Recognition: no theorem link
Faithful Autoformalization via Roundtrip Verification and Repair
Pith reviewed 2026-05-12 00:59 UTC · model grok-4.3
The pith
Roundtrip verification detects and repairs unfaithful LLM formalizations of natural language by checking logical equivalence after back-translation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that roundtrip verification supplies evidence of a faithful formalization whenever the original and roundtripped formalizations are logically equivalent, and that when they disagree a stage-level diagnosis can localize the error to a specific translation step so that a scoped repair operator can correct it, yielding higher overall faithfulness than repair methods that lack diagnosis.
What carries the argument
The roundtrip verification loop of formalization, back-translation, re-formalization, logical-equivalence checking, followed by diagnosis and scoped repair when the check fails.
If this is right
- Diagnosis-guided scoped repair is the most effective repair strategy across both statutory domains and both tested LLMs.
- Repair effectiveness depends directly on the accuracy of the diagnosis function that localizes the error.
- Rules that fail the equivalence check exhibit 1.4x to 2.5x more natural-language-inference drift than rules that pass it.
- The approach can be applied directly to formalizing rules from the Texas Transportation Code and the Texas Parks and Wildlife Code.
Where Pith is reading between the lines
- The same back-translation-plus-equivalence pattern could be tested on other formalization tasks such as turning English specifications into code or turning mathematical text into proofs.
- If the diagnosis step can be made reliable, self-verification loops of this kind may reduce the amount of human annotation needed to train or fine-tune formalization models.
- The method suggests a general strategy for catching meaning drift whenever an LLM moves between informal and formal representations without external labels.
Load-bearing premise
Logical equivalence between the original and roundtripped formalizations reliably indicates that the formalization has preserved the original natural-language meaning rather than merely being equivalent for unrelated reasons.
What would settle it
A single statute where two formalizations are logically equivalent according to the tool yet produce different conclusions when fed into a downstream reasoner or when compared against human interpretation of the original text would refute the verification method.
Figures





read the original abstract
When an LLM formalizes natural language, how do we know the output is faithful? We propose a roundtrip verification approach which does not require ground-truth annotations: formalize a statement, translate the result back to natural language, re-formalize, and use a formal tool to check logical equivalence. When the two formalizations agree, this provides evidence of a faithful formalization. When they disagree, a stage-level diagnosis localizes the error to a specific translation step, and a scoped repair operator attempts to correct that step. We evaluate the framework on two statutory domains (the Texas Transportation Code and the Texas Parks and Wildlife Code) using two LLMs (Claude Opus~4.6 and GPT-5.2) with three repair baselines. Diagnosis-guided scoped repair is the most effective method, with effectiveness contingent on the reliability of the diagnosis function. Across both domains and both models, under our full repair system, rules that fail the equivalence check show 1.4x-2.5x more NLI drift than rules that pass it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a roundtrip verification and repair framework for faithful autoformalization of natural language (NL) statements by LLMs without ground-truth annotations. The method formalizes an NL statement to a formal representation F1, back-translates F1 to NL, re-formalizes to F2, and checks logical equivalence of F1 and F2 via a formal verifier. Equivalence is taken as evidence of faithfulness to the original NL; non-equivalence triggers stage-level diagnosis to localize the error and a scoped repair operator to correct it. The framework is evaluated on two statutory domains (Texas Transportation Code and Texas Parks and Wildlife Code) using Claude Opus 4.6 and GPT-5.2, with three repair baselines. Diagnosis-guided scoped repair is reported as most effective, and rules failing the equivalence check exhibit 1.4x-2.5x more NLI drift than those that pass.
