Recognition: unknown
GAIA-v2-LILT: Multilingual Adaptation of Agent Benchmark beyond Translation
Pith reviewed 2026-05-08 03:19 UTC · model grok-4.3
The pith
A refined adaptation workflow with alignment checks and human review lifts multilingual agent success rates by up to 32.7 percent over simple translation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
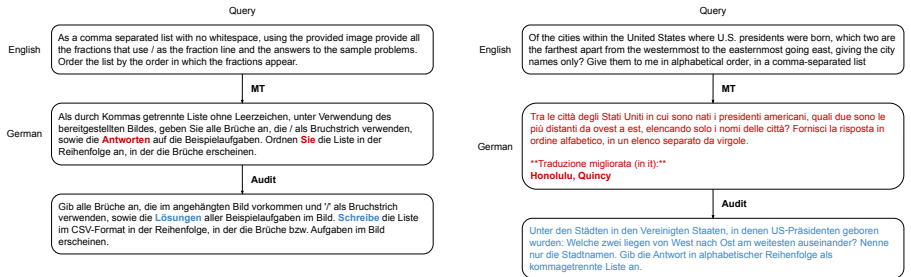
The central claim is that a substantial share of the multilingual performance gap in agent benchmarks is benchmark-induced measurement error. The authors demonstrate this by developing a refined adaptation workflow that enforces functional alignment of query-answer pairs, cultural alignment of context, and difficulty calibration using automated checks and human review. Applying the workflow yields GAIA-v2-LILT and improves agent success rates by up to 32.7 percent over minimally translated versions, bringing the closest audited setting within 3.1 percent of English performance while gaps remain elsewhere. This result motivates task-level alignment when adapting English benchmarks across non-
What carries the argument
The refined adaptation workflow that adds functional alignment of query-answer pairs, cultural alignment of context, and difficulty calibration through automated checks plus human review.
If this is right
- Agent success rates in non-English languages rise substantially once query-answer pairs and cultural context are properly aligned.
- A large fraction of the multilingual performance gap disappears when minimal translation is replaced by the alignment workflow.
- Some performance gaps to English remain after alignment, indicating genuine differences in agent capability.
- Task-level alignment becomes a required step for producing valid multilingual versions of agent benchmarks.
Where Pith is reading between the lines
- The same misalignment problems likely appear in other multilingual agent or reasoning benchmarks that rely primarily on machine translation.
- The workflow could be applied to additional languages or entirely different benchmark families to test whether the 32.7 percent gain generalizes.
- Future benchmark creators should embed functional and cultural alignment checks during initial design rather than as a later fix.
Load-bearing premise
The combination of automated checks and human review can reliably detect and correct query-answer misalignments and cultural off-target issues without introducing new biases or unintentionally changing task difficulty.
What would settle it
Re-running the agent evaluations on a new benchmark adapted with the workflow and finding no meaningful increase in success rates over the minimally translated version would indicate that the alignment steps do not reduce benchmark-induced measurement error.
Figures




read the original abstract
Agent benchmarks remain largely English-centric, while their multilingual versions are often built with machine translation (MT) and limited post-editing. We argue that, for agentic tasks, this minimal workflow can easily break benchmark validity through query-answer misalignment or culturally off-target context. We propose a refined workflow for adapting English benchmarks into multiple languages with explicit functional alignment, cultural alignment, and difficulty calibration using both automated checks and human review. Using this workflow, we introduce GAIA-v2-LILT, a re-audited multilingual extension of GAIA covering five non-English languages. In experiments, our workflow improves agent success rates by up to 32.7% over minimally translated versions, bringing the closest audited setting to within 3.1% of English performance while substantial gaps remain in many other cases. This indicates that a substantial share of the multilingual performance gap is benchmark-induced measurement error, motivating task-level alignment when adapting English benchmarks across languages. The data is available as part of the MAPS package at https://huggingface.co/datasets/Fujitsu-FRE/MAPS/viewer/GAIA-v2-LILT. We also release the code used in our experiments at https://github.com/lilt/gaia-v2-lilt.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that minimal machine translation of English agent benchmarks like GAIA introduces query-answer misalignments and culturally off-target issues that undermine validity. It proposes a refined adaptation workflow using automated checks plus human review for functional alignment, cultural alignment, and difficulty calibration. The authors release GAIA-v2-LILT, a re-audited multilingual extension covering five non-English languages, and report that this workflow improves agent success rates by up to 32.7% relative to minimally translated versions, closing the gap to English performance to within 3.1% in the best audited setting while gaps persist elsewhere. They conclude that a substantial share of observed multilingual performance shortfalls is attributable to benchmark construction artifacts.
