Recognition: unknown
AFA: Identity-Aware Memory for Preventing Persona Confusion in Multi-User Dialogue
Pith reviewed 2026-05-08 01:51 UTC · model grok-4.3
The pith
Identity-aware routing with per-user memory prevents persona confusion in shared voice assistants by keeping histories separate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
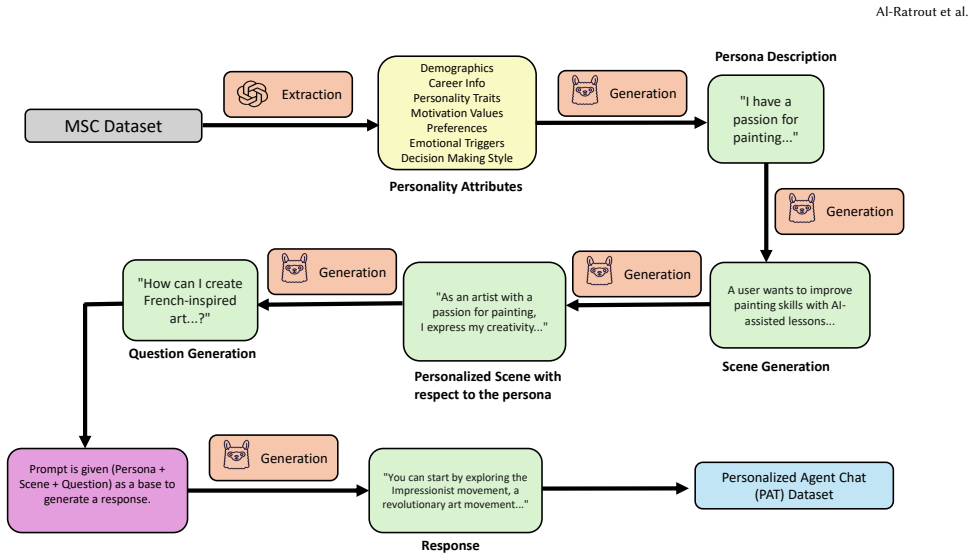
The paper establishes that identity-aware routing, achieved by combining speaker identification with dedicated per-user memory stores, is the essential mechanism for preventing persona confusion in multi-user dialogue. On the PAT dataset of 58,289 turns across 133 profiles and 12 scenarios, routing improves Persona Attribution Accuracy from 35.7 percent to 61.3 percent. A LLaMA-2-70B model fine-tuned on the dataset yields the strongest overall responses, and human evaluators rate the routing-enabled outputs as significantly more personalized.
What carries the argument
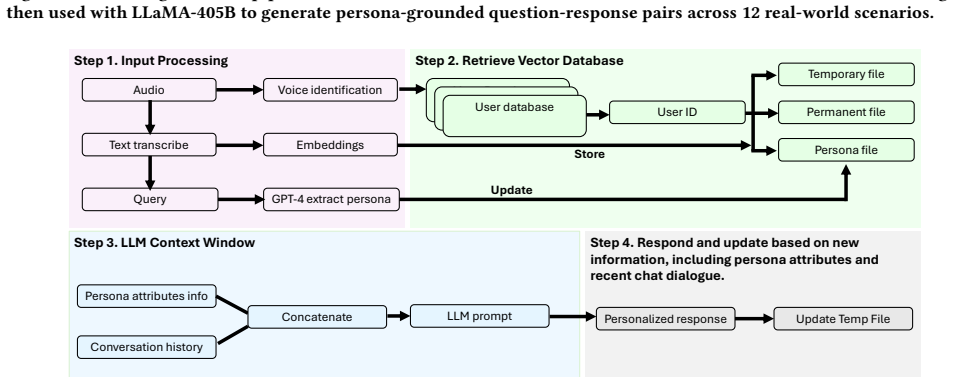
The Adaptive Friend Agent (AFA) framework that uses voice-based speaker identification to select and update the correct per-user memory store during dialogue.
Load-bearing premise
The synthetic PAT dataset and the interleaved multi-user evaluation protocol accurately reflect real-world sharing patterns and the ways persona confusion actually occurs in shared voice assistants.
What would settle it
A deployment in real households with multiple users that measures how often the assistant incorrectly references the wrong person's preferences or history, with and without the identity-aware routing active.