Significance. If the roundtrip equivalence check reliably proxies faithfulness, the approach would provide a valuable annotation-free technique for verifying and improving LLM formalizations in high-stakes domains such as legal reasoning. The evaluation design uses external statutory texts, independent formal verifiers, and separate NLI models, which avoids obvious circularity. The quantitative outcomes on NLI drift and repair effectiveness are concrete, but the indirect proxy nature of the metrics limits the strength of the conclusions.
major comments (3)
- [§3] §3 (Roundtrip Verification): The central claim that logical equivalence between the initial formalization F1 and roundtrip formalization F2 provides evidence of faithfulness to the original NL statement assumes that back-translation and re-formalization will surface meaning-altering errors rather than preserve consistent misinterpretations (e.g., of statutory quantifiers or scoping). No counterexample analysis or human faithfulness judgments on a sample of cases are described to test this assumption, which is load-bearing for the verification method.
- [§4.2] §4.2 (NLI Drift Evaluation): The reported result that failing rules show 1.4x-2.5x more NLI drift than passing rules is presented as supporting evidence, but the manuscript does not specify the exact NLI model, the precise definition of 'drift' (e.g., which NL pairs are compared and how scores are aggregated), or any statistical significance tests. This weakens the support for the effectiveness claim.
- [§4.3] §4.3 (Repair Effectiveness): Diagnosis-guided scoped repair is claimed to be the most effective method, with effectiveness stated to be contingent on diagnosis reliability. However, no independent quantitative validation of the diagnosis function (e.g., precision/recall against human-annotated error localizations) is provided, which is load-bearing for interpreting the superiority result.
minor comments (2)
- The abstract and evaluation sections use model versions (Claude Opus~4.6, GPT-5.2) that may require clarification on whether they refer to specific releases or are illustrative.
- Notation for formal representations and NLI drift could be introduced more explicitly on first use to aid readability for readers outside formal methods.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important aspects of our roundtrip verification framework. We address each major comment point by point below, providing the strongest honest defense of the manuscript while acknowledging where revisions are warranted to improve clarity and support for our claims.
read point-by-point responses
-
Referee: [§3] §3 (Roundtrip Verification): The central claim that logical equivalence between the initial formalization F1 and roundtrip formalization F2 provides evidence of faithfulness to the original NL statement assumes that back-translation and re-formalization will surface meaning-altering errors rather than preserve consistent misinterpretations (e.g., of statutory quantifiers or scoping). No counterexample analysis or human faithfulness judgments on a sample of cases are described to test this assumption, which is load-bearing for the verification method.
Authors: We acknowledge that the roundtrip equivalence check is an indirect proxy whose validity rests on the assumption that back-translation and re-formalization will typically expose meaning-altering errors. In the domain of statutory text, which uses precise legal language, we argue that consistent misinterpretations (e.g., of quantifiers) are less likely to persist undetected because the formal verifier operates independently of the LLM and the back-translation step re-exposes the formalization to the same model. The observed 1.4x-2.5x higher NLI drift in failing cases provides indirect empirical support that the check is sensitive to faithfulness issues. In the revised manuscript we will add a dedicated limitations paragraph in §3 with 2-3 concrete counterexamples drawn from our Texas codes dataset where equivalence held but potential scoping ambiguities existed, and we will explicitly discuss the assumption rather than leaving it implicit. revision: partial
-
Referee: [§4.2] §4.2 (NLI Drift Evaluation): The reported result that failing rules show 1.4x-2.5x more NLI drift than passing rules is presented as supporting evidence, but the manuscript does not specify the exact NLI model, the precise definition of 'drift' (e.g., which NL pairs are compared and how scores are aggregated), or any statistical significance tests. This weakens the support for the effectiveness claim.
Authors: We agree that these implementation details were omitted and should have been included. In the revised manuscript we will specify the NLI model (a RoBERTa-large model fine-tuned on MNLI), define NLI drift precisely as the absolute difference in entailment probability between the original NL statement and the back-translated NL derived from F1 (with mean aggregation across rules), and report statistical significance via paired t-tests together with p-values and 95% confidence intervals for the reported 1.4x-2.5x factor. These additions will appear in §4.2 and the supplementary material. revision: yes
-
Referee: [§4.3] §4.3 (Repair Effectiveness): Diagnosis-guided scoped repair is claimed to be the most effective method, with effectiveness stated to be contingent on diagnosis reliability. However, no independent quantitative validation of the diagnosis function (e.g., precision/recall against human-annotated error localizations) is provided, which is load-bearing for interpreting the superiority result.
