Recognition: unknown
Cooperate to Compete: Strategic Coordination in Multi-Agent Conquest
Pith reviewed 2026-05-07 16:34 UTC · model grok-4.3
The pith
Adjusting language model agents to match human negotiation patterns raises their win rate from 22 percent to 33 percent in a new competitive game.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the Cooperate to Compete environment, language-model agents produce more complex and more reliable negotiation behavior than humans, who accept deals without counter-offers only 56 percent of the time and favor lower-complexity agreements. Targeted prompting that aligns agent behavior with these human patterns improves the agents' win rate against human opponents from 22.2 percent to 32.7 percent across more than 1,100 games.
What carries the argument
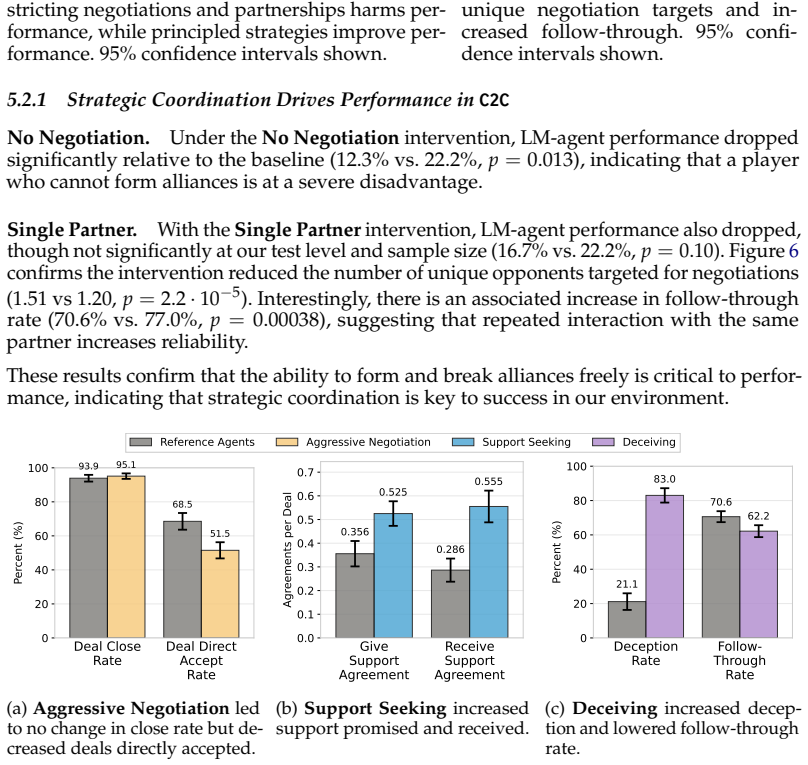
The Cooperate to Compete (C2C) environment, in which players hold asymmetric secret objectives and conduct private non-binding negotiations that can form and dissolve as short-term interests align or diverge.
If this is right
- Language-model agents can be steered toward more effective mixed-motive behavior without retraining, simply by changing their negotiation prompts.
- C2C provides a scalable testbed for studying coordination failures and successes that occur when short-term alliances must serve long-term competitive goals.
- The collected dataset of 16,000 private conversations supplies a concrete resource for measuring and improving agent reliability in negotiation.
- Human-AI performance gaps in this setting are large enough that modest behavioral alignment yields double-digit win-rate gains.
Where Pith is reading between the lines
- The same prompting approach could be tested in other non-binding negotiation domains such as automated bargaining or multi-party policy simulation.
- If human unreliability is the dominant factor, future agents might benefit from explicit modeling of partner reliability rather than pure imitation of human style.
- The 10-point win-rate improvement suggests that real-world deployments involving repeated human-AI interactions could see compounding advantages from similar alignment techniques.
Load-bearing premise
The differences between human and language-model negotiation styles observed in the user study will remain stable enough to guide prompt changes that continue to work against new opponents and in new game variants.
What would settle it
Re-running the same prompting modifications against a fresh pool of human players or with a different base language model and measuring whether the win-rate gain disappears.