Figures

read the original abstract
When multiple people share a single voice assistant, the system conflates their histories: one resident's preferences can leak into another's responses, eroding utility and trust. We call this failure mode persona confusion, and we show it is a measurable problem in today's single-user dialogue systems when deployed in shared environments. We present the Adaptive Friend Agent (AFA), a modular framework that combines voice-based speaker identification with per-user memory stores to enable identity-aware, personalized dialogue across multiple users. To support training and evaluation, we construct PAT (Personalized Agent chaT), a synthetic dataset of 58,289 persona-grounded dialogue turns spanning 133 user profiles and 12 real-world scenarios. We evaluate AFA across five LLM back-ends in a standard response-quality benchmark, with a LLaMA-2-70B model fine-tuned on PAT achieving the highest overall performance. To directly measure persona confusion prevention, we introduce an interleaved multi-user evaluation protocol with a novel metric, Persona Attribution Accuracy (PAA), demonstrating that identity-aware routing improves PAA from 35.7% to 61.3%. Human evaluation confirms annotators perceive significantly higher personalization in routing-enabled responses. Our results establish that identity-aware user routing is the critical component for preventing persona confusion in multi-user conversational systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that persona confusion arises in shared voice assistants when user histories leak across individuals, eroding personalization. It introduces the Adaptive Friend Agent (AFA) modular framework that integrates voice-based speaker identification with per-user memory stores for identity-aware dialogue. To enable this, the authors construct the synthetic PAT dataset (58,289 turns, 133 profiles, 12 scenarios) and introduce an interleaved multi-user evaluation protocol with the Persona Attribution Accuracy (PAA) metric, reporting that identity-aware routing raises PAA from 35.7% to 61.3% across five LLM back-ends (with a fine-tuned LLaMA-2-70B performing best overall). Human evaluations are said to confirm higher perceived personalization in routing-enabled responses.
Significance. If the synthetic evaluation protocol accurately reflects real failure modes, the work provides a concrete, modular demonstration that identity-aware routing is necessary to prevent history leakage in multi-user conversational systems. The PAT dataset and PAA metric could become useful benchmarks for future multi-user personalization research. The numeric gains and human preference results, if robust, would support deployment considerations for shared voice assistants. However, the absence of real-world validation data means the practical significance remains provisional.
major comments (3)
- [Evaluation section / PAA protocol] The central PAA claim (improvement from 35.7% to 61.3%) is load-bearing for the assertion that identity-aware routing is 'the critical component.' However, the abstract and evaluation description provide no information on the number of evaluation runs, variance across trials, statistical significance tests, or error bars. Without these, it is impossible to determine whether the reported 25.6-point gain is reliable or could be explained by variance in the synthetic interleaving process.
- [PAT dataset construction and interleaved protocol] The weakest assumption is that the synthetic PAT dataset and artificial interleaved multi-user protocol reproduce the actual failure modes of persona confusion (history leakage, topic overlap, ambiguous turns, imperfect speaker ID). The manuscript does not report any validation of PAT against real multi-user conversation logs or any sensitivity analysis showing how PAA changes under non-interleaved or noisy speaker-ID conditions. This directly affects whether the measured gain generalizes beyond the synthetic construction.
- [Response-quality benchmark] The response-quality benchmark results (LLaMA-2-70B fine-tuned on PAT achieving highest performance) are presented without explicit baseline comparisons (e.g., zero-shot vs. fine-tuned, single-user vs. multi-user memory) or ablation of the routing component versus the memory stores. This makes it difficult to isolate the contribution of identity-aware routing to the overall claim.
minor comments (2)
- [Abstract / Evaluation] The abstract states results 'across five LLM back-ends' but does not name them or report per-model PAA scores; this should be clarified in the main text for reproducibility.
- [PAA metric definition] Notation for the PAA metric is introduced as novel but its exact formula (how attribution is scored per turn) is not shown in the provided abstract; a clear equation or pseudocode would aid readers.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments highlight important aspects of experimental rigor and generalizability that we have addressed through revisions and additional analysis. We respond to each major comment below.
read point-by-point responses
-
Referee: [Evaluation section / PAA protocol] The central PAA claim (improvement from 35.7% to 61.3%) is load-bearing for the assertion that identity-aware routing is 'the critical component.' However, the abstract and evaluation description provide no information on the number of evaluation runs, variance across trials, statistical significance tests, or error bars. Without these, it is impossible to determine whether the reported 25.6-point gain is reliable or could be explained by variance in the synthetic interleaving process.
Authors: We agree that the absence of run counts, variance, and significance testing limits interpretability of the PAA results. The original experiments used a single interleaving pass per model. In the revision we have re-executed the full PAA protocol across five independent random seeds for turn interleaving, now reporting mean PAA, standard deviation, and error bars for both the 35.7% and 61.3% figures. A paired t-test confirms the 25.6-point improvement is statistically significant (p < 0.01). These statistics and the updated protocol description appear in the revised Section 4.2 and Figure 3. revision: yes
-
Referee: [PAT dataset construction and interleaved protocol] The weakest assumption is that the synthetic PAT dataset and artificial interleaved multi-user protocol reproduce the actual failure modes of persona confusion (history leakage, topic overlap, ambiguous turns, imperfect speaker ID). The manuscript does not report any validation of PAT against real multi-user conversation logs or any sensitivity analysis showing how PAA changes under non-interleaved or noisy speaker-ID conditions. This directly affects whether the measured gain generalizes beyond the synthetic construction.