Authors: We accept that an independent quantitative validation (precision/recall against human annotations) would strengthen the claim. The diagnosis function is deterministic, relying on stage-level equivalence checks between intermediate representations, and the superiority of the full system is demonstrated by end-to-end improvements in equivalence rate and NLI drift reduction relative to the three baselines. In the revision we will expand §4.3 with a qualitative validation: manual inspection of 20 randomly sampled cases to assess whether the diagnosed error stage aligns with human judgment of the fault location. We will also note that a full precision/recall study against annotated localizations is left as future work due to the annotation cost. revision: partial
Circularity Check
No significant circularity; evaluation uses independent external benchmarks
full rationale
The paper's framework relies on external statutory texts (Texas codes), independent formal verifiers for equivalence, and separate NLI models for drift measurement. The central empirical claim (1.4x-2.5x drift difference) is a measured outcome on these external elements rather than a reduction to self-defined parameters or self-citation chains. The roundtrip equivalence is presented as evidence of faithfulness, not defined as equivalent to it by construction, and no load-bearing step collapses to a fitted input or prior self-work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Logical equivalence detected by the formal tool indicates faithfulness to the original natural language meaning
- domain assumption The back-translation step preserves enough semantic information for the re-formalization to be meaningful
Forward citations
Cited by 1 Pith paper
-
Neurosymbolic Auditing of Natural-Language Software Requirements
VERIMED translates natural-language requirements to formal logic via LLMs, detects ambiguity from stochastic formalization differences, and audits for inconsistency and safety violations using SMT queries.
Reference graph
Works this paper leans on
-
[1]
ProofBridge: Auto-formalization of natural language proofs in Lean via joint embeddings.arXiv preprint arXiv:2510.15681. Albert Q. Jiang, Wenda Li, and Mateja Jamnik. 2023a. Multilingual mathematical autoformalization. ArXiv:2311.03755. Albert Q. Jiang, Sean Welleck, Jin Peng Zhou, Wenda Li, Jiacheng Liu, Mateja Jamnik, Timo- thée Lacroix, Yuhuai Wu, and ...
-
[2]
TR2MTL: LLM based framework for met- ric temporal logic formalization of traffic rules. ArXiv:2406.05709. Tom McCoy, Ellie Pavlick, and Tal Linzen. 2019. Right for the wrong reasons: Diagnosing syntactic heuris- tics in natural language inference. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), pages 3428–3...
-
[3]
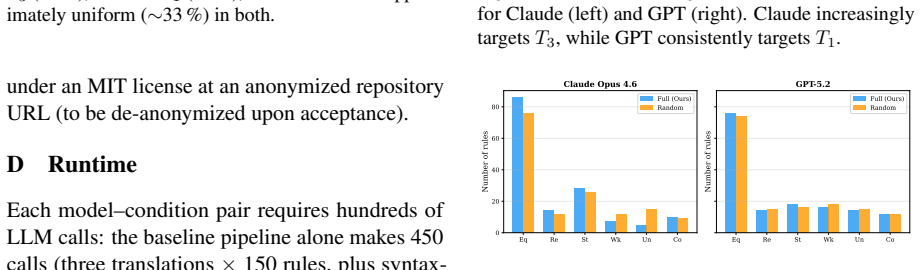
MiniF2F: a cross-system benchmark for for- mal Olympiad-level mathematics. InInternational Conference on Learning Representations (ICLR). ArXiv:2109.00110. A Worked Example: Stage 3 Repair We trace rule r127 from the Claude Opus 4.6 run end-to-end. This rule is initially SAT (non- equivalent), diagnosed as a Stage 3 (T3) divergence, and repaired in a sing...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.