Figures






read the original abstract
Language Model (LM)-based agents remain largely untested in mixed-motive settings where agents must leverage short-term cooperation for long-term competitive goals (e.g., multi-party politics). We introduce Cooperate to Compete (C2C), a multi-agent environment where players can engage in private negotiations while competing to be the first to achieve their secret objective. Players have asymmetric objectives and negotiations are non-binding, allowing alliances to form and break as players' short-term interests align and diverge. We run AI only games and conduct a user study pitting human players against AI opponents. We identify significant differences between human and AI negotiation behaviors, finding that humans favor lower-complexity deals and are significantly less reliable partners compared to LM-based agents. We also find that humans are more aggressive negotiators, accepting deals without a counteroffer only 56.3% of the time compared to 67.6% for LM-based agents. Through targeted prompting inspired by these findings, we modify agents' negotiation behavior and improve win rates from 22.2% to 32.7%. We run over 1,100 games with over 16,000 private conversations totaling 15.2 million tokens and over 150,000 player actions. Our results establish C2C as a testbed for studying and building LM-based agents that can navigate the sophisticated coordination required for real-world deployments. The game, code, and dataset may be found at https://negotiationgame.io/c2c.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Cooperate to Compete (C2C) multi-agent environment in which LM-based agents engage in non-binding private negotiations while pursuing asymmetric secret objectives. Through AI-only games and a human-AI user study, it identifies behavioral differences (humans favor lower-complexity deals, are less reliable partners, and accept deals without counteroffer only 56.3% of the time versus 67.6% for LM agents). Targeted prompting inspired by these differences is then shown to raise LM agent win rates from 22.2% to 32.7% across >1,100 games, >16,000 conversations, and >150,000 actions. The work positions C2C as a testbed and releases the game, code, and dataset.
Significance. If the central performance claim is statistically supported, the paper supplies a scalable, mixed-motive testbed and concrete evidence that human-AI behavioral differences can be leveraged to improve LM negotiation strategies. The large experimental scale and public artifacts are clear strengths that would enable follow-on work on coordination in politics-like settings.
major comments (2)
- [Abstract and Results] Abstract and Results: the headline claim that targeted prompting improves win rates from 22.2% to 32.7% is reported without per-condition sample sizes, standard errors, bootstrap intervals, or any hypothesis test. With only the aggregate >1,100 games stated, it is impossible to determine whether the 10.5-point lift exceeds sampling variability or is attributable to the prompting rather than other factors.
- [User-study and prompting sections] User-study and prompting sections: the manuscript states that prompting is 'inspired by' the observed human-AI differences (e.g., acceptance rates, reliability) but provides no explicit mapping from those statistics to the prompt modifications, nor any ablation showing that the specific changes (rather than generic prompting) drive the gain.
minor comments (2)
- [Abstract] Abstract should include brief baseline details, opponent pool description, and mention of statistical testing to allow readers to evaluate the 10.5-point claim at a glance.
- [Methods] Notation for negotiation complexity and reliability metrics should be defined consistently when first introduced and carried through tables or figures.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the statistical details and the explicit link between user-study observations and prompting require strengthening. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results: the headline claim that targeted prompting improves win rates from 22.2% to 32.7% is reported without per-condition sample sizes, standard errors, bootstrap intervals, or any hypothesis test. With only the aggregate >1,100 games stated, it is impossible to determine whether the 10.5-point lift exceeds sampling variability or is attributable to the prompting rather than other factors.
Authors: We agree that the current reporting is insufficient to evaluate the reliability of the improvement. In the revision we will report the exact number of games per condition, standard errors, bootstrap confidence intervals, and the result of an appropriate hypothesis test (two-proportion z-test) for the difference between 22.2% and 32.7%. The total exceeds 1,100 games with balanced allocation across conditions, which supplies adequate power for these analyses. revision: yes
-
Referee: [User-study and prompting sections] User-study and prompting sections: the manuscript states that prompting is 'inspired by' the observed human-AI differences (e.g., acceptance rates, reliability) but provides no explicit mapping from those statistics to the prompt modifications, nor any ablation showing that the specific changes (rather than generic prompting) drive the gain.