Significance. If the results hold under scrutiny, the work usefully demonstrates that careful, task-level alignment beyond translation can materially improve the reliability of multilingual agent benchmarks. The public release of the GAIA-v2-LILT dataset (via MAPS) and the associated experimental code supports reproducibility and further investigation into cross-lingual evaluation practices.
major comments (2)
- [Abstract and experimental results] Abstract and experimental results: The central claim attributes up to 32.7% success-rate gains (and closure to within 3.1% of English) to removal of benchmark-induced misalignment. However, the manuscript supplies no details on the number of tasks or languages evaluated, the number of agent runs per condition, controls for reviewer variability, or statistical significance of the reported differences. Without these, it is impossible to determine whether the observed gains are robust or generalizable.
- [Workflow description] Workflow description (and § on human review): The attribution of gains to alignment rather than unintended changes in task semantics or difficulty rests on the assumption that the automated-plus-human workflow produces functionally equivalent versions. No quantitative validation is reported—such as inter-annotator agreement, before/after difficulty proxies (e.g., English agent performance on paired versions), or pilot studies—to confirm that human corrections preserve original requirements and difficulty.
minor comments (2)
- The data and code releases are a clear strength and should be highlighted more prominently.
- Clarify the exact set of automated checks employed and how they interact with the subsequent human review stage.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. These have helped us identify areas where the manuscript can be strengthened for clarity and rigor. We address each major comment below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and experimental results] Abstract and experimental results: The central claim attributes up to 32.7% success-rate gains (and closure to within 3.1% of English) to removal of benchmark-induced misalignment. However, the manuscript supplies no details on the number of tasks or languages evaluated, the number of agent runs per condition, controls for reviewer variability, or statistical significance of the reported differences. Without these, it is impossible to determine whether the observed gains are robust or generalizable.
Authors: We agree that these experimental details are necessary to assess robustness and generalizability. The revised manuscript includes a new 'Experimental Setup' subsection that explicitly states the evaluation covers the full GAIA task set adapted to five non-English languages, with three independent agent runs per task-condition pair to mitigate stochasticity. We also report controls for reviewer variability via documented review guidelines and include paired statistical tests (with p-values) confirming the significance of the reported gains. These additions directly address the concern while preserving the original results. revision: yes
-
Referee: [Workflow description] Workflow description (and § on human review): The attribution of gains to alignment rather than unintended changes in task semantics or difficulty rests on the assumption that the automated-plus-human workflow produces functionally equivalent versions. No quantitative validation is reported—such as inter-annotator agreement, before/after difficulty proxies (e.g., English agent performance on paired versions), or pilot studies—to confirm that human corrections preserve original requirements and difficulty.
