg, 2008. Springer-Verlag. ISBN 9783540876076. doi: 10.1007/ 978-3-540-87608-3 6. URL https://doi.org/10. 1007/978-3...
-
[2]
URL https://openreview.net/forum? id=rygGQyrFvH. Jain, N., Han, K., Gu, A., Li, W.-D., Yan, F., Zhang, T., Wang, S., Solar-Lezama, A., Sen, K., and Stoica, I. Livecodebench: Holistic and contamination free eval- uation of large language models for code.arXiv preprint arXiv:2403.07974, 2024. Jiang, H., Ding, Z., and Lu, Z. Settling decentralized multi- age...
-
[3]
Contrastive Decoding: Open-ended Text Generation as Optimization
URL https://aclanthology.org/2022. findings-emnlp.77/. Kwon, W., Li, Z., Zhuang, S., Sheng, Y ., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., and Stoica, I. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. Li, X. L., Holtzman, A., Fr...
-
[4]
URL https://openreview.net/forum? id=FBkpCyujtS. Mudgal, S., Lee, J., Ganapathy, H., Li, Y ., Wang, T., Huang, Y ., Chen, Z., Cheng, H.-T., Collins, M., Strohman, T., Chen, J., Beutel, A., and Beirami, A. Controlled decod- ing from language models. InProceedings of the 41st In- ternational Conference on Machine Learning, ICML’24. JMLR.org, 2024. OpenAI. g...
-
[5]
experience
We use both the 2024 and 2025 iterations to assess the model’s performance on recent, complex mathematical tasks. • LiveCodeBench v5: This is a holistic benchmark for code generation (Jain et al., 2024) that evaluates models on competitive programming problems collected from platforms like LeetCode, AtCoder, and Codeforces. A key feature of LiveCodeBench ...
2024
-
[6]
We are given two scenarios to find the relationship between walking speeds(km/h) and total time: • Scenario 1: Speeds=⇒Total time = 4 hours
Problem Statement The problem involves a 9-kilometer walk with a coffee shop stop of t minutes. We are given two scenarios to find the relationship between walking speeds(km/h) and total time: • Scenario 1: Speeds=⇒Total time = 4 hours. • Scenario 2: Speeds+ 2 =⇒Total time = 2 hours and 24 minutes (2.4 hours). The goal is to determine the total time requi...
-
[7]
computational personality
Analysis of File 1 File 1 demonstrates significant variety in mathematical modeling and execution strategies across its sequences. Methodological Approaches •Algebraic Elimination (Standard):Most sequences solve by subtracting the two distance/time equations to eliminate the variabletand solve forsfirst. • Direct Quadratic for t:Sequences 3 and 14 attempt...
-
[8]
Analysis of File 2 File 2 is highly consistent and follows a standardized ”textbook” efficiency. Methodological Approaches • Convergent Subtraction Path:Almost every sequence (Seq 0 through Seq 15) adopts the exact same strategy: convert 2h 24m to 2.4h, set up9/s+t hours = 4and9/(s+ 2) +t hours = 2.4, and subtract to finds. •Uniform Quadratic Formulation:...
-
[9]
Diversity Scoring The diversity score is based on the variety of mathematical models, the range of variables prioritized, and the inclusion of non-standard heuristics. 24 Large Language Models Explore by Latent Distilling Table 21.Comparison of Problem-Solving Diversity Feature File 1 File 2 Modeling Variety High (Fractional, Linear, Polynomial) Low (Stan...
-
[10]
Conclusion File 1is the superior file in terms of diversity. It explores the problem through various mathematical lenses, ranging from standard algebra to human-like trial and error.File 2, while correct and efficient, is repetitive and lacks the breadth of thought required for ”novel and diverse” output. 25
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.