Authors: We acknowledge that the manuscript lacks an explicit mapping and an ablation. In the revision we will add a subsection that directly links each reported human-AI difference (e.g., 56.3% vs. 67.6% acceptance without counter-offer, lower human reliability) to the corresponding prompt modifications. We will also include an ablation comparing the targeted prompts against a generic negotiation-prompt baseline to demonstrate that the specific changes, rather than prompting in general, account for the observed gain. revision: yes
Circularity Check
No significant circularity; empirical results are independent of inputs
full rationale
The paper reports results from separate runs of AI-only games (>1,100 total) and a distinct human-vs-AI user study. The win-rate improvement (22.2% to 32.7%) is obtained by applying prompting changes in new game instances, not by any re-use of the same data, fitted parameters, or self-referential definitions. No equations, uniqueness theorems, or ansatzes appear in the provided text, and no self-citations are invoked as load-bearing justification for the behavioral differences or performance gains. The derivation chain consists of observation followed by independent validation runs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Targeted prompting can reliably alter LM negotiation behavior in the direction suggested by human-AI comparisons
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Cooperation, competition, and maliciousness: LLM -stakeholders interactive negotiation
Sahar Abdelnabi, Amr Gomaa, Sarath Sivaprasad, Lea Sch \"o nherr, and Mario Fritz. Cooperation, competition, and maliciousness: LLM -stakeholders interactive negotiation. Advances in Neural Information Processing Systems, 37: 0 83548--83599, 2024
2024
-
[3]
Playing repeated games with large language models
Elif Akata, Lion Schulz, Julian Coda-Forno, Seong Joon Oh, Matthias Bethge, and Eric Schulz. Playing repeated games with large language models. Nature Human Behaviour, pp.\ 1--11, 2025
2025
-
[4]
Human-level play in the game of Diplomacy by combining language models with strategic reasoning
Anton Bakhtin, Noam Brown, Emily Dinan, Gabriele Farina, Colin Flaherty, Daniel Fried, Andrew Goff, Jonathan Gray, Hengyuan Hu, et al. Human-level play in the game of Diplomacy by combining language models with strategic reasoning. Science, 378 0 (6624): 0 1067--1074, 2022
2022
-
[5]
Using cognitive psychology to understand GPT -3
Marcel Binz and Eric Schulz. Using cognitive psychology to understand GPT -3. Proceedings of the National Academy of Sciences, 120 0 (6): 0 e2218523120, 2023
2023
-
[6]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39 0 (3/4): 0 324--345, 1952
1952
-
[7]
Overcommunication in strategic information transmission games
Hongbin Cai and Joseph Tao-Yi Wang. Overcommunication in strategic information transmission games. Games and Economic Behavior, 56 0 (1): 0 7--36, 2006
2006
-
[8]
Diplomacy, 1957
Allan Calhamer. Diplomacy, 1957
1957
-
[9]
Bounded rationality for LLMs : Satisficing alignment at inference-time
Mohamad Chehade, Soumya Suvra Ghosal, Souradip Chakraborty, Avinash Reddy, Dinesh Manocha, Hao Zhu, and Amrit Singh Bedi. Bounded rationality for LLMs : Satisficing alignment at inference-time. arXiv preprint arXiv:2505.23729, 2025
-
[10]
Tim R Davidson, Adam Fourney, Saleema Amershi, Robert West, Eric Horvitz, and Ece Kamar. The collaboration gap. arXiv preprint arXiv:2511.02687, 2025
-
[11]
Cheap talk
Joseph Farrell and Matthew Rabin. Cheap talk. Journal of Economic perspectives, 10 0 (3): 0 103--118, 1996
1996
-
[12]
Universal mechanisms
Fran c oise Forges. Universal mechanisms. Econometrica: Journal of the Econometric Society, pp.\ 1341--1364, 1990
1990
-
[13]
Gemini 3.1 flash lite model card