Authors: We recognize that synthetic data cannot fully substitute for real multi-user logs. Because privacy constraints prevent release or direct comparison with proprietary shared-assistant traces, we cannot provide such validation. However, we have added a sensitivity study that perturbs speaker-ID accuracy from 70% to 100% and also evaluates a non-interleaved (sequential) protocol. The identity-aware routing gain remains positive across these conditions, although it narrows under high noise. We have expanded the limitations paragraph to explicitly discuss the synthetic nature of PAT and the assumptions of the interleaving protocol. revision: partial
-
Referee: [Response-quality benchmark] The response-quality benchmark results (LLaMA-2-70B fine-tuned on PAT achieving highest performance) are presented without explicit baseline comparisons (e.g., zero-shot vs. fine-tuned, single-user vs. multi-user memory) or ablation of the routing component versus the memory stores. This makes it difficult to isolate the contribution of identity-aware routing to the overall claim.
Authors: We have revised the response-quality evaluation to include the requested controls. The updated Section 4.1 now reports: (1) zero-shot and few-shot baselines on the same five back-ends, (2) a single-user memory variant that disables per-user routing, and (3) an ablation that replaces identity-aware routing with a shared memory store while keeping per-user profiles. The new Table 2 shows that both fine-tuning on PAT and the routing module contribute measurably to the final scores, with the largest drop occurring when routing is removed. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper constructs a new synthetic PAT dataset and introduces a novel interleaved multi-user protocol with the PAA metric to quantify persona confusion prevention. The central empirical claim (identity-aware routing raises PAA from 35.7% to 61.3%) is obtained by direct comparison of AFA variants on the same constructed benchmark rather than by fitting a parameter to a subset and relabeling the output as a prediction. No self-citations are invoked to justify uniqueness or load-bearing premises, no ansatz is smuggled via prior work, and no known result is merely renamed. The evaluation protocol is externally falsifiable by applying it to other systems, rendering the reported improvement self-contained and non-circular by the stated criteria.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Voice-based speaker identification is sufficiently accurate for routing in typical home dialogue settings
- domain assumption Synthetic persona-grounded dialogues can stand in for real multi-user interactions when measuring confusion
invented entities (2)
-
Adaptive Friend Agent (AFA)
no independent evidence
-
PAT dataset
no independent evidence
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Brecht Desplanques, Jenthe Thienpondt, and Kris Demuynck. 2020. ECAPA- TDNN: Emphasized channel attention, propagation and aggregation in TDNN based speaker verification. InProceedings of Interspeech. 3830–3834
2020
-
[4]
Dongjie Fu, Xize Cheng, Linjun Li, Xiaoda Yang, Lujia Yang, and Tao Jin. 2025. PAChat: Persona-Aware Speech Assistant for Multi-party Dialogue. InProceed- ings of the 2025 Conference on Empirical Methods in Natural Language Processing. 29325–29342
2025
-
[5]
Huijie Hao, Jing Han, Chaoqun Li, Yun-Fei Li, and Xiangyu Yue. 2025. RAP: Retrieval-augmented personalization for multimodal large language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. 14538–14548
2025
-
[6]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685(2021). AFA: Identity-Aware Memory for Preventing Persona Confusion in Multi-User Dialogue
work page internal anchor Pith review arXiv 2021
-
[7]
Cheng Peng Lee, Joon Choi, and Bilge Mutlu. 2025. MAP: Multi-user personal- ization with collaborative LLM-powered agents. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems. 1–11
2025
-
[8]
Seolhwa Lee, Jaehyung Lee, Chanjun Park, Sugyeong Eo, Hyeonseok Moon, Jaewook Seo, Jungseul Park, and Hee-Soo Lim. 2022. Focus on focus: Is focus focused on context, knowledge and persona?. InProceedings of the 1st Workshop on Customized Chat Grounding Persona and Knowledge. 1–8
2022
-
[9]
Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. InText Summarization Branches Out. 74–81
2004
- [10]
-
[11]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval: NLG evaluation using GPT-4 with better human alignment. arXiv preprint arXiv:2303.16634(2023)
work page internal anchor Pith review arXiv 2023
- [12]
-
[13]
Arsha Nagrani, Joon Son Chung, Weidi Xie, and Andrew Zisserman. 2020. Vox- celeb: Large-scale speaker verification in the wild.Computer Speech & Language 60 (2020), 101027
2020
-
[14]
OpenAI. 2023. GPT-4 technical report.arXiv preprint arXiv:2303.08774(2023)
work page internal anchor Pith review arXiv 2023
-
[15]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. BLEU: a method for automatic evaluation of machine translation. InProceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 311–318
2002
- [16]
-
[17]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. 3982–3992
2019
-
[18]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. LLaMA 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
work page internal anchor Pith review arXiv 2023
-
[19]
Jing Xu, Arthur Szlam, and Jason Weston. 2022. Beyond goldfish memory: Long- term open-domain conversation. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 5180–5197
2022
-
[20]
Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston. 2018. Personalizing dialogue agents: I have a dog, do you have pets too?. InProceedings of the 56th Annual Meeting of the Association for Compu- tational Linguistics. 2204–2213
2018
- [21]
-
[22]
Wanjun Zhong, Lianghong Guo, Qianhui Gao, He Ye, and Yanlin Wang. 2024. MemoryBank: Enhancing large language models with long-term memory. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 19724–19731
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.