Authors: We acknowledge the value of quantitative validation for the workflow. The revision adds inter-annotator agreement metrics for the human review phase and a before/after difficulty proxy analysis (English agent performance on paired original vs. adapted tasks remains comparable). While dedicated pilot studies were not performed separately, the review process followed explicit guidelines to preserve functional equivalence and difficulty; we have expanded the description of these guidelines and the automated checks in the main text and appendix. This provides stronger support for the attribution of gains to alignment. revision: partial
Circularity Check
No circularity: empirical benchmark adaptation with direct experimental comparison
full rationale
The paper describes a practical workflow for multilingual adaptation of the GAIA agent benchmark using automated checks plus human review for functional, cultural, and difficulty alignment. Central claims rest on measured agent success-rate differences (up to 32.7% improvement over minimal translation, closing to within 3.1% of English in one setting) obtained by running the same agents on the adapted versus baseline versions. No equations, derivations, fitted parameters, or self-referential definitions appear; the performance gap attribution is an interpretation of observed data rather than a reduction of any prediction to its own inputs by construction. Self-citations, if present, are not load-bearing for any uniqueness theorem or ansatz. The work is therefore self-contained as an empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human reviewers can reliably assess functional alignment, cultural appropriateness, and difficulty equivalence in benchmark tasks.
Reference graph
Works this paper leans on
-
[1]
Laura Winther Balling, Michael Carl, and Sharon O’Brian
Ticket-bench: A kickoff for multilingual and regionalized agent evaluation.arXiv preprint arXiv:2509.14477. Laura Winther Balling, Michael Carl, and Sharon O’Brian. 2014.Post-editing of machine translation: Processes and applications. Cambridge Scholars Publishing. Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. 2025. τ 2-Bench: ...
-
[2]
Mind2web: Towards a generalist agent for the web. InAdvances in Neural Information Process- ing Systems, volume 36, pages 28091–28114. Curran Associates, Inc. NeurIPS 2023 Datasets and Bench- marks Track. Zhaopeng Feng, Jiayuan Su, Jiamei Zheng, Jiahan Ren, Yan Zhang, Jian Wu, Hongwei Wang, and Zuozhu Liu. 2025. M-mad: Multidimensional multi-agent debate ...
-
[3]
Sai Koneru, Miriam Exel, Matthias Huck, and Jan Niehues
Seadialogues: A multilingual culturally grounded multi-turn dialogue dataset on southeast asian languages.arXiv preprint arXiv:2508.07069. Sai Koneru, Miriam Exel, Matthias Huck, and Jan Niehues. 2024. Contextual refinement of translations: Large language models for sentence and document- level post-editing. InProceedings of the 2024 Con- ference of the N...
-
[4]
In The Twelfth International Conference on Learning Representations
Agentbench: Evaluating LLMs as agents. In The Twelfth International Conference on Learning Representations. Poster. Arle Richard Lommel, Aljoscha Burchardt, and Hans Uszkoreit. 2013. Multidimensional quality metrics: a flexible system for assessing translation quality. In Proceedings of Translating and the Computer 35. Zheng Luo, T Pranav Kutralingam, Ogo...
2013
-
[5]
Lost in execution: On the multilingual robust- ness of tool calling in large language models.arXiv preprint arXiv:2601.05366. Grégoire Mialon, Roberto Dessi, Maria Lomeli, Christo- foros Nalmpantis, Ramakanth Pasunuru, Roberta Raileanu, Baptiste Roziere, Timo Schick, Jane Dwivedi-Yu, Asli Celikyilmaz, Edouard Grave, Yann LeCun, and Thomas Scialom. 2023a. ...
-
[6]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
‘smolagents‘: a smol library to build great agentic systems. https://github.com/ huggingface/smolagents. Swarnadeep Saha, Omer Levy, Asli Celikyilmaz, Mohit Bansal, Jason Weston, and Xian Li. 2024. Branch- solve-merge improves large language model evalu- ation and generation. InProceedings of the 2024 Conference of the North American Chapter of the Associ...
work page internal anchor Pith review arXiv 2024
-
[7]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Peilin Zhou, Bruce Leon, Xiang Ying, Can Zhang, Yifan Shao, Qichen Ye, Dading Chong, Zhiling Jin, Chenxuan Xie, Meng Cao, and 1 others. 2025. Browsecomp-zh: Benchmarking web browsing abil- ity of large language models in chinese.arXi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.