Gemini Team . Gemini 3.1 flash lite model card. https://storage.googleapis.com/deepmind-media/Model-Cards/Gemini-3-1-Flash-Lite-Model-Card.pdf, March 2026 a
2026
-
[14]
Gemini 3.1 pro model card
Gemini Team . Gemini 3.1 pro model card. https://storage.googleapis.com/deepmind-media/Model-Cards/Gemini-3-1-Pro-Model-Card.pdf, February 2026 b
2026
-
[15]
Explicit cooperation shapes human-like multi-agent LLM negotiation
Yanru Jiang and G \"u lsah Ak c ak r. Explicit cooperation shapes human-like multi-agent LLM negotiation. In Proceedings of the Annual Meeting of the Cognitive Science Society, volume 47, 2025
2025
-
[16]
Risk: The game of global domination, 1957
Albert Lamorisse. Risk: The game of global domination, 1957
1957
-
[17]
FightLadder : A benchmark for competitive multi-agent reinforcement learning
Wenzhe Li, Zihan Ding, Seth Karten, and Chi Jin. FightLadder : A benchmark for competitive multi-agent reinforcement learning. arXiv preprint arXiv:2406.02081, 2024
-
[18]
From text to tactic: Evaluating llms play- ing the game of avalon
Jonathan Light, Min Cai, Sheng Shen, and Ziniu Hu. AvalonBench : Evaluating LLMs playing the game of Avalon . arXiv preprint arXiv:2310.05036, 2023
-
[19]
On the limited memory bfgs method for large scale optimization
Dong C Liu and Jorge Nocedal. On the limited memory bfgs method for large scale optimization. Mathematical programming, 45 0 (1): 0 503--528, 1989
1989
-
[20]
Communication enhances LLMs ' stability in strategic thinking
Nunzio Lore and Babak Heydari. Communication enhances LLMs ' stability in strategic thinking. arXiv preprint arXiv:2602.06081, 2026
-
[21]
Individual choice behavior, volume 4
R Duncan Luce. Individual choice behavior, volume 4. Wiley New York, 1959
1959
-
[22]
(ir) rationality and cognitive biases in large language models
Olivia Macmillan-Scott and Mirco Musolesi. (ir) rationality and cognitive biases in large language models. Royal Society open science, 11 0 (6), 2024
2024
-
[23]
Communication enables cooperation in LLM agents: A comparison with curriculum-based approaches
Hachem Madmoun and Salem Lahlou. Communication enables cooperation in LLM agents: A comparison with curriculum-based approaches. arXiv preprint arXiv:2510.05748, 2025
-
[24]
Note on the sampling error of the difference between correlated proportions or percentages
Quinn McNemar . Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika, 12 0 (2): 0 153--157, 1947
1947
-
[25]
LieCraft : A multi-agent framework for evaluating deceptive capabilities in language models
Matthew Lyle Olson, Neale Ratzlaff, Musashi Hinck, Tri Nguyen, Vasudev Lal, Joseph Campbell, Simon Stepputtis, and Shao-Yen Tseng. LieCraft : A multi-agent framework for evaluating deceptive capabilities in language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pp.\ 37802--37809, 2026
2026
-
[26]
Introducing gpt-4.1 in the API
OpenAI . Introducing gpt-4.1 in the API . https://openai.com/index/gpt-4-1/, April 2025 a
2025
-
[27]
Introducing gpt-5.2
OpenAI . Introducing gpt-5.2. https://openai.com/index/introducing-gpt-5-2/, December 2025 b
2025
-
[28]
arXiv preprint arXiv:2410.07553 , year=
Timothy Ossowski, Jixuan Chen, Danyal Maqbool, Zefan Cai, Tyler Bradshaw, and Junjie Hu. COMMA : A communicative multimodal multi-agent benchmark. arXiv preprint arXiv:2410.07553, 2024
-
[29]
The analysis of permutations
Robin L Plackett. The analysis of permutations. Journal of the Royal Statistical Society Series C: Applied Statistics, 24 0 (2): 0 193--202, 1975
1975
-
[30]
Evaluating large language models through communication games: An agent-based framework using Werewolf in unity
Christian Poglitsch, Fabian Szak \'a cs, and Johanna Pirker. Evaluating large language models through communication games: An agent-based framework using Werewolf in unity. In Proceedings of the 20th International Conference on the Foundations of Digital Games, pp.\ 1--10, 2025
2025
-
[31]
Micromotives and macrobehavior
Thomas C Schelling. Micromotives and macrobehavior. WW Norton & Company, 2006
2006
-
[32]
BLGAN : Bayesian learning and genetic algorithm for supporting negotiation with incomplete information
Kwang Mong Sim, Yuanyuan Guo, and Benyun Shi. BLGAN : Bayesian learning and genetic algorithm for supporting negotiation with incomplete information. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 39 0 (1): 0 198--211, 2008
2008
-
[33]
Evaluating generalization capabilities of llm-based agents in mixed-motive scenarios using Concordia
Chandler Smith, Marwa Abdulhai, Manfred Diaz, Marko Tesic, Rakshit S Trivedi, Alexander Sasha Vezhnevets, Lewis Hammond, Jesse Clifton, Minsuk Chang, Edgar A Du \'e \ n ez-Guzm \'a n, et al. Evaluating generalization capabilities of llm-based agents in mixed-motive scenarios using Concordia . arXiv preprint arXiv:2512.03318, 2025
-
[34]
Beyond survival: Evaluating llms in social deduction games with human- aligned strategies, 2025
Zirui Song, Yuan Huang, Junchang Liu, Haozhe Luo, Chenxi Wang, Lang Gao, Zixiang Xu, Mingfei Han, Xiaojun Chang, and Xiuying Chen. Beyond survival: Evaluating LLMs in social deduction games with human-aligned strategies. arXiv preprint arXiv:2510.11389, 2025
-
[35]
arXiv preprint arXiv:2408.15971 , year=
Wei Wang, Dan Zhang, Tao Feng, Boyan Wang, and Jie Tang. BattleAgentBench : A benchmark for evaluating cooperation and competition capabilities of language models in multi-agent systems. arXiv preprint arXiv:2408.15971, 2024
-
[36]
Individual comparisons by ranking methods
Frank Wilcoxon. Individual comparisons by ranking methods. Biometrics bulletin, 1 0 (6): 0 80--83, 1945
1945
-
[37]
More victories, less cooperation: Assessing Cicero ’s diplomacy play
Wichayaporn Wongkamjan, Feng Gu, Yanze Wang, Ulf Hermjakob, Jonathan May, Brandon M Stewart, Jonathan Kummerfeld, Denis Peskoff, and Jordan Boyd-Graber. More victories, less cooperation: Assessing Cicero ’s diplomacy play. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 12423--12441, 2024
2024
-
[38]
Grok 4.1 model card
xAI . Grok 4.1 model card. https://data.x.ai/2025-11-17-grok-4-1-model-card.pdf, November 2025
2025
-
[39]
Can large language model agents simulate human trust behavior? Advances in neural information processing systems, 37: 0 15674--15729, 2024
Chengxing Xie, Canyu Chen, Feiran Jia, Ziyu Ye, Shiyang Lai, Kai Shu, Jindong Gu, Adel Bibi, Ziniu Hu, David Jurgens, et al. Can large language model agents simulate human trust behavior? Advances in neural information processing systems, 37: 0 15674--15729, 2024
2024
-
[40]
Magic: Investigation of large language model powered multi-agent in cognition, adaptability, rationality and collaboration
Lin Xu, Zhiyuan Hu, Daquan Zhou, Hongyu Ren, Zhen Dong, Kurt Keutzer, See Kiong Ng, and Jiashi Feng. Magic: Investigation of large language model powered multi-agent in cognition, adaptability, rationality and collaboration. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 7315--7332, 2024
2024
-
[41]
arXiv preprint arXiv:2310.11667 , year=
Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, et al. SOTOPIA : Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667, 2023
-
[42]
MultiAgentBench : Evaluating the collaboration and competition of LLM agents
Kunlun Zhu, Hongyi Du, Zhaochen Hong, Xiaocheng Yang, Shuyi Guo, Daisy Zhe Wang, Zhenhailong Wang, Cheng Qian, Robert Tang, Heng Ji, et al. MultiAgentBench : Evaluating the collaboration and competition of LLM agents. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 8580--8622, 2025
2025
-
[43]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[44]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[